Last year my co-bloggers and I posted 565 entries on this blog. Here’s a list of all them, in decreasing order of number of comments. You can draw your own conclusions from all this.
- A tale of two epidemiologists: It was the worst of times. (237 comments)
- Economics as a community (225 comments)
- What is a “woman”? (197 comments)
- What is the landscape of uncertainty outside the clinical trial’s methods? (194 comments)
- What about that new paper estimating the effects of lockdowns etc? (179 comments)
- The social sciences are useless. So why do we study them? Here’s a good reason: (156 comments)
- Three coronavirus quickies (145 comments)
- Thinking fast, slow, and not at all: System 3 jumps the shark (145 comments)
- Wanna bet? A COVID-19 example. (145 comments)
- New research suggests: “Targeting interventions – including transmission-blocking vaccines – to adults aged 20-49 is an important consideration in halting resurgent epidemics and preventing COVID-19-attributable deaths.” (140 comments)
- How did the international public health establishment fail us on covid? By “explicitly privileging the bricks of RCT evidence over the odd-shaped dry stones of mechanistic evidence” (130 comments)
- “I looked for questions on the polio vaccine and saw one in 1954 that asked if you wanted to get it—60% said yes and 31% no.” (129 comments)
- Justin Grimmer vs. the Hoover Institution commenters (119 comments)
- Relative vs. absolute risk reduction . . . 500 doctors want to know! (116 comments)
- How to think about evil thoughts expressed by entertainers on news shows? (109 comments)
- Responding to Richard Morey on p-values and inference (102 comments)
- “A Headline That Will Make Global-Warming Activists Apoplectic” . . . how’s that one going, Freakonomics team? (100 comments)
- Accounting for uncertainty during a pandemic (99 comments)
- Smoking and Covid (99 comments)
- Here’s why I don’t trust the Nudgelords . . . (97 comments)
- About that claim that “SARS-CoV-2 is not a natural zoonosis but instead is laboratory derived” (96 comments)
- “Where in your education were you taught about intellectual honesty?” (96 comments)
- COVID and Vitamin D…and some other things too. (93 comments)
- Rasslin’ over writin’ teachin’ (92 comments)
- The COVID wager: results are in (90 comments)
- Why are goods stacking up at U.S. ports? (87 comments)
- “Christopher Columbus And The Replacement-Level Historical Figure” (87 comments)
- Alan Sokal on exponential growth and coronavirus rebound (86 comments)
- Scott Atlas, Team Stanford, and their friends (83 comments)
- Lakatos was a Stalinist (83 comments)
- Learning by confronting the contradictions in our statements/actions/beliefs (and how come the notorious Stanford covid contrarians can’t do it?) (82 comments)
- “Death and Lockdowns” (81 comments)
- Public opinion on vaccine mandates etc. (81 comments)
- I like Steven Pinker’s new book. Here’s why: (81 comments)
- If a value is “less than 10%”, you can bet it’s not 0.1%. Usually. (79 comments)
- Lying to people by associating health care with conspiracy theories—it’s a tradition. Here’s a horrible example from an old-school science fiction writer: (79 comments)
- You’re a data scientist at a local hospital and you’ve been asked to present to the physicians on communicating statistical information to patients. What should you say? (78 comments)
- Thoughts on “The American Statistical Association President’s Task Force Statement on Statistical Significance and Replicability” (78 comments)
- Our ridiculous health care system, part 734 (77 comments)
- The 5-sigma rule in physics (77 comments)
- Coronavirus and Simpson’s paradox: Oldsters are more likely to be vaccinated and more likely to have severe infections, so you need to adjust for age when comparing vaccinated and unvaccinated people (77 comments)
- Journals submit article with fake data, demonstrate that some higher education journal you’d never heard of is as bad as PNAS, Psychological Science, Lancet, etc etc etc. And an ice cream analogy: (76 comments)
- Is “choosing your favorite” an optimization problem? (76 comments)
- Another example to trick Bayesian inference (75 comments)
- Postmodernism for zillionaires (73 comments)
- “ai-promised-to-revolutionize-radiology-but-so-far-its-failing” (71 comments)
- What happened with HMOs? (71 comments)
- Is it really true that “the U.S. death rate in 2020 was the highest above normal since the early 1900s—even surpassing the calamity of the 1918 flu pandemic”? (70 comments)
- The Pandemic: how bad is it really? (70 comments)
- “Using Benford’s Law to Detect Bitcoin Manipulation” (70 comments)
- Why did Bill Gates say this one weird thing about Bad Blood, the story of Theranos?? (70 comments)
