I believe, as applied statisticians, we need to get our hands dirty and immerse ourselves in the applications we try to address. This post is mostly about medical ethics and the famous “first, do no harm” principle. It is also an attempt to understand how statistics can serve medical practice. The motivation for this comes from a recent debate in the statistics literature about counterfactual losses, which often invokes this “first, do no harm’’ principle as a motivation. Much has been written about the theory of these counterfactual losses — and I’m sure they will find a fruitful application — but do they actually speak to the challenge of medical decision-making that the “first, do no harm’’ principle seeks to address?
I will argue that they cannot, because this principle is concerned with medicine at its most human: medical practice centered on the relationship between an individual patient and an individual physician. But what can statistics help with? Modern medical obligations acknowledge that medicine is embedded in society; they highlight medical practitioners’ concern with justice and with reducing health disparities. These are concerns statistics can help to address.
But let me start at the beginning. There’s a recent literature that considers decision making under counterfactual loss — what if the utility of your decisions not only depends on the realized outcome but also on what could have been, on a counterfactual? A paradigmatic example is the following “first, do no harm’’ utility: Suppose you’re administering a drug and there are only two extreme outcomes. The patient may live, or they will die. The literature (e.g., Bordley, 2009, Ben-Michae et al., 2023, Christy and Kowalski, 2026) has interpreted the medical aphorism “first, do no harm” as requiring a utility function that assigns asymmetric weights to saving a life and causing a patient’s death. The disutility from killing a patient who, counterfactually, would have survived outweighs the positive utility of saving a patient who otherwise would have died. Although this may initially seem attractive, several authors have pointed out complications that arise when decisions are based on such counterfactual losses (e.g., Dawid and Senn, 2023, Sarvet and Stensrud, 2023).
Andrew and I contributed to this literature with a small example that seemingly produces a counterintuitive recommendation, which I discuss below.
In response, Koch and co-authors write:
[T]his seemingly nonsensical result can be reasonable in a different setting. […] It may be reasonable for a physician to prefer standard care, prioritizing the avoidance of adverse counterfactual outcomes over improvements in expected benefits. Indeed, such a decision reflects the Hippocratic principle of “do no harm”. […] This example underscores the fact that a utility function represents the preferences of the decision-maker and is therefore inherently subjective and context-dependent.
This uncovers a problem with our argument based on intuition — see, this decision doesn’t make sense, does it? Intuition, of course, can be misleading. One way our example might be misleading, as Koch et al. point out, is that it may describes a setting in which we simply do not hold these counterfactual utilities. If we were to transplant the same recommendation into an appropriate setting, it might no longer appear nonsensical and might instead conform to how we think we should behave.
This has me very excited. I believe statistics is at its best when it takes its applications seriously. So, in this blog post, I want to do just that.
I will briefly give the example Andrew and I came up with to show that a “do no harm’’ utility can lead to counterintuitive decision recommendations. We do so through an example involving Russian roulette. It is a useful example, but by no means an accurate representation of what we would consider plausible in real medical settings. What it does show, however, is that we need to be really careful with these “do no harm’’ utilities: if we don’t really hold them, they may lead to nonsensical decisions.
Taking the application seriously, we will dive into medical ethics to ask whether the proposed counterfactual “do no harm” utilities help with medical decisions. We do so by briefly examining the origin and history of the “first, do no harm” principle. We will see that “do no harm” is perhaps best understood in the context of a professional ethic that commits physicians to the rules of their craft and to respect for each individual patient. Statistics cannot truly speak to this individual-level patient-physician relationship. Since the Hippocratic Oath, however, medicine has changed substantially. With the advent of scientific methods in clinical medicine, doctors face new moral obligations not captured by the “do no harm’’ principle. Some of these new obligations arise from the relationship among medicine and society; others arise from the use of scientific methods themselves. We will look at modern medical oaths to get a glimpse of these new obligations — and how statistics can help fulfill them.
Russian Roulette
As a starting point, let me present our simple and somewhat morbid example in which counterfactual utilities give a counterintuitive decision recommendation: Imagine we are choosing between two games of Russian roulette. In the first game, the status quo, we play with a six-chamber gun, one chamber of which is loaded. That is, we face a one-in-six chance of death. We are then offered the option to switch to a seven-chamber gun, the new alternative “treatment.” If we switch, we face better odds: only a one-in-seven chance of dying. By switching games, we lower our probability of death, which to me seems preferable.
