
Part 1:
Here’s a 1993 article from the American Sociological Review in which church attendance was measured by the number of cars in the parking lot (link from here).
Part 2:
In 2005 or 2006, an economist who does statistics reportedly tries to run over a sociologist who does statistics in a parking lot (but see denial here).
Part 3:
Commenter Zhao Fang argues that a recent preprint that claims evidence of coronavirus cases in China in 2019 is flawed because of misleading parking lot photos (see image above).
The preprint in question, “Analysis of hospital traffic and search engine data in Wuhan China indicates early disease activity in the Fall of 2019,” has perhaps received extra attention and respect because the corresponding author is a professor at Harvard medical school (and also the “Chief Innovation Officer” (?) of Boston Children’s Hospital).
Here’s their graph summarizing the car-park data:
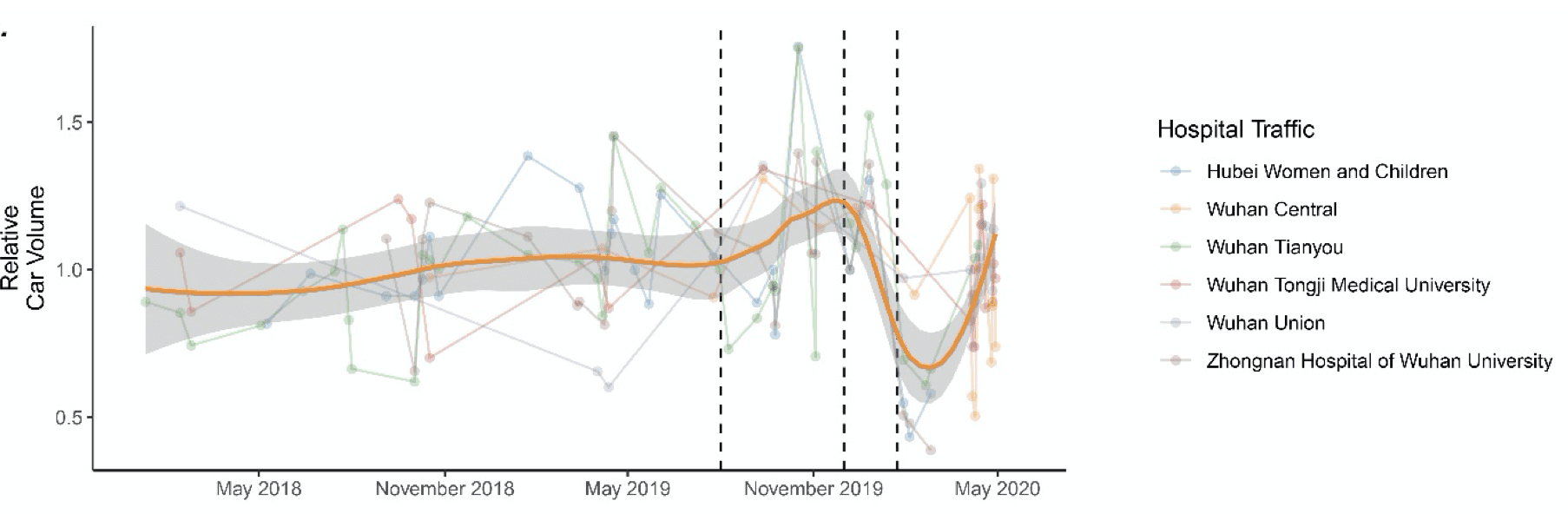
The lines jump around a lot so it’s not clear what to make of this. Much depends on the data quality. They say, “Images with tree cover, building shadow, construction and other factors that present difficulties in defining the contours were excluded since this could lead to over- or under-counting of the number of vehicles.” I guess they should just post all their images online and then other people can check their counts.
I really have no idea what to think on this one. On one hand, Fang’s parking lot image is pretty compelling. On the other hand, just cos a paper has an author from Harvard, we shouldn’t automatically assume the data are junk. They do some good work at Harvard too, right? We should be careful not to judge a paper too harshly just because of the institutional affiliations of its authors. For one thing, the other authors of the paper are from Boston University, which maybe has less of a reputation for data opportunism?
In all seriousness, I know nothing about Chinese hospital parking lots, and I know nothing about the progress of coronavirus in 2019. The point here is not that this work is wrong of that ABC News should not have featured it (in that report, it says that one of the authors of the study is “an ABC News contributor,” whatever that means).
