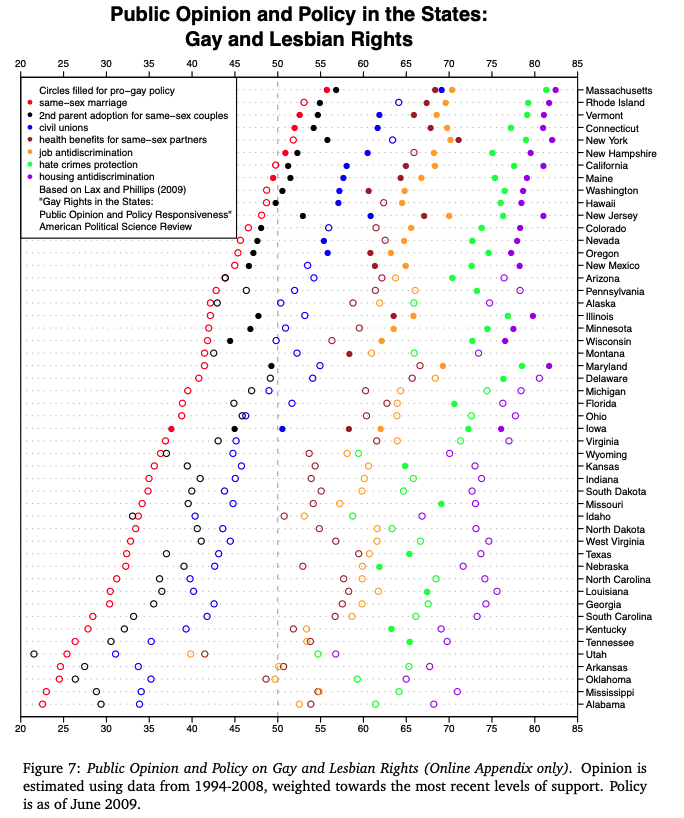
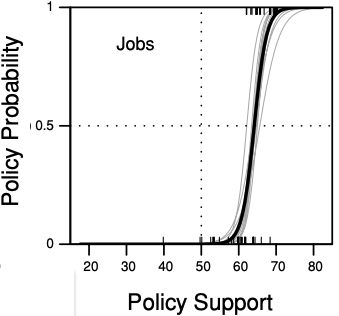
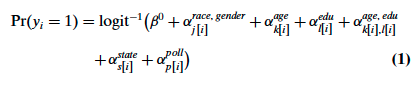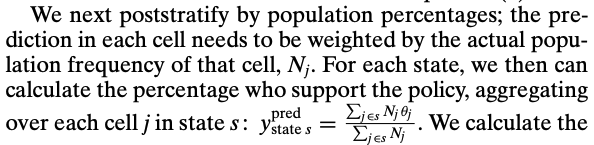This long post covers four topics:
1. The Knicks’ stunning series of come-from-behind victories to win the NBA title in 5 games;
2. The martingale property of probability forecasts;
3. An example of learning from simulation;
4. How we (sometimes) do research in probability and statistics.
I don’t know enough about this blog’s audience to know which of the four topics will appeal to most of you. For the internet as a whole, it’s #1; for most of you, it might be #3.
I’m interested in all four, which is why I’m writing this all up right now. I’m embarrassed to say that it took several hours to do this. I was originally planning to post this Sunday morning after the game but it took time for me to get to the task. Most of the effort came from writing the code, not from writing the text. And there’s actually not much code, as you can see if you scroll to the end of this post. The main effort was not figuring out the syntax or even debugging (although there was some of that) but in working out what I wanted to be coding in the first place.
On the plus side, this is research I’ve been wanting to do for awhile, so (a) I don’t think this effort is wasted, even beyond whatever educational and entertainment value if has for you, and (b) I learned a bit from this already. Looking at data is always good; experimenting with simulation is always good.
Ok, here goes.
