The other day, Connor Gilroy, Shira Mitchell, David Shor, and Jonathan Tannen posted a detailed discussion of the challenges of learning about the political preferences of nonvoters, marginal voters, and groups such as young voters who rarely answer opinion polls. Their post was relevant to a discussion we had last month of the political attitudes of nonvoters.
As I wrote at the time, the real interest for campaigns is not nonvoters but rather marginal voters: the people who might be persuaded or dissuaded from voting. Comparing nonvoters to voters is interesting, but marginal voters could well differ from the mass of nonvoters or even the mass of registered voters. Gilroy et al. work at Blue Rose Research, where they have access to some sort of “voter file” that has enough information that they should be able to get a good sense of who the marginal voters are; still, as they explain in their post, a lot of uncertainty about this group remains, especially considering that, strictly speaking, there is no such thing as a marginal voter: your level of “marginality” depends on the campaign itself.
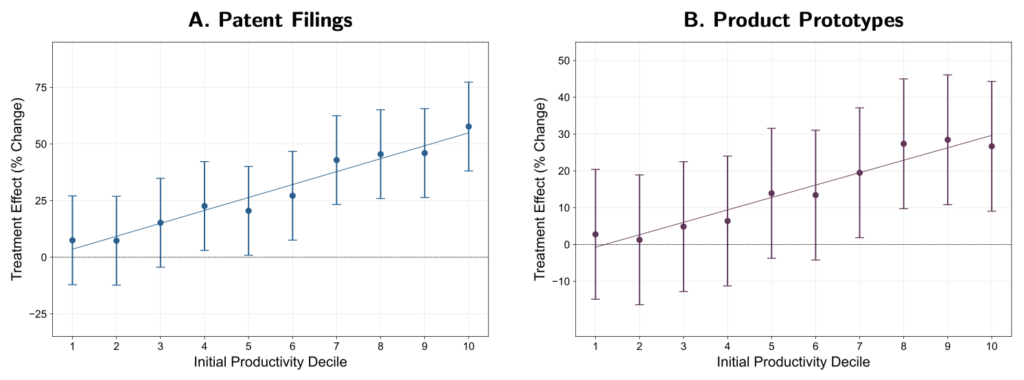
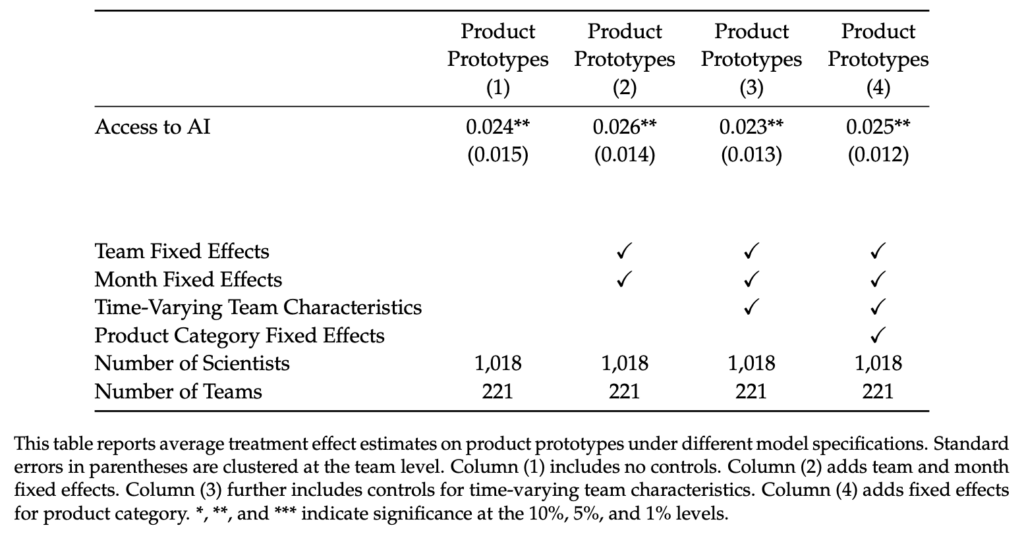
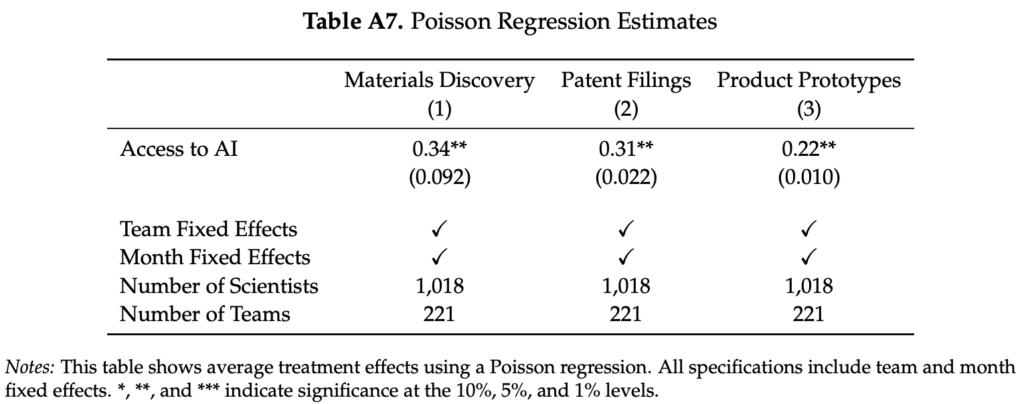
Another firm that uses the voter file is Catalist, which just released their scheduled post-election report. Yair Ghitza, Haris Aqeel, and Josh Yazman write:
Catalist’s What Happened reports offer a comprehensive voter-file based view of the electorate after every major presidential and midterm election. Our 2024 report is based on publicly available vote history data and precinct-level election results from every state . . . as well as Census data, and Catalist’s proprietary modeling and polling, which are all used to estimate the composition and partisan leanings of the electorate from the precinct to the national level.