- Bayesian inference completely solves the multiple comparisons problem (68 comments)
- Is an improper uniform prior informative? It isn’t by any accepted measure of information I know of (68 comments)
- What’s the difference between xkcd and Freakonomics? (68 comments)
- Yes, there is such a thing as Eurocentric science (Gremlins edition) (65 comments)
- A scandal in Tedhemia: Noted study in psychology first fails to replicate (but is still promoted by NPR), then crumbles with striking evidence of data fraud (64 comments)
- Lumley on the Alzheimer’s drug approval (63 comments)
- A study comparing young and middle-aged adults who got covid to similarly-aged people who were vaccinated (63 comments)
- When confidence intervals include unreasonable values . . . When confidence intervals include only unreasonable values . . . (63 comments)
- Struggling to estimate the effects of policies on coronavirus outcomes (62 comments)
- “Have we been thinking about the pandemic wrong? The effect of population structure on transmission” (62 comments)
- Kill the math in the intro stat course? (61 comments)
- There often seems to be an assumption that being in the elite and being an outsider are mutually exclusive qualities, but they’re not. (60 comments)
- Which sorts of posts get more blog comments? (59 comments)
- Pathfinder: A parallel quasi-Newton algorithm for reaching regions of high probability mass (59 comments)
- “There are no equal opportunity infectors: Epidemiological modelers must rethink our approach to inequality in infection risk” (58 comments)
- “Not statistically significant” is not the same as zero (58 comments)
- Wow, just wow. If you think Psychological Science was bad in the 2010-2015 era, you can’t imagine how bad it was back in 1999 (57 comments)
- “The 60-Year-Old Scientific Screwup That Helped Covid Kill” (57 comments)
- ‘No regulatory body uses Bayesian statistics to make decisions’ (56 comments)
- Scabies! (56 comments)
- Who are the culture heroes of today? (55 comments)
- Many years ago, when he was a baby economist . . . (55 comments)
- This system too often rewards cronyism rather than hard work or creativity — and perpetuates the gross inequalities in representation … (55 comments)
- The University of California statistics department paid at least $329,619.84 to an adjunct professor who did no research, was a terrible teacher, and engaged in sexual harassment (55 comments)
- A regression puzzle . . . and its solution (55 comments)
- Routine hospital-based SARS-CoV-2 testing outperforms state-based data in predicting clinical burden. (54 comments)
- How to incorporate new data into our understanding? Sturgis rally example. (54 comments)
- “When Should Clinicians Act on Non–Statistically Significant Results From Clinical Trials?” (54 comments)
- Whassup with the haphazard coronavirus statistics? (53 comments)
- It’s not an echo chamber, but it’s an echo chamber . . . How does that work, exactly? (53 comments)
- “Causal Impact of Masks, Policies, Behavior on Early Covid-19 Pandemic in the U.S”: Chernozhukov et al. respond to Lemoine’s critique (52 comments)
- Does the “Table 1 fallacy” apply if it is Table S1 instead? (50 comments)
- Pundits continue to push the white-men-are-dying story, even though the real change is occurring among women. (50 comments)
- The NFL regression puzzle . . . and my discussion of possible solutions: (50 comments)
- “Infections in vaccinated Americans are rare, compared with those in unvaccinated people . . . But when they occur, vaccinated people may spread the virus just as easily.” (49 comments)
- Teaching and the separation of form and content (49 comments)
- Fake drug studies (49 comments)
- “Why and How We Should Join the Shift From Significance Testing to Estimation” (49 comments)
- What’s the best novel ever written by an 85-year-old? (48 comments)
- Estimating the college wealth premium: Not so easy (48 comments)
- When does mathematical tractability predict human behavior? (47 comments)
- “What, are you nuts? We don’t have time in AP Stats to explain to students what stats actually means. We have to just get them to grind through the computations.” (47 comments)
- Reflections on Lakatos’s “Proofs and Refutations” (46 comments)
- A counterexample to the potential-outcomes model for causal inference (46 comments)
- CDC as bad as Harvard? . . . no, but they could still do better (46 comments)
- “Unrepresentative big surveys significantly overestimated US vaccine uptake,” and the problem of generalizing from sample to population (46 comments)
- She sent a letter pointing out problems with a published article, the reviewers agreed that her comments were valid, but the journal didn’t publish her letter because “the policy among editors is not to accept comments.” (45 comments)
