OK, enough about coronavirus. Time to talk about the election.
Dhruv Madeka starts things off with this email:
Someone just forwarded me your election model (with Elliott Morris and Merlin Heidemanns) for the Economist. I noticed Biden was already at 84%. I wrote a few years ago about how the time to election factors a lot into the uncertainty – basically more clock time till the election means there’s more clock time for really random things to happen (Biden gets Covid, something crazy is released about him like the second Comey letter etc).
For the 2016 Bloomberg model – we used a linear increase in variance for the time to election, though something more elaborate might help!
Nassim Taleb and I also followed up on this later on to explain that FiveThirtyEight’s forecast violated certain probabilistic constraints (for being a forecast of the future).
Morris replies:
Our model has linearly increasing variance in the random walk, but the maximum amount of distance from time T to T+…..n is constrained by our prior forecast. That is to say that while the temporal error on the polls 300 days to Election Day has a 95% uncertainty interval close to 10 percentage points, our state priors at that distance are normally dispersed in a range closer to +/- 6, constraining to total error to a more reasonable range.
I know about your argument with Taleb against Nate. The whole thing frankly just seems pedantic to me. Lots of this stuff is just really unpredictable (especially pollster error) and black swan events don’t fit neatly into our models, even those with fat tails!
Madeka responds:
I agree that it might be pedantic – but the more uncertainty you have (black swan or clock time), the wider than distribution for the terminal point gets. So if you really did have just a simple brownian (sigma * random_walk – not to say its not way more complex in reality) model, the farther out you are + the more uncertainty you have, the terminal normal distribution with a large variance on the real line starts looking like a “uniform on the real line”. So the probability of being greater than any value becomes 0.5.
I guess our point beyond the martingale technicalities is that when there is a lot of uncertainty, the probabilities won’t move around a lot (typically they’ll be flat at some level, though anything but 0.5 seems suspect to me personally, the level can be say 84%). So if your model was to freeze or move slowly around 84%, that would make sense and be perfectly consistent.
But if more and more news came out, and you updated it – say there was a “scandal” for Biden and that dropped the probability to 52% for Biden and then back to 84% close to the election – I think Nassim and I would say, probabilities don’t behave like that, that it’s more likely a failure to capture the intrinsic time uncertainty of the problem. That was closer to our criticism of Nate: if there really was that much uncertainty (black swan or pollster or news or time) – the probability would have frozen. If you didn’t know, you’d say “I don’t know, it’s all really variable – I’m not going to bet on it”.
In finance terms, Biden winning is a binary option on the election date (more realistically, a basket of binary options) – so the more volatility there is, the closer to 0.5 the price gets.
The implied betting odds from Betfair are 53% for Biden, 40% for Trump, 2% for Mike Pence, 2% for Hillary Clinton (!), and another few percent for some other possible longshot replacements for Biden or Trump.
Right away, you can see that our model does not account for all possibilities, as we frame it as Biden vs. Trump, with the implicit understanding that it would be the Democrat vs. the Republican if either or both candidates are replaced.
But, setting that aside, these implied betting probabilities are much closer than our model, which is based on polls and forecasts.
Just to be clear: The Betfair odds don’t correspond to Biden getting 53% of the vote, they correspond to him having a 53% chance of winning, which in turn basically corresponds to the national election being a tossup.
So the prediction markets really do disagree with our forecast. And there’s nothing so special about our forecast; given the data we have now, I expect that just about every poll-based model will give similar predictions.
Madeka then elaborates on the betting odds:
The idea in a sequence of steps is this:
– If you’re publishing your forecasts, we assume theyre “proper” in the sense that youd be willing to bet on them. So if I gave you $1 for every $4 you put in if Biden won (let’s say you have Biden at 80%) youd be willing to take that. And the converse for Trump.
– If your forecast was too volatile, when you increased the probability for Trump in the future, we’d assume again that your posting was honest and that you’d be happy to sell us (say if you moved Trump to 40%) Trump at those odds. So the trade would go like this:
Today, Trump at 20%:
– bet $1, win $4 – Trump Wins
– take $1, pay $0.25 – Biden WinsTwo months from now, Trump at 40%:
– take $1, Pay $1.5 – Trump Wins
– bet $1, get $0.67 – Biden WinsIf you didn’t have volatility, or you absorbed at 100% – you’d be free from this. But in the scenario where you behaved like Silver in 2016, mean reverting up and down – we’d make money from you whether Trump or Biden won.
I guess what maybe pedantic is that the only sensible interpretation I can see for a single event forecast like an election is betting. You’re asking people to make decisions (say in the extreme case, move to Canada or Europe) based on these numbers – so they should be numbers you’re willing to bet on. That’s where the interpretation of the binary option and betting comes from – so having a super volatile forecast isn’t a great forecast, because once people identify that; they’ll trade against you.
My reply: I agree that betting is a model for probability, but it’s not the only model for probability. To put it another way: Yes, if I were planning to bet money on the election, I would bet using the odds that our model provided. And if I were planning to bet a lot of money on it, I guess I’d put more effort into the forecasting model and try to use more information in some way. But, even if I don’t plan to bet, I can still help to create the model as a public service, to allow other people to make sensible decisions. It’s like if I were a chef: I would want to make delicious food, but that doesn’t mean that I’m always hungry myself.
On the technical matter. I agree that it should be rare (but not impossible) for the election probabilities to swing wildly during the campaign.
Finally, regarding the statement: “If I gave you $1 for every $4 you put in if Biden won (lets say you have Biden at 80%) youd be willing to take that. And the converse for Trump”: Not quite. Don’t forget the vig. I can’t go around offering both sides of every bet without (a) getting takers on both sides and (b) having some sort of vig. Without (a) and (b), I’m vulnerable to getting taken out by someone with inside information.
The point is that, yes, if you have betting odds, these do translate into probabilities. But the reverse mapping is not so clear, as it involves actual economics.
Anyway, yes, I do believe our probabilities. They’re conditional on our model, and it seems like a reasonable model.
It’s possible that the model will have Trump at 40% chance of winning in 2 months, but I doubt it. My best guess of the probability we’ll have of a Trump win in 2 months is . . . the probability of a Trump win we have right now!
We had a couple more go-arounds on this, and a few more points came up.
Merlin writes:
The forecast partially pools the fundamentals based forecast with the polling based forecast. Essentially, the probability estimate walks toward the fundamentals based prediction. Increasing the diffusion term would allow it to get closer to it (higher uncertainty leading to lower weight in the polls based forecast relative to the fundamentals based forecast in the partial pooling for the prediction for Election Day).
I’ll add that it might be confusing to think of the forecast as a “prior.” This is not a prior, it’s a prediction from a fitted regression model. It’s only a prior in the sense that is the posterior from a previous analysis.
You might want a noninformative prior centered on 50/50. That’s fine. But we have some information. The president is unpopular and the economy is doing poorly. Historically this predicts a poor result for the incumbent in the election:
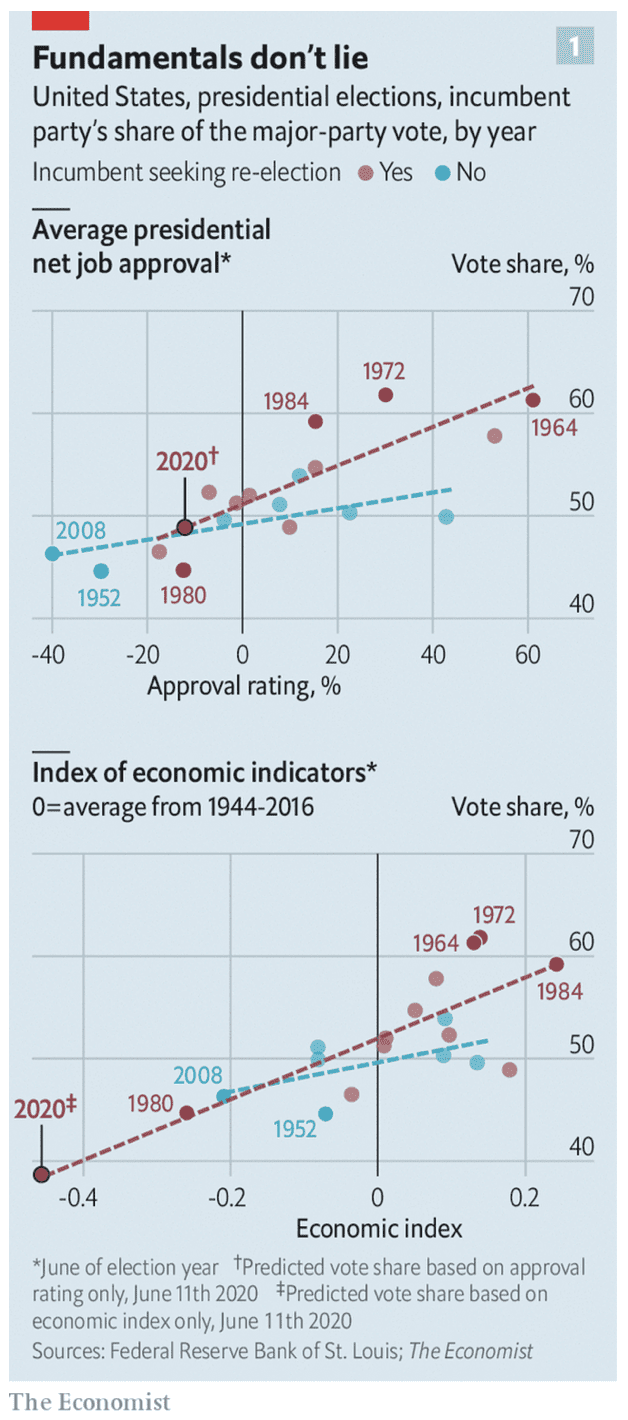
We could decrease the slope in our fitted regressions (thus making the election prediction less sensitive to presidential popularity and the state of the economy). Actually, we already did reduce the slope to account for polarization. I still don’t see it getting you to 45% chance of Trump winning.
