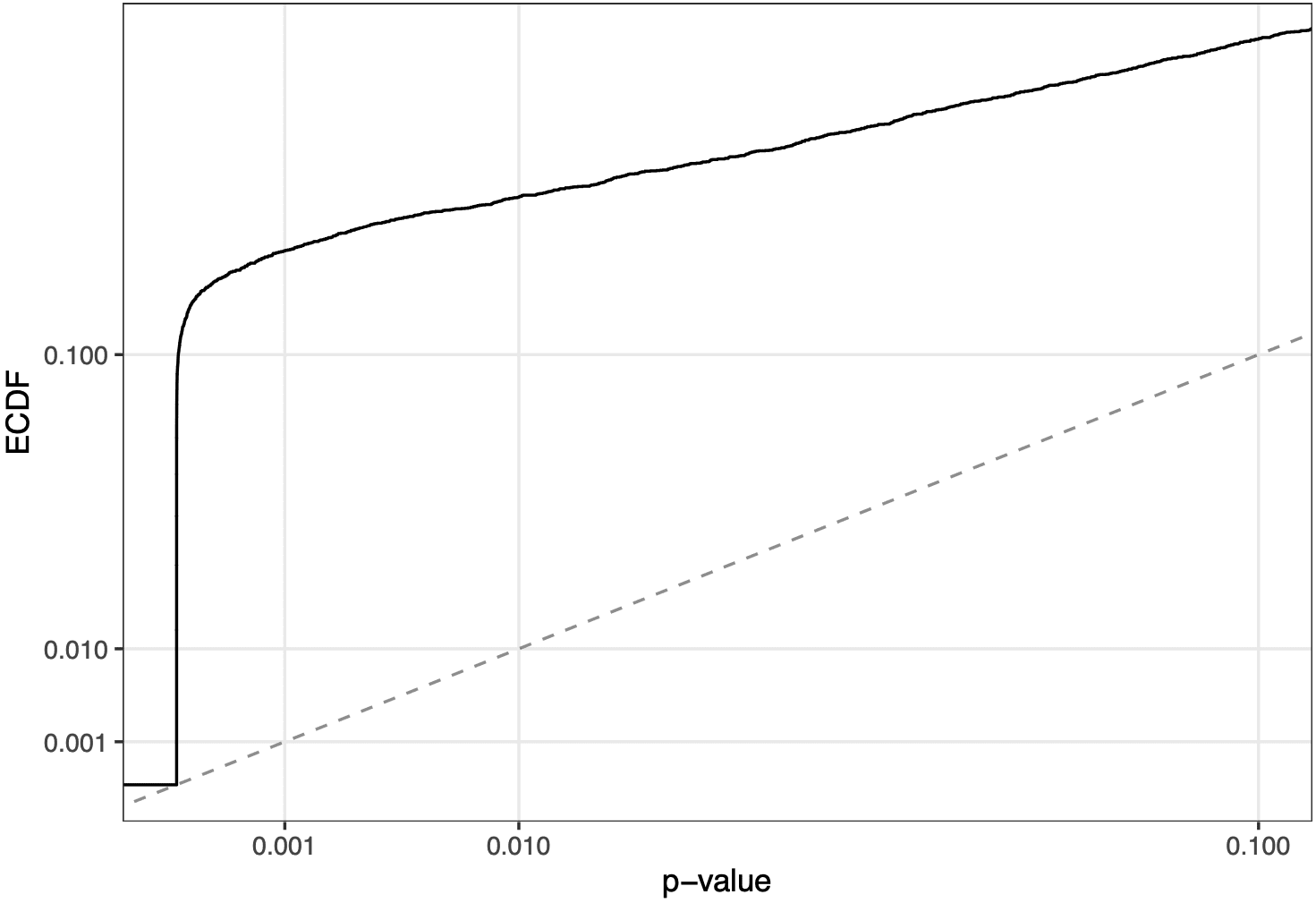
OK, this one’s in our wheelhouse. So I’ll write about it. I just want to say that writing this sort of post takes a lot of effort. When it comes to social engagement, my benefit/cost ratio is much higher if I just spend 10 minutes writing a post about the virtues of p-values or whatever. Maximizing the number of hits and blog comments isn’t the only goal, though, and I do find that writing this sort of long post helps me clarify my thinking, so here we go. . . .