My take-home point here is that the authors should post all their data. The ABS news report says that “the study has been submitted to the journal Nature Digital Medicine and is under peer review.” So this is easy. If Nature Digital Medicine (or any journal) is interested in publishing this paper, they should make it a condition that the authors post all their data, including the images they excluded from their analysis.
Was there a mini-epidemic of coronavirus in Wuhan in late 2019? This is an important question, important enough that all data should be shared.
I suspect this wasn’t done with the help of imagery analysts from the intelligence community. Such work can be incredibly useful, but there are pitfalls. IMINT analysts would have been more aware of the off-nadir angle of the images being used.
Also, my best guess is the intel community has already done a more involved version of this kind of imagery analysis, combined it innumerable other sources of intel, and already has a shocking good timeline for the Covid-19 outbreak.
I find it unlikely, it’s not like the intel community or anyone else can easily measure the prevalence of coronavirus even in the US.
This was from an article from a couple of days ago:
> Though Chinese officials would not formally notify the World Health Organization until Dec. 31 that a new respiratory pathogen was coursing through Wuhan, U.S. intelligence caught wind of a problem as early as late November and notified the Pentagon, according to four sources briefed on the confidential information.
https://t.co/qYBq0NKQeD?amp=1
Also, there’s this kind of stuff from back in April:
> WASHINGTON — U.S. spy agencies collected raw intelligence hinting at a public health crisis in Wuhan, China, in November, two current and one former U.S. official told NBC News, but the information was not understood as the first warning signs of an impending global pandemic.
The intelligence came in the form of communications intercepts and overhead images showing increased activity at health facilities, the officials said. The intelligence was distributed to some federal public health officials in the form of a “situation report” in late November, a former official briefed on the matter said. But there was no assessment that a lethal global outbreak was brewing at that time, a defense official said
http://www.nbcnews.com/news/amp/ncna1180646
> This was from an article from a couple of days ago
That first article is just citing the study here.
> U.S. spy agencies collected raw intelligence hinting at a public health crisis in Wuhan, China, in November, two current and one former U.S. official told NBC News, but the information was not understood as the first warning signs of an impending global pandemic.
Unnamed U.S. officials in U.S. spy agencies are not reliable sources.
I think if someone did say “pandemic” in November, they were probably looking at noise (and so if we knew their methods and applied them in other situations, we’d get a lot of false pandemics).
And this is especially true with noisy, indirect data sources like satellite photos — like it’s been hard enough for people to get a sense of the true covid19 prevalence when they’re motivated to save lives, let alone for people just hanging out at Langley waiting for the 5PM go home bell.
Note that the “officials” mentioned there are not actually stated to be part of the spy agencies. The particular officials and former officials could be Donald Trump and Bannon for all we know.
Yeah, it was very difficult to try to piece together anything in that article. Anonymous people said things things; official people appeared to respond, but anonymous people insisted things were slightly different due to wording; more officials appeared to respond — and the article just forwards all this confusion right along.
This has been the primary source of information for lots of mainstream news sources for a while now. That’s why I don’t even bother with washington post, cnn, nyt, nbc, fox, etc anymore. I could care less what an anonymous official with no track record told a reporter.
With whom do you bother?
“With whom do you bother?”
Sounds like a ten-year-old’s joke. (Or maybe a Dad joke?)
Peter schiff, Dan Bongino, Dave Haggith, Mike Maloney. Zerohedge got sold and has become overrun by trolls but still check that and every now and then theres a comment leading to good info still. Then some other reddit subs like covid19 and for different cities. Plus the conspiracy sub but thats just mostly politic stuff these days.
Then youtubers/etc like jason goodman who was the only one actually walking around showing NYC during the covid shutdown and talking to people (but get ready for him to be an asshole and go into a lot of conspiracy stuff). When the minneapolis stuff was going down unicorn riot was the best. I didnt really find similar in other cities and switched to police scanners.
On twitter these days Ill check richard cheng, sidney powell, cameron kyle-sidell, emcrit, trump.
All have their biases I disagree with but the common attribute is they dont quote anonymous officials like its reliable information.
Also wsws sometimes has good info.
> All have their biases I disagree with
Actually I need to correct this. Not Richard Cheng, havent seen any bs from him yet.