Don’t forget, if you want a baseline, it’s that more people have voted for Democrats than Republicans in most of the past several national elections. To make a prediction of close to 50/50, you have to be really influenced by what happened in 2016. Which I think is happening with these bettors.
Madeka replies:
I guess the part that surprises me is that the model is so confident this far out – its only June. And that the uncertainty bands (for the ones you show – Popular vote) are basically constant-width till election day. That’s the part that makes me think that the forecast will jump as things happen.
We can dispute the market (trade if you like) – but I think the point goes back to my first email, if you think the probability wont move too much – that’s pretty consistent/good and we can disagree on the value.
I guess the question isn’t so much the point today as the dynamic going forward – if Biden drops/moves in the polls, how much does the probability move through time. I always liked Nassim’s picture in his paper:

To which Morris responds:
Again, this is because our election-day outcomes are being constrained by the poplar vote prediction. The “prices” won’t evolve over time like a traditional financial market because we have a really good way of telling what’s going to happen in the future—approval ratings, the economy and polarization are good predictors of election outcomes even this far out, so the resulting process in our forecast is not like a traditional random walk with linearly increasing error as we move away from election day.
To put it another way, the polls do provide information, and they’ll provide more information going forward, but the baseline from the model is a prediction of something like 54% +/- 3% of the vote for Biden, which translates into something like an 85% chance of him winning the electoral vote with the current lineup of states.
It’s good to be transparent here. If you want to go with the market odds rather than our probabilities, that’s fair enough; now you can figure out exactly what part of our model you think is wrong. The only reasonable way I can see you getting anywhere close to 50/50 odds is to center your popular-vote forecast around 51% rather than 53%. You can get there by saying that 2020 is kinda like a rerun of 2016, except the Republicans have the disadvantage of a bad economy and the advantage of incumbency. Say that these kinda balance out and there you go. But I don’t think they really balance out; see the graphs immediately above.
The bet
Suppose I were to lay $1000 on Biden right now. According to Betfair it seems that, if I win, I make a profit of $840:
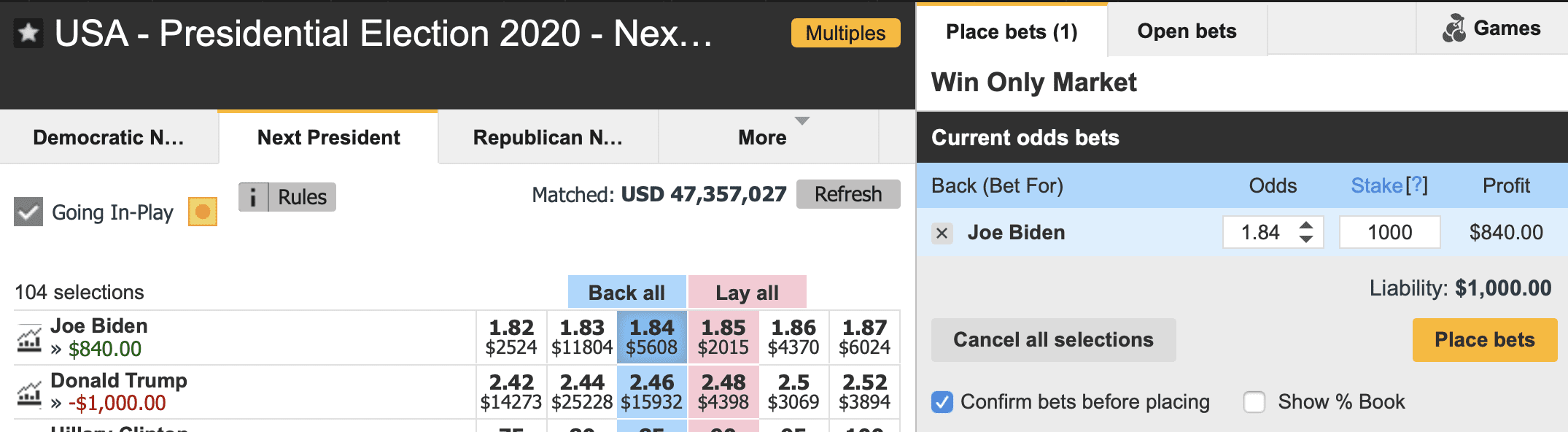
And our model gives Biden an 88% chance of winning. But we’re modeling Biden vs. Trump, whereas Betfair considers other possibilities, including replacements for the Democratic or Republican nominee. So let’s take our 88% down to 80% to account for those unmodeled outcomes.
My expected return from this $1000 bet is then 0.80 * $840 + 0.20 * (-$1000) = $472.
That’s pretty good—a 47% rate of return! That’s a pretty juicy investment.
I discussed this with Josh Miller and he pointed out that if you wanted to hedge this bet, you could just wait until Biden’s price goes up enough and then cover the bet in the opposite direction.
I’m not recommending you make this bet, or that you make any bet. Indeed, you could argue that this spread just shows that the bettors know more than we do. I don’t think so—I think the bettors are too influenced in their thinking by the 2016 outcome—but it’s hard to say more than that.
P.S. See here for a detailed explanation by Morris of the different components of our model.
Great post, thank you Andrew. I think we need much more explanations around counterfactuals like this and much less focused on horserace day to day movement.
Is it possible to apply this model to parallel data from 2016, and see what probability it would have assigned a Clinton electoral college victory at this point in time? If it’s anywhere near as high as 88%, then you can decide whether you really believe her loss was a 7 to 1 anomaly.
I suspect it would give her a lower probability, because the economy wasn’t as bad in 2016 and the incumbent was more popular. Also Biden seems to be polling a bit better right about now. Then again you had the party-running-for-a-third-term thing last time, which you don’t this time.
Mmm, brain fart. I meant it would give her a higher probability running on a stronger economy and succeeding a more popular incumbent. Biden polling better would suggest hers is lower. The succession thing is ambiguous because he’s running against a first-term incumbent, which is usually a losing proposition, but she was running to succeed a two-term incumbent, which is also usually a losing proposition.
Ram:
Yes, we’re planning to do this on a day-by-day basis for 2012 and 2016.
If the argument is that volatility in probability creates opportunities in a betting market, wouldn’t the same issue arise in real time sports betting? Probabilities, and thus betting odds, would be extremely volatile to change in score, time, etc. Are there opportunities for smart gambling plays in this scenario?
An:
Yes, I think. But this is the biggest opportunity I’ve seen—such a big gap between the empirical (as I see it) probability and the market odds.
Madeka and Taleb seem to want to encode into the probabilities more information than a single number.
There are two basic facts:
1. Based on information we have now, Biden is significantly favored to win
2. Estimates we make now are much less certain than estimates we’ll make in October
Their argument seems to be that one should encode 2 by taking a weighted average of the estimate of 1 with 50%
This just loses information, and makes it hard to distinguish (for example) between the situation in June 2020 vs June 2016 (where there is a real difference: https://twitter.com/boazbaraktcs/status/1273770640621948928?s=21 )
More generally, estimates that we produce with limited information and computation will never satisfy all the axioms of rationality, so it’s not surprising that the fluctuation of such estimates would create arbitrage opportunities. Trying to force these estimates to obey such axioms by fiat only makes them less useful.