Jonathan Ben-Menachem writes:
Two criminal justice reform heavyweights are trading blows over a seemingly arcane subject: research methods. . . . Jennifer Doleac, Executive Vice President of Criminal Justice at Arnold Ventures, accused the Vera Institute of Justice of “research malpractice” for their evaluation of New York college-in-prison programs. In a response posted on Vera’s website, President Nick Turner accused Doleac of “giving comfort to the opponents of reform.”
At first glance, the study at the core of this debate doesn’t seem controversial: Vera evaluated Manhattan DA-funded college education programs for New York prisoners and found that participants were less likely to commit a new crime after exiting prison. . . . Vera used a method called propensity score matching, and constructed a “control” group on the basis of prisoners’ similarity to the “treatment” group. . . . Despite their acknowledgment that “differences may remain across the groups,” Vera researchers contended that “any remaining differences on unobserved variables will be small.”
Doleac didn’t buy it. . . . She argued that propensity score matching could not account for potentially different “motivation and focus.” In other words, the kind of people who apply for classes are different from people who don’t apply, so the difference in outcomes can’t be attributed to prison education. . . .
Here’s Doleac’s full comment:
Vera Institute just released this study of a college-in-prison education program in NY, funded by the Manhattan DA’s Criminal Justice Investment Initiative. Researchers compared people who chose to enroll in the program with similar-looking people who chose not to. This does not isolate the treatment effect of the education program. It is very likely that those who enrolled were more motivated to change, and/or more able to focus on their goals. This pre-existing difference in motivation & focus likely caused both the difference in enrollment in the program and the subsequent difference in recidivism across groups.
This report provides no useful information about whether this NY program is having beneficial effects.
Now we return to Ben-Menachem for some background:
This fight between big philanthropy and a nonprofit executive is extremely rare, and points to a broader struggle over research and politics. The Vera Institute boasts a $264 million operating budget, and . . . has been working on bail reform since the 1960s. Arnold Ventures was founded in 2010, and the organization has allocated around $400 million to criminal justice reform—some of which went to Vera.
How does the debate over methods relate to larger policy questions? Ben-Menachem writes:
Although propensity score matching does have useful applications, I might have made a critique similar to Doleac if I was a peer reviewer for an academic journal. But I’m not sure about Doleac’s claim that Vera’s study provides “no useful information,” or her broader insistence on (quasi) experimental research designs. Because “all studies on this topic use the same flawed design,” Doleac argued, “we have *no idea* whether in-prison college programming is a good investment.” This is a striking declaration that nothing outside of causal inference counts.
He connects this to an earlier controversy:
In 2018, Doleac and Anita Mukherjee published a working paper called “The Moral Hazard of Lifesaving Innovations: Naloxone Access, Opioid Abuse, and Crime” which claimed that naloxone distribution fails to reduce overdose deaths while also “making riskier opioid use more appealing.” In addition to measurement problems, the moral hazard frame partly relied on an urban myth—“naloxone parties,” where opioid users stockpile naloxone, an FDA approved medication designed to rapidly reverse overdose, and intentionally overdose with the knowledge that they can be revived. The final version of the study includes no references to “naloxone parties,” removes the moral hazard framing from the title, and describes the findings as “suggestive” rather than causal.
Later that year, Doleac and coauthors published a research review in Brookings citing her controversial naloxone study claiming that both naloxone and syringe exchange programs were unsupported by rigorous research. Opioid health researchers immediately demanded a retraction, pointing to heaps of prior research suggesting that these policies reduce overdose deaths (among other benefits). . . .
Ben-Menachem connects this to debates between economists and others regarding the role of causal inference. He writes:
While causal inference can be useful, it is insufficient on its own and arguably not always necessary in the policy context. By contrast, Vera produces research using a very wide variety of methods. This work teaches us about the who, where, when, what, why, and how of criminalization. Causal inference primarily tells us “whether.”
I disagree with him on this one. Propensity score matching (which should be followed up with regression adjustment; see for example our discussion here) is a method that is used for causal inference. I will also channel my causal-inference colleagues and say that, if your goal is to estimate and understand the effects of a policy, causal inference is absolutely necessary. Ben-Menachem’s mistake is to identify “causal inference” with some particular forms of natural-experiment or instrumental-variables analyses. Also, no matter how you define it, causal inference primarily tells us, or attempts to tell us, “how much” and “where and when,” not “whether.” I agree with his larger point, though, which is that understanding (what we sometimes call “theory”) is important.