Here are their key findings:
Turnout remained high, especially in battleground states, and especially in Republican areas. National turnout was 64% of the voter eligible population, nearly matching 2020’s historic turnout. In the seven major battleground states turnout was more than 70%, exceeding both the national turnout rate and the battleground state turnout rate for 2020. Even though turnout was high overall, there were differences between groups. Turnout in Republican areas dropped less than in Democratic areas across both battleground and non-battleground states, and turnout remained higher for white voters than voters of color.
Many voters changed their partisan preferences, from supporting Biden in 2020 to Trump in 2024. . . . Shifts in turnout and shifts in voters’ partisan preferences both contributed to the final election outcome and these trends relate to one another across demographic groups and subgroups.
Harris continued to do well among voters who have consistently participated in elections. . . .
The major trends against Democrats in the election were mitigated in the battleground states – turnout was higher, support losses were lessened – which may be related to higher levels of campaign activity and more frequent election participation in these states.
Voters of color continue to support Democrats, but support has dropped successively over the past three presidential elections. . . . Democratic support has continued to erode among voters of color. Drops from 2020 to 2024 were highest among Latino voters (9 points in support), lowest among Black voters (3 points), and 4 points for Asian and Pacific Islander groups (AAPI). Support drops were 5 to 6 points among “Other” voters . . . As with other demographic groups, support drops were concentrated among the younger cohorts of voters, particularly young men. For instance, support among young Black men dropped from 85% to 75% and support among young Latino men dropped from 63% to 47%.
White voters remained over 72% of voters, the same as 2020, and Harris also lost support among some of these voters. . . . concentrated among specific sets of white voters – irregular voters, young voters, and men. Harris also saw support drops among white men with a college degree.
The partisan gender gap remains high and grew in 2024. . . .
After years of historically high support among Democrats, a significant share of young voters swung toward Republicans. Voters under the age of 30 dropped from 61% Democratic support in 2020 to 55% in 2024. Similar support drops are evident when examining voters by generational cohorts, such as Gen Z or Millennials. These drops were larger than drops for any other generation or age group, and other trends in the demographic data, such as drops among different racial groups and the gender gap, were more pronounced among young voters than the rest of the electorate.
Education polarization remains high, but decreased slightly in 2024. . . .
The urban-rural divide remains strong, but Democrats did worse in cities in 2024. . . . These drops are related to other trends in the data, particularly the drops in Democratic turnout in major metropolitan areas.
They summarize:
Harris lost in 2024 due to a combination of support and turnout drops among key groups, particularly “rotating voters.” The nature of Democratic coalitions is different from Republican coalitions. In recent years, successful Democratic elections have seen a combination of (1) support shifts towards the Democrats among core regular voters, and (2) a consistent refresh of new voters that lean towards Democrats – including young people, voters of color, urban voters, and people who move regularly. In 2024, Harris lost support among presidential repeat voters, meaning those who also voted in 2020, and the new set of “rotating Democrats” did not materialize as they had in previous elections. . . . these groups of voters overlap in many ways and we discuss the strategic implications of this data and how campaigns engage voters along a variety of interrelated channels that go beyond simple “mobilization” or “persuasion.”