Oct and Nov are also a normal time for people to get regular old Influenza right?
So intelligence analysts may well have an idea of how much hospital usage there really was in China in October and November, but knowing that it was COV2 would be a different and more difficult task.
Zhou, you don’t need to measure the prevalence of coronavirus to put together a timeline of such things like when a hospital started getting excess cases, when they realized there was a problem, and when they took major steps to deal with it. My best guess is they not only have a good idea of these kinds of things, but have had it for a while.
This seems right, and I’d be very surprised if there were a rush on hospital usage associated with COVID-19 before Jan 1 or so. We know lockdown came Feb 11, it was clearly a problem early Feb, you can’t claim that it was a problem already in Oct or Nov without it being the entirety of Wuhan that was sick by Feb 11.
Could it have bubbled up and down for a while? Yeah, especially if it happened in outlying more rural areas. But a major epidemic? No, just because the growth rate was too crazy fast to have been going on for very long.
I doubt it started much earlier than generally thought, because of genetic evidence, but I’m not sure how certain that argument is. If we don’t know when it started we don’t know what the real growth rate was. (IE, if early cases were missed and when they started looking for it they found a bunch of cases, it would look like really fast growth).
Excess cases would be very difficult to recover from normal background cases of influenza and pneumonia etc, because normal infectious disease has a very long tailed distribution. (This is an additional way the findings can be faulty, because it may well be the case that any pattern seen is actually explained by a large norovirus outbreak or something)
You do have to distinguish one from the other some how.
Going by the official narrative, the alarm bells started ringing only when they genotyped the virus and made the connection to SARS, which was leaked by Wenliang. This seems reasonably consistent with the progression of rolling out PCR testing and other anti-disease measures – delays in the process due to reflexive coverup seem likely to be on the order of days to a maximum of a couple of weeks, not months.
Excuse me for being pedantic but Dr Li did not “leak” anything, well except accidentally.
Dr Li sent a WeChat message to some 7 or so colleagues warning about some SARS-like cases and suggesting that they should take precautions. This subsequently went viral which presumably was not his intention.
Dr. Zhang Jixian had already identified these anomalous cases and reported them to the hospital administration. It, in turn, reported this to the Wuhan CDC which in turn reported to PRC CDC who reported to the WHO and so on.
Presumably Dr. Li based his WeChat message on Dr Zhang’s findings or report since it was sent after Wuhan CDC had been notified of the cases but a day before the PRC CDC was notified.
jrkrideau –
> Excuse me for being pedantic but…
I feel rather certain in saying that is the first time that phrase has ever been written in a blog comment thread.
I commend you on your thoughtfulness. May you serve as inspiration for other blog commenters.
FWIW, the data on internet search trends should be made available as well (it is claimed that increases in Wuhan in searches on words such as “cough” also support a conclusion that an epidemic of COVID-1 9 infections started earlier than previously thought.)
Joshua:
Oh, yes, when I say that all data should be shared, I mean that all data should be shared. All code too.
My major concern with the search part of the study is p-hacking. Diarrhea is not the first symptom you think of with covid19 at all. This, plus the weird wording “symptoms of diarrhea”, makes me think they looked at a bunch of words and just reported the one they found had an effect.
Zhou:
In sharing their data, they should share the data for all the words they searched on. Also in sharing their code, they should share enough information so that others could look up other words.
> Diarrhea is not the first symptom you think of with covid19 at all.
However, it’s the first symptom for many patients (I’ve seen 20% reported, I don’t know if better estimates exist) and while it’s not very covid-specific it’s not “just the flu” as may happen with respiratory symptoms. (I’m not in any way defending that paper, I’ve not looked at it.)
My beef is not that it’s unreasonable to look at it at all, but rather that I think it’s suspicious for the term to appear out of thin air as if it’s the only search term one can possibly consider looking at. Especially with other plausible search terms showing no signal.
Belatedly, this study gives diarrhea prevalence during covid 19 of 10.4%.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7141637/
This appears on the face of it to be no more common than diarrhea during a flu infection with a prevalence of 2-30%, depending on strain.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4676820/
So I think the case for using diarrhea to distinguish between flu and covid19 appears weak.
Interesting, thanks.