I think Ben-Menachem’s framing of this as economists-doing-causal-inference vs. other-researchers-doing-pluralism misses the mark. Everybody’s doing causal inference here, one way or another, and indeed matching can be just fine if it is used as part of a general strategy for adjustment, even if, as with other causal inference methods, it can do badly when applied blindly.
But let’s move on. Ben-Menachem continues:
In a recent interview about Arnold Ventures’ funding priorities, Doleac explained that her goal is to “help build the evidence base on what works, and then push for policy change based on that evidence.” But insisting on “rigorous” evidence before implementing policy change risks slowing the steady progress of decarceration to a grinding halt. . . .
In an email, Vera’s Turner echoed this point. “The cost of Doleac’s apparently rigid standard is that it not only devalues legitimate methods,” he wrote, “but it sets an unreasonably and unnecessarily high burden of proof to undo a system that itself has very little evidence supporting its current state.”
Indeed, mass incarceration was not built on “rigorous research.” . . . Yet today some philanthropists demand randomized controlled trials (or “natural experiments”) for every brick we want to remove from the wall of mass incarceration. . . .
Decarceration is a fight that takes place on the streets and in city halls across America, not in the halls of philanthropic organizations. . . . the narrow emphasis on the evaluation standards of academic economists will hamstring otherwise promising efforts to undo the harms of criminalization.
Several questions arise here:
1. What can be learned from this now-controversial research project? What does it tell us about the effects of New York college-in-prison programs, or about programs to reduce prison time?
2. Given the inevitable weaknesses of any study of this sort (including studies that Doleac or I or other methods critics might like), how should its findings inform policy?
3. What should advocates’ or legislators’ views of the policy options be, given that the evidence in favor of the status quo is far from rigorous by any standard?
4. Given questions 1, 2, 3 above, what is the relevance of methodological critiques of any study in a real-world policy context?
Let me go through these four questions in turn.
1. What can be learned from this now-controversial research project?
First we have to look at the study! Here it is: “The Impacts of College-in-Prison Participation on Safety and Employment in New York State: An Analysis of College Students Funded by the Criminal Justice Investment Initiative,” published in November 2023.
I have no connection to this particular project, but I have some tenuous connection to both of the organizations involved in this debate, as many years ago I attended a brief meeting at the Arnold Foundation regarding a study being done by the Vera Institute regarding a program they were doing in the correctional system. And many years ago my aunt Lucy taught math at Sing Sing prison for awhile.
Let’s go to the Vera report, which concludes:
The study found a strong, significant, and consistent effect of college participation on reducing new convictions following release. Participation in this form of postsecondary education reduced reconviction by at least 66 percent. . . .
Vera also conducted a cost analysis of these seven college-in-prison programs . . . Researchers calculated the costs reimbursed by CJII, as well as two measures of the overall cost: the average cost per student and the costs of adding an additional group of 10 or 20 students to an existing college program . . . Adding an additional group of 10 or 20 students to those colleges that provided both education and reentry services would cost colleges approximately $10,500 per additional student, while adding an additional group of students to colleges that focused on education would cost approximately $3,800 per additional student. . . . The final evaluation report will expand this cost analysis to a benefit-cost analysis, which will evaluate the return on investment of these monetary and resource outlays in terms of avoided incarceration, averted criminal victimization, and increased labor force participation and improved income.
And they connect this to policy:
This research indicates that academic college programs are highly effective at reducing future convictions among participating students. Yet, interest in college in prison among prospective students far outstrips the ability of institutions of higher education to provide that programming, due in no small part to resource constraints. In such a context, funding through initiatives such as CJII and through state and federal programs not only supports the aspirations of people who are incarcerated but also promotes public safety.
Now let’s jump to the methods. From page 13 of the report onward:
To understand the impact of access to a college education on the people in the program, Vera researchers needed to know what would have happened to these people if they had not participated in the program. . . . Ideally, researchers need these comparisons to be between groups that are otherwise as similar as possible to guard against attributing outcomes to the effects of education that may be due to the characteristics of people who are eligible for or interested in participating in education. In a fair comparison of students and nonstudents, the only difference between the two is that students participated in college education in prison while nonstudents did not. . . . One study of the impacts of college in prison on criminal legal system outcomes found that people who chose or were able to access education differed in their demographics, employment and conviction histories, and sentence lengths from people who did not choose or have the ability to access education. This indicates a need for research and statistical methods that can account for such “selection” into college education . . .