+1 to Boaz’s points and, especially, to his linked twitter comparison of 2020 with 2016 — it communicates a lot of important information very simply.
Two things – from someone who can only follow a small portion of the technical discussion.
First, given that our country is so easily split along party identification, and has been for a long time. And given that ideological orientation is so explanatory for how people vote. Even with an understanding that party ID seems to be pretty volatile and can change in particular in association with the momentum provided from forecasts such as yours, I don’t see how it makes sense to make such a strong forecast. I certainly wouldn’t question your math…but it goes back to my baseline belief that math can only take you so far unless you can explicate a causal mechanism: In this case, how could you explain how we’d get so far away from the basic 50/50 split in how people vote in presidential elections. How would you get a result so far away from recent precendent?
Second, (somewhat related) I don’t understand how we could have much confidence in a prediction that has moved so far in just a couple of months? Trump’s basic polling has been quite stable for a long period of time, but even there, it just seems to me that relatively short-term swings in polling may well reflect events that drive short-term emotional responses but not really how people actually vote when they walk into a polling booth. Answering a question on a poll is a very different behavior than actually voting for someone. Actually voting for someone, it seems to me, is less likely to elicit a significant change in behavior like voting for a president from a different party than what you’ve done in the past. Much has been made of the Obama —> Trump voters – but my belief is that those were relatively rare (not saying there weren’t any). I think what we actually saw more of are many Obama voters who just didn’t vote in 2016, and people who typically didn’t vote coming out and voting for Trump. Without detailed evidence that is extremely hard to get in a reliable fashion (self-report on voting is unreliable), such a pattern would look from above very much like a lot of voters switching from Obama to Trump. Again, I just don’t think that there are that many people who are that volatile in their voting behaviors.
“… he pointed out that if you wanted to hedge this bet, you could just wait until Biden’s price goes up enough and then cover the bet in the opposite direction”
Umm… No. If that sort of thing worked, it would be really easy to make lots of money in the stock market.
It’s entirely possible that after you make your bet, Biden’s price will NEVER go up enough to let you hedge your bet.
If you believe in any form of the weak efficient market hypothesis, then you can’t make money trading stocks that way. The basic point is that election forecasting models often don’t appear obey a similar property rendering them suspect. Not saying that’s right or wrong but the whole claim is that election forecasts work differently than financial markets.
Radford:
Of course. This is all based on my understanding that the current posted odds are off. If I’m the one who’s off, I’m sunk in any case.
Radford:
As I predicted, the odds are shifting. At Betfair, a $1000 bet on Biden now returns $750, down a bit from the $840 when I wrote the above post a few days ago.
It’s now down to $710!
The betting markets do seem to move more slowly than 538-type forecasts. Even today, PredictIt is forecasting a 9% probability that someone other than Biden will be the Democratic nominee (on the economics point, it looks like you could presently make money arbitraging PredictIt vs. Betfair purely on a price basis but obviously there are impediments to actually doing it).
Of course, if the model-based forecasts didn’t move around then no one would ever pay attention to them. 538 needs as much traffic as it can get, which means driving people to come back over and over again. A forecast that assumes a lot of mean reversion or puts lots of weight on the fundamentals and thus doesn’t change gives people no reason to make a second or third visit. Even if forecasters talk up the role of fundamentals, their traffic comes from the horse race.
The 538 primary election model had Biden close to 50% just before Iowa, down in the single digits after Nevada, then up to a 90% chance after South Carolina a week later even though the outcomes in those states were basically in line with the model expectations. I guess you can argue that the other candidates dropping out was a total black swan but it’s hard to credit 538 as an appropriate probabilistic forecasts. The betting markets were moving in the same timeframe, but not nearly as widely. I believe they had Biden as the favorite all along, which seems more reasonable.
> The 538 primary election model had Biden close to 50% just before Iowa, down in the single digits after Nevada, then up to a 90% chance after South Carolina a week later even though the outcomes in those states were basically in line with the model expectations. I guess you can argue that the other candidates dropping out was a total black swan but it’s hard to credit 538 as an appropriate probabilistic forecasts. The betting markets were moving in the same timeframe, but not nearly as widely. I believe they had Biden as the favorite all along, which seems more reasonable.
He got 4th in Iowa and 5th in NH. Historically that has been very difficult to come back from (even if your prior is that they are a strong candidate). His polls also declined substantially, and the lack of dropouts substantially increased the likelihood of no one winning a majority of delegates.
His chances went up after winning South Carolina by 30 points (compared to expected 10 points, a 90th percentile outcome for him), his polling substantially improving in Super Tuesday states, and the dropouts + endorsements from Klob and Pete. Although, it was not 90% to win, it was still only 30% for him to win a majority until after Super Tuesday.
It is also very much not the case that the betting markets always had him as a favorite. If anything they were basically always more bearish on Biden than the 538 model.
Is this 88% for Biden or democrats in general? I still don’t think Biden will be the nominee.
Anon:
Our forecast is for Democrats in general. We say Biden vs Trump because it seems that they’re the nominees. We don’t try to include other candidates, which is why I knocked the probability down from 88% to 80%.
I see. It’s just kind of weird that it doesn’t even matter who the candidate is. Makes me think we should just get rid of candidates altogether.
The parties have evolved processes that let them choose the most efficient candidate (or something close to it, anyway). It doesn’t matter who the candidate is as long as that process works.
It does matter, it’s just that the difference in different candidates’ electability is baked into the polling responses, so there’s no need to hard code it into the model. If Hillary were to get the nom somehow, then the probabilities would automatically shift with the polls, presumably downward. From a completely practical standpoint, it would matter almost as much why the switch happened as who the new candidate is, e.g. scandal vs illness, and there’s no way to account for that.
Two things – from someone who can only follow a small portion of the technical discussion.
First, given that our country is so easily split along party identification, and has been for a long time. And given that ideological orientation is so explanatory for how people vote. Even with an understanding that party ID seems to be pretty volatile and can change in particular in association with the momentum provided from forecasts such as yours, I don’t see how it makes sense to make such a strong forecast. I certainly wouldn’t question your math…but it goes back to my baseline belief that math can only take you so far unless you can explicate a causal mechanism: In this case, how could you explain how we’d get so far away from the basic 50/50 split in how people vote in presidential elections. How would you get a result so far away from recent precendent?
Second, (somewhat related) I don’t understand how we could have much confidence in a prediction that has moved so far in just a couple of months? Trump’s basic polling has been quite stable for a long period of time, but even there, it just seems to me that relatively short-term swings in polling may well reflect events that drive short-term emotional responses but not really how people actually vote when they walk into a polling booth. Answering a question on a poll is a very different behavior than actually voting for someone. Actually voting for someone, it seems to me, is less likely to elicit a significant change in behavior like voting for a president from a different party than what you’ve done in the past. Much has been made of the Obama —> Trump voters – but my belief is that those were relatively rare (not saying there weren’t any). I think what we actually saw more of are many Obama voters who just didn’t vote in 2016, and people who typically didn’t vote coming out and voting for Trump. Without detailed evidence that is extremely hard to get in a reliable fashion (self-report on voting is unreliable), such a pattern would look from above very much like a lot of voters switching from Obama to Trump. Again, I just don’t think that there are that many people who are that volatile in their voting behaviors.
I think the present-day approval rating and economic indicators are best viewed as predictors of early November approval rating and economic indicators, which in turn predict the election results. In that context, we can consider whether we expect the current values to be good or bad predictors of November values. I suspect that approval rating is unusually stable this time around (given how stable it’s been over the past four years) and economic indicators are unusually unstable (given the pandemic), and that the latter is the main source of skepticism in the model forecast.
Testable hypothesis: is recent volatility in the fundamentals a good predictor of future volatility in the fundamentals?
Apologies if this has been mentioned before or if my message represents my lack of knowledge about election forecasting but I would assume economy is a strong predictor of election outcome because voters link economic performance to the actions of the president. However, I wonder if the assumption will hold in 2020. In other words, will many voters blame the pandemic instead of the president for the current economy? I could imagine hearing a Republican or undecided voter saying something like “the economy was doing great under Trump until Covid struck.” They then might base their vote based on, say, last year’s economy. I do not necessarily endorse the statement that Trump was responsible for the previously strong economy and, of course, Trump’s handling of Covid has had an influence on the current economy. But I wonder if many voters will see it that way. In sum, the predictor of election outcome may not be some absolute economic indicator but that portion of the indicator for which the president is perceived as being responsible. In most years it might be near 1:1 but I’m not so sure about this year.
