Washington Post columnist Richard Cohen brings up one of my research topics:
In New York City, blacks make up a quarter of the population, yet they represent 78 percent of all shooting suspects — almost all of them young men. We know them from the nightly news.
Those statistics represent the justification for New York City’s controversial stop-and-frisk program, which amounts to racial profiling writ large. After all, if young black males are your shooters, then it ought to be young black males whom the police stop and frisk.
I have two comments on this. First, my research with Jeff Fagan and Alex Kiss (based on data from the late 1990s, so maybe things have changed) found that the NYPD was stopping blacks and hispanics at a rate higher than their previous arrest rates:
To briefly summarize our findings, blacks and Hispanics represented 51% and 33% of the stops while representing only 26% and 24% of the New York City population. Compared with the number of arrests of each group in the previous year (used as a proxy for the rate of criminal behavior), blacks were stopped 23% more often than whites and Hispanics were stopped 39% more often than whites. Controlling for precinct actually increased these discrepancies, with minorities between 1.5 and 2.5 times as often as whites (compared with the groups’ previous arrest rates in the precincts where they were stopped) for the most common categories of stops (violent crimes and drug crimes), with smaller differences for property and drug crimes.
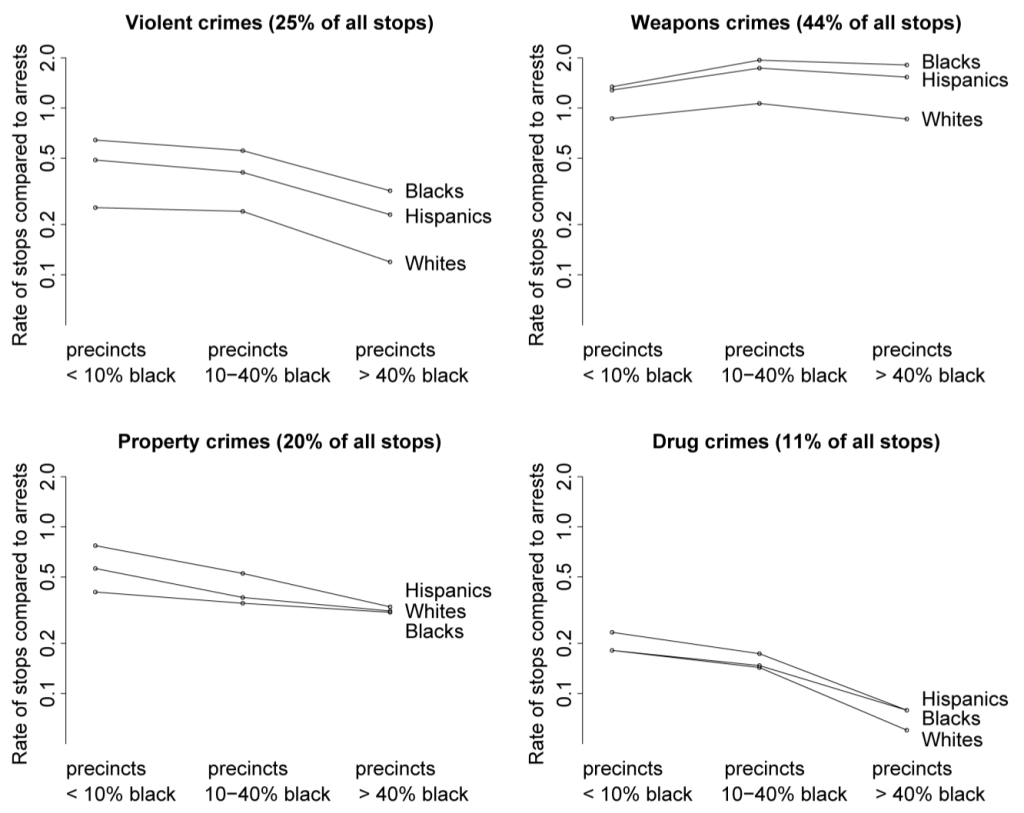
I can’t fault Cohen here, he’s just a newspaper columnist, you can’t expect him to be aware of a six-year-old article in the Journal of the American Statistical Association. And things may have changed since 1998-1999 (which is when our data are from). But the data we have here shows the police were disproportionately stopping minorities.
The other thing is, I don’t think Cohen is necessarily being fair to the police when he describes the stop-and-frisk program as “racial profiling.” As we wrote in our paper, “It is quite reasonable to suppose that effective policing requires stopping and questioning many people to gather information about any given crime.” It could well be that a statistical pattern of stops could arise from individual decisions that are not based on race but instead are based on characteristics that are correlated with race. I have no idea what the police are doing—my only experience here is with the numbers.
