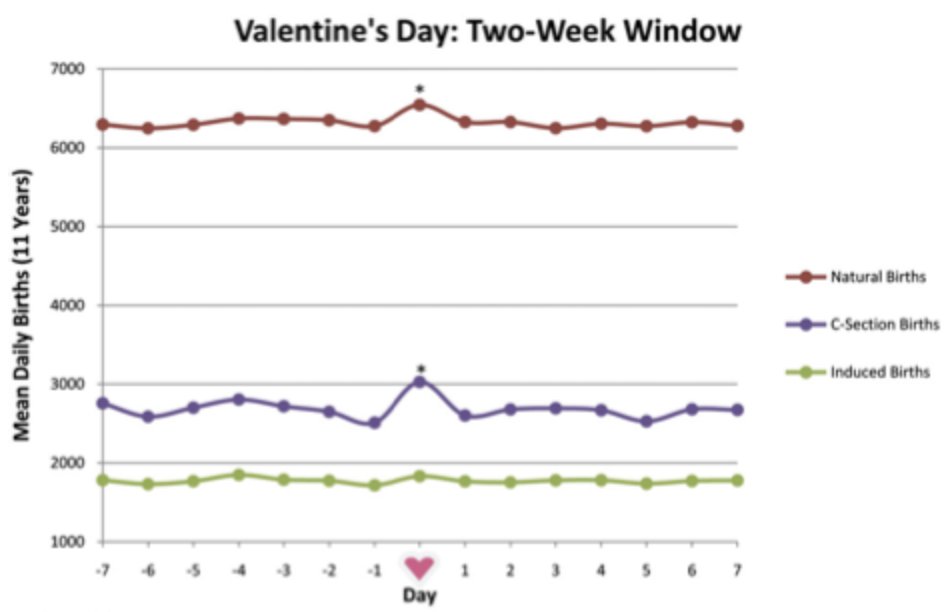
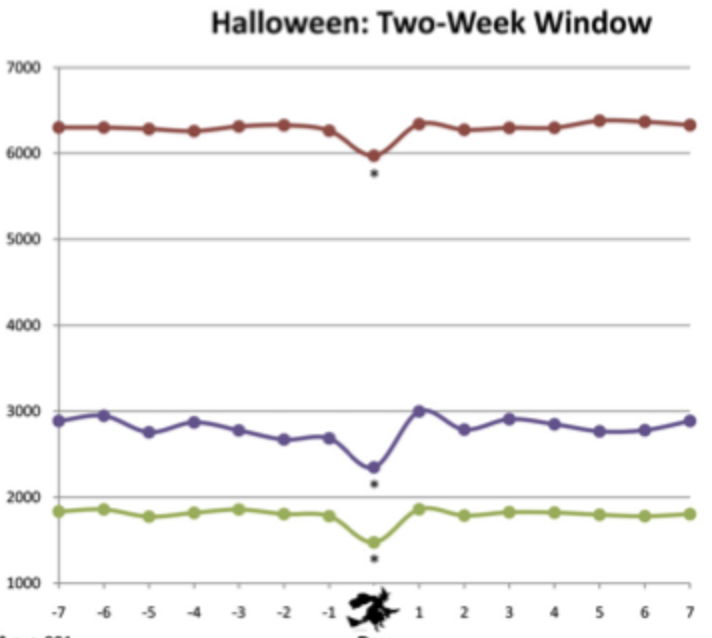
This is Jessica. There have been a few interesting articles in the past couple weeks that point to evaluation blind spots in LLM evaluation. One is this explainer article from OpenAI on why they withdrew their late April update to GPT-4o. It’s worth reading if you aren’t familiar with the kinds of adjustments these models undergo after pre-training. While many concrete details are lacking, they give an overview of their evaluation approach, which involves combining different types of reward signals (e.g., fine tuning on good examples, adjusting the model’s reward distribution to match preferences elicited from humans and ChatGPT), various safety checks, offline testing against benchmarks, and interactive “vibe checking” by experts aimed at getting a sense of how it feels to interact with the model in practice.
The recent model update was problematic they claim because it introduced inappropriate levels of sycophancy (including “validating doubts, fuelling anger, urging impulsive actions” etc). The article attributes this mistake to their decision to de-prioritize results of the vibe checking done by experts, some of which had suggested something being off about the model. Leading up to this release, signals about general model behavior and personality (which the vibe-check evals are about) were not “launch-blocking” the way safety tests for things that might cause catastrophic risks were. So they went forward on the grounds that the model looked good on these other tests.