Here are estimates of probability of winning an NBA game updated by possession: https://stats.inpredictable.com/nba/wpBox_live.php. They’re volatile, so Madeka (if he’s consistent) must also think that these probabilities are “wrong”, but on what basis? They’re based on observed outcome frequencies conditional on game situation at each point in time (and prior assessments of team skill). Basically, back-and-forth games with runs happen. They’re not the most common type of game, so if you have a lead it’s reflected in a high win probability. What’s the confusion?
I think the confusion comes from treating a prediction as a series of peaks and troughs and then forgetting about the extreme dependence (as well as look ahead bias) that you create when you do that.
Cool chart! That’s the most sensible thing I’ve read on this thread. But it would be cool to see the score difference plotted as well so you could see how runs change the probability. Would also be interesting to know what kind of entrails are in the “observed outcome frequencies” sausage – all NBA games over a certain period?
Not sure why this keeps getting trapped in the spam filter. Will try a posting in parts to find the problem.
Two things – from someone who can only follow a small portion of the technical discussion.
First, given that our country is so easily split along party identification, and has been for a long time. And given that ideological orientation is so explanatory for how people vote. Even with an understanding that party ID seems to be pretty volatile and can change in particular in association with the momentum provided from forecasts such as yours, I don’t see how it makes sense to make such a strong forecast. I certainly wouldn’t question your math…but it goes back to my baseline belief that math can only take you so far unless you can explicate a causal mechanism: In this case, how could you explain how we’d get so far away from the basic 50/50 split in how people vote in presidential elections. How would you get a result so far away from recent precendent?
Part two:
Second, (somewhat related) I don’t understand how we could have much confidence in a prediction that has moved so far in just a couple of months? Trump’s basic polling has been quite stable for a long period of time, but even there, it just seems to me that relatively short-term swings in polling may well reflect events that drive short-term emotional responses but not really how people actually vote when they walk into a polling booth. Answering a question on a poll is a very different behavior than actually voting for someone. Actually voting for someone, it seems to me, is less likely to elicit a significant change in behavior like voting for a president from a different party than what you’ve done in the past. Much has been made of the Obama —> Trump voters – but my belief is that those were relatively rare (not saying there weren’t any). I think what we actually saw more of are many Obama voters who just didn’t vote in 2016, and people who typically didn’t vote coming out and voting for Trump. Without detailed evidence that is extremely hard to get in a reliable fashion (self-report on voting is unreliable), such a pattern would look from above very much like a lot of voters switching from Obama to Trump. Again, I just don’t think that there are that many people who are that volatile in their voting behaviors.
Part two:
Second, (somewhat related) I don’t understand how we could have much confidence in a prediction that has moved so far in just a couple of months? Trump’s basic polling has been quite stable for a long period of time, but even there, it just seems to me that relatively short-term swings in polling may well reflect events that drive short-term emotional responses but not really how people actually vote when they walk into a polling booth. Answering a question on a poll is a very different behavior than actually voting for someone. Actually voting for someone, it seems to me, is less likely to elicit a significant change in behavior like voting for a president from a different party than what you’ve done in the past. Much has been made of the Obama —> Trump voters – but my belief is that those were relatively rare (not saying there weren’t any).
The popular vote prediction was 54% +/- 3% (of the two party vote, I believe).
From the post:
In 2016, Clinton got roughly 51% of the two-party vote share (dem / (dem + rep)).
As Joshua points out, and Andrew has blogged about before, differential response can be a big factor.
Second, (somewhat related) I don’t understand how we could have much confidence in a prediction that has moved so far in just a couple of months?
Trump’s basic polling has been quite stable for a long period of time, but even there, it just seems to me that relatively short-term swings in polling may well reflect events that drive short-term emotional responses but not really how people actually vote when they walk into a polling booth.
Answering a question on a poll is a very different behavior than actually voting for someone. Actually voting for someone, it seems to me, is less likely to elicit a significant change in behavior like voting for a president from a different party than what you’ve done in the past. Much has been made of the Obama —> Trump voters – but my belief is that those were relatively rare (not saying there weren’t any).
The oei kwm is in this section. I’ve tried re-wording.
Responding to polls and voting are very different activities. I think voting for a president from a different party is probably rarer than changing responses to polling questions. Much has been made of the Obama switched to Trump voters, but my belief is that those were probably fewer than it seems
Sorry for the many comments – but there was no apparent reason for the spam filter to stop my comment. Last part…
I think what we actually saw more of are many Obama voters who just didn’t vote in 2016, and people who typically didn’t vote coming out and voting for Trump. Without detailed evidence that is extremely hard to get in a reliable fashion (self-report on voting is unreliable), such a pattern would look from above very much like a lot of voters switching from Obama to Trump. Again, I just don’t think that there are that many people who are that volatile in their voting behaviors.
Oy. Still a problem! I’ll try re-wording this also:
I think some Obama voters just didn’t vote in 2016, and people who hadn’t voted much voted for Trump. Self-report on voting is unreliable so it’s hard to know. This behavior would look very much like voters switching from Obama to Trump. But how many voters are really that volatile?
Madeka writes, “But in the scenario where you behaved like Silver in 2016, mean reverting up and down – we’d make money from you whether Trump or Biden won.”
Has this been shown with the time-series of Silver’s probabilities, or just asserted to be possible in principle? Would be neat to look at a week by week series of hypothetical bets assuming that Silver’s probabilities were being offered as betting odds.
The fact that the model is based on the two party vote is basically an acknowledgement that its predictions are *conditional on these candidates being nominated*.
The model makes no effort to predict p(Biden Wins | an election happens) it’s p(Biden Wins | An election where Trump and Biden are candidates happens)
Much of the concerns being raised are related to things like Trump or Biden die of COVID or are forced out by other health issues or Trump decides not to run or is impeached a second time or assassinated or etc etc.
These are the real “black swan” events. This model is conditional on them not happening.
I’m confused about the “black swan” discussion.
Perhaps I’m over-simplifying things, but if both candidates are equally likely to have a long-tail event happen in their favor, then isn’t the net effect that nothing changes?
Let’s say you knew that an October surprise would definitely happen, but you didn’t know which candidate it would favor. I guess that would change your confidence in the predicted results, but why would it change the prediction itself?
Steven, good question. The more uncertainty you have in what amounts to a binary win probability, the more the probability moves towards 0.5 – this is the maximum entropy result if you will.
You’re thinking that “the prediction” is a number. I mean, you can extract a number like the mean, but “the prediction” is a probability distribution, and the existence of weird possibilities as you say widens that probability distribution. It should widen more and more as time goes on because there are more possibilities for strange things to happen.
Furthermore, as they widen, the probability you assign to “biden over trump” decreases towards whatever your baseline is. That is, evidence from today that doesn’t tell you much about the future also won’t cause your prior to shift much.
Imagine for example that you have some prior idea how long my pencil is… Then you look through a super blurry telescope from 10 miles away and try to measure the length of my pencil… The errors in your measurement are on the order of +- 20cm. So you get 20 +- 20. Now your prior for my pencil length is 10cm +- 5.
If you take normal(10,5) truncated to the positive axis, and multiply by normal(20,20)… and re-normalize. the posterior isn’t very different from normal(10,5). (you can plot the two curves and see for yourself).
“You’re thinking that “the prediction” is a number. I mean, you can extract a number like the mean, but “the prediction” is a probability distribution”
+1
You said a couple of comments back that “The model makes no effort to predict p(Biden Wins | x) it’s p(Biden Wins | y)”. In that case, the prediction *is* a number.
It looks like what they’re actually modeling is the vote differential. So there’s a probability distribution over the vote differential and from that you can derive a p(biden wins | …). That’s what I meant by the prediction “not being a [single] number” ([single] added for clarification)
Also, you don’t *predict* a probability. A probability isn’t an observable thing. Like Jaynes said, you can’t measure a boys love for his dog by doing experiments with the dog. A probability is like that, it’s a thing you assert about your understanding of the world based on all the things you’re taking into account. In this case they provide probabilities over vote differentials, meaning they think certain vote differentials are more likely and others are less likely.
Sure. It’s a good think that the model makes no effort to predict p(Biden Wins | an election happens) then.
Yes, it’s a good thing you pointed out how imprecise my previous statement was too ;-)
What’s funny about the “black swan” discussion is that no one knows if an event is one or not until the effect on the result is observed.
“Misfire!” Gene Hackman says in the ultimate scene in Unforgiven. It’s the perfect break – the black swan!! Except Clint handles it perfectly and kills Hackman anyway.