I that Cohen is, on one hand, way too quick to dismiss the numbers with his blanket statement that “young black males are your shooters” and on the other hand may be way too quick to describe police work as racial profiling.
P.S. As a bonus, Slate columnist Matthew Yglesias connects this to one of my other research interests: Bayesian inference. I won’t comment on Yglesias’s remarks except to point out that Bayes’ theorem is a two-way street. The problem here is not so much Bayesian inference as its application to decision analysis. If you have to make individual decisions by maximizing the probability of success (catching a criminal, if you are the police), then profiling can be a logical strategy. Reasons not to profile include, “equal protection of the laws” etc. and also indirect effects of what one might call the “profiling culture,” effects such as hassling innocent people, reducing trust in the police, empowerment of Bernard Goetz and George Zimmerman to go around shooting people, etc. Bayes’ theorem is relevant in all these calculations but the issues here are not trivial.
Andrew, excellent points here. It makes sense to me that police stops could involve many variables so I don’t understand how one can look at a single variable (such as race) with much clarity.
There’s another thing about these data, though, that troubles me in how it’s being interpreted. The “stop and frisk” report called a UF250 is essentially a check-off form (you can see a reproduction of this form and some interesting analysis here: https://www.nyc.gov/html/nypd/downloads/pdf/public_information/TR534_FINALCompiled.pdf). It’s a catch-all form that covers a wide range of public interactions. This can range from an observed person acting suspiciously to a person being searched for contraband.
On the form a police officer can indicate whether or not the person was searched or frisked. There are cases where the person was never searched/frisked and, in fact, the majority do not. The form may be filled out following any type of stop or interaction with the public (e.g., a traffic stop, person asking for information). Furthermore, there could be times the form is used in instances in which the police officer doesn’t have any verbal contact with the person in question. What I mean to say is, that neither a stop nor a frisk occurred. I don’t see many reports differentiating between these situations and I think it’s an important distinction to make.
Legally, there is a huge difference between stopping to talk to someone and frisking them. There are basically three levels of interaction between a person and the police: an encounter, a detention, and an arrest. (1) A chat is a mere encounter and the person is free to leave and the police may not search without consent. (2) A detention may involve a frisk if the police believe they are endangered, and the person is not free to go, but it requires that the police have a reasonable suspicion that a crime has been (or is being) committed. Reasonable suspicion means the police have a particularized and objective basis for suspecting criminal activity is afoot or that the person encountered was involved (or is wanted) in connection with a completed felony. (3) An arrest normally involves a frisk and the police must have probable cause that a crime has been (or is being) committed. Probable cause means the police can cite enough particularized facts to lead a common sense person of reasonable caution to believe that there is a fair probability of criminal activity.
We have a Constitution for a reason and that reason is to check the government’s authority and power. A a one-size-fits-all form that encompasses all of these interactions is very problematic.
Do you have a personal position on the question of intent versus disproportionate impact? The issue is interesting if only because of the blunt question of acknowledged or explicit intent versus that attributable through data analysis.
Just as a public policy matter, I was reading an article in (I believe) the NY Times regarding policing in LA versus NY. LA has chosen a different path than NY (neighborhood policing, essentially, rather than stop and frisk), and has recorded a similar drop in crime (and with a third fewer cops). This gets back to the “broken window” theories, which “worked” in NY but in other cities (Philadelphia/Boston) a similar drop in crime was recorded without application of this theory. It would be nice to have a lead article in APSR or ASR going through the statistics (I’m just quoting from memory and I may be wrong), but the interesting question is, if I’m right, why certain localities in America return to what are clearly racially discriminatory policies when non-discriminatory policies work just as well?
Ironically, profiling of some sort is almost the core of traditional policing work. How else does a beat cop know which troublemaker to watch for or the detective know which of his suspects to follow up more on.
I think it eventually boils down to how we, as a society, rate the relative downside of “hassling innocent people” versus “preventing crime”.
It seems like the other factor here is that some people bear a lot more of the weight of the hassling innocent people than others. Blacks are way more likely than whites to be criminals (assuming the crime statistics are more-or-less accurate), and so you’d expect police to do better following, harassing, searching, etc. random blacks rather than random whites. But this must really, really suck if you’re a 19 year old black kid just trying to walk to work or something.
We can address the hassling the innocent/disproportionate hassling of innocent people from more criminal groups issue in policy when it’s the police doing the hassling. It’s way harder to address it when done by private citizens, as with Zimmerman. (Different laws regarding guns could have led to a different outcome, but you’re not going to pass a law that makes neighborhood watch volunteers *not* suspect black teenage males of being criminals more than they do, say, middle-aged white women.)