This twitter user goes into detail on that. I can’t verify myself, I can’t be assed figuring out how to access BaiduIndex, but it seems legit….
https://twitter.com/WillMaStat/status/1270575010093182976
What if it’s one car being driven around and put into a time lapse? If you’re going to fabricate data, it can become an art form.
If their thesis holds, presumably there would be similar patterns that play out in hospital traffic and search engines in places as well, like in Lombardy, except delayed by some period of time but still prior to when diagnoses were starting to be made officially.
I’ve often wondered why, with all the speculation about COVID-19 spreading widely here before official diagnoses were being made, have there been surveillance attempts to identify if there was increased prevalence of pneumonia in places like NYC in January or February?
So many people are convinced they had it before official diagnoses were being made – well of so, I would think that there would have been a spike in pneumonia cases before the link to COVID-19 became so clear?
You can look up NYC here:
https://gis.cdc.gov/grasp/fluview/fluportaldashboard.html
Not sure how distinguish between covid and other causes. Or the effect of the hysteria leading to more healthcare seeking behaviour once testing began in March.
I looked into the Google trends data for “symptoms of diarrhea” (their chosen indicator) and I don’t buy it. What you see across every country I looked at (was indeed a recent peak in search activity – but the peak seemed to happen at the same date for every country (March 15) even though we know that covid pandemic progression differed. Further geographically search activity was low in New York relative to states like Alabama or Kentucky where we believe covid prevalence to be low.
My suspicion is that these search activity is actually driven more by media activity than people actually having those symptoms.
The image analysis *must* be done by hand / eye under magnification and double/triple checked by team with consensus, if the result is to be taken seriously.
If the image analysis was done by computer, then it must be regarded from the get-go with a very high degree of skepticism.
“Automated” image analysis is the meat-and-potatoes of the computer-science and engineering conference-paper racket.
The dirty secret is that it takes armies of graduate students to “tune” the thing to work correctly on the data on-hand.
I.e. it helps to know the answer in order to tune the algorithms correctly.
Change the data and the methods need to be re-tuned and/or re-invented.
You just need to use a proper hold out dataset to judge the skill on mew data.
Its very simple but yea pretty much every academic paper fails to do this.
You certainly do need to do that! But …. what you will almost certainly find is: the algorithm design is no longer optimal. E.g. you found all the checkerboard corners on the checkered cylinder floating in space, with reasonable missed-hit and false-positive rates; but now you cannot get any of the corners on the exterior view of the Louvre. Or vice-versa. No matter — the first analysis gets you and your graduate students the conference paper credit (and the trip to Boulder). The second analysis (and algorithm re-design) can be left to the next post-doc and hist coterie of graduate students and their conference paper effort.
But if your goal is to actually do something useful you will make sure to choose a good hold out to assess the skill of the model. Just because the standards in academia are so low doesn’t mean you need to do things that way.
“Here’s their graph summarizing the car-park data:”
Fraud!
This is actually Minard’s graphic of Napolean’s march on Moscow!
https://images.thoughtbot.com/analyzing-minards-visualization-of-napoleons-1812-march/minard_lg.gif
Andrew wrote: “The point here is not that this work is wrong of that ABC News should not have featured it…”
It should be: “The point here is not that this work is wrong or that ABC News should not have featured it…”
Then again, “of” in Dutch does mean “or” in English.
Virologists have estimated the timing of the evolution of SARS-CoV-2 using sequence data, e.g., https://onlinelibrary.wiley.com/doi/full/10.1002/jmv.25731 Seems like that should carry some weight.
Its good they got the model to fit the data they used to develop it, but they need to make some predictions with the model to test it on other data.
Test a model? What for? All we need is to look at the code. If the code is correct it’s all good! When your a scientist you know what you’re doing. You can forecast days weeks months years decades even centuries ahead if you know the code is good!
On the other hand, if we don’t like the outcomes of the model we can just criticize the code because it isn’t perfect.
The very odd thing about this study is – why didn’t they just use the number of hospitalizations (all causes)? It seems surreal to be counting cars in carparks (whether or not adequately controlled for camera angles and times of day) when they could have just asked the hospitals “how many people were you looking after”. They did get two hospitals’ worth of such data for two diseases (‘flu and covid), so it’s not like the hospitals weren’t co-operating.
The implicit argument in the paper is that people were searching for ‘diarrhoea’ on the internet and getting hospitalised but not diagnosed with Covid, so surely it would be simple enough to just count the hospital cases.