The NBA finals
Hey, remember this, from game 4 of the recent NBA finals:

Or the trajectory of the game that came after:

Just for completeness, here are the traces for games 3, 2, and 1, also courtesy of ESPN:
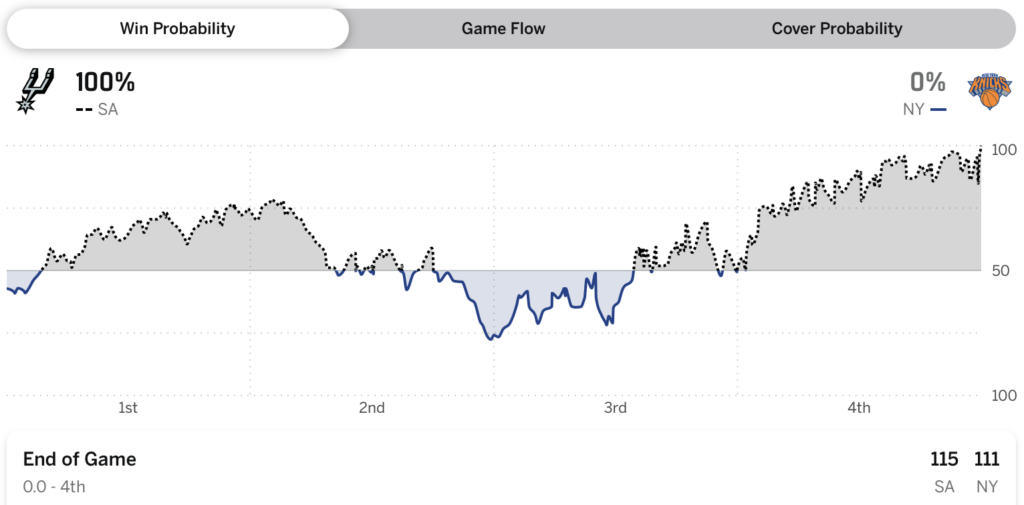
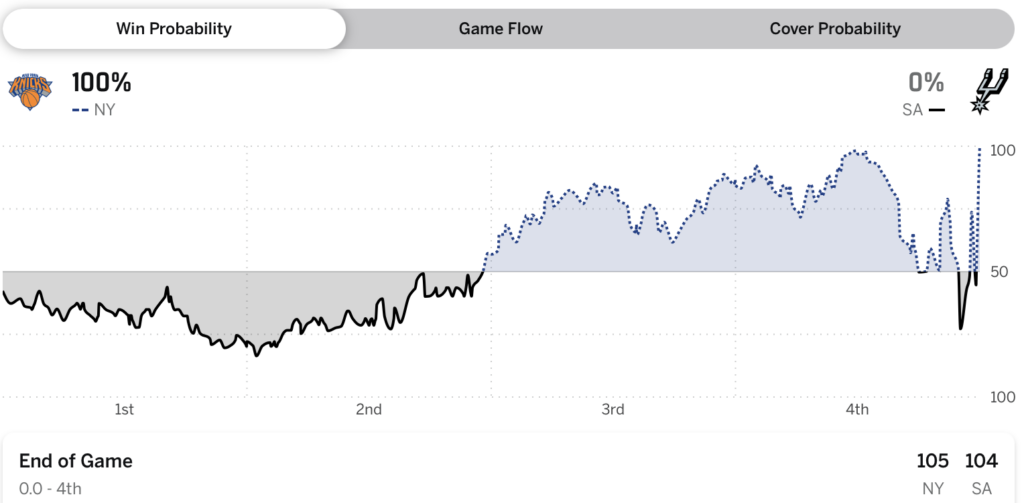

In game 4, the Spurs at one point were estimated to have a 99.6% chance of winning. But, as you might have heard, they lost.
Extreme win probabilities
Were those stated win probabilities too extreme?
