This is Jessica. I had been teaching visualization for years, to computer science students, informatics students, and occasionally journalism students, and recently overhauled how I do it curriculum-wise, including to focus a little more on ‘visualizations as model checks’ and visualization for decision making.
Previously I had been working from an outline of topics I’d gotten from teaching with my postdoc mentor Maneesh Agrawala, which had originated from Pat Hanrahan’s course at Stanford and I think included some materials from Jeff Heer. It was a very solid basis and so beyond adding some topics that weren’t previously represented (visualizing uncertainty, visualization to convey a narrative), I hadn’t really messed with it. But there was one issue, which seems common to lots of visualization course designs I’ve seen, which is that around midway through the quarter we’d leave the foundational stuff like grammar of graphics and effectiveness criteria behind and start traversing the various subareas of visualization focused on different data types (networks, time series, hierarchy, uncertainty) etc. Every time I taught it it felt like about midway through the course, I’d watch the excitement the students got when they realized that there are more systematic ways to think about what makes a visualization effective sort of fade as the second half of the course devolved into a grab bag of techniques for different types of data.
The new plan came about when I was approached through my engineering school to work with an online company to develop a short (8 week) online course on visualization, which is now open and running multiple times a year. I agreed and suddenly I had professional learning designers interested in trying to identify a good curriculum, based on my guidance and my existing course materials and other research I sent their way. Sort of a power trip for a faculty member, as there is nothing quite like having a team of people go off and find the appropriate evidence to back up your statements with references you’d forgotten about.
Anyway, I am pretty happy with the result in terms of progression of topics:
The purpose of visualization. Course introduction. Covers essential functions of visualizations as laid out in work on graph comprehension in cognitive psych (affordances like facilitating search, offloading cognition to perception/freeing working memory), as well as an overview of the types of challenges (technical, cognitive, perceptual) that arise. I have them read a paper by Mary Hegarty and the Anscombe paper where he uses plots to show how regression coefficients can be misleading.
Data fundamentals and the visualization process. How visualization can fit into an analytical workflow to inform what questions get posed, what new data get collected, etc., and the more specific “visualization pipeline’, i.e. the process by which you translate some domain specific question into a search for the right visual representation. Also levels of measurement (how do we classify data abstractly in preparation for visualizing data) and basic tasks by data types, i.e. what types of questions can we ask when we visualize data of different dimensions/typess.
Visualization as a language. Introduction to Jacque Bertin’s view, where visual representations are rearrangeable, with different arrangements exposing different types of relationships, not unlike how words can. Characterizing visual or “image space” in terms of marks and encoding functions that map from data to visual variables like position, size, lightness, hue, etc. Semantics of visual variables (e.g., color hue is better for associating groups of data, position naturally expresses continuous data). The grammar of graphics as a notational system for formalizing what constitutes a visualization and the space of possible visualizations. The idea of, and toolkits for, declarative visualization and why this is advantageous over programmatic specifications.
Principles for automated design. The problem of finding the best visualization for a set of n variables where we know the data types and relative importance of them, but must choose a particular set of encodings from the huge space of possibilities. Heuristics/canonical criteria for pruning and ranking alternative visualizations for a given dataset (taken from Jock Mackinlay’s canonical work on automated vis): expressiveness (do the encoding choices express the data and only the data?), effectiveness (how accurately can someone read the data from those encodings?), importance ordering (are the more accurate visual channels like position reserved for the most important data?) Graphical perception experiments to learn about effectiveness of different visual variables for certain tasks (e.g, proportion judgment), pre-attentiveness, how visual variables can interact to make things harder/easier, types of color scales and how to use them.
Multidimensional data analysis and visualization. The challenges of visually analyzing or communicating big multidimensional datasets. Scatterplot matrices, glyphs, parallel coordinate plots, hierarchical data, space-filling/space-efficient techniques, visualizing trees, time series (ok it gets a little grab baggy here).
Exploratory data analysis. Returns to the idea of visualization in a larger analysis workflow to discuss stages of exploratory analysis, iterative nature (including breadth and depth first aspects), relation to confirmatory analysis and potential for “overfitting” in visual analysis. Statistical graphics for examining distribution, statistical graphics for judging model fit. The relationship between visualizations and statistical models (the students do a close read of Becker, Cleveland, and Shyu).
Communication and persuasion. Designing visualizations for communication. Narrative tactics (highlighting, annotation, guided interactivity, etc.) and genres (poster-style, step-through, start guided end with exploration, etc.). Visualization design for communication as an editorial process with rhetorical goals. The influence of how you scale axes and other encodings, how you transform/aggregate data on the message the audience takes away (there are lots of good examples here from climate change axis scaling debates, maps being used to persuade, etc.)