One metric that might be interesting is the “percent of productive stops”. i.e. Of all blacks stopped what percent led to arrests. Versus that same metric for whites.
Is this metric somehow derivable from Andrew’s data?
One goal could be to keep that “success rate” uniform across groups. i.e. If one out of every three stops results in an arrest for whites so should it for blacks. If the stop-to-arrest conversion rate for blacks is less, it means we are hassling more blacks proportionally.
Rahul:
Yes, we do have such information. We discuss this in our paper.
Thanks! The other criticism could be the causality direction. Number of arrests in a previous year will be correlated to how many stops you did on that ethnic group in previous year.
One of the problems with basing racial profiling on crime statistics is that the crime statistics over time will begin to change based upon the profiling.
If police are profiling/targeting particular groups, then individuals in those groups are MORE LIKELY to get caught, which increases the proportion of crimes committed by the profiled group. Meanwhile, the groups that aren’t getting profiled/targeted are LESS LIKELY to get caught, which decreases the proportion of crimes committed by the non-profiled group.
Yglesias doesn’t know a Gibbs sampler from a…well whatever. Point is he throws out the word Bayesian in a statistical context and hopes his humanities major readers will be impressed. Not clear to me what his point is.
Yglesias’s point is that Cohen is arguing as if Pr(criminal | young black man) is equal to Pr(young black man | criminal). The former is low even in circumstances where the latter is high because there are far more young black men then criminals (i.e., Pr(criminal)/Pr(young black man) is small).
Yglesias gives the analogy “young black man : criminal :: Jewish man : op-ed columnist” to help clarify the issue: inferring that any Jewish man one encounters is an op-ed columnists is a ridiculous error. Inferring that any young black man one encounters is a criminal is the exact same error. (But replacing “inferring” with “acting as if” in the previous sentence is less ridiculous because the consequences differ in the two scenarios.)
In short, Bayes’ theorem is precisely on point; Yglesias is not just pulling that out of his ass.
What really matters is the ratio: Pr(criminal | young black man) : Pr(criminal | young non-black man)
If that is high enough it’s still a pragmatic (but unethical) case for profiling.
The problem is finding unbiased data to determine those probabilities. Arrest data is highly problematic. If the police patrol predominantly black neighborhoods more intensely than they do non-black neighborhoods and the rates of crime are identical, the rates of arrest will be skewed and will lead one to believe blacks are more prone to crime. The cycle continues.
One interesting thing to me: this confusion between P(A | B) and P(B | A) is very common. And the analog in logic is at least as common (confusion between p->q and q->p) . I suspect there is some common failure in the way humans think that is at root in both problems.
Andrew:
Here’s Mayor Bloomberg on why he thinks they stop whites too often in NYC: “They just keep saying, ‘Oh, it’s a disproportionate percentage of a particular ethnic group,’ ” he said dismissively of the practice’s critics. “That may be, but it’s not a disproportionate percentage of those who witnesses and victims describe as committing the murder. In that case, incidentally, I think we disproportionately stop whites too much and minorities too little.”
He added: “It’s exactly the reverse of what they say. I don’t know where they went to school, but they didn’t take a math course. Or a logic course.”
https://www.nytimes.com/2013/06/29/nyregion/bloomberg-says-math-backs-police-stops-of-minorities.html
“I can’t fault Cohen here, he’s just a newspaper columnist, you can’t expect him to be aware of a six-year-old article in the Journal of the American Statistical Association. And things may have changed since 1998-1999 (which is when our data are from). But the data we have here shows the police were disproportionately stopping minorities.”
My sarcasm detector is having trouble – but I would absolutely expect a newspaper journalist (at a supposedly top-notch publication with a huge audience) to be aware, if not of this particular paper, similar trends. As a somewhat liberal I unfortunately (and incorrectly, to be fair) take this as a stylized fact. But I would at least expect him (and anyone else) to go through the implications and caveats of his statement once he’s written something that’s so vulnerable to statistical flaw.
Ashok:
I was not being sarcastic. Cohen’s shtick is his being able to offer his regular-guy opinions on issues of the day, also I guess he gets credit for writing columns that are read and talked about. I’d think it’s a rare newspaper columnist who would read a journal article. Paul Krugman would do it, as would David Brooks, but not so many others, right?
Yeah but writing columns “regular guys” read is not the same thing as writing it like a “regular guy” would. I don’t expect him to have read this paper before hand, but once he’s written down these words “after all, if young black males are your shooters, then it ought to be young black males whom the police stop and frisk.” I would expect him to at least run a Google search on terms like “black male profiling effect” ,”black male disproportionate arrest” until he is at least thoroughly acquainted with a set of abstracts on the issue.