- A survey of oldsters. Can someone explain why they do it this way? (45 comments)
- Science reform can get so personal (44 comments)
- EU proposing to regulate the use of Bayesian estimation (44 comments)
- “Ivermectin Research Has a Big Fraud Problem, Scientists Say Numerous studies suggesting ivermectin can treat or prevent covid-19 have dodgy data behind them, according to an international group of researchers.” (44 comments)
- What’s your “Mathematical Comfort Food”? (43 comments)
- Just another day at the sausage factory . . . It’s just funny how regression discontinuity analyses routinely produce these ridiculous graphs and the authors and journals don’t even seem to notice. (43 comments)
- What is the relevance of “bad science” to our understanding of “good science”? (42 comments)
- Statistical fallacies as they arise in political science (from Bob Jervis) (42 comments)
- “The presumption of wisdom and/or virtue causes intellectuals to personalize situations where contending ideas are involved.” (42 comments)
- The odd overlap of political left and right that’s associated with much of “neoliberal” social science (42 comments)
- Whassup with the FDA approval of that Alzheimer’s drug? A “disgraceful decision” or a good idea? (41 comments)
- I can’t quite say I’m shocked that people aren’t more shocked about Harvard and the CDC’s latest misdeeds . . . but I’m disappointed that people aren’t more disappointed. (41 comments)
- Nudgelords: Given their past track record, why should I trust them this time? (Don’t call me Stasi) (40 comments)
- Chernobyl disaster and Matthew Walker’s “Why We Sleep” (40 comments)
- 2020: What happened? (40 comments)
- Chevron, Donziger, and rationality (40 comments)
- What is/are bad data? (39 comments)
- Huge partisan differences in who wants to get vaccinated (39 comments)
- More on the role of hypotheses in science (39 comments)
- More on the epidemiologists who other epidemiologists don’t trust (39 comments)
- Can the “Dunning-Kruger effect” be explained as a misunderstanding of regression to the mean? (39 comments)
- What can we learn from COVID burnout? (39 comments)
- xkcd: “Curve-fitting methods and the messages they send” (38 comments)
- Substack. (38 comments)
- 2 reasons why the CDC and WHO were getting things wrong: (1) It takes so much more evidence to correct a mistaken claim than to establish it in the first place; (2) The implicit goal of much of the public health apparatus is to serve the health care delivery system. (38 comments)
- Some open questions in chess (38 comments)
- Ethics washing, ethics bashing (37 comments)
- Why did it take so many decades for the behavioral sciences to develop a sense of crisis around methodology and replication? (37 comments)
- The problem with p-hacking is not the “hacking,” it’s the “p” (or, Fisher is just fine on this one) (37 comments)
- Tukeyian uphill battles (36 comments)
- Regression discontinuity analysis is often a disaster. So what should you do instead? Here’s my recommendation: (36 comments)
- “Off white: A preliminary taxonomy” (36 comments)
- Whassup with the weird state borders on this vaccine hesitancy map? (36 comments)
- “Why I blog about apparent problems in science” (36 comments)
- “While critique is certainly an important part of improving scientific fields, we do not want to set a precedent or encourage submission of articles that only critique the methods used by others.” (36 comments)
- My thoughts on “What’s Wrong with Social Science and How to Fix It: Reflections After Reading 2578 Papers” (35 comments)
- Probability problem involving multiple coronavirus tests in the same household (35 comments)
- Mortality data 2015-2020 around the world (34 comments)
- The lawsuit that never happened (Niall Ferguson vs. Pankaj Mishra) (34 comments)
- How much faster is the Tokyo track? (34 comments)
- A fill-in-the-blanks contest: Attributing the persistence of the $7.25 minimum wage to “the median voter theorem” is as silly as _______________________ (33 comments)
- Your tax dollars at work (junk social science edition) (33 comments)
- Review of Art Studio, Volume 1, by James Watt (33 comments)
- Creatures of their time: Shirley Jackson and John Campbell (32 comments)
- Bayesian methods and what they offer compared to classical econometrics (32 comments)
- If you put an o on understo, you’ll ruin my thunderstorm. (32 comments)
- “Small Steps to Accuracy: Incremental Updaters are Better Forecasters” (31 comments)
- Simulated-data experimentation: Why does it work so well? (31 comments)
- What’s the biggest mistake revealed by this table? A puzzle: (31 comments)
- Thoughts inspired by “the Gospel of Jesus’s Wife” (31 comments)
- Jordan Ellenberg’s new book, “Shape” (31 comments)