A black swan “misfire” in the Presidential race: Biden gets COVID and becomes too ill to continue. OMG!! Trump has his chance!! Kamala Harris steps up and she wins by the expected margin.
Jim:
I’m no quite sure what is the definition of a black swan event, but I don’t think that “old guy gets sick” is one!
Huh? You’re saying it’s predictable for old dudes to get COVID? :) Yeah that wasn’t a great example. Almost as bad as “trump gets indicted!”.
„I’m no quite sure what is the definition of a black swan event, but I don’t think that “old guy gets sick” is one!“
This aged quite well
What do the confidence/uncertainty/whatever intervals in the “Modeled popular vote on each day” mean?
Do you think that the probability, by some definition, of the following hypothetical events is the same?
a) if people had to vote for Biden or Trump tomorrow, the share of popular vote for Biden would be between 51% and 57%
b) if people had to vote for Biden or Trump in four months, the share of popular vote for Biden would be between 51% and 57%
If you had to bet now for one of those (and there was a way to settle the bet) would you be indefferent?
Carlos, the model is for vote share on election day. The intervals represent uncertainty conditional on the model and the information that is available now and that has been conditioned on. They build in temporal components so presumably their forecasts would be different if forced to answer the hypothetical “what would happen if the vote were tomorrow?”
Thanks, but I don’t get it. If the current estimate, as of June 19th, of what the vote share will be on election day is 53.9% what does the 53.8% that appear at the end of the forecast period represent? Or does the 53.9% mean something else?
I agree with Carlos, that it’s ambiguous what the model predicts. I can imagine for example that in the graph shown before: https://statmodeling.stat.columbia.edu/wp-content/uploads/2020/06/Screen-Shot-2020-06-12-at-1.57.49-PM.png
Biden 54.1% means more or less something like: If you could run a very high quality poll today equivalent in most ways to a real election, that 54.1% of people who participated would want Biden.
So then the 53.6% prediction for election day and the fact that the intervals stay basically the same width and move horizontally basically means “we are just as certain about what would happen today in a hypothetical mass-polling as we are for the real election”
which does seem a little weird. I mean, even if you ignore the long-tailed events like someone gets assassinated, dies of COVID, or is otherwise unable to stand for election, you still have the possibility that say it comes out that one or the other candidate was involved in some very unsavory deal which moves the election strongly away from them. The possibility that between now and then such a thing could happen is real, and seems unaccounted for. I just expect that the uncertainty intervals should widen with time if you’re accurately expressing real uncertainty.
The ‘rare’ events which we used to think of as ‘rare’ (or merely Manchurian Candidate movie-fare) are no longer rare at all. What was the effect of the then FBI director’s communiques in 2016? What will the analogous thing be this time? I presume there will something of that order; and because I am not a writer of 1st-rate screen plays it is almost beyond my comprehension — whatever it is to be! Something of that order though will come to pass. Mark my words.
I’d also like to know the answer to Carlos’s good question, which Daniel’s comment helped me to understand the importance of.
Ah, good eye Carlos! I’ll have to let Andrew or Merlin answer to know for sure. I think Daniel is on the right track, and the model is basically adding a bit of extra uncertainty in going from 54.1 to 53.6%. That this doesn’t feel like “enough” is because of the kinds of events he alludes to, but those are inherently hard to factor in, so among the model assumptions is “no new bombshells” or something like that :)
Ugh.
Apologies to all, and especially Andrew, for all those posts. I couldn’t figure out what was going in (I got a mixture of comments just disappearing and comments awaiting moderation)/
Madeka’s comments make sense, but as he notes the effect he’s describing is heavily dependent on the level of volatility. As volatility increases unbounded, best estimate of probability approaches zero. So couldn’t his issue also be resolved if his expectations of volatility are much higher than your model’s?
Looking at the picture Madeka provided, the volatility implied by the line labeled “Rigorous updating” seems absurd. It’s basically saying that no information is reliable as late as 2 or 3 days before the election. That doesn’t make sense to me — at that point early voting has already been going on for weeks and it’s not like we’re getting new high quality polls on the day of the election. That line looks more like a situation where one’s model thinks the data is basically indicative of a coin flip the whole time (up until the day of the election when you flip the coin and find out) rather than a situation where the model is accounting for time-based uncertainty.
Also, in the same picture, what’s with the the line labeled “538”? That doesn’t look like 538’s predictions for 2016 — they ended up at about 70% for Clinton, not 90+.
Hmm, maybe I’m just completely misreading picture. The axes aren’t labeled, and after skimming the paper I see that figure, but I can’t find any reference to it or its underlying data or what the author thinks the figure implies. So I’m stumped.
This is not meant as a rebuttal of Madeka, but to a more naive “if the predictions jump around a lot, they must be wrong” type of argument.
Imagine I made a bet with my friend that I would flip a fair coin three times and I win if two or more heads show up and she wins otherwise.
The probability that I win is obviously 50%.
However, if my first flip is heads, my chance of winning is now 75%.
Nothing wrong with the probabilities here.
Having said that, I do think political forecasting is an example of point estimates being abused when they only tell part of the story.
There is a difference between
A) Biden has 80% chance of winning because on election day, he will either have 60% or 100% of winning. (we will be able to figure out which of these scenarios we are in by then)
B) Biden has 80% chance of winning because on election day, he will have 80% chance of winning.
Looking at the economic index graph, I wonder if you think that is a good prediction. To me it looks like you have:
(a) data points that don’t show a clear linear relation
(b) no theoretical model that suggests a linear relation
(c) an economic index for 2020 falling outside the the range of previous observations, resulting in
(d) a prediction that is outside the range of previous outcomes.
To see how this could fail, imagine if you fit all of the incumbent-runs elections except 1980 and tried to predict Carter’s vote share. Just eyeballing it, it looks like you’d get a much sharper slope and predict something in the mid 30s, where in reality it was 45%.
Yariv:
It’s possible, but I don’t see what you’re saying about Carter. I don’t think any model would predict him getting only 30% of the two-party vote in 1980.
He’s saying, in the graphic you posted (https://statmodeling.stat.columbia.edu/wp-content/uploads/2020/06/Screen-Shot-2020-06-17-at-8.38.59-PM.png), on the bottom half, red line, if you remove the 1980 data point, and refit the linear regression line, it would have a much sharper slope, and if you then used that new line to predict Carter’s vote share, it’d be something in the mid 30s.
His point is, that single data point is very influential, and the 2020 data point is far outside of the range of previous outcomes. Extrapolating in modeling is a risky thing, and you’re liable to be very wrong, especially when the regression is already heavily influenced by an outlier point (1980) in a limited data set.
Harrison:
But it’s not true that if you remove the 1980 data point that the line would be lower!
Why am I so sure? Because the line already goes through the 1980 data point. So removing that point will not change the least-squares line.
It’s a bit frustrating to see this argument being trotted out again. Aubrey Clayton thoroughly rebukes the derivatives pricing criticism being advanced here by Madeka (and Taleb): https://arxiv.org/pdf/1907.01576.pdf. Less technical versions of the argument in this paper can be found here: https://nautil.us/issue/70/variables/how-to-improve-political-forecasts and https://nautil.us/blog/nassim-talebs-case-against-nate-silver-is-bad-math.
To briefly address the point being made by Madeka, the scenario he’s describing isn’t an example of arbitrage unless he *knows right now* that the Economist model will revert towards a 50% probability of election for Biden. He may well think this is true, but then his issue should be stated as “I think your model doesn’t take into account certain factors. It thus underestimates the probability of crazy things happening later in the election cycle, which will manifest as high volatility in the model, and you should fix this.”
It is not true however that “probabilities don’t behave like that.” The commenter “Z” has a great example above involving win probability graphs for baseball or basketball, and there are other examples discussed by Clayton in his articles.
John:
I have not tried to follow the details of the arguments on each side, but I notice that Clayton refers to a “random-walk model for a given candidate’s vote share.” I don’t think such a model makes sense; see here.
Andrew, since Clayton is responding to Taleb, it is Taleb who injected the ‘random-walk’ approach to forecasting a candidates vote share, e.g. here: https://arxiv.org/pdf/1703.06351.pdf
I believe the random walk model here is intended to illustrate Clayton’s point that option prices can vary considerably even when the volatility of the underlying asset increases. I don’t think that random walk is intended to define a good model for election forecasting. I’ll try to summarize the arguments on both sides here, but I think the right conclusion here is that the derivatives pricing stuff is just unnecessary. Examining the argument made more carefully reveals that all of this options pricing stuff conceals the actual argument Madeka and Taleb are making: “I disagree with your model. I think there is higher chance than you do of Trump gaining ground in the polls.”
