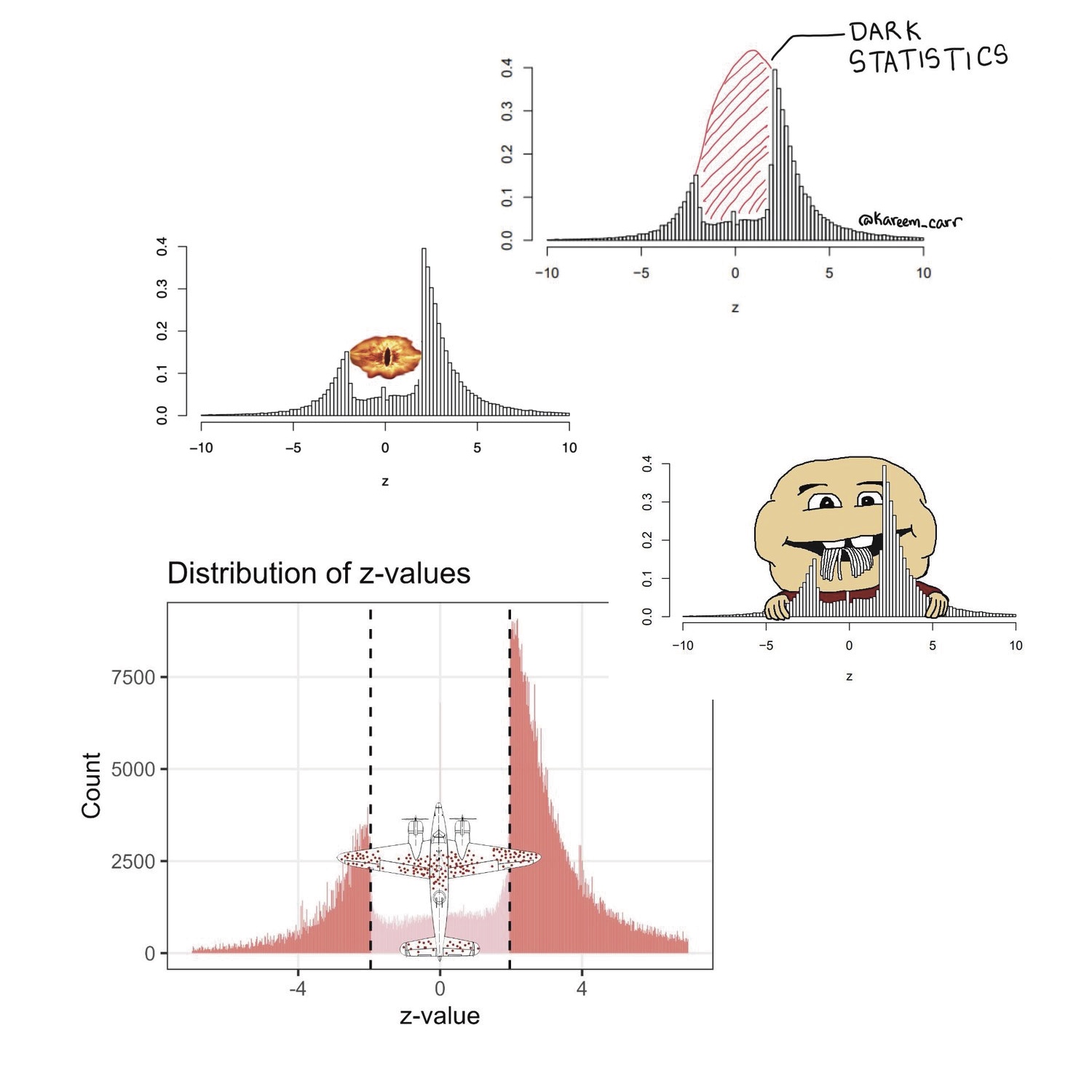
This is Erik. Five years ago, I wrote a short paper about The significance filter, the winner’s curse and the need to shrink (with Eric Cator). The main purpose was to publish some mathematical results for later reference. To make the paper a little more interesting, we wanted to add a motivating example. I came across a paper by Barnett and Wren (2019) who scraped more than a million confidence intervals of ratio estimates from PubMed and made them publicly available. I converted the confidence intervals to z-statistics, made a histogram, and was struck by the lack of z-statistics between -2 and 2 (i.e. non-significant results).