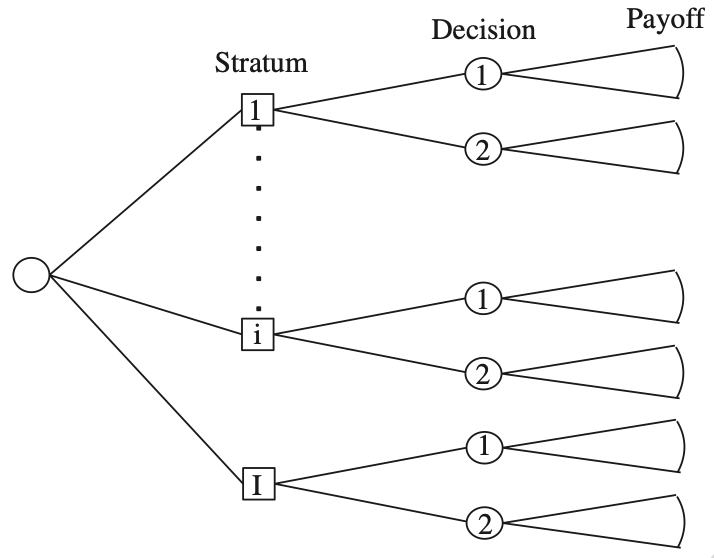
What would the counterfactual “do no harm’’ utility function recommend? To figure this out, we treat the outcomes under either game of Russian roulette as (independent) potential outcomes and divide the population of players into four principal strata based on survival status. Only two of the principal strata are relevant for our decision, those in which a player would survive one game but die playing the other. It’s easy to work out that with probability 6/42 switching to the new gun saves you: you would die under the status quo but survive under the treatment. But with probability 5/42, you would have survived under the status quo, but switching to the new gun, you will die. Suppose we interpret “first, do no harm’’ as mandating that the negative repercussions of our treatment choice, the death of a player, outweigh the benefits of saving a life. For example, suppose saving a life has utility +1, while the death of a player has utility −2. Then the 6/42 chance that the treatment saves you is outweighed by the 5/42 chance that the treatment kills you in cases where, counterfactually, you would have lived.
Under this counterfactual utility, we ought not to switch. It recommends we stick to the status quo, under which we face a higher chance of death. This strikes me as a counterintuitive decision recommendation.
The “First, do no harm” Principle
There is, however, a limit to the force of this argument based on intuition. One might argue that the recommendation in the Russian roulette example is not evidence against counterfactual utilities in general, but rather an indication that, when playing Russian roulette, we do not hold utilities of this kind. When transplanted to a setting where we have such asymmetric counterfactual utilities, the same recommendation might be sensible. The counterfactual-utility literature often motivates asymmetric counterfactual utilities by appealing to the “first, do no harm’’ principle in medicine.
For the rest of this post, I will discuss whether counterfactual utilities are useful in this paradigmatic application: medical decision-making.
In a paper frequently cited by advocates of counterfactual utilities, Cedric Smith (2005) discusses the origin and limitations of the “first, do no harm” principle. It is actually not part of the Hippocratic Oath, or the wider Hippocratic corpus, as is often implied, but has somewhat nebulous roots. Smith traces its origin to the seventeenth-century English physician Thomas Sydenham. While undoubtedly catchy, this principle is not embedded in a larger ethical framework that would give guidance on its interpretation or justifications for its use.
The is a problem because taken literally, this “first, do no harm’’ principle is a poor guide to medical decision-making. Let me cite Louis Lasagna, an American physician of the last century who was very involved in rethinking the Hippocratic Oath:
“To observe this advice [first, do no harm] literally is to deny important therapy to everyone, since only inert nostrums [quack medicine without active pharmaceutical ingredients] can be guaranteed to do no harm. It is more reasonable to ask doctors to balance the potential gains against the possible harm; would that we could only quantify these probabilities more precisely!” (Lasagna cited in Smith, 2005)
A call to action for us statisticians if I ever saw one. Of course, the counterfactual-utility literature that cites this principle is not advocating what Lasagna warns against: doing absolutely no harm. Its proponents are well aware that benefits and risks must be carefully weighed against each other. If the principle is not meant to be taken literally, then its obscure origin becomes a problem: it gives us little insight into what actually matters to medical practitioners, because it is disconnected from any wider tradition that would help us interpret it.
Luckily, we can find a similar, more nuanced statement in the Hippocratic corpus (Epidemics I):
“Declare the past, recognize the present, foretell the future: attend to these things. As to diseases, make a habit of two things—to help, or at least to do no harm. The art has three factors, the disease, the patient, the physician. The physician is the servant of the art.”