On one hand, sure, unusual events happen on occasion. If you have a 0.4% chance of losing, that’s something that should happen 1 in 250 times, and there were a lot more than 250 basketball games just in this past season. On the other hand, very unusual event are supposed to happen only very rarely, and there was a point in the third quarter of game 4 where ESPN’s algorithm gave the Spurs a 97.1% chance of winning, a point in game 1 where the Spurs were given a 94.1% chance. There was a moment in game 2 where the Knicks were assigned a 98.2% chance of winning, and, sure, they did win that one, but given that the final score was 105-104, after being tied 97-97 and 104-104, it seems in retrospect that this 98.2% was a bit overconfident.
Should we be suspicious of these probabilities? One way to ask this question is to check calibration: if we collect all game situations where a team has a 99.6% of winning, are they winning 99.6% of the time?
On the other hand, I’m picking the most extreme values of these win probabilities. You should get calibration of win probabilities at any time, and it’s ok to condition on them, but only to condition on what came before.
That is, if we look at win probabilities at the end of the first quarter, or at the end of the first half, or at the end of the third quarter, they should be calibrated. And if you look only at win probabilities only when they’re greater than 99%, they should be calibrated. And if you look only at win probabilities when they are the maximum for the game so far, they should be calibrated. But it’s not clear to me that you should expect calibration for win probabilities selected to be the maximum for the entire game, because if the win probability at time t is p(t), and you condition on the event p(t) < p(t_0) for t > t_0, that could provide information. It’s tricky.
The martingale property of probability forecasts
We wrote about this in section 1.6 of our 2020 article, Information, incentives, and goals in election forecasts:


And it also came up in some blog posts:
from 2020: Do we really believe the Democrats have an 88% chance of winning the presidential election?
from 2020: More on martingale property of probabilistic forecasts and some other issues with our election model
from 2024: “Unusual Betting Patterns With Several Temple Games”: It’s martingale time, baby!
also from 2024: It’s martingale time, baby! How to evaluate probabilistic forecasts before the event happens? Rajiv Sethi has an idea. (Hint: it involves time series.)
I’d expect ESPN’s win probabilities to be closer to calibrated than prediction-market odds or model-based election forecasts. Prediction markets depend on the bettors and there’s no reason to expect calibration, at least not until the market is fully mature in some way. Model-based election forecasts are based on approximate models that have known pathologies (for example here), so they won’t be universally calibrated. ESPN’s probabilities won’t be calibrated either–they too are based on an imperfect model–but I assume it’s model has been trained on tons of data so I don’t think it should be far off.
If someone could send me the moment-by-moment estimated win probabilities from some large database of basketball games, we could take a look.
In the meantime we can get some intuition by simulating from a mathematical model where we can compute win probabilities exactly.
Simulating the process
Assume a simple Brownian motion with drift, where the score differential y(t) starts at y(0) = 0 and then takes a continuous random walk so that y(t) ~ normal(delta*t, sigma*sqrt(t)). We’ll scale t to be in minutes, so the game goes from t=0 to t=48, with the winner being determined by y(48). The drift is then delta=point_spread/48, because this is the expected final score differential before the game has started. And we’ll set sigma=2, which seems reasonable: 2*sqrt(48)=13.8, so that the sd of the final score differential is approximately 14 points.
One cool thing about this model is that the win probability can be trivially computed given the score differential at any point in the game.
How wrong can you be?
To demonstrate, I’ll show the results–the score and the win probability during the game–for 18 independently simulated games. For simplicity I’ll assume the point spread is 0, so the two teams are always assumed to be evenly matched. And I’ll step through the game 10 times per minute, thus approximating the game as a sum of 480 independent increments.