It’s not really a big secret that even if blacks are more likely to be criminal than whites (and I’m not sure about the statistics within crime-ridden neighborhoods) stop-and-frisk as well as other policies (like detainment) are disproportionately targeted against blacks. This is just one of those ridiculous statistical flaws we read in MSM that sounds good to someone who reads it at face value.
Paul Krugman and David Brooks would do it. Which is why they are better than Richard Cohen.
If op-eds were fact checked the way you want them to be, this would have a hard time getting published: lest the whole article be predicated on an “if” that is obviously false.
Andrew,
I looked at your stop-and-frisk report and admired it greatly. I do think, however, that the difference in “productive arrest” rates is quite small. I did a “Number Needed to Treat” calculation and, as I recall, I think that only in about one our of every 40(+) stops is the racial difference evident.
I did a similar analysis on highway traffic stops in Arizona, where minorities are more often stopped than non-Hispanic whites. The number of stops needed to observe a difference was about 20 (by my memory).
I quite agree with your idea that the data do not provide information about the reason for the difference, e.g., race. The difference is small and could be accounted for by a wide range of subtle cues that police (and highway patrolmen) rely on that are correlated with race. Several years ago one of my students, newly arrived from Germany, was stopped at night on a highway. He had unwittingly bought a used car that had special high springs favored by smugglers!
A good many years ago I did some work with police, including rides in patrol cars, and I was impressed by the way police on patrol see things, what they pick up on, and so forth.
Rich cities like New York have a variety of tactics at their disposal, such as tearing down housing projects and giving residents Section 8 vouchers that will go farther in the sticks, to push out poor African Americans and Puerto Ricans. New York seems to be the most shameless in adding industrial scale police harassment of unwelcome minorities to the mix. I can’t imagine that a Red State city could get away for long with Mayor Bloomberg’s stop-and-frisk program.
Steve:
The data we analyze come from before Bloomberg was mayor.
Sorry. I forgot that I also wanted to suggest that the small magnitude of bias effects usually found poses real difficulties both for researchers and for policy makers. (I spent some time a few years ago looking at data on discrimination in medical settings also.)
It is almost never the case that the nature and source of statistical bias is identified in a way that is likely to be useful for policy. For example, it makes a lot of difference whether the whole NYPD is a little bit biased or whether a small fraction of the department is very biased. The latter can pretty easily dealt with if the perps can be identified. The former is very difficult to cope with.
If we are to do something about the problem of bias, we have to do better than simply determine that there is one. If it were easy to do that, someone would have done so by now.
That granularity ought to be easy with a precinct or officer level dicing of the stop-n-frisk data. Doesn’t NYPD have that gleaming BigData package, CompStat or whatever they call it.
Andrew,
Have you ever read the Stop and Frisk report by Greg Ridgeway at RAND? He cites your paper, although instead of previous arrest rates he compares stops to crime-suspect descriptions. If you’ve read it, do you have any opinion on the methodology?
Pingback: Defensive political science responds defensively to an attack on social science | Symposium Magazine
Pingback: Defensive Political Science Responds Defensively to an Attack on Social Science
So this may be a strange place to ask this question, but I am seeking some help on a modeling problem. I am a programmer by trade, not a statistician, but I’m quite interested in modeling the general “profiling” logic and it’s actual effects.
To that end I’ve built and am enhancing a police check model. Essentially, I can create populations comprised of people with a demographic (this can be arbitrarily defined) and the person either is or is not a criminal. From there I can setup sample biases for each demographic. These samples could represent Stop and Frisk, or Airport security checks, etc. There are two check factors for false positive and false negative. Currently I can basically see how the reported crime statistics are affected by the sample bias as well as the actual number of criminals distributed across a population by demographic.
I’m currently working on making an iterative sample bias, where the discovered crimes of the previous run, become the new sample bias’s.
However, I am trying to make this model a bit more general purpose, and many of my assumptions are quite simplistic. I am actively seeking some feedback on additional variables and considerations to build in my model. Each model run, is based on the idea of a year. Some additional considerations are:
1) Sampling multiple times in a year – if 100 checks are done, do them in batches of 10, this would allow for people to be checked twice in a year.
2) Removing “caught” individuals from said population for that year, under the idea they would be in jail, and no longer in the pool of potential checkees.
3) While false positives are built in, I really question wether they are relevant, so have been running my early runs with that set to 0
Thoughts, comments or even suggestions on a better place to post this are very welcome.
Pingback: Graphic Debate | Stop-and-Frisk – On AndrewGelman.com