The Greek word here is technē (orig. τέχνη) which we might also want to translate as “craft”. Medicine is a craft because the decisions a physician has to face cannot be made by rote application of knowledge. As a craftsperson, the physician as an individual becomes relevant. That is why the Hippocratic Oath commits the physician, as an individual, to be benevolent in each patient interaction. Medical ethics based on the Hippocratic Oath is not focused on outcomes, let alone utility, but concerned with the character of the physician and their obligations toward their patient (Pellegrino, 2006). It centers the patient-physician relationship.
With this background in mind, we can understand why the “benevolence” implied in the imperative to help is qualified with the phrase ‘’or at least do no harm’’ — if I’m already committed to help, it may seem that I’m already committed to do no harm. Lynn Jansen (2022) argues that this is where the professional aspect of medicine enters: As a professional, the physician needs to restrict their actions to those that align with their profession. That is, while they strive for benevolence in the sense of furthering the patient’s overall well-being, they reject all courses of action that would harm the patient’s medical well-being. This second aspect is often called non-maleficence.
Statistics and Medicine
In modern medicine, this tension is heightened. Taking the patient’s moral agency seriously, a physician must be careful not to “confuse technical with moral authority” (Pellegrino, 2006) or override patients’ values. This is worth keeping in mind. The patient must be involved in weighing benefits and risks. Thus, the medical professional does not have sole discretion to choose an optimal treatment. “Help, or at least do no harm” is a professional mantra that guides a physician in their interactions with patients. It is not a constraint on optimal decision-making; it is a moral commitment to respect each patient.
This conception of medicine is in stark contrast to the world seen through the lens of statistics. Compare this focus on the individuality of both patient and physician with the following quotation from an 1835 report to the Academy of Sciences, written by a committee of four mathematicians, including Poisson, on operations for gallstones:
“In statistical affairs … the first care before all else is to lose sight of the man taken in isolation in order to consider him only as a fraction of the species. It is necessary to strip him of his individuality to arrive at the elimination of all accidental effects that individuality can introduce into the question.” (taken from Hacking, 1990)
Statistics’ power lies in constructing aggregates, making disparate things hold together (Desrosières, 1998). Historically, these aggregates were useful for the emerging nation-state and were quickly adopted to address large-scale social problems, such as public health. Many professions, including medicine, strongly resisted losing sight of the particular – in our case, the individual patient — in favor of aggregates. Even randomized experiments, which we nowadays all too easily accept as the gold standard of evidence, had a hard time entering clinical medicine (Porter, 2020).
Due to this tension, modern medicine has a dual nature. On the one hand, doctors are still committed to treating their patients as individuals — medicine is the art of healing. Yet with advances of scientific methods within medicine, and with the recognition that health must be understood in the context of society, doctors face new moral obligations (Pellegrino, 2006).
Modern Medical Oaths
To get a glimpse of these new obligations and the self-understanding of doctors in the twenty-first-century, we can look to modern versions of medical oaths. While many doctors still take the ancient Hippocratic Oath, many medical schools revise the original text or students take an additional self-formulated oath. In 2005, for example, students at Weill Cornell Medical College began taking a revised Hippocratic Oath. Let me highlight a brief excerpt:
I vow […]
That above all else I will serve the highest interests of my patients through the practice of my science and my art; That I will be an advocate for patients in need and strive for justice in the care of the sick.
Notice the emphasis on justice; it’s not idiosyncratic to this oath. Two further examples show similar themes. The University of Pittsburgh School of Medicine’s class of 2024 took an oath that highlighted the social determinants of health and advocated for a more equitable health care system. Harvard Medical School’s class of 2019 vowed to combat structural oppression and promote social justice. In this admittedly selective set of examples, much emphasis is placed on how medicine relates to society. Core commitments are justice and the building of an equitable health care system.
So, how can we statisticians help modern medical practice? Modern medical ethics places great emphasis on patients’ autonomy and their freedom to choose based on their own values. For a patient’s decision to be well informed, deliberation about benefits and risks is central — but the decision ultimately depends on a personal tradeoff shaped by the patient’s values. For this reason, our goal should perhaps not be to optimize treatment decisions. We do need to help estimate the benefits and risks of treatments more accurately, but treatment decisions remain part of the individual patient-physician relationship. Instead, we should put more emphasis on identifying and reducing disparities in the health care system, focusing on medicine as embedded in society. The most important task may not be deciding which drug to administer, but reducing inequalities in access to treatment in the first place. I believe statistics has an important role to play in making health care systems more equitable and more just.