The code is below; here are the results:
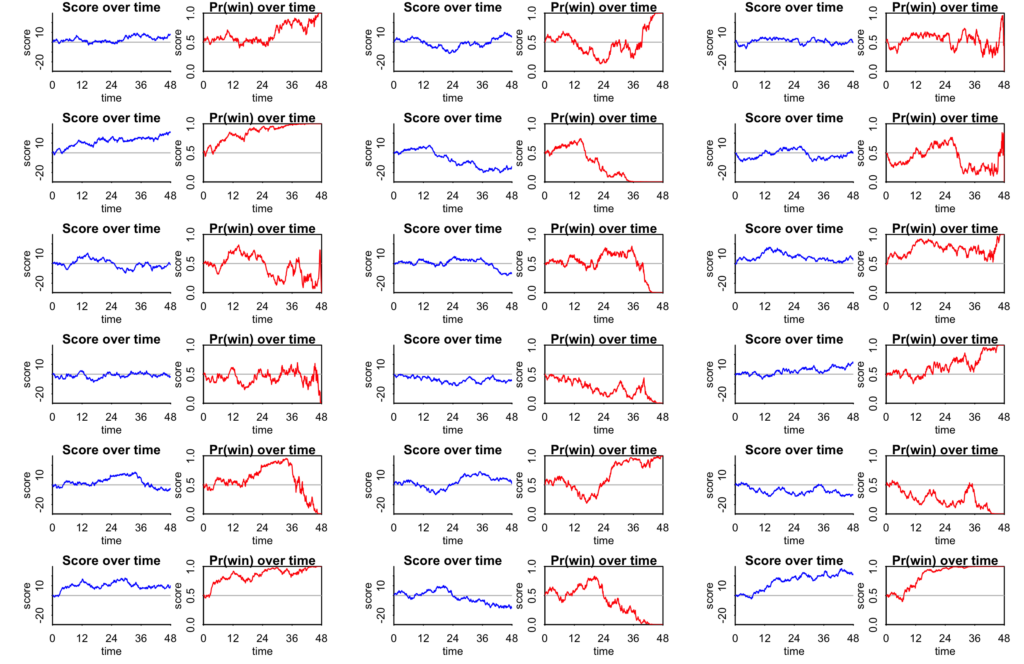
I don’t know enough about basketball to have a sense of how plausible these are as game outcomes (setting aside the lack of discreteness in the score; we used a continuous model so that we could more easily compute the relevant probabilities analytically). They don’t look too much like the Knicks-Spurs game except for that one simulation near the lower left of the plot, where the “Spurs” led by 10 points into the third quarter, maxing out with a win probability of 95.6% before eventually losing.
To get a broader picture, I simulated 10,000 games. (Just as a reference point, there are 30 NBA teams, so there are 82*30/2=1230 regular season games each year.)
For each game, I computed “max_p_wrong”: the highest win probability assigned to the game’s eventual loser. In my simulation, every game starts with a 50/50 probability–remember, for simplicity I’m always assuming a point spread of 0–so max_p_wrong must be somewhere between 0.5 and 1. Here’s what comes out:
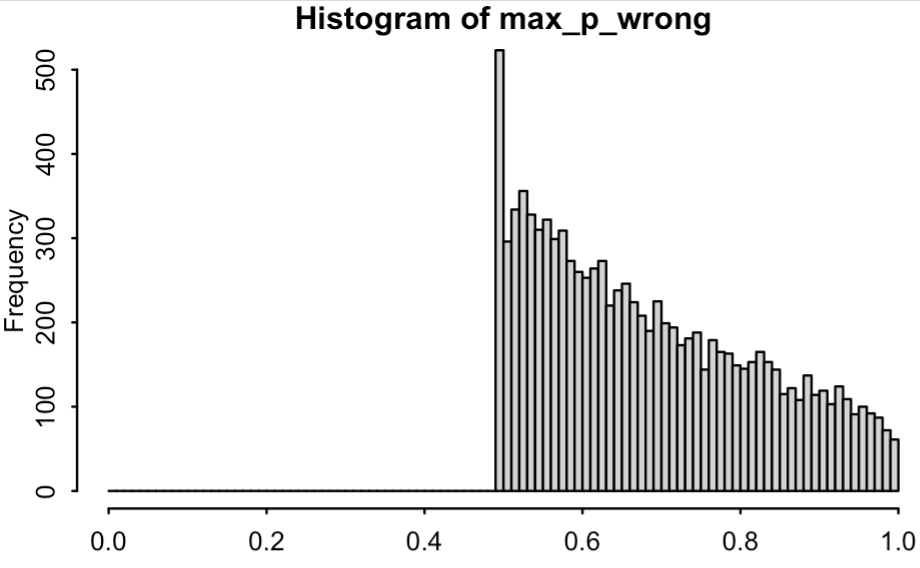
So, extreme wrong probabilities are not unheard of. How common are they? Out of these 10,000 games, 61 had max_p_wrong greater than 99%. That is, in 0.6% of games, the eventually-losing team exceeds the threshold of 99% win probability during some point in the game.
