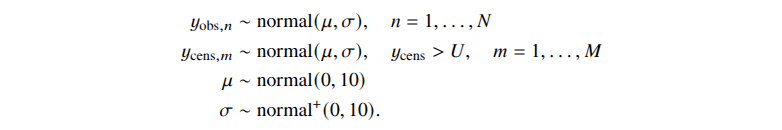The Journal of the American Medical Association recently contacted me to ask for a comment on a recent Draft Guidance for Industry from the U.S. Food and Drug Administration on the use of Bayesian methodology in clinical trials of drug and biological products.
I’ve recently been doing a lot of work with Erik van Zwet and Witold Więcek–we meet every week and we’re writing a bunch of papers related to statistical inference and decision making, especially for clinical trials (our two completed papers are Meta-analysis with a single study and A statistical case for qualified scientific optimism) so I invited them to join in writing this. Erik is a biostatistician who works with clinical researchers all the time, and Witold’s involved in policy analysis, also he posted on the FDA draft guidance back when it appeared in January.
What with all the bad things going down at the U.S. Department of Health and Human Services, I was ready to get riled up–also there was this problematic document from HHS back in 2015–but actually this new Draft Guidance for Industry was just fine, very serious and professional. I guess the clowns at HHS were too busy doing pushups or whatever to interfere with this one.
So, Witold, Erik, and I wrote this short article for JAMA. The review process was smooth. The journal was on a tight schedule so we submitted our first version right away, while simultaneously sending it to several colleagues who made various useful suggestions, which we implemented for our revision. Our first version was too technical for JAMA–maybe we’ll put it into another article–so we were able to cut to the required length.
I’m happy with our final version, and here it is:

Some of our key points:
The prior is sometimes described as a subjective belief, but the FDA guidance frames it as pre-study information, which we think is a good framing. The formal and transparent incorporation of prior knowledge into the design and analysis of trials is the main advantage of the Bayesian approach. The use of prior information, even if not in a formal Bayesian framework, is not new in the context of clinical trials. For example, it is used during the planning stage of a trial using traditional frequentist methods to determine the sample size. . . .
The guidance still insists on type I error control when Bayesian methods are used, but only when the prior is noninformative. We see the logic to this: Bayesian analysis with noninformative priors is functionally similar to a traditional frequentist analysis, and in these cases there is no compelling reason to break with the current paradigm. In contrast, when substantial prior information is available, the required assumption for defining type I error of no treatment effect may already be inconsistent with that prior information to some extent, invalidating the type I error rate as a meaningful design metric. . . .
We suggest two simple rules for Bayesian analysis of clinical trials: (1) the prior should be clearly stated and (2) readers and reviewers should be able to assess the prior’s influence on the result. . . . The guidance is right to stress the importance of justifying the prior. However, we also remind readers that it is just as critical to have a prespecified and valid data model. Both the prior and the data model should be scrutinized when the data arrive, and it may be necessary to revise either. We also applaud the recommendation that computations be evaluated using simulation studies: in the Bayesian framework, these would be posterior predictive checks, in silico replicated datasets simulated from the fitted model that are then compared with the observed data, with systematic discrepancies indicating problems with the model. . . .
Although often criticized as subjective, Bayesian approaches, when implemented transparently, can improve on informal principles of clinical judgment that often inform the current FDA model.
Two other discussions
Along with our article, JAMA ran two other comments on the FDA guidance:
– Embracing Bayesian Methods in Clinical Trials: FDA’s Long-Awaited Draft Guidance, by
Jack Lee, Frank Harrell, Lisa LaVange, and David Spiegelhalter.
– Reflections on FDA Draft Guidance on Bayesian Methods in Trials—Protecting Scientific Integrity and Evidentiary Standards, by Scott Evans, Thomas Fleming, Holly Janes, and Lori Dodd.
Both groups of authors have lots of experience on the statistical analysis of clinical trials, and both articles are thoughtful. I recommend reading them both.
Comments on the pro-Bayesian discussion by Lee et al.
Lee at al. share our general perspective, and their comment is usefully complementary to ours. We focus on priors, hierarchical modeling, and meta-analysis, while they go into more detail on the way that Bayesian methods connect to classical methods and existing regulatory approaches.
I only have three nits to pick on their article. First, they refer to “skeptical, optimistic, or noninformative prior distributions.” I’d like to clarify that there are too sorts of “skeptical prior.” One version of a skeptical prior is centered at a negative value, i.e., you assume the prior model in which the effect is more likely to be negative than positive, so that to get a positive estimated effect you need strong positive information from the new trial. The other version is centered at zero, which corresponds to a world in which most effects are small (as in the priors on the signal-to-noise ratio discussed here). By default with clinical trials we recommend that second sort of skeptical prior.
Second, Lee et al. write, “By contrast [to classical p-values and confidence intervals], Bayes tackles the real question of interest head-on and provides a direct answer to the question ‘Does the new drug or biologic work?’ by computing the probability of treatment benefit.” I get what they’re saying, but I don’t like the binary framing of whether something works or not. Effects will vary by person, across situations, and over time; there’s not really a stable effect or average effect, and even if we’re summarizing by an average, the question is not whether this average is different from zero or even whether it’s positive, but how large it is. Sure, you can take your Bayesian inference distribution and summarize it by the posterior probability that the average treatment effect is positive, but that’s just one thing to look at, and I think it’s a mistake to identify this as “the real question of interest.”