load(url("https://github.com/agbarnett/intervals/raw/master/data/Georgescu.Wren.RData"))
d=complete[complete$mistake==0,]
L=log(d$lower) # take the log because these are ratio estimates
U=log(d$upper)
estimate=(L+U)/2
stderror=(U-L)/(2*1.96)
z=estimate/stderror
hist(z[abs(z)<10],100)

Richard McElreath noticed the figure, snipped it from our paper and posted it on Twitter. Next, it was picked up by several (relatively) large accounts; Harlan Krumholz, Inquisitive Bird, Kareem Carr, John Holbein, Cremieux and Nicolas Fabiano. Just 2 weeks ago John Holbein re-upped his earlier post and got another few thousand likes. The histogram is also quite popular with bloggers, see here, here, here, here, here, here, here, here, here, here, here and here. Adrian Barnett and David Borg wrote a blog post with their own version of the histogram. Several memes were also created.

For the fifth anniversary of the histogram, I wanted to react to a few typical comments. For example, Adriano Aguzzi commented:
Let’s not hyperventilate about this. It’s in the nature of things that negative results are rarely informative and therefore rarely published. And that is perfectly legitimate.
It is disappointing – to say the least – that many people still fail to see the problem of distorting the scientific record by selectively reporting and publishing results that meet p<0.05.
Another typical comment (Simo110901):
I don’t think this is inherently bad, a part of this bias certainly comes from publishing bias, but a significant part (hopefully the majority) could be that researchers are often really good at formulating educated guesses and therefore able to reject null results in most cases.
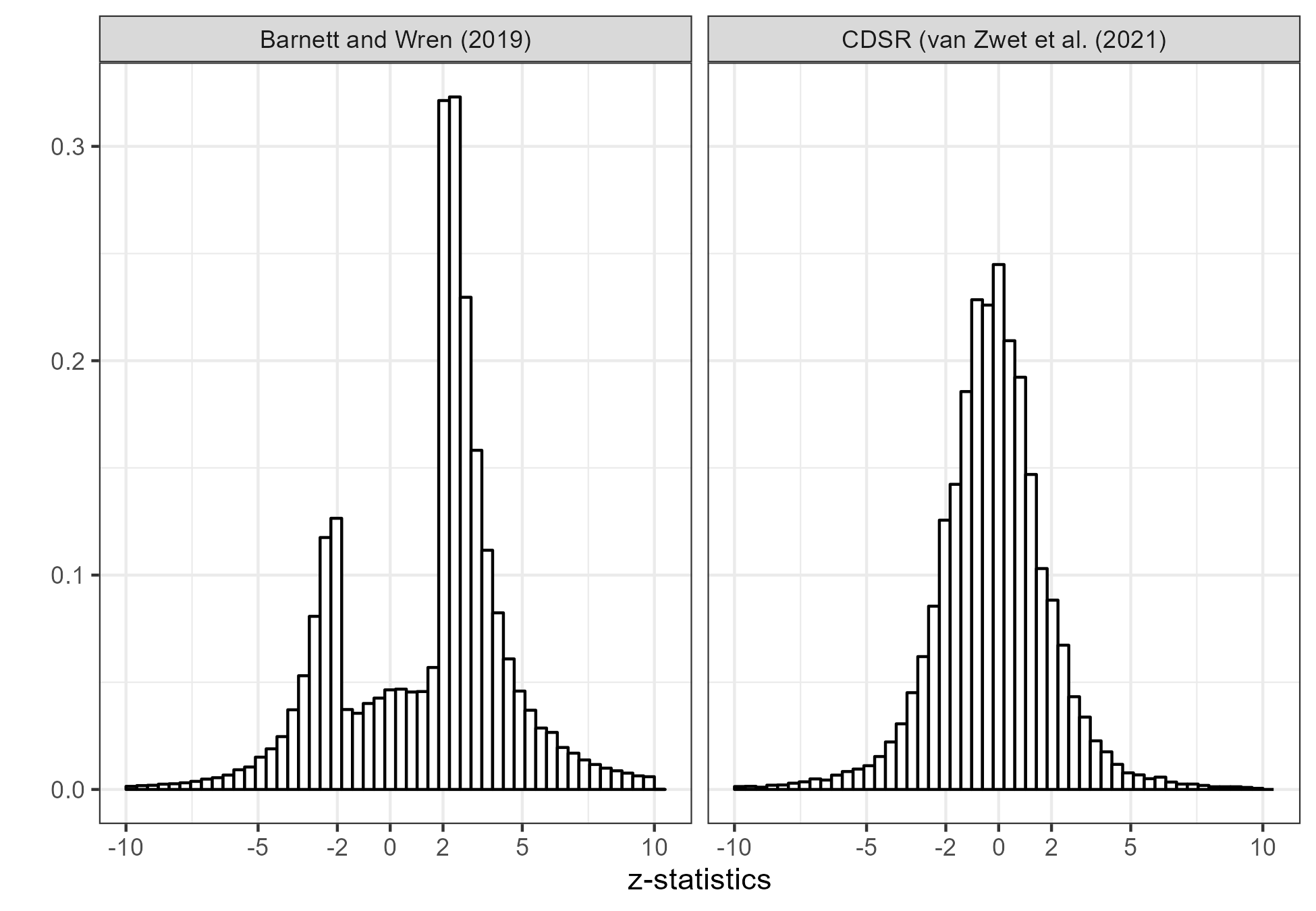
Many other commenters also believe that the lack of non-significant results is due to researchers’ ability to size their studies exactly right to obtain statistical significance with minimal undershoot. This is very unlikely. In the figure below, I compare the z-statistics from Barnett and Wren (2019) to a set of more than 20,000 z-statistics of the primary efficacy endpoints of clinical trials from the Cochrane Database of Systematic Reviews (CDSR).