And they supply some graphs:
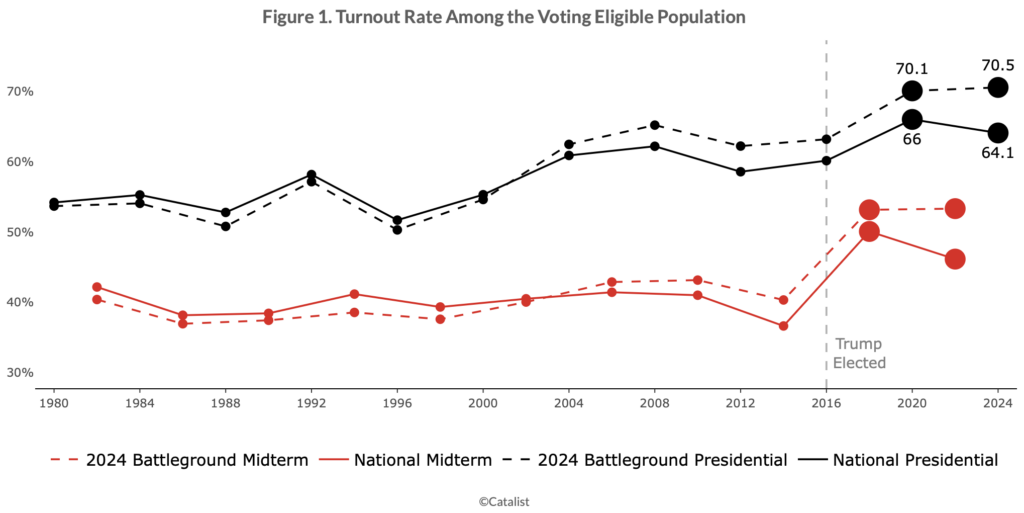

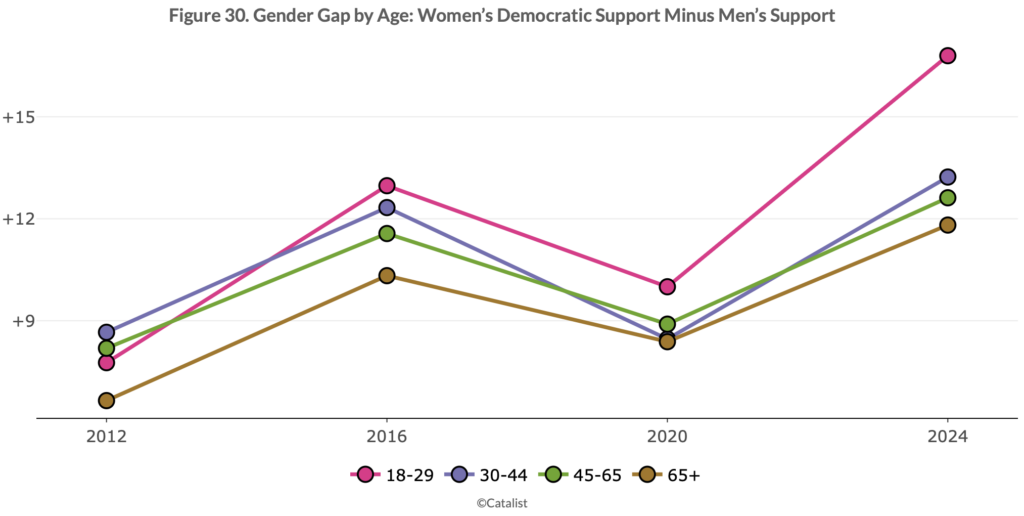
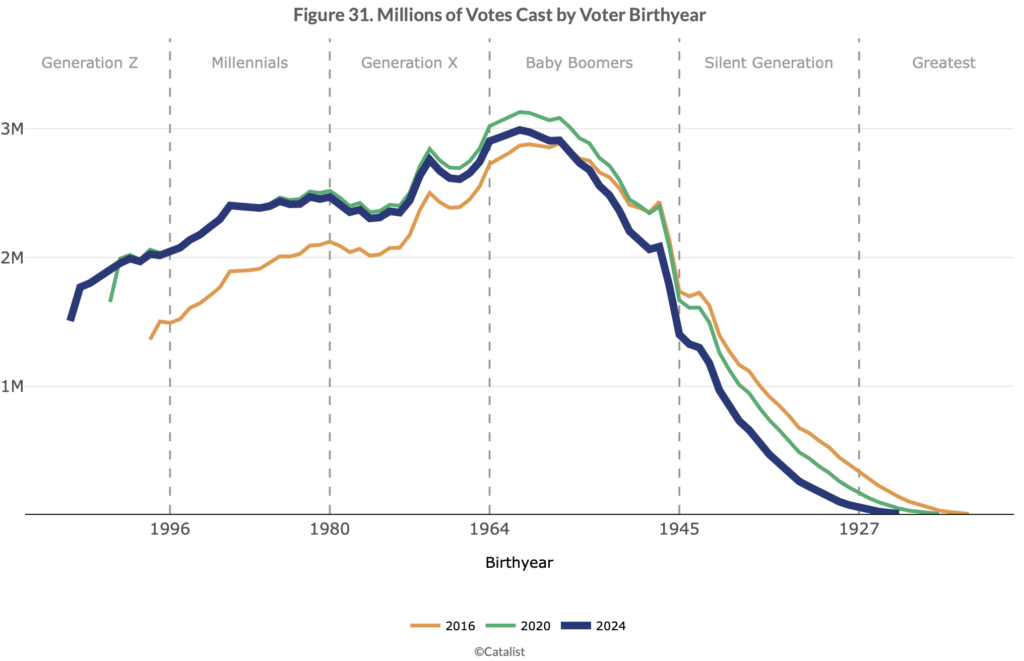
Lots more at the link.
For comparison, here are some previous reports:
Reflections on the recent election
What happened in the 2022 elections
What Happened in the 2018 Election
“What Happened Next Tuesday: A New Way To Understand Election Results”
“2010: What happened?” in light of 2018
Wanna know what happened in 2016? We got a ton of graphs for you.