Taleb makes essentially two arguments:
1) as the volatility of the underlying quantity of interest (e.g. voter preferences) increases, the price of the option that provides $1 if Biden wins should approach 0.5 (no matter what the current value of the voter preferences are).
2) You’re telling me today (6/20) that the probability of Biden winning today is 88%. But conditioning on today’s information, your model’s expected forecast on August 1st for the probability of Biden winning is 65%. Then, I can make money off of you.
On their face, these arguments seem correct, but they both make bad assumptions to set up their claims! Starting with argument 1, it is true that if the volatility of the polling is high, then I shouldn’t be able to say anything useful about who will win in November today. But this argument essentially sets up the problem incorrectly. To understand why, Clayton provides the example of the random walk. In layman’s terms, let’s pretend that there’s some number we can track to determine who wins the election: if this number is positive on November 3, Biden wins. Each day between now and then, we flip a coin. If the coin ends up as heads, this number increases by 0.01, and vice versa if the coin is tails. Halfway between now and Election Day, we notice that Biden is up by 0.32, and conclude he has better than 50% odds of winning the election. OK, so far so good, Taleb probably agrees. But now, Taleb would argue that as we increase the variance of this random walk, our forecast probability for Biden should concentrate at 0.5. But is that true for the process I just mentioned? Well let’s increase the variance of this process by changing the shift at each coin flip to +/- 100. The forecast we will make halfway between now and Election Day hasn’t changed! It hasn’t concentrated around 0.5 because what mattered here was the *number of coin flips* that went Biden’s way (not their value).
Where did Taleb go wrong? It’s true that as the volatility of the underlying asset increases, the forecast probability goes to 0.5 for a fixed value of the current asset. However, the asset price (e.g. the polling margin, etc.) was also subject to that volatility in the past. The only way Taleb’s argument guarantees that the forecast probability stays around 0.5 until the very end is if you assume that future volatility goes to infinity but past volatility is fixed. Maybe it’s true that your model (and Nate Silver’s model) understates the volatility of polling later in the election cycle, but there’s nothing mathematically wrong here. An argument about modeling assumptions is being disguised as an assertion of mathematical fact.
I tried to partially address the second argument in my brief comment above regarding arbitrage. Above, Madeka claims that he can do “arbitrage” on your prediction because he’ll simply sell Biden now and buy Biden later when your forecast inevitably drops. That isn’t inevitable though. Unless you’re purposefully issuing forecasts that you anticipate will be revised downwards later, your forecast is a martingale with respect to past observations and there’s no guarantee that Madeka will make money with this strategy. This isn’t an example of arbitrage. Madeka simply thinks he knows more about election modeling and believes that your model underestimates the likelihood of future events that will harm Biden’s prospects. This assertion is perhaps true but there’s no mathematical error here. He just thinks your model is bad because he disagrees that it’s a good model of the world.
There are some details I’ve glossed over here; it is true that as your forecasts approach 100% or 0%, the volatility of your forecast should decrease. To see why, if your forecast of Biden winning is 100%, that necessarily means that you do not envision a world in which adverse events between now and the election decrease Biden’s probability of winning. If your forecast dropped from 99.9% in June to 63% in August, you would probably want to question whether your model was correct to begin with. This is a valid criticism of Nate Silver’s 2016 forecasts, but to provide a counterpoint, we’ve all seen sports games where the win probability over the course of the game goes from 99% to 50% in a flash. Rare events happen and using the 2016 election to say that political forecasting must be mathematically broken because there was lots of volatility is jumping the gun. The simpler argument is that models validated on prior election cycles did not anticipate the events of the 2016 election cycle very well (i.e. you made bad modeling assumptions).
Why did I write this long screed? Well, for one, I hope it will shed some light on the quantitative finance terminology used by Taleb to make his point. I found it confusing for a long time until I read Clayton’s articles. But also I think it’s really important that we distinguish between verifiable mistakes (i.e. incorrectly computing a confidence interval) and disagreements over modeling. Papers/authors that make the former mistake need to retract and revise their work; the latter is part of healthy scientific discourse.
Well explained John. +1
Thanks John, that’s very helpful.
Do you understand the graph that Makeda provided (the one with arrows labeled “538”, “rigorous updating” and “election day”)?
Is the one labeled “538” meant to be 538’s predictions over time of Clinton’s chances of winning 2016? Because those numbers don’t look right.
Is “rigorous updating” Taleb’s corrected version of 538’s predictions, or something similar? It seems to follow the same shape as the “538” line, but with much smaller amplitude. It would seem to comport with Makeda’s note that volatility means the farther out you are the closer the prediction will be to 0.5.
If so, it doesn’t seem reasonable — Makeda’s description would have me expect it to creep up over time, but it never breaks 0.55 until the final day when it jumps to (what appears to be) 100%.
So…that graph is not explained in the paper in which it is included as Figure 2, but is presented in a Twitter thread here with some accompanying Mathematica code: https://twitter.com/nntaleb/status/762048739334885380
The 538 curve is not a real forecast time series from Silver but his assessment of how 538 would compute the option price for an underlying security whose value follows a Wiener process (Brownian motion). The rigorous updating curve then captures how he would compute that price. However, as explained in the Quora answer here, the curve he describes as “rigorous updating” is computed incorrectly.
https://www.quora.com/Whats-Nassim-Talebs-best-argument-that-Nate-Silver-is-not-very-good-at-what-he-does/answer/Markus-Schmaus
The error he makes while constructing the “rigorous updating” curve illustrates the central problem with Taleb’s argument. Essentially, he assumes that the variance of the underlying process is high when making his forecast, but forgets to actually increase the variance of the underlying process. We can use the above example re: coin flips to make this error more concrete. Taleb assumes in his forecast that each coin flip changes the value being tracked by 14, but forgets to increase the variance of the underlying coin flip process to 14. In his plot, each coin flip is only changing the tracked value of the security by 1. In that case, of course you’ll never issue a forecast much higher than 0.5 — you are constantly living in fear of a coin flip that will decrease the value of your security by 14 that will never come!
Anyways, the Quora respondent shows that when you fix this mistake (i.e. increase the variance of the underlying process to match the assumption made when pricing the option), the resulting forecast curve looks just like the 538 curve. As in the coin flip example, the variance of the process doesn’t really affect the volatility of the optimal forecast over time.
Hope that makes sense!
My previous comment disappeared I think, but essentially the rigorous updating curve is incorrectly computed. Both graphs correspond to different models for forecasting that Taleb came up with for a toy model. If you’re interested in delving into this more deeply, check out this Quora answer: https://www.quora.com/Whats-Nassim-Talebs-best-argument-that-Nate-Silver-is-not-very-good-at-what-he-does/answer/Markus-Schmaus
I think they responded here – https://twitter.com/nntaleb/status/1157399736980295680
It’s not much of a response to the substantive criticisms laid out by Clayton or Schmaus (in fact, Schmaus’ criticism goes entirely unaddressed). I struggle to deal with Taleb because, to be perfectly honest, I don’t think he’s responding in good faith. If you read through that response post, it’s filled with personal attacks and smokescreen math that has nothing to do with the criticisms levied by Clayton. A particularly important claim re: arbitrage is accompanied by a footnote that it was “proved in the class notes” of some class at NYU. Broadly, I’m not sure whether it’s worth engaging with someone who replies to criticism like this.
But since it’s posted, I just want to note that in Taleb’s response he makes the same mistake he made in the original analysis. For a fixed value of the underlying asset, it is true that if you send the variance of the asset to infinity for the remaining time period, the option value will go to 0.5. Taleb rejects Clayton’s setup because he says that when you pause at any point, the option price should go to 0.5 if the variance of the asset in the remaining time period goes to infinity. But does that make any sense? Let’s take the coin flip example again to illustrate this concretely. We can apply Taleb’s set up as follows: pause part way through the sequence of coin flips, and ask yourself, “OK, how should we reprice this option if we change the game such that each coin flip now changes the value of the tracked asset by +1000 or -1000 instead of +1 or -1?”
If we think that the volatility of voter preferences (i.e. the underlying asset tracked by political forecasters) is high, it should be high presumably both before and after we observe the current voter preference. By fixing the asset price at some time t and sending sigma to infinity for the remaining period, he is creating a world in which the future volatility in voter preferences is for some reason always going to infinity no matter what the past observed volatility is. Frankly, even if this was a sensible model of voter preferences (or any asset price for that matter), this decision is simply a modeling choice, not some kind of mathematical error.
