I have mixed feelings about this picture
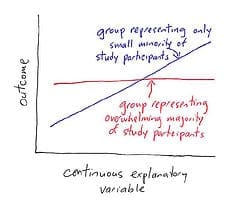
and accompanying note of Jeremy Freese, who writes:
Key findings in quantitative social science are often interaction effects in which the estimated “effect” of a continuous variable on an outcome for one group is found to differ from the estimated effect for another group. . . . Interaction effects are notorious for being much easier to publish than to replicate, partly because it is easy for researchers to forget (?) how they tested many dozens of possible interactions before finding one that is statistically significant and can be presented as though it was hypothesized by the researchers all along. . . . There are so many ways of dividing a sample into subgroups, and there are so many variables in a typical dataset that have low correlation with an outcome, that it is inevitable that there will be all kinds of little pockets for high correlation for some subgroup just by chance.
I take his point, and indeed I’ve written myself about the perils of fishing for statistical significance in a pond full of weak effects (uh, ok, let’s shut down that metaphor right there). And I even cite Freese in my article.
On the other hand, I’m also on record as saying that interactions are important (see also here).
I guess my answer is that interactions are important, but we should look for them where they make sense. Jeremy’s graph reproduced above doesn’t really give enough context. Also, remember that the correlation between before and after measurements will be higher among controls than among treated units.
Age-old multiple comparisons question… because of the coming together of data mining and statistics, we now recognize that there is some value to looking for interactions but of course, the more you look, the more likely to see spurious ones. The opposite is also true: the less you look, the less likely to see real ones.
I think we just need to do confirmation studies, or be more exacting in doing validation of models.
The point about fishing for interactions is a valid one. Also observational studies with continuous predictors have notoriously low power to detect interactions. Combined this means that i) many interactions effects in such studies are spurious and don't replicate, ii) many genuine interesting and important interaction effects can't be detected or replicated.
The solution is perhaps to design studies specifically to test interaction effects of particulat theoretical or applied interest and importance. This is relatively easy for experimental research but can also be done for observational studies if you oversample the extremes on the predictors thought to interact.
Thom,
But in many examples, the interactions are more important than the main effects. And, if we're going to have a default model (which we always will), I don't think that zero-interactions is always the appropriate default.
I'm wary of default models – but they are very hard to avoid and have their uses. I certainly wouldn't want to default to zero interactions in all (or even most) cases. I guess I'm more cautious because (sadly) many areas of psychology have small N that makes power to detect interactions particularly poor.