d=read.csv("https://osf.io/xq4b2/?action=download")
d=d %>% filter(RCT=="yes",outcome.group=="efficacy", outcome.nr==1, abs(z)<20 )
d=group_by(d,study.id.sha1) %>% sample_n(size=1) # one outcome per study
hist(d$z[abs(d$z)<10],50)

The histogram from the CDSR (right) shows no appreciable gap. I can’t know for sure why that is, but would guess it’s due to the fact that clinical trials are serious research. They are usually pre-registered in the sense that they have a protocol which was approved by some Institutional Review Board. They are expensive and time-consuming, so even if they are not significant it would be a shame not to get a publication out of them. Finally, it would be unethical to the participants not to publish.
Another typical comment (Daniel Lakens):
This is not an accurate picture of how biased the literature is. The authors only analyze p-values in abstracts.
Barnett and Wren (2019) collected z-statistics from both abstracts and full text sources. The full text data are available for papers that are on PubMed Central. There are 961,862 abstracts and 348,809 full-text sources. Below, I show the z-statistics separately. The distributions are remarkably similar, although there is a slightly higher proportion non-significant results from the full texts

Any automated scraping algorithm is bound to miss some things. It’s quite possible that non-significant results that are not in the abstract or main text are still reported in separate tables, appendices and supplements. However, it doubt that that’s the reason for the huge gap. I’m quite convinced that the z-statistics from PubMed really do provide strong evidence of publication bias against non-significant results in the medical literature. However, it should be noted that the underrepresentation of z-statistics between -2 and 2 is probably not only due to publication bias, but also due to authors not reporting confidence intervals for non-significant results. Of course, that is still not a good thing.