The remainder of the reply is filled with ridiculous statements (and the aforementioned footnote to class notes I can’t find). He claims the following: “a forecaster…can be arbitraged by following a strategy that sells (proportionately) when the forecast is too high and buys (proportionately) when the forecast is too low.” What does this even mean? Am I arbitraging an S&P 500 ETF right now by short selling it today and then buying it later if I think the market is overvalued now and likely to be undervalued later? No! I just have a different model of the world than the average market participant, and I think I can profit from my superior model. There is no way to look at the 538 forecast at any point and know with certainty whether it is too high or low. If there is some secret method for doing so (that is not equivalent to apply my superior model for election forecasting), Taleb and Madeka should tell us about it.
John:
I’m not sure I understand your argument. Why would a price be constrained on the positive side at any given point in time?
Curious:
Sorry if something wasn’t clear! What do you mean by the price being constrained on the positive side?
I was referring to:
“Taleb rejects Clayton’s setup because he says that when you pause at any point, the option price should go to 0.5 if the variance of the asset in the remaining time period goes to infinity.”
Why would this not be the correct assumption?
Curious:
In the lengthier follow up post to Patrick above, I (tried to) explain why that limit is somewhat nonsensical. Taleb is attempting to argue that if the variance of the underlying security is high, then the option price should concentrate at 0.5. The limit he sets up proves a subtly different conditional statement. By pausing at some point t and sending the variance of the process to infinity, he assumes “future volatility of the security” goes to infinity. This is *not* the same as assuming that the volatility of the underlying security is going to infinity. The former setup might be relevant if we were studying time-dependent variance in voter preferences (i.e., we think there’s greater variance in voter preferences in October than June), but that’s not what Taleb is talking about.
Again, the coin flip example makes this concrete. Let’s assume we’re playing that coin flip game I described in the original comment. Heads means I get a $1, tails means I lose a $1, and some option pays out $1 if I have a positive dollar value at the end of the game (clearly its value at any point is equal to the probability that I will have a positive balance at the end of the game). Let’s say the game lasts 10 coin flips. Now, if we pause before coin flip 2,…,10 and send the pay out from a subsequent coin flip to $1000 or -$1000, the price of the option will obviously become very close to $0.5. But pausing at coin flip 5 and assuming that the rules of the game suddenly changed from flips 6 through 10 isn’t helping us answer the question of how the option will be priced when the payouts from the coin flips get larger *everywhere*.
Increasing the variance of the underlying security everywhere has *two* effects when we study the option price at time t (for any t). 1) it pushes the value of the option towards $0.5 because, in plain English, more crazy things could happen in the future, 2) it increases the volatility of the option price at time t because more crazy things could have happened in the past. In fact, for the coin flip example, these two effects precisely cancel out. The win probability doesn’t depend on the variance of the random walk at all, but solely on the number of coin flips I win.
Curious:
Another more abstract way of intuitively grasping what might be problematic about Taleb’s statement is that it involves conditioning on the random quantity whose properties he is interested in modifying.
Thanks John, once again that’s fantastically helpful.
He really does seem to be arguing in bad faith. In his response to Clayton, he snarks: “There is no mention of FiveThirtyEight in Taleb (2018),and Clayton must be confusing scientific papers with Twitter debates. The paper is an attempt at addressing elections in a rigorous manner, not journalistic discussion, and only mentions the 2016 election in one illustrative sentence.”
Yet Taleb (2018) includes a chart with a line labeled “538” that came directly from a Taleb Twitter posting and goes entirely undescribed in Taleb (2018). It’s the chart that Madeka likes and sent to Andew — lefthand chart in this graphic: https://statmodeling.stat.columbia.edu/wp-content/uploads/2020/06/image-1.png
Anyway, all I can think in that response to Clayton is that he’s trying to twist his own argument by positing a _literally_ infinite sigma for future volatility (and not simply a very large sigma). He notes in his response to Clayton: “The σ here is never past realized, only future unrealized volatility.” and “At infinite σ, it becomes all noise, and such a level of noise drowns all signals.”
I can’t claim to fully understand the first comment, but the second I get — if sigma is “truly” infinite, then the potential future movement is such that neither outcome is more probable than the other. And I think that informs his prior comment, “the σ here is never past realized…”, because the flip side of that is that the magnitude of prior actual movement is irrelevant if the potential for future movement is infinited.
But you are correct — for any real value of sigma, it is possible (likely?) that actual, realized prior experience will drive the process far enough from equilibrium to cause a significant shift in probability.
But if I’m reading him wrong, I think the core of the thing is the first sigma sentence I quoted. If there is some justification for the assumption that past, realized volatility is always negligible with respect to future volatility then yes, the argument makes sense. If Taleb can justify that then his argument works; otherwise it would appear that Schmaus has identified correctly and Taleb simply made a coding error (not increasing the volatility of the actual process) and got a result that comported with his intuition, and dumped it out on Twitter.
Also, can you tell what Taleb is doing here? My guess is that he’s showing what the “rigorous updating” model would produce for different values of sigma, with the blue line being low sigma and consistent with what he termed the fivethirtyeight projection and the others corresponding to larger values of sigma. https://twitter.com/nntaleb/status/762655751143886848/photo/1
But again, these all make the error increasing the sigma used as a future expectation for pricing purposes but not increasing the sigma on the underlying process. If he had updated the underlying process, they would all look similar to the blue line (but perhaps not as jagged – I’m not sure).
So the one way I could get to Taleb’s result is if the process were bounded somehow, such that volatility were asymmetric based on prior realized results. For example, take your coin flip model and say that the accumulated dollar value must remain inside the corridor -$100 to +$100. As you increase the volatility, the corridor has greater effect and for very large values of volatility you would approach a 50% probability estimate even if prior realized results have planted you firmly at the extreme of the corridor. It doesn’t feel wrong to assume that such a thing might exist in politics, that a candidate’s situation can only be improved so much regardless of how much “good news” occurs for them, leaving any volatility to act to their detriment (and the reverse for a candidate who has gotten a lot of bad news). But that might just be me coming up with justification for a gambler’s fallacy belief that aligns with my intuition about elections.
But more importantly, I don’t see anything in Taleb’s Twitter or articles that would support that as being an element of his model. I admit though that I haven’t tried to fully understand Taleb 2018, maybe it’s in there (or implied in there) somewhere.
Joseph:
I think I’m in agreement with everything you’ve stated. And I believe your interpretation of his second set of graphs is correct. If there is some justification for why future volatility is always going to infinity, then his argument is valid. Though again, I would repeat, at this point, Taleb is clearly just stipulating that we should be forecasting with a different model of the world than the model Silver/Gelman are using. It’s not as if Silver also agrees that future unrealized volatility is going to infinity, but nevertheless produces a forecast that is highly variable over time.
As far as I can tell, Taleb 2018 does not make these kinds of arguments regarding bounds. To define the bounded process, he applies the error function to the underlying Brownian motion (see Sec. III). In fact, he explicitly claims that it doesn’t matter if you price the option based on the unbounded process or the bounded transformation of that process (see the last paragraph of Sec. III). Again though, doing something like this supports an argument of the form “I have a different, better model of the world.”
John:
Please. There is no “the model Silver/Gelman are using.” I have no idea what Nate is doing.
Andrew:
Sorry, that’s my mistake. That sentence should read “the [models] Silver/Gelman are using.” I’m not trying to imply that you’re using the same models. My goal was to point out that the critique laid out by Taleb/Madeka is really better understood as advancing an alternative model, not a proof that volatile forecasts violate the rules of probability theory.
John,
Joseph and I tried to resolve this through email unsuccessfully. We’re planning a post-pandemic lunch to discuss. You’re welcome to join! Feel free to email me through my website!
Dhruv
I’ve stumbled today upon this old tweet of Madeka: https://twitter.com/DhruvMadeka/status/1266188053510533122
“You want to be comparing two tradeable instruments – if there’s a divergence/arbitrage the market corrects for that. Comparing a tradeable one to a non-tradeable one then saying the market is arbitrageable isnt clear to me”
That’s funny, because their argument seems to be based on arbitrage-free pricing of election forecasts as derivatives of a hypothetical, non-tradable underlying instrument.
One question I’m a bit surprised didn’t come up in your discussion was why your forecast went from roughly 50% in March to 85-90% now, or to be more precise why you are fairly confident it won’t reverse in the next couple of months? I appreciate that the economy and Trump’s approval has fallen over that period, but Trump’s approval has been pretty mean-reverting over time and given it is a strong driver of his re-election odds it seems fairly likely to me that as the current circumstances fade (the protests in particular) his approval will improve a bit.
