This is Bob. And I’d like to know the best way for us to code a bunch of models in JAX to use to evaluate parallel algorithms including normalizing flows. I’m going to dump out my current thinking, but I’m really hoping to get feedback from experts on the best way to do this without starting a flame war in the comments.
Why not Stan? Ask Elizaveta!
The bottom line is that in order to evaluate the parallel algorithms we’re considering, we need fast parallel execution in-kernel on the GPU. Stan has some ability to offload compute to GPU, but not to the extent that we can parallelize entire model evaluations.
Elizaveta Semenova’s words at StanCon are still ringing in my ears—she started her live interview with Alex Andorra by saying, “I don’t use Stan any more.”
Why JAX?
Elizaveta needed to integrate neural networks for the Bayesian optimization she’s doing and for that turned to JAX. (The interview with Elizaveta and Chris Wymant will soon be up on Alex’s podcast, Learn Bayes Stats, along with the interview of Brian Ward and Mitzi Morris in another segment that also took place live at StanCon—the podcast is a ton of fun and both Andrew and I have done interviews).
The real reason for why JAX isn’t that all the cool kids are using it (though everyone I know on the CS side has pretty much switched to JAX, including my own personal bellwether, Matt Hoffman). JAX is beautifully compositional in the same way as Unix. I suppose we could’ve used PyTorch, but JAX just feels much more natural to a computer scientist like me. I just love the way it can compose JIT and autodiff to enable massively parallel differentiable programs. There are really two applications I have in mind, normalizing flows (the main topic of this post) and parallelized MCMC of the form Matt Hoffman’s been propounding lately (Charles Margossian, a former Ph.D. student of Andrew’s and one of our postdocs here, did an internship with Matt at Google working out how to do R-hat in a massively parallel setting with 1000+ chains that communicate with each other to accelerate convergence, after which a single draw is taken from each in the limiting case).
Normalizing flows
I think there is a good chance that normalizing flow-based variational inference will displace MCMC as the go-to method for Bayesian posterior inference as soon as everyone gets access to good GPUs. I’ve been looking into normalizing flows with Gilad Turok, Sifan Liu, Justin Domke, and Abhinav Agrawal. Justin visited Flatiron for five months and during that time, we didn’t manage to program a distribution in JAX that his and Abhinav’s take on realNVP, as coded in the repo vistan, couldn’t fit well. They’re busy writing up a more extensive evaluation in a follow-up paper and the results only look better. Gilad was able to port their vistan code to Blackjax and replicate all their results on our clusters here—he’ll be submitting a PR to Blackjax soon.
My thinking on normalizing flows was inspired by the last model we fit with Justin—a centered parameterization of a hierarchical IRT 2PL model with around 1000 total parameters (this is a nice example due to additive non-identifiability, multiplicative non-identifiability, and funnels from the hierarchical priors). With this parameterization, Stan struggles to the point where I’d say it can’t really fit the model. Justin and Abhinav’s RealNVP fit it quite well—much better than Stan managed. It just took a massive number of flops on a state-of-the-art GPU. One of the things Justin and Abhinav’s approach to flows relies on for convergence is a massive number of evaluations of the log density and gradients for computing the approximate KL-divergence stochastic gradient (i.e., the ELBO). So we needed to code the models in JAX to run entirely on the GPU. So I’m looking for an easier way to do this.
Workflow in JAX
Colin Carroll (Google employee, PyMC dev) just presented a talk about Bayes and JAX at PyData Vermont. He covers the whole workflow in JAX and talks about his bayeaux repository. Colin talks about Adrian Seyboldt’s new nutpie sampler in Rust, which Adrian also just presented at StanCon. There’s no write-up, but we’re looking into reverse engineering the Rust into C++ for Stan—it works quite well. Adrian’s agreed to come out and give a talk here at Flatiron on his sampler in the new year. But that’s a different topic.
For now, I want to do a lot more evaluations of Justin and Abhinav’s take on realNVP, and we’re trying to figure out how to code up a couple dozen models in JAX. There are many possibilities.