At a minimum, the very noisy carpark data should have been checked/validated against ‘total number of people in the hospital’ from the more traditional (and obvious) source.
The general use of this result in the commentariat is to imply some kind of massive cover up. I don’t think the authors claim this, but not using the official statistics does have a point to it – the claim is that the car counts are the “real” numbers.
Yes I agree this is what is going on. But sustain the claim that the car counts are the real numbers they should surely be compared with number of “hospitalizations all causes” as well as with “hospitalizations for covid”. Then the conspiracy theorists would be able to choose between the claims that “cases were deliberately not diagnosed as covid” and the even more remarkable “hospitalization numbers were completely made up for all diseases” (which is what is needed for the carpark counts to be useful).
Part of the problem seems like an insistence on a narrative, and searching for “data” to fill that in, sort of like a bizarro scientific method where only confirmatory evidence, no matter how weak, matters.
More Harvard stamped (and Stanford! And Alphabet!) “covid data research” making the rounds on Twitter this week https://mobile.twitter.com/shoshievass/status/1270499858969841664/photo/1 … lots of claims about data, but just like lancet scandal, the private corporations “proprietary algorithm” wont be released, and despite the fancy numbers and equations, figure9 in June 9 2020 version shows that the relative goodness of their proposed policies is totally independent of the input data https://reopenmappingproject.com/home2/_highlights/network-heterogeneity-pandemic-policy.pdf
Its just academic theoretical modeling dressed up with data
How should statistical practitioners educate audiences on making sure our models actually respond meaningfully to input data, and are not just reflecting our personal views?
The Stanford paper is only (!) 77 pages long and uses 7 different databases, some of which are public and some are not. Code and/or processed data does not seem to be available. But, it is from Stanford! I guess I should trust it. And, I’m sure peer review will be thorough. And, there are tons of predictions and scenarios for which I am sure they will be held accountable – notably, if the predictions turn out to be bad, there is plenty of rationale that could be provided for why the model was not correct (perhaps the masks that were used were not up to an adequate standard, perhaps fewer people were able to work from home than the scenario assumed, etc.). Really, I am at a loss for deciding whether these efforts are constructive or not. I’m all for model-building, and this seems to be a non-trivial attempt to model multiple interlocking pieces of reality (employment characteristics, mobility data, public policies for phased reopening, pandemic evolution, demographic characteristics, etc.). I just don’t see how anybody can keep up with these attempts or sort out which ones are useful for decision-making.
Use Bayes rule. Which ones predicted something that would be otherwise surprising? It is up to the people who devised the model to point these predictions out to you *before the data is available*. If they fail to do that you can ignore them. This is how science always worked.
I gave up on modelling it, too many unconstrained free parameters to adjust at this point (eg, if I can change R0 then I can make the epidemic curve look however I want). Strange how constant the number of new cases/day has been in the US though.
>>Strange how constant the number of new cases/day has been in the US though.
Well, the timescale that’s been true over isn’t really *that* long, and I think there are several factors ‘stabilizing’ it:
– testing has gotten notably better over the course of the pandemic in the US (not just number of tests increasing, but more awareness of hotspots eg prisons, meatpacking plants, etc and thus testing being better directed to find cases). There are probably quite a few states that are reporting flat or rising cases where true infections are actually decreasing. Even % positive tests might not show this if testing is hotspot-focused.
– possibly, less concern about social distancing in states that weren’t hit hard so far;
– even more speculatively, indoor activity *increasing* in warm-weather states (which, except Louisiana, were barely hit early on) but *decreasing* in cold-weather states.
Yea, to get a sir model to reproduce it you basically need to model different communities with infrequent interaction between them. Could be, but once a model gets so complicated and so many parameters are unconstrained by data I dont have much confidence in it.
Oh yeah, I am not defending the usefulness of the models .. it’s not so much that they are necessarily ‘wrong’, but if all the uncertainties are incorporated the confidence intervals are or would be wide enough to be not very useful in guiding decisions.
I was just talking about the “plateau” of the US case numbers.
Interestingly, deaths are generally flat or down even in states where cases and even % positive are up. Some of this may be because of lag, but GA has a clear two-peak pattern in cases and a very clear one-peak bell curve in deaths, and enough time seems to have passed after the 2nd peak in cases that it ought to be showing up.