They also suggest that several changes to the reward signals in the post-training process contributed to the increased sycophancy:
In the April 25th model update, we had candidate improvements to better incorporate user feedback, memory, and fresher data, among others. … For example, the update introduced an additional reward signal based on user feedback—thumbs-up and thumbs-down data from ChatGPT. This signal is often useful; a thumbs-down usually means something went wrong.
But we believe in aggregate, these changes weakened the influence of our primary reward signal, which had been holding sycophancy in check.
AI safety concerns are hard to separate from model behavior in general
There are a few things I find interesting in this. First, it strikes me as being kind of naive and behind the times on an epistemological level to assume that behavior and personality can be separated from other safety risks. There has been plenty of public discussion at this point about the potential for large language models to persuade people to believe things that aren’t true, and evidence that this is already happening. More generally, it seems like it should be common knowledge that small shifts in complex system dynamics can throw things out of whack in ways that become significant. It’s weird to think that OpenAI somehow still saw these behavioral risks as less pressing than the possibility of cyberattacks or the creation of bioweapons. It suggests a mismatch between how OpenAI (and perhaps the AI community more broadly) sees (or wants to see) what they are doing and where the models are these days. The article mentions, for example, that they had not originally expected the models to be used as much as they are for emotional support. I wonder if overlooking the change in sychophancy is partly a result of their not wanting to acknowledge these use cases because they don’t fit some preferred narrative of the models as superintelligent agents capable of strategizing or reasoning beyond human abilities.
On the other hand, hindsight is always 20-20, and it is naturally going to be harder to predict the impacts of changes to a model’s tone or personality than it is to predict what could go wrong if it supplies specific harmful information. From this perspective it’s less surprising to hear that their evaluation approach was underprepared to catch subtle but potentially harmful shifts in behavior like sycophancy.
Going forward, they say that signals of general model behavior will have launch-blocking potential. This implies that AI safety really subsumes all model behavior, which seems right. If LLMs provide a new kind of primitive or basic interface to computing, which I would argue is the right way to think about them, then it’s hard to argue that a few narrow use cases should take precedence.
Post-hoc alignment with human values is a messy game of heuristics
The fact that incorporating new reward signals that they thought would be helpful threw the model out of whack makes clear what a delicate, heuristic-layering process posthoc adjustments to align model behavior with human values are. It’s impressive that these kinds of approaches have worked as well as they have. But from the standpoint of evaluation, is there any way out of getting stuck in a kind of whack-a-mole game, where every time some new kind of feedback is introduced in the posthoc tuning process, the entire model surface must be re-surveyed for new types of vulnerabilities or risks? Is there really some final uber state of evaluation that will be reached through this process, where all potentially harmful aspects of model behavior can be checked and therefore controlled? Or will the criteria themselves keep shifting as the use cases change, making these kinds of “woopsies” model updates inevitable?
It makes me wonder as well about the stability of the signals that are being elicited. Human experts using a model may be more robust evaluation instruments than benchmark-style evaluations or crowd-based preference feedback when it comes to picking up on subtle shifts in behavior, but it’s not clear to me that we should expect people’s judgments about the appropriateness of model personality or changes in behaviors like sycophancy to be a) stable and b) informative about the actual riskiness of model updates. I would expect human appraisals of what’s appropriate to shift with our emerging understanding of what these models can and cannot do, and to be idiosyncratic to some degree. It seems hard to assess the value of subtle behavioral shifts outside of some specific downstream task, but there are so many downstream tasks. So I wonder if evaluation noise is something inherent because the eval targets are themselves poorly defined.
Beneath all of this there is also the incentive issue of needing to create a model that feels pleasant enough to use to keep people coming back while also avoiding the dark side of people being vulnerable to flattery and preferring to believe things that align with their beliefs more than reality. I guess I’m wondering how far can we really expect to take a philosophy of alignment based on applying a bunch of patches posthoc before it backfires due to people being poor judges of what is good for them.
P.S. Right after posting I saw this Rolling Stone article, which talks about chatbot-based emotional support on a whole different level. Apparently delusion is no longer available only to those mentally afflicted. Now we can democratize it too.