- More institutional failure by universities that refuse to grapple with potential research misconduct by their faculty (31 comments)
- Measuring the information in an empirical prior (31 comments)
- He was fooled by randomness—until he replicated his study and put it in a multilevel framework. Then he saw what was (not) going on. (31 comments)
- NYT editor described columnists as “people who are paid to have very, very strong convictions, and to believe that they’re right.” (30 comments)
- A new approach to pandemic control by informing people of their social distance from exposure (30 comments)
- Adjusting for differences between treatment and control groups: “statistical significance” and “multiple testing” have nothing to do with it (30 comments)
- Not so easy to estimate the effects of school mask requirements . . . how to think about this? (30 comments)
- “America Has a Ruling Class” (29 comments)
- That $9 trillion bill on the sidewalk: Why don’t third-world countries borrow to get vaccines? (29 comments)
- Harvard behaving badly (it’s all about Jesus) (29 comments)
- New blog formatting (29 comments)
- Rapid prepublication peer review (28 comments)
- Stanford prison experiment (28 comments)
- Cancer patients be criming? Some discussion and meta-discussion of statistical modeling, causal inference, and social science: (28 comments)
- “Losing one night’s sleep may increase risk factor for Alzheimer’s, study says” (28 comments)
- Gladwell! (28 comments)
- The Current State of Undergraduate Bayesian Education and Recommendations for the Future (28 comments)
- A new idea for a science core course based entirely on computer simulation (28 comments)
- The connection between junk statistics and the lack of appreciation for variation (28 comments)
- Kelloggs in the house! (28 comments)
- Most controversial posts of 2020 (27 comments)
- The norm of entertainment (27 comments)
- Is explainability the new uncertainty? (27 comments)
- Chess.com cheater-detection bot pisses someone off (27 comments)
- The revelation came while hearing a background music version of Iron Butterfly’s “In A Gadda Da Vida” at a Mr. Steak restaurant in Colorado (27 comments)
- The ML uncertainty revolution is … now? (27 comments)
- Climate change as a biological accelerator (27 comments)
- National Academy of Sciences scandal and the concept of countervailing power (27 comments)
- Comments on a Nobel prize in economics for causal inference (27 comments)
- “The 100 Worst Ed-Tech Debacles of the Decade” (26 comments)
- “Do you come from Liverpool?” (26 comments)
- Any graph should contain the seeds of its own destruction (26 comments)
- Nooooooooooooo (another hopeless sex ratio study) (26 comments)
- Here is how you should title the next book you write. (25 comments)
- Alex Jones and the fallacy of the one-sided bet (25 comments)
- Two sides, no vig: The problem with generative and inferential reasoning in social science (25 comments)
- Learning from failure (25 comments)
- New textbook, “Statistics for Health Data Science,” by Etzioni, Mandel, and Gulati (24 comments)
- Let them log scale (24 comments)
- “Our underpowered trial provides no indication that X has a positive or negative effect on Y” (24 comments)
- The 2019 project: How false beliefs in statistical differences still live in social science and journalism today (24 comments)
- Indeed, the standard way that statistical hypothesis testing is taught is a 2-way binary grid. Both these dichotomies are inappropriate. (24 comments)
- Albert-Laszlo Barabasi is underpaid. By a lot! (24 comments)
- More on that claim that scientific citations are worth $100,000 each (24 comments)
- Event frequencies and my dated MLB analogy (24 comments)
- The textbook paradox: “Textbooks more than a very few years old cannot even be given away, but new textbooks are mostly made by copying from former ones” (23 comments)
- One more cartoon like this, and this blog will be obsolete. (23 comments)
- Evidence-based medicine eats itself in real time (23 comments)
- John Cook: “Students are disturbed when they find out that Newtonian mechanics ‘only’ works over a couple dozen orders of magnitude. They’d really freak out if they realized how few theories work well when applied over two orders of magnitude.” (23 comments)
- How to interpret inferential statistics when your data aren’t a random sample (23 comments)
- “Why do people prefer to share misinformation, even when they value accuracy and are able to identify falsehoods?” (23 comments)
- It’s so hard to compare the efficiency of MCMC samplers (23 comments)
- Importance of understanding variation when considering how a treatment effect will scale (23 comments)
- $ (23 comments)