Judgment and decision making. Sources of uncertainty (in data collection, model selection, estimation of parameters, rendering the visualization) and various arguments for why it’s important to be transparent about them. Ways to define and measure uncertainty. Heuristics as tactics for suppressing uncertainty when making decisions from data. Techniques for visualizing uncertainty, including glyph-based approaches (e.g. error bars, box plots), mappings of probability to visual variables (e.g., density plots, gradient plots), and outcome or frequency-based encodings (animated hypothetical outcomes, quantile dotplots, ensemble visualization). Evaluating the effectiveness of an uncertainty visualization.
Naturally there are activities throughout, and some applied stuff with Tableau. I didn’t really have a choice about, but I like Tableau among GUI visualization tools so that was fine for the purposes of this online version (I’ll probably still be teaching D3.js or maybe observable in my CS course). Also there are some interviews with guest experts, including Steve Franconeri on perceptual and cognitive challenges, Dominik Moritz on technical challenges, Danielle Szafir on perception, and Jen Christiansen on conveying a narrative while communicating uncertainty.
I’m especially happy I was able to work in content that isn’t as typical to cover in visualization courses, at least in the computer science/informatics paradigm I’m used to. This includes talking more about the relationships between statistical models and visualization, the need for awareness of where we are in larger (inferential) data analysis process when we use visualization, the way axis scaling influences judgments of effect size. And decision making under uncertainty has become a relatively big portion as well, along with a more explicit than usual discussion of visualization as a language and the grammar of graphics.