It might be because people being infected in the last 3 weeks or so tend younger (maybe older people are being more careful? nursing homes are being better protected?) and thus a smaller proportion of the cases (and maybe fewer of the hospitalizations as well) translate into deaths.
Or it could be hot-spot testing (maybe % positive could be rising because you are testing subpopulations expected to have more cases e.g. prisons, meatpacking plants, etc?)
Or maybe supportive care is getting better so fewer hospitalized people die? (and maybe remdesivir? It’s being supplied to hospitals, but supplies are limited, no idea what % get it…)
No idea which (if any) it is, but it would probably be useful policy-wise if someone could find out…
I think as word spread to stop “intubating early” the mortality rate dropped like 5-10x. Would be nice to have data on this change in care.
I also think if they gave the patients fresh air instead of putting them in negative pressure rooms with other covid patients and added an adaptation phase when putting them on supplemental oxygen you can see mortality drop further.
Then of course start checking vitamin c levels and correcting the deficiency they will find. And of course hbot for those with lower spO2.
All relatively easy, safe, and cheap things to do.
The number of new cases per day in the US has *not* been constant, if you do a state by state breakdown.
https://twitter.com/Fang__z/status/1271400946736791553?s=20
This graph should be instructive and IMO should really *dominate* the discussion of covid in the US. In some states Covid19 has been slowly and consistently growing. In other states covid19 has been declining from an early peak. These two groups almost exactly cancel. For now.
So then you agree it’s been (nearly) constant. A plateau lasting for months is not normal for a pandemic in the US. Like I said, one way is different communities with slow contact between each other.
Ken, Dale:
I’m collaborating with one of the authors of this paper (on a different project), so that will color my view.
But in any case, I wonder if the two of you are misunderstanding the goal of posting or publication of the article. Here’s how I see it: Data integration is important. But it’s hard! One way forward is for people to try their best and then put their data and methods out there for criticism by others. Then we can all learn how to do better.
I do think it would be good for them to release all their code and as much of their data as possible.
Andrew I think that is all true. My concer is more that the data is trapped behind a corporate wall (Alphabet instead of Surgisphere this time)
Also their SIR+ model does not do anything to integrate data. Regardless of input, the output recommendation relative goodness seems to be the same (Figure 9 and Table 4). This is like if a image recognition model always saying “cat” and I am wondering how to educate general audiences to understand models that do not respond to data (too constant, like in the cat example)
> data is trapped behind a corporate wall
Assume you mean individual data are not available but summaries are/will be available from the separate data sources.
Given economic realities of the cost of data collection/management, it may be the case, that only summaries can be provided. With multiple data sources these can be contrasted and anomalies addressed.
Until there is the political will and the wide expertise needed to fund high quality purposeful for others research (rather than career building and prestige enhancing) this may be the best we can ever get.
> Assume you mean individual data are not available but summaries are/will be available from the separate data sources.
It’s not that we expect Google to share a petabyte of personal identifying cell phone tracking data. It’s really convenient they’ve taken the time to summarize this.
As far as I can tell though they don’t actually seriously discuss how they summarize stuff. Went through this a little previously: https://statmodeling.stat.columbia.edu/2020/05/22/new-report-on-coronavirus-trends-the-epidemic-is-not-under-control-in-much-of-the-us-factors-modulating-transmission-such-as-rapid-testing-contact-tracing-and-behavioural-precautions-are-cr/#comment-1342785 . tldr; didn’t find much.
> Given economic realities of the cost of data collection/management
Google seems happy to be getting credit for this, so they should also be subject to scrutiny. They took the time to make the website, presumably they can produce reports to convince us of the utility of their processing pipeline. If there’s no real attempt to document where the data came from, that really limits what the data means!
Like we get so mad around here when people don’t talk about adjustments or don’t characterize how they’re handling their data. We’re just supposed to take this Google mobility number for granted? Seems really fishy. I think the implicit argument is that somehow because Google is a successful company, the things they get involved with should be good, but that obviously isn’t good logic: https://statmodeling.stat.columbia.edu/2019/11/24/why-we-sleep-update-some-thoughts-while-we-wait-for-matthew-walker-to-respond-to-alexey-guzeys-criticisms/
> I’m collaborating with one of the authors of this paper (on a different project), so that will color my view.