- “The obesity wars and the education of a researcher: A personal account” (23 comments)
- There is only one reality (and we cannot demand consistency from any other) (22 comments)
- The both both of science reform (22 comments)
- The Javert paradox rears its ugly head (22 comments)
- Tableau and the Grammar of Graphics (22 comments)
- The continuing misrepresentations coming from the University of California sleep researcher and publicized by Ted and NPR (22 comments)
- How to reconcile that I hate structural equation models, but I love measurement error models and multilevel regressions, even though these are special cases of structural equation models? (22 comments)
- Teaching in person! (22 comments)
- Bayesian workflow for disease transmission modeling in Stan! (22 comments)
- A little correlation puzzle, leading to a discussion of the connections between intuition and brute force (22 comments)
- Objectively worse, but practically better: an example from the World Chess Championship (22 comments)
- My problems with Superior (22 comments)
- Megan Higgs (statistician) and Anna Dreber (economist) on how to judge the success of a replication (21 comments)
- “They adjusted for three hundred confounders.” (21 comments)
- Sketching the distribution of data vs. sketching the imagined distribution of data (21 comments)
- Is sqrt(2) a normal number? (21 comments)
- Answers to your questions about polling and elections. (21 comments)
- When can we challenge authority with authority? (21 comments)
- What can the anthropic principle tell us about visualization? (21 comments)
- Top 10 Ideas in Statistics That Have Powered the AI Revolution (21 comments)
- Tokyo Track revisited: no, I don’t think the track surface is “1-2% faster” (21 comments)
- The Bayesian cringe (21 comments)
- What are my statistical principles? What are yours? (21 comments)
- Suburban Dicks (21 comments)
- Drawing Maps of Model Space with Modular Stan (21 comments)
- The hot hand and the nudgelords (21 comments)
- The garden of forking paths: Why multiple comparisons can be a problem, even when there is no “fishing expedition” or “p-hacking” and the research hypothesis was posited ahead of time (20 comments)
- Some issues when using MRP to model attitudes on a gun control attitude question on a 1–4 scale (20 comments)
- Hullman’s theorem of graphical perception (20 comments)
- The insider-outsider perspective (Jim Bouton example) (20 comments)
- Computing with muffins (20 comments)
- Controversy over “Facial recognition technology can expose political orientation from naturalistic facial images” (20 comments)
- Design choices and user experience in Stan and TensorFlow Probability (20 comments)
- The so-called “lucky golf ball”: The Association for Psychological Science promotes junk science while ignoring the careful, serious work of replication (20 comments)
- “Maybe the better analogy is that these people are museum curators and we’re telling them that their precious collection of Leonardos, which they have been augmenting at a rate of about one per month, include some fakes.” (19 comments)
- “Maybe we should’ve called it Arianna” (19 comments)
- Postdoc in Paris for Bayesian models in genetics . . . differential equation models in Stan (19 comments)
- In making minimal corrections and not acknowledging that he made these errors, Rajan is dealing with the symptoms but not the underlying problem, which is that he’s processing recent history via conventional wisdom. (19 comments)
- We were wrong about redistricting. (19 comments)
- How do you measure success in an academic field such as astronomy? (19 comments)
- Include all design information as predictors in your regression model, then postratify if necessary. No need to include survey weights: the information that goes into the weights will be used in any poststratification that is done. (18 comments)
- Should we judge pundits based on their demonstrated willingness to learn from their mistakes? (18 comments)
- Whatever you’re looking for, it’s somewhere in the Stan documentation and you can just google for it. (18 comments)
- Blast from the past (18 comments)
- Feeling like a pariah (even when you’re not) (18 comments)
- We should all routinely criticize our own work. (18 comments)
- When does a misunderstanding reach the point where it is recognized to be flat-out ridiculous? (18 comments)
- When MCMC fails: The advice we’re giving is wrong. Here’s what we you should be doing instead. (Hint: it’s all about the folk theorem.) (18 comments)
- Guttman points out another problem with null hypothesis significance testing: It falls apart when considering replications. (18 comments)
- Get this man a job at the Hoover Institution! (18 comments)
- Against either/or thinking, part 978 (18 comments)