The best way to create the fair comparisons needed to estimate causal effects is to perform a randomized experiment. However, this was not done in this study due to the ethical impact of withholding from a comparison group an intervention that has established positive benefits . . . Vera researchers instead aimed to create a fairer comparison across groups using a statistical technique called propensity score matching . . . Vera researchers matched students and nonstudents on the following variables:
– demographics . . .
– conviction history . . .
– correctional characteristics . . .
– education characteristics . . .
Researchers considered nonstudents to be eligible for comparison not only if they met the same academic and behavioral history requirements as students but also if they had a similar time to release during the CIP period, a similar age at incarceration, and a similar time from prison admission to eligibility. . . . when evaluating whether an intervention influences an outcome of interest, it is a necessary but not sufficient condition that the intervention happens before the outcome. Vera researchers therefore defined a “start date” for students and a “virtual start date” for nonstudents in order to determine when to begin measuring in-facility outcomes, which included Tier II, Tier III, high-severity, and all misconducts. . . . To examine the effect of college education in prison on misconducts and on reported wages, Vera researchers used linear regression on the matched sample. For formal employment status and for an incident within six months and 12 months of release that led to a new conviction, Vera used logistic regression on the matched sample. For recidivism at any point following release, Vera used survival analysis on the matched sample to estimate the impact of the program on the time until an incident that leads to a new conviction occurs.
What about the concern expressed by Doleac regarding differences that are not accounted for by the matching and adjustment variables? Here’s what the report says:
Vera researchers have attempted to control [I’d prefer the term “adjust” — ed.] for pre-incarceration factors, such as conviction history, age, and gender, that may contribute to misconducts in prison. However, Vera was not able to control for other pre-incarceration factors that have been found in the literature to contribute to misconducts, such as marital status and family structure, mental health needs, a history of physical abuse, antisocial attitudes and beliefs, religiosity, socioeconomic disadvantage and exposure to geographically concentrated poverty, and other factors that, if present, would still allow a person to remain eligible for college education but might influence misconducts. Vera researchers also have not been able to control for factors that may be related to misconducts, including characteristics of the prison management environment, such as prison size, and the proportion of people incarcerated under age 25, as Vera did not have access to information about the facilities where nonstudents were incarcerated. Vera also did not have access to other programs that students and nonstudents may be participating in, such as work assignments, other programming, or health and mental health service engagement, which may influence in-facility behavior and are commonly used as controls in the literature. If other literature on the subject is correct and education does help to lower misconducts, Vera may have, by chance, mismatched students with controls who, unobserved to researchers and unmeasured in the data, were less likely to have characteristics or be exposed to environments that influence misconducts. While prior misconducts, assigned security class, and time since admission may, as proxies, capture some of this information, they may do so imperfectly.
They have plans to mitigate these limitations going forward:
First, Vera will receive information on new students and newly eligible nonstudents who have enrolled or become eligible following receipt of the first tranche of data. Researchers will also have the opportunity to follow the people in the analytical sample for the present study over a longer period of time. . . . Second, researchers will receive new variables in new time periods from both DOCCS and DOL. Vera plans to obtain more detailed information on both misconducts and counts of misconducts that take place in different time periods for the final report. . . . Next, Vera will obtain data on pre-incarceration wages and formal employment status, which could help researchers to achieve better balance between students and nonstudents on their work histories . . .
In summary: Yeah, observational studies are hard. You adjust for what you can adjust for, then you can do supplementary analyses to assess the sizes and directions of possible biases. I’m kinda with Ben-Menachem on this one: Doleac’s right that the study “does not isolate the treatment effect of the education program,” but there’s really no way to isolate this effect—indeed, there is no single “effect,” as any effect will vary by person and depend on context. But to say that the report “provides no useful information” about the effect . . . I think that’s way too harsh.
Another way of saying this is that, speaking in general terms, I don’t find adjusting for existing pre-treatment variables to be a worse identification strategy than instrumental variables, or difference-in-differences, or various other methods that are used for causal inference from observational studies. All these methods rely on strong, false assumptions. I’m not saying that these methods are equivalent, either in general or in any particular case, just that all have flaws. And indeed, in her work with the Arnold Foundation, Doleac promotes various criminal-justice reforms. So I’m not quite sure why she’s so bothered by this particular Vera study. I’m not saying she’s wrong to be bothered by it; there just must be more to the story, other reasons she has for concern that were not mentioned in her above-linked social media post.