PyMC
PyMC can produce JAX output. The PyMC devs just did a little hackathon and created about ten pull requests in the posteriordb repository for PyMC implementations.
with pm.Model() as hierarchical:
eta = pm.Normal("eta", 0, 1, shape=J)
mu = pm.Normal("mu", 0, sigma=10)
tau = pm.HalfNormal("tau", 10)
theta = pm.Deterministic("theta", mu + tau * eta)
obs = pm.Normal("obs", theta, sigma=sigma, observed=y)
All of the approaches in Python wind up having to name variables and then provide string-based names. I don’t know if the sigma=sigma thing is necessary for the scale parameter. I like that the distributions are vectorized here. It’s too bad that there’s an observed= in the data models—I think that means the models as defined aren’t as flexible as the BUGS models in terms of specifying what’s data at run time. At the same time, Thomas Wiecki was telling me you could use NaN to code the equivalent of R’s NA and do inference, so I think that observed value can have missingness.
Not all of the PyMC models look so much like a graphical model.
NumPyro
NumPyro is the version of Pyro that generates JAX on the back end. NumPyro looks like BUGS (or Turing.jl), which is not necessarily a bad thing. Here’s the NumPyro version of Andrew’s favorite example model, eight schools (the arguments to the top-level function are the data):
def eight_schools(J, sigma, y=None):
mu = numpyro.sample('mu', dist.Normal(0, 5))
tau = numpyro.sample('tau', dist.HalfCauchy(5))
with numpyro.plate('J', J):
theta = numpyro.sample('theta', dist.Normal(mu, tau))
numpyro.sample('obs', dist.Normal(theta, sigma), obs=y)
pangolin
pangolin can produce JAX output. This is an “early-stage probabilistic inference project” rather than a longstanding embedded PPL like PyMC or NumPyro. Specifically, it’s a graphical modeling language that looks a lot like the others, and it has back ends for Stan, JAGS, and JAX. It’s very experimental and a work in progress, but the models look nice. Python doesn’t let you overload the ~ operator, which is unary arithmetic complement. Here it’s not so clear that y and stddevs are the data.
mu = pg.normal(0,10) # μ ~ normal(0,10)
tau = pg.exp(pg.normal(5,1)) # τ ~ lognormal(5,1)
theta = [pg.normal(mu,tau) for i in range(num_schools)] # θ[i] ~ normal(μ,τ)
y = [pg.normal(theta[i],stddevs[i]) for i in range(num_schools)] # y[i] ~ normal(θ[i],stddevs[I])
No names here, but they have to get introduced later if you want to do I/O. The doc also makes it clear how things line up. unlike the other approaches, this uses standard Python comprehensions, which I don’t think are super efficient in JAX judging from the JAX doc I’ve read. But I think there are lots of ways to code in pangolin. The problem is when you release “Hello, World!” code, people read it as what your project does rather than as a simple example.
postjax
We can just code models in JAX. Bernardo Williams (Ph.D. student at U. Helsinki) just coded a bunch of models directly in JAX in his GitHub postjax. I couldn’t find eight schools, but here’s a simple logistic regression model as a class with a method defined as follows.
def logp(self, theta):
sqrt_alpha = jnp.sqrt(self.alpha_var)
data = self.data
X = data["X"]
y = data["y"]
assert len(theta) == self.D
return jnp.sum(jss.norm.logpdf(theta, 0.0, sqrt_alpha)) + jnp.sum(
jss.bernoulli.logpmf(y, sigmoid(jnp.dot(X, theta)))
)
The variable self.alpha_var is set as data in the constructor as is the data dictionary data. I’d have been tempted to put alpha_var into the data input.
Other options?
I’d really like to hear about other options for coding statistical models in JAX.
Straight to XLA?
Both JAX and TensorFlow run by compilation down to XLA (stands for “accelerated linear algebra”). Mattijs Vákár, who coded a lot of the Stan parser and code generator, is working on autodiff down at that level. That may be a good eventual target for a compiler, but it’s a lot easier to start in JAX. Similarly, we could have targeted LLVM with Stan rather than C++, but we rely on so much pre-existing C++ infrastructure that would have been challenging. Similarly, I think coding directly at the XLA level would be painful at this stage, not that I’ve ever tried it or even know what it looks like. I just know we’re going to need a lot more than linear algebra.