This result should go up if we move to continuous updating. But we’re already updating 10 times a minute. Increasing this schedule to 50 times a minute increases Pr(max_p_wrong > 0.99) to 0.0075, and increasing to 100 times a minute takes it to 0.0076, so my guess is that this is roughly the continuous limit.
OK, just to check, I’ll simulate 100,000 games, and now Pr(max_p_wrong > 0.99) is 0.0072 with 10 updates a minute, or 0.0084 with 50 updates per minute. So I’ll go out on a limb and say that if we were to compute the exact probability under continuous updating, we’d get 0.0085.
This was a surprise. Before doing this simulation, I was assuming that the probability of p_win exceeding 99% in for the eventual loser at any time in the game would be more than 1% because of selection. I guess my intuition was wrong. Maybe it has to do with the fact that I’m conditioning on which team wins. (Of course, if you go the other way, the probability of p_win exceeding 99% for the eventual winner is 100% in the continuous limit, because with epsilon of a second left in the game the winner will almost certainly be known.)
So, yeah, the above graph is kind of interesting. Under our model, most games won’t stray too far into retrospectively-embarrassing probability estimates, but it can happen sometimes.
It would be interesting to compare the above graph with what you’d get from a database of game-odds data from ESPN or whatever.
Just to be clear: there’s no reason to think that the above graph represents any sort of universal property of martingales. It’s a very specific model! But you have to start somewhere. Also, the existence of various central limit theorems makes me hold out the hope that this could be a general result under some appropriately restricted class of continuous martingale processes. It’s a research question!
A surprising uniform distribution
To get some further understanding of the process, I gathered the win probabilities after the end of each of the three quarters for the 10,000 simulated games. Below are histograms of these probabilities and calibration plots:

Unsurprisingly, the calibration is fine. After all, the probabilities are computed from the same model that the data are drawn from. Indeed, even the apparent anomaly in the lower-left plot is just a small-sample artifact which disappears when we up the number of simulations to 100,000.
More interesting are the histograms. It makes sense that, as the game goes on, the distribution of win probabilities starts at 0.5, then gradually bunches up at 0 and 1. Indeed, at the end of the fourth quarter the win probabilities are exactly 0 and 1.
But it’s funny how the distribution of win probabilities is exactly uniform at halftime. There must be a direct mathematical argument giving intuition for that result; it’s too perfect to just be an accident.
Lots more research to be done here:
– Generalizing beyond the continuous model to allow discrete scoring changes.
– Generalizing beyond the random walk; there’s no reason the model needs to be Markovian.
– Are there general statements that can be made about these distributions of win probabilities under arbitrary martingale processes? I’m guessing there are some results. At least, there should be some inequalities and limit theorems.
– Looking at real data from basketball, other sports, and other realms, including election forecasts and prediction markets.
Our ultimate aim here is to come up with a general measure of departure from the martingale property of probability forecasts. We want something that can be applied to any dataset, obviously with more precision as the series get longer, more finely-spaced in time, and when replications are available (as in those thousands of basketball games).
P.S. Here’s the R code to make the above simulations and graphs:
Continue reading →