- Not being able to say why you see a 2 doesn’t excuse your uninterpretable model (18 comments)
- “Why Some Important Findings Remain Uncited” (18 comments)
- Pendulum versus policy explanations of the 2021 elections (18 comments)
- Reflections on a talk gone wrong (17 comments)
- My reply: Three words. Fake. Data. Simulation. (17 comments)
- Is the right brain hemisphere more analog and Bayesian? (17 comments)
- How to figure out what went wrong with this model? (17 comments)
- “Like a harbor clotted with sunken vessels”: update (17 comments)
- Questions about our old analysis of police stops (17 comments)
- Philip Roth biographies, and literary biographies in general (17 comments)
- What’s the purpose of mathematical modeling? (17 comments)
- Politics and economic policy in the age of political science (17 comments)
- Not-so-recently in the sister blog (17 comments)
- BREAKING: Benford’s law violations in California. Hollywood TV and movie franchises got some splainin to do! (17 comments)
- Reassessing Nate Silver’s claim from last month that Democrats’ successful (in retrospect) 1-and-Done campaign against the California recall was “self-destructive . . . bad advice . . . a mistake” (17 comments)
- f2f is better (17 comments)
- Writing negative blog posts (17 comments)
- How different are causal estimation and decision-making? (17 comments)
- Holland academic statistics horror story (17 comments)
- An economist and his lonely belief (17 comments)
- Social penumbras predict political attitudes (16 comments)
- Further comments on “Assessing mandatory stay‐at‐home and business closure effects on the spread of COVID‐19” (16 comments)
- “Men Appear Twice as Often as Women in News Photos on Facebook” (16 comments)
- Richard Hamming’s “The Art of Doing Science and Engineering” (16 comments)
- Open data and quality: two orthogonal factors of a study (16 comments)
- Raymond Smullyan on Ted Cruz, Al Sharpton, and those scary congressmembers (16 comments)
- Impressive visualizations of social mobility (16 comments)
- Can statistical software do better at giving warnings when you apply a method when maybe you shouldn’t? (16 comments)
- “Sponsored products related to this item” (16 comments)
- Claim of police shootings causing low birth weights in the neighborhood (16 comments)
- Forecast displays that emphasize uncertainty (16 comments)
- “What are your latest thoughts on how to use a posterior from a previous fit as the prior for a subsequent fit after collecting new data?” (16 comments)
- What is a claim in ML-oriented research, and when is it not reproducible? (16 comments)
- “As you all know, first prize is a Cadillac El Dorado. Anyone wanna see second prize? Second prize is you’re governor of California. Third prize is you’re fired.” (16 comments)
- Trash talkin’ (16 comments)
- This is a wonderful graph, because it clearly reveals that . . . (16 comments)
- Simulation-based inference and approximate Bayesian computation in ecology and population genetics (16 comments)
- A forecasting error in law school admissions. Could this have been avoided? (16 comments)
- What we did in 2020, and thanks to all our collaborators and many more (15 comments)
- Authors retract the Nature Communications paper on female mentors (15 comments)
- The Folk Theorem, revisited (15 comments)
- The Tall T* (15 comments)
- When can a predictive model improve by anticipating behavioral reactions to its predictions? (15 comments)
- The challenges of statistical measurement . . . in an environment where bad measurement and junk science get hyped (15 comments)
- Bayesian hierarchical stacking: Some models are (somewhere) useful (15 comments)
- Biographies of scientists vs. biographies of authors (15 comments)
- The Sheffield Graduate Certificate in Statistics (15 comments)
- Is the accuracy of Bayesian Improved Surname Geocoding bad news for privacy protection at the Census? Technically no, PR-wise probably. (15 comments)
- Replicating the literature on meritocratic promotion in China, or It’s all about ethics in social science workflow (15 comments)
- Spufford: “Semi-bamboozled” and cookery vs. science (special Thanksgiving post) (15 comments)
- Estimates of “false positive” rates in various scientific fields (15 comments)
- Weakliem on air rage and himmicanes (14 comments)
- How to track covid using hospital data collection and MRP (14 comments)
- Call for a moratorium on the use of the term “prisoner’s dilemma” (14 comments)
- Doubting the IHME claims about excess deaths by country (14 comments)
- He wants to test whether his distribution has infinite variance. I have other ideas . . . (14 comments)
- 4 years of an unpopular Republican president –> bad news for Republican support among young voters –> continuation of unprecedented generation gap –> I’m not sure what this implies for politics (14 comments)