Third, for reasons I’ve discussed many times, I’m not happy with their use of the term, “prior belief”–unless they’re also willing to refer to other aspects of statistical models as “belief.”
But these are all just minor issues of emphasis. In practice I expect that Lee et al. are recommending the same sorts of Bayesian methods for design and analysis of clinical trials as we are.
Comments on the Bayes-wary discussion by Evans et al.
The article by Evans et al. expresses much more skeptical about the use of Bayesian methods for clinical trials. As noted above, I find their article to be thoughtful and it is worth reading. But they do say some things I disagree with.
The good news is that I think that some of their concerns can be directly addressed, and I hope that after reading my comments they will revise their view somewhat.
You might say that Evans et al. have a strong prior against Bayesian methods, and in this comment I’m sharing information that should shift their prior a bit. As a Bayesian, I can hardly complain that they have strong priors, and it’s my duty to provide arguments that they will view as convincing evidence.
Evans et al. conveniently provide a list of key points:

I’ll go through their five points in turn.
Item 1: I agree 100%. “Replicability, integrity, and reliability of evidence for disease treatment and prevention.”
Item 2: Again, I agree completely in this list of settings where Bayesian methods have been useful.
Item 4: Again, I agree! Transparency about all aspects of design, data collection, and modeling is absolutely necessary. This is the case for non-Bayesian method and for Bayesian approaches as well. I also agree that Bayesian inferences based on informative priors should be accompanied by results with noninformative priors or non-Bayesian estimates. It’s important to see the effect of the prior.
Item 5: Again, complete agreement. FDA guidance is crucial.
So it all comes down to item 3.
Item 3: They write that Bayesian methods “can compromise evidentiary and integrity standards.” I agree: any statistical method can be used inappropriately, and we should be aware of failure modes, especially in a high-stakes situation such as clinical trials. They list three concerns: “concession of the benefits of randomization,” “loss of objectivity by incorporating sponsor- or investigator-specific priors,” and “reduced robustness via reliance on strong and sometimes unverifiable assumptions.” I think they’re just wrong on the first of these items. We discuss the issue more fully in Bayesian Data Analysis (see chapter 8 of the third edition), but, just quickly, Bayesian analysis of clinical trials makes strong use of the benefits of randomization, as this is what allows you to set up a likelihood function corresponding to an unbiased estimate. I don’t see any concession of the benefits of randomization, in design or analysis. For their second item, yeah, if you put in a bad prior you can get a bad posterior, and that’s one reason we emphasize transparency in any statistical analysis. See the last paragraph of our article above. Finally, yes, I agree that Bayesian inference has additional assumptions beyond a classical analysis. I don’t think this “compromises evidentiary standards,” though! The prior is based on evidence too.
Let me put it another way. Sometimes you’ll have a nice clean trial, no problems with recruitment, dropout, or missing data, precise and well-targeted measurements, and a large enough sample size to get precise inference for endpoints of interest. You can do a Bayesian analysis if you want, but it won’t make much difference, and the classical confidence interval should be just fine. In other settings, your data are noisy, there are various sources of bias, you’re interested in small subgroups, and classical inferences aren’t enough. You’re in the position of making decisions based on incomplete information. And here the Bayesian approach can be helpful. Yes, additional assumptions are required–I’d like to frame that as, “additional information can be added to the analysis”–; that’s the price you pay for adjusting for bias and noise.
All this explains why I agree with Evans et al. that it’s good to compare any Bayesian inference to the (potentially biased and noisy) classical estimate, and it’s important to be transparent about all assumptions–including the past data and theory used to construct the prior. Data models can be constructed badly (for example, adjusting for age or smoking using binary indicator variables, or using curves that don’t fit the data, or not accounting for hierarchical structure), and priors can be constructed badly too (for example, by centering your prior from a noisy past estimate). Transparency doesn’t eliminate these problems but it should help us notice and correct them when they happen.
Summary
General caution by skeptics of Bayesian methods is valid and should be applied more generally, to all of our statistical models.
A useful analogy is to regression adjustment for experiments and observational studies. If your experiment is clean and your noise level is low, you might be able to get away with a simple treatment vs. control comparison with no adjustment. But in real-world studies there are a lot of reasons to adjust for pre-treatment predictors–it can help even in the simplest experimental settings. That said, it’s good to compare adjusted to unadjusted results and to understand your adjustment procedures as they get more complicated.
The reason for Bayesian methods in clinical trials is that classical methods are often not enough. It’s good to see these new FDA guidelines, and I think JAMA got some good discussions that should help move the ball forward.
P.S. There’s this funny thing . . . the JAMA style required us all to write “bayesian” as lower case. I told them this was nonstandard but they insisted on it. Weird, huh?
P.P.S. More here from Frank Harrell.