Also, I don’t believe that estimate from the Vera study that the treatment reduces recidivism by 66%. No way. See the section “About that ’66 percent'” below for details. So there are reasons to be bothered by that report; I just don’t quite get where Doleac is coming from in her particular criticism.
2. Given the inevitable weaknesses of any study of this sort, how should its findings inform policy?
I guess it’s the usual story: each study only adds a bit to the big picture. The Vera study is encouraging to the extent that it’s part of a larger story that makes sense and is consistent with observation. The results so far seem too noisy to be able to say much about the size of the effect, but maybe more will be learned from the followups.
3. What should advocates’ or legislators’ views of the policy options be, given that the evidence in favor of the status quo is far from rigorous by any standard?
This I’m not sure. It depends on your understanding of justice policy. Ben-Menachem and others want to reduce mass incarceration, and this makes sense to me, but others have different views and take the position that mass incarceration has positive net effects.
I agree with Ben-Menachem that policymakers should not stick with the status quo, just on the basis that there is no strong evidence in favor of a particular alternative. For one thing, the status quo is itself relatively recent, so it’s not like it can be supported based on any general “if it ain’t broke, don’t fix it” principle. But . . . I don’t think Doleac is taking a stick-with-the-status-quo position either! Yes, she’s saying that the Vera study “provides no useful information”—a statement I don’t really agree with—but I don’t see her saying that New York’s college-in-prison education program is a bad idea, or that it shouldn’t be funded. I take Doleac as saying that, if policymakers want to fund this program, they should be clear that they’re making this decision based on their theoretical understanding, or maybe based on political concerns, not based on a solid empirical estimate of its effects.
4. Given questions 1, 2, 3 above, what is the relevance of methodological critiques of any study in a real-world policy context?
Methodological critique can help us avoid overconfidence in the interpretation of results.
Concerns such as Doleac’s regarding identification help us understand how different studies can differ so much in their results: in addition to sampling variation and varying treatment effect, the biases of measurement and estimation depend on context. Concerns such as mine regarding effect sizes should help when taking exaggerated estimates and mapping them to cost-benefit analyses.
Even with all our concerns, I do think projects such as this Vera study are useful in that they connect the qualitative aspects of administrating the program with quantitative evaluation. It’s also important that the project itself has social value and that the proposed mechanism of action makes sense. I’m reminded of our retrospective control study of the Millennium Villages project (here’s the published paper, here and here are two unpublished papers on the design of the study, and here’s a later discussion of our study and another evaluation of the project): the study could never have been perfect, but we learned a lot from doing a careful comparison.
To return to Ben-Menachem’s post, I think the framing of this as a “fight over rigor” is a mistake. The researchers at the Vera Institute and the economist at the Arnold Foundation seem to be operating at the same, reasonable, level of rigor. They’re concerned about causal identification and generalizability, they’re trying to learn what they can from observational data, etc. Regression adjustment with propensity scores is no more or less rigorous than instrumental variables or change-point analysis or multilevel modeling or any other method that might be applied in this sort of problem. It’s really all about the details.
It might help to compare this to an example we’ve discussed in this space many times before: flawed estimates of the effect of air pollution on lifespan. There’s lot of theory and evidence that air pollution is bad for your life expectancy. The theory and evidence are not 100% conclusive—there’s this idea that a little bit of pollution can make you stronger by stimulating your immune system or whatever—but we’re pretty much expecting heavy indoor air pollution to be bad for you.
The question then comes up, what is learned that is policy relevant from a really bad study of the effects of air pollution. I’d say, pretty much nothing. I have a more positive take on the Vera study, partly because it is very directly studying the effect of a treatment of interest. The analysis has some omitted variables concerns, also the published estimates are, I believe, way too high, but it still seems to me to be moving the ball forward. I guess that one way they could do better would be to focus on more immediate outcomes. I get that reduction in recidivism is the big goal, but that’s kind of indirect, meaning that we would expect smaller effects and noisier estimates. Direct outcomes of participation in the program could be a better thing to focus on. But I’m speaking in general terms here, as I have no knowledge of the prison system etc.