What I’m saying here (and how I read Ken’s argument) isn’t a critique of the article so much as the data sources.
Anyway I’m not really an expert here maybe this is all carefully documented somewhere (I just wasn’t able to find it).
Ken: How do you conclude “figure 9 shows that the relative goodness of their proposed policies is totally independent of the input data” ? Admittedly they don’t *show* uncertainty of the results/sensitivity to data, but I don’t understand your logic.
Dale: “… sort out which ones are useful for decision-making …” Isn’t this the usual problem? I would hope that the people responsible for setting policy would take this model (or one like it) as one among a number of pieces of information. Other than gut feeling or back-of-the-envelope calculations, I don’t see what choice policy-makers have but using models …
The referenced tweet said “We’ll post code (freely reproducible using FRED instead of Replica) soon + results across all MSAs — watch for it here https://www.reopenmappingproject.com/ ” Nothing there yet, but it’s only been 3 days …
Ben: on Deaths axis EO < AS < WFH < 60+ < CR independent of input city and on Empt.Loss axis WFH < CR < 60+ < AS < EO independent of input city so the relative goodness of policy does not depend on 'underlying heterogeneity'
Something I don’t understand about the images is that there still appears to be shadows of the buildings in the 2019 image, suggesting they have been removed from the image to allow counting of vehicles in 2019, but this does not appear to have been done in the 2018 image. Are the shadows not related to the buildings? The angle and length appear to match ‘shadows’ of other structures in the image and are very similar in both images which would be expected given the point made about using images from the same time of day.
The tall building on the right is present in both images. The rightmost image is taken from a higher angle, pretty much directly above the roof. From that angle the entire parking lot is visible; in the leftmost image most of it is blocked by the building.
First glance at the parking lot plot makes it look like they captured _some_ sort of signal that wasn’t there in the prior year — there’s a spike that starts in October and then a crash in December.
But then look closer at the prior year data, and they appear to have exactly _one_* observation in the entire period from October 1, 2018 to January 1, 2018. How are you supposed to validate that we’re not simply looking at seasonal effects when the prior-year data is so sparse that it would completely miss any movement with a period of less than a few months?
In other words, it seems likely that 2018 looks so smooth because they sampled at so few dates, not because it actually was smooth.
They do have a cluster of observations in Oct 2018, but that of course isn’t enough to generate a baseline for a “normal” August to January given how sparse the other months are.
*And coincidentally — or maybe not — the one single data point they captured in Nov/Dec 2018 happens to be nearly as high as the peak they revealed in 2019. But of course their scatterplot regression line smooths it out completely because they didn’t capture any data points close enough to it to validate a buildup to or droppoff from a peak.
And what’s with the confidence interval around their regression line? How is it that it doesn’t widen where the data is sparse?
That’s it, though. I looked at the graph when it was mentioned in the comments and thought, “that data is so sparse and so noisy, how can you have the confidence that this isn’t random?”
Figure 2c in the paper shows a signal for the 2018/2019 flu season that isn’t reflected on the graph, so the initial takeaway would be that the data is unsuitable to detect anything like that (so certainly not an “under-the radar” covid outbreak. They do have a strong signal for the fall 2019 flu, which might explain some of that bump. They apparently built a new parking lot on a big hospital, which explains some. They use a “relative car volume” measure that obscures the actual numbers of cars and the sizes of the hospital. If they give the actual parking lot counts in a table, I missed it. How many extra cars are that 20% “bump”? 100 cars or more? How can you keep an increase like that hidden, and prevent the accompanying mild and asymptomatic Covid-19 cases from causing an epidemic without anyone noticing?
They don’t control for day-of-the-week in their data.
When less than a third of your data points are inside the standard error range, something’s off.
Even if the numbers were correct, I wouldn’t trust this analysis.
Catching up on my blog reading. The Harvard study has many problems, most of which can be seen on the chart Andrew included. The data were extremely unevenly spaced with only 140 points across 6 sites over 2+ years. The orange line is a loess smoother, not likely to reveal change points. The gray band appears to be just 1 standard error (and way too even given the spacing of the data). If you double that, you see there is almost nothing statistically meaningful. After this mess, you still have to deal with “story time”. Why is parking lot statistics a proxy for “hospital occupancy”? See my posts here and here for more discussion.
The first post linked above is actually here.