- About those claims that the election forecasts hurt the Democrats in November (14 comments)
- This awesome Pubpeer thread is about 80 times better than the original paper (14 comments)
- Default informative priors for effect sizes: Where do they come from? (14 comments)
- Ten ways to rank the Tokyo Olympics, with 10 different winners, and no one losing (14 comments)
- Color schemes in data graphics (14 comments)
- Making better data charts: From communication goals to graphics design (14 comments)
- Found poetry 2021 (14 comments)
- “Translation Plagiarism” (13 comments)
- Subtleties of discretized density plots (13 comments)
- Hierarchical stacking (13 comments)
- Jordana Cepelewicz on “The Hard Lessons of Modeling the Coronavirus Pandemic” (13 comments)
- Impressions of differential privacy for supreme court justices (13 comments)
- Workflow and the role of hypothesis-free data analysis (13 comments)
- Take the American Statistical Association’s “”How Well Do You Know Your Federal Data Sources?” quiz! (13 comments)
- Adjusting for stratification and clustering in coronavirus surveys (13 comments)
- Simulation-based calibration: Some challenges and directions for future research (13 comments)
- “For a research assistant, do you think there is an ethical responsibility to inform your supervisor/principal investigator if they change their analysis plan multiple times during the research project in a manner that verges on p-hacking?” (13 comments)
- How does post-processed differentially private Census data affect redistricting? How concerned should we be about gerrymandering with the new DAS? (13 comments)
- Estimating basketball shooting ability while it varies over time (13 comments)
- Open positions in the Columbia statistics department (13 comments)
- Webinar: Predicting future forest tree communities and winegrowing regions with Stan (13 comments)
- Use stacking rather than Bayesian model averaging. (13 comments)
- Tessa Hadley on John Updike (12 comments)
- “Smell the Data” (12 comments)
- “From Socrates to Darwin and beyond: What children can teach us about the human mind” (12 comments)
- No, I don’t like talk of false positive false negative etc but it can still be useful to warn people about systematic biases in meta-analysis (12 comments)
- Understanding the value of bloc voting, using the Congressional Progressive Caucus as an example: (12 comments)
- size of bubbles in a bubble chart (12 comments)
- New book coming out by Fischer Black! (12 comments)
- Meta-meta-science studies (12 comments)
- “The Critic as Artist,” by Oscar Wilde (12 comments)
- On fatally-flawed, valueless papers that journals refuse to retract (12 comments)
- What’s the best way to interact with a computer? Do we want conversations, or do we want to poke it like a thing? (12 comments)
- I have some skepticism about this “Future Directions for Applying Behavioral Economics to Policy” project (12 comments)
- An urgent puzzle (12 comments)
- Election update (12 comments)
- “Fast state, slow state: what’s the matter with Connecticut?” (12 comments)
- Lying as kicking the can down the road (12 comments)
- They call him Dr. Manhattan because he updates in one dimension at a time. (12 comments)
- Eliciting expert knowledge in applied machine learning (12 comments)
- Stop talking about “statistical significance and practical significance” (12 comments)
- Will the pandemic cause a decline in births? We’ll be able to resolve this particular debate in about 9 months . . . (11 comments)
- Earliest Known Uses of Some of the Words of Mathematics (11 comments)
- Postdoctoral opportunity with Sarah Cowan and Jennifer Hill: causal inference for Universal Basic Income (UBI) (11 comments)
- I have these great April Fools ideas but there’s no space for them in the margin of this blog (11 comments)
- More background on our research on constructing an informative prior from a corpus of comparable studies (11 comments)
- “Causal Inference: The Mixtape” (11 comments)
- “Test & Roll: Profit-Maximizing A/B Tests” by Feit and Berman (11 comments)
- As Seung-Whan Choi explains: Just about any dataset worth analyzing is worth reanalyzing. (The story of when I was “canceled” by Perspectives on Politics. OK, not really.) (11 comments)
- Prior knowledge elicitation: The past, present, and future (11 comments)
- What we know about designing graphs (11 comments)
- What color is your
parachutebikecar? (11 comments)
- “Enhancing Academic Freedom and Transparency in Publishing Through Post-Publication Debate”: Some examples in the study of political conflict (10 comments)
- Luc Sante reviews books by Nick Hornby and Geoffrey O’Brien on pop music (10 comments)