About that “66 percent”
As noted above, the Vera study concluded:
Participation in this form of postsecondary education reduced reconviction by at least 66 percent.
“At least 66 percent” . . . where did this come from? I searched the paper for “66” and found this passage:
Vera’s study found that participation in college in prison reduced the risk of reconviction by 66 to 67 percent (a relative risk of 0.33 and 0.34). (See Table 7.) The impact of participation in college education was found to reduce reconviction in all three of the analyses (six months, 12 months, and at any point following release). The consistency of estimated treatment effects gives Vera confidence in the validity of this finding.
And here is the relevant table:
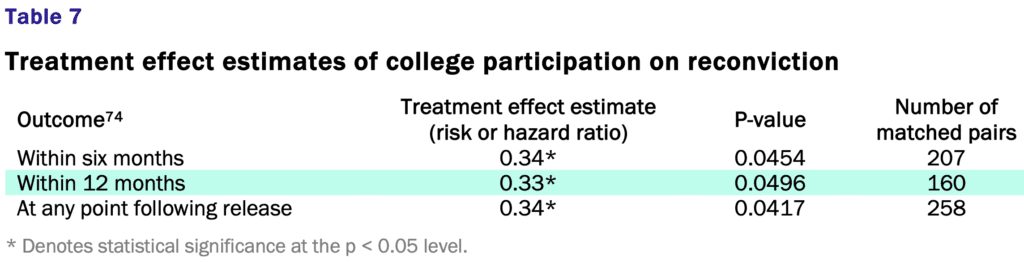
Ummmm . . . no. Remember Type M errors? The raw estimate is HUGE (a reduction in risk of 66%) and the standard error is huge too (I guess it’s about 33%, given that a p-value of 0.05 corresponds to an estimate that’s approximately two standard errors away from zero) . . . that’s the classic recipe for bias.
Give it a straight-up Edlin factor of 1/2 and your estimated effect is to reduce the risk of reconviction by 33%, which still sounds kinda high to me, but I’ll leave this one to the experts. The Vera report states that they “detected a much stronger effect than prior studies,” and those prior studies could very well be positively biased themselves, so, yeah, my best guess is that any true average effect is less than 33%.
So when they say, “at least 66 percent”: I think that’s just wrong, an example of the very common statistical error of reporting an estimate without correcting for bias.
Also, I don’t buy that the result appearing in all three of the analyses represents a “consistency of estimated treatment effects” that should give “confidence in the validity of this finding.” The three analyses have a lot of overlap, no? I don’t have the raw data to check what proportion of the reconvictions within 12 months or at any point following release already occurred within 6 months, and I’m not saying the three summaries are entirely redundant. But they’re not independent pieces of information either. I have no idea why the estimates are soooo close to each other; I guess that is probably just one of those chance things which in this case give a misleading illusion of consistency.
Finally, to say a risk reduction of “66 to 67 percent” is a ridiculous level of precision, given that even if you were to just take the straight-up classical 95% intervals you’d get a range of risk reductions of something like 90 percent to zero percent (a relative risk between 0.1 and 1.0).
So we’re seeing overestimation of effect size and overconfidence in what can be learned by the study, which is an all-too-common problem in policy analysis (for example here).
None of this has anything to do with Doleac’s point. Even with no issues of identification at all, I don’t think this treatment effect estimate of 66% (or “at least 66%” or “66 to 67 percent”) decline in recidivism should be taken seriously.
To put it another way, if the same treatment were done on the same population, just with a different sample of people, what would I expect to see? I don’t know—but my best estimate would be that the observed difference would be a lot less than 66%. Call it the Edlin factor, call it Type M error, call it an empirical correction, call it Bayes; whatever you want to call it, I wouldn’t feel comfortable taking that 66% as an estimated effect.
As I always say for this sort of problem, this does not mean that I think the intervention has no effect, or that I have any certainty that the effect is less than the claimed estimate. The data are, indeed, consistent with that claimed 66% decline. The data are also consistent with many other things, including (in my view more plausibly) smaller average effects. What I’m disagreeing with is the claim that the study demonstrates provides strong evidence for that claimed effect, and I say this based on basic statistics, without even getting into causal identification.
P.S. Ben-Menachem is a Ph.D. student in sociology at Columbia and he’s published a paper on police stops in the APSR. I don’t recall meeting him, but maybe he came by the Playroom at some point? Columbia’s a big place.