There are some major omissions – since this course is aimed more at analysts than the typical computer science student and I had a limited amount of space, the idea of interaction and how it augments visual analysis is implied in specific examples but not directly discussed as a first order concern. I usually talk about color perception more. And then there’s the omission of the laundry list of data types/domains: text, networks, maps, but I certainly won’t miss them.
There are ways it could be further improved I think. When I talk about communication it would be good to bring in more observations from people who are experts on this, like data journalists. I recall Amanda Cox and others occasionally talking about how interactivity can fail, how mobile devices have killed certain techniques, etc. Relatedly, more on responsive visualization for different display sizes could be useful.
Also I would love to also connect the model check idea more specifically to the communication piece. I did this in a paper once, where I basically concluded that if you see a visualization as a model check, then you can communicate better if you design it to specify the model rather than making the audience work hard to figure that out. But I think there’s a lot more to say about the subtle ways graphs convey models and influence what someone concludes by suggesting, for instance, what a plausible or important effect is. This is implicit in some materials but could be discussed more directly.
PS: This course is publicly available (it’s distinct from the course I teach in computer science at Northwestern, enrollment info is here).

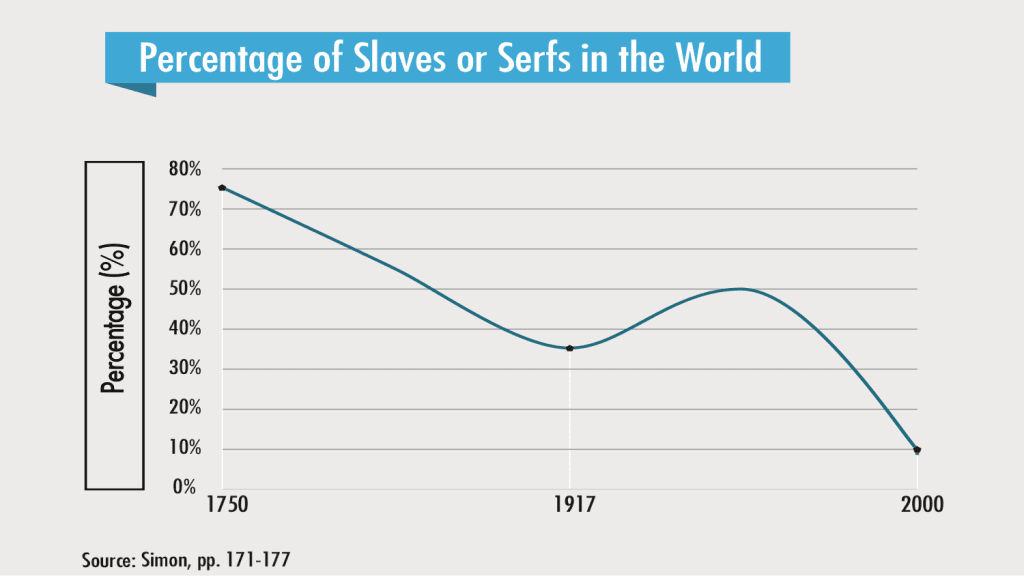
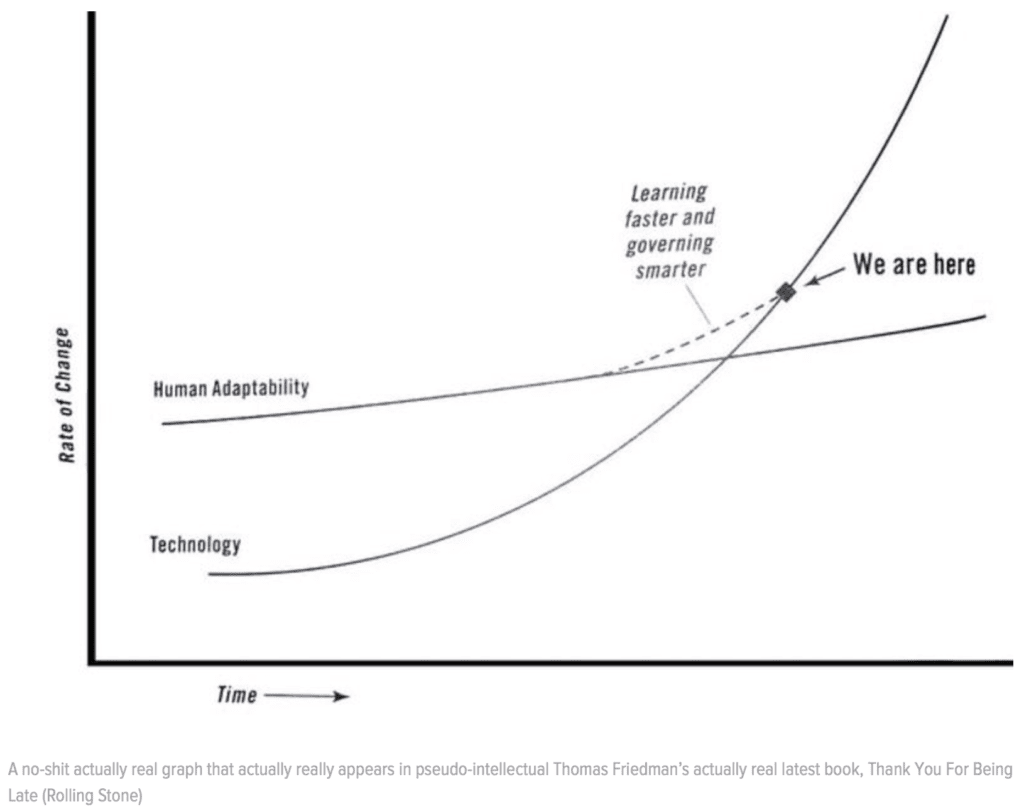
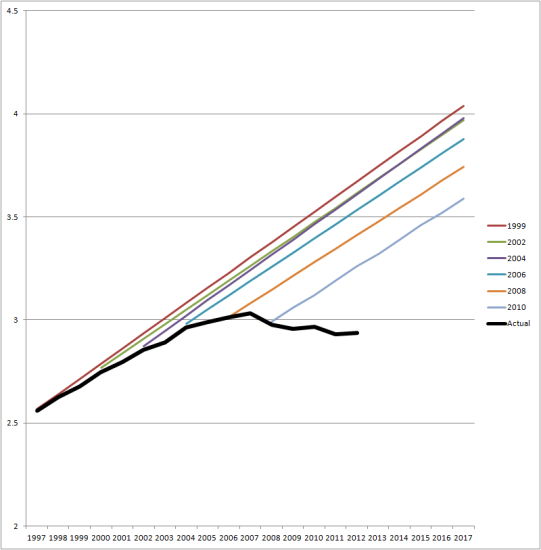
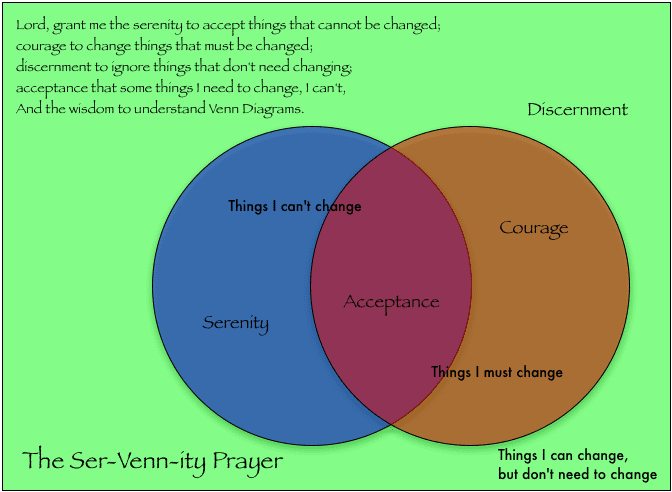





{kind=link}
{kind=link}