I agree with you about the betting markets. I do bet thousands on these markets and have the election far closer to your model than the market. But I think there is a fair question to ask: If the 85-90% model is being driven in part by a recent drop in approval ratings isn’t it likely that it’s overstating Biden’s chances because that drop is likely to reverse (due to unusual circumstances fading and a history of drops/rises reversing)?
The answer to this is “yes” but that’s just the nature forecasting. Anything could happen tomorrow and change the probabilities. On the one hand things may calm down and the economy may improve, giving Trump a boost. On the other things may just as well get worse making Trump’s problems bigger.
But those shifts are also in part baked into the model which relies on previous elections where similar ups and downs have occurred.
Jim:
Not quite. Quincel’s got a point. Our model does implicitly account for past prediction errors, but it doesn’t account for uncertainty in the predictors.
Wasn’t uncertainty in the predictors the entire ballgame in 2016? Not volatility but bias. Everyone thought Clinton would win but it was a consistent bias driving that. If we had high quality pills with ~100% response… Things would have looked different.
It seems your fundamentals model tries to address this. What else are you doing to address this?
Daniel –
> Everyone thought Clinton would win but it was a consistent bias driving that.
What was the bias of which you speak?
Maybe a bias explains why people underestimated the possibility that many states’ polling were off in the same direction?
IIRC, some states’ polling was outside the MOE but that was largely because of late-deciding voters and perhaps because of late-breaking events; iirc, much of the national polling was within the MOE?
The problem is that through time polling by telephone has gotten FAR less reliable. Response rates have gone from way up above 40% down to like 9%:
https://www.pewresearch.org/methods/2017/05/15/what-low-response-rates-mean-for-telephone-surveys/
Furthermore vast swaths of america don’t have landlines anymore at all.
All this means, no-one really knows what population they’re targeting by telephone polling. Andrew has done some work on adjusting these polls based on demographics, but I’m pretty convinced that telephone polling has lost its edge. It’s a little like testing for a disease that has 2% prevalence with a test that has 3% false positives.
Suppose that telephone polling has overall an 8 percent bias which through adjustments can be brought down to 4%… But of course we don’t know that. So we’re making predictions based on highly adjusted polls which still give consistent 4% errors that we’re not really aware of… Well this makes the polls useless, because in the modern world elections are won by ~2% differences.
This is why I asked Andrew if he’s got in his model an unknown measurement error bias. If you take his estimates and acknowledge a normal(0,3) percentage point residual measurement bias in all of the polls… I don’t think you’d be saying 85% chance of winning. It’d probably drop to like 59% which is only slightly better than flipping a coin and calling the winner.
There isn’t that much information in polls with 9% response rate with complicated response biases. Whatever info there is, I expect Andrew knows how to extract it… but if there’s not much to begin with… it’s rough
While it is true that response rates have gone down, it is not true that polling has gotten noticeably less reliable (https://fivethirtyeight.com/features/the-polls-are-all-right/).
Interesting. I certainly don’t have any expertise in polling. But it’s interesting that 538’s analysis says that proper high probability density intervals for real polls are about 10-15 percentage points wide, and ALWAYS HAVE BEEN.
He then goes on to say that averaging polls helps a lot. And this is where my concern lies: what if there are consistent biases in polling that have gotten worse over time as response rates have gotten worse.
We only have a couple of election cycles to evaluate that kind of bias. I don’t think 538’s analysis addresses this concern. In fact he even mentions that averaging polls doesn’t help when they all go the wrong direction together… but dismisses the issue immediately and goes on to say that averaging is a good thing. Maybe that’s true, and maybe he has the info to prove it, but I didn’t see it skimming that article.
I just don’t think we know a lot about these potential consistent biases because we don’t have a lot of elections to look at in the period post conversion to mostly-cell-phones.
Googling graphs of cell phone adoption and smart phone adoption. I think 2015 or so is an important year: https://www.statista.com/chart/2072/landline-phones-in-the-united-states/
So what polling is like today vs what it was like in 2012 might be very different. And yet there has only been ONE presidential election in that time frame.
Daniel:
Fair point! We don’t really have a large enough sample size at the moment to properly evaluate this, but for what it’s worth, it seems that the polling for the 2018 midterms was also quite accurate (https://www.cnn.com/2018/11/19/politics/2018-midterm-elections-good-year-polls/index.html).
“Anything could happen tomorrow and change the probabilities”
is this not “uncertainty in the predictors”?
Jim:
Sure, but suppose the forecast is based on conditions in June, so we’re comparing June 2020 with June in previous election years. Now further suppose that there’s more uncertainty in 2020 then in previous years. So we’d want our forecast to incorporate this uncertainty in the economic and political conditions in the next few months, beyond the uncertainty that was happening in earlier years.
From a mathematical standpoint I see your point. But is there really any more (or less) uncertainty in 2020 than there was in any previous election? How can you know that? And if it’s just the spread or volatility in this election vs. past elections wouldn’t that already be in your model?
I still wonder how should the reader interpret the different elements in the “modeled popular vote on each day” chart. From the explanatory article it seems that these “95% confidence intervals” should be interpreted probabilistically, but the probability of what precisely? It’s not very clear, in particular for the part of the chart to the right of the current date.
The article ends with: “And if our stated probabilities do wind up diverging from the results, we will welcome the opportunity to learn from our mistakes and do better next time.” What does it mean for the result and your stated probabilities to diverge? Does a Trump victory at the election count as a divergence given that the model claims that the probability is 12%?
I agree. It looks to me like the probability of a particular polling share… but it seems weird that the interval stays basically constant through time. Perhaps its the probability of not an aggregate polling share, but any given poll reporting a given share. Which then the width being constant says essentially that the polls have variability that is pretty much constant.
So, it’s kind of the difference between stddev of population and standard error of estimate kind of thing.
The explanation contains the following paragraph, but it’s unclear if it has any relation to what is shown in the chart:
“For every day that remains until the election, the MCMC process allows state polling averages to drift randomly by a small amount in each of its 20,000 simulations. Each step of this “random walk” can either favour Democrats or Republicans, but is more likely to be in the direction that the “prior” prediction would indicate than in the opposite one. These steps are correlated, so that a shift towards one candidate in a given state is likely to be mirrored by similar shifts in similar states. As the election draws near, there are fewer days left for this random drift to accumulate, reducing both the range of uncertainty surrounding the current polling average and the influence of the prior on the final forecast. In states that are heavily polled late in the race, the model will pay little attention to its prior forecast; conversely, it will emphasise the prior more early in the race or in thinly-polled states (particularly ones for which it cannot make reliable assumptions based on polls of similar states).”
The Republicans not nominating Trump would be the black swan event, because it changes the status of the Republican candidate away from “incumbent”, and that affects the fundamentals.
From the methodology:
“The 2020 election presents an unusual difficulty, because the recession caused by the coronavirus is both far graver than any other post-war downturn, and also more likely to turn into a rapid recovery once lockdowns lift. History provides no guide as to how voters will respond to these extreme and potentially fast-reversing economic conditions. As a result, we have adjusted this economic index to pull values that are unprecedentedly high or low partway towards the limits of the data on which our model was trained. As of June 2020, this means that we are treating the recession caused by the coronavirus pandemic as roughly 40% worse than the Great Recession of 2008-09, rather than two to three times worse.”
Choosing “40% worse than the Great Recession” sounds like guesswork. Without any history as guide, would it be more sound to exclude this variable from the fundamentals model?
Kai:
It’s possible to play around with the model can get just about anything. But for both theoretical and empirical reasons, I think that bad economic conditions are bad for the incumbent, and I think it would be a mistake to remove this information from the prediction. Just as an example, recall that the bad economy in 1980 was in part due to an oil price hike following the Iranian revolution.
Since 2020 economic conditions present an “unusual difficulty” is it possible to produce results based on low, middle, and high values for treating the covid recession?
The unrest in Kenosha since the August 23 shooting of Jacob Blake has dimmed Biden’s campaign according to the betting odds. According to the RealClearPolitics betting odds index, Biden’s had a 12 point advantage over Trump on August 23. It is now only 2 points. https://www.realclearpolitics.com/elections/betting_odds/2020_president/
Can the model capture the anger and anxiety of voters over unrest that many blame Democratic Party rhetoric for kindling? Your colleague Mr Morris is highly skeptical that the unrest in Kenosha will benefit Trump (below). I highly disagree.
“I don’t think we can look at trends in polls this summer, which included numerous news cycles about BLM protests & abt violence/looting/unrest, and conclude that THIS TIME it’ll be different and Trump will get a bounce. Our prior should be that it won’t matter to the horse race.
10:52 PM · Aug 30, 2020”
Donald trump is going to win 100%