- This one pushes all my buttons (10 comments)
- Ahhhh, Cornell! (10 comments)
- It was a year ago today . . . (10 comments)
- (10 comments)
- A recommender system for scientific papers (10 comments)
- Plan for the creation of “a network of new scientific institutes pursuing basic research while not being dependent on universities, the NIH, and the rest of traditional academia and, importantly, not being dominated culturally by academia” (10 comments)
- Coronavirus baby bust (10 comments)
- Polling using the collective recognition heuristic to get a better sense of popularity? (10 comments)
- Some researchers retrospect on their mistakes (10 comments)
- “Identifying airborne transmission as the dominant route for the spread of COVID-19” followup (10 comments)
- Shots taken, shots returned regarding the Census’ motivation for using differential privacy (and btw, it’s not an algorithm) (10 comments)
- Counterfactual history and historical fiction (10 comments)
- Oooh, I hate it when people call me “disingenuous”: (10 comments)
- An interesting research problem at the intersection of graphical perception and comparative politics. (10 comments)
- An important skill for woodworkers and social science researchers (10 comments)
- Statisticians don’t use statistical evidence to decide what statistical methods to use. Also, The Way of the Physicist. (9 comments)
- Question on multilevel modeling reminds me that we need a good modeling workflow (building up your model by including varying intercepts, slopes, etc.) and a good computing workflow (9 comments)
- Headline permutations (9 comments)
- I have a feeling this lawsuit will backfire. (9 comments)
- Leaving a Doll’s House, by Claire Bloom (9 comments)
- Ira Glass asks. We answer. (9 comments)
- Honor Thy Father as a classic of Mafia-deflating literature (9 comments)
- Comparing collaborative to non-collaborative research (9 comments)
- Being Alive (9 comments)
- “How We’re Duped by Data” and how we can do better (8 comments)
- “There ya go: preregistered, within-subject, multilevel” (8 comments)
- Webinar: Some Outstanding Challenges when Solving ODEs in a Bayesian context (8 comments)
- Marshmallow update (8 comments)
- This one’s for all the Veronica Geng fans out there . . . (8 comments)
- What did ML researchers talk about in their broader impacts statements? (8 comments)
- She’s thinking of buying a house, but it has a high radon measurement. What should she do? (8 comments)
- “The real thing, like the Perseverance mission, is slow, difficult and expensive, but far cooler than the make-believe alternative.” (8 comments)
- A quick fix in science communication: Switch from the present to the past tense. Here’s an example from New Zealand: (8 comments)
- Don’t Call Me Shirley, Mr. Feynman! (8 comments)
- Graphing advice: “If zero is in the neighborhood, invite it in.” (8 comments)
- Weights in statistics (7 comments)
- The “story time” is to lull us in with a randomized controlled experiment and as we fall asleep, feed us less reliable conclusions that come from an embedded observational study. (7 comments)
- Toronto Data Workshop on Reproducibility (7 comments)
- Come work with me and David Shor ! (7 comments)
- Drew Bailey on backward causal questions and forward causal inference (7 comments)
- Webinar: An introduction to Bayesian multilevel modeling with brms (7 comments)
- Estimating excess mortality in rural Bangladesh from surveys and MRP (7 comments)
- Another estimate of excess deaths during the pandemic. (7 comments)
- This one is for fans of George V. Higgins (7 comments)
- Stan short course in July (7 comments)
- “Historians’ Fallacies” by David Hackett Fischer and “The Rhetoric of Fiction” by Wayne Booth (7 comments)
- In which we learn through the logical reasoning of a 33-year-old book that B. H. Liddell Hart wasn’t all that. (7 comments)
- Progress! (cross validation for Bayesian multilevel modeling) (7 comments)
- Zzzzzzzzzz (7 comments)
- ProbProg 2021 is Oct 20–22 and registration is open (7 comments)
- What’s a good supply demand model to study visualization equilibria in rideshare/taxi routing? (7 comments)
- Cross validation and model assessment comparing models with different likelihoods? The answer’s in Aki’s cross validation faq! (7 comments)
- No, it’s not a “witch hunt” (7 comments)
- “A mix of obvious, perhaps useful, and somewhat absurd” (7 comments)
- Comparing bias and overfitting in learning from data across social psych and machine learning (7 comments)
- Interpreting apparently sparse fitted models (7 comments)
- Wilkinson’s contribution to interactive visualization (7 comments)
- Did this study really identify “the most discriminatory federal judges”? (7 comments)
- A problem with that implicit-racism thing (7 comments)