Stan
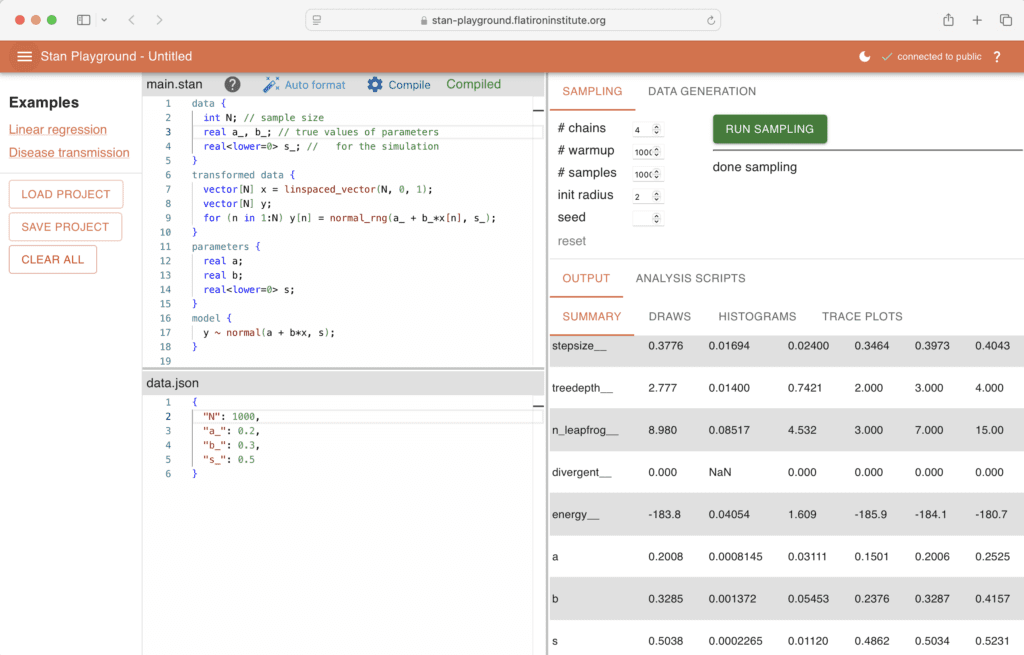
For comparison, I really wish we could just use Stan. Here’s what eight schools looks like in Stan. This includes all the data declarations that were implicit in the other programs (which used either a closure or function argument to capture data directly).
data {
int J;
vector[J] y;
vector[J] sigma;
}
parameters {
real mu;
real tau;
vector[J] theta;
}
model {
tau ~ cauchy(0, 5);
theta ~ normal(mu, tau);
y ~ normal(theta, sigma);
mu ~ normal(0, 5);
}
I’m thinking the way I would code something that follows Stan’s execution logic in JAX directly would be something like this:
class LinearRegression:
def __init__(self, data):
self._data = data
def num_params_unc(self):
return 3
def log_density(self, params_unc):
reader r = Reader(params_Unc)
alpha = r.real()
beta = r.real()
sigma = r.realLB(lower=0)
log_jacobian = r.lp_
log_prior = 0
log_prior += norm.logpdf(alpha, 0, 1)
log_prior += norm.logpdf(beta, 0, 1)
log_prior += exponential.logpdf(sigma, 1)
log_likelihood = 0
log_likelihood_fun = lambda x, y: norm.logpdf(y, alpha + beta * x, sigma)
log_likelihood += sum(vmap(log_likelihood)(zip(self._data['x'], self._data['y'])))
return log_jacobian + log_prior + log_likelihood
where I’m relying on a Reader class that follows the reader I first coded for Stan in order to define the log density over a vector. It’s really a deserializer. I’m wondering if I can just lean more on the pytree construct in JAX to simplify my interfaces, but I’m just getting started with JAX myself.
class Reader:
def __init__(self, params):
self._params = params
self._lj = 0
self._next = 1
def real(self):
x = self._params[self._next_]
self._next += 1
return x
def real_lb(lb):
x_unc = self.read_real()
self._lj += x_unc
return lb + jax.numpy.exp(x_unc)
... other constraining transforms ...
def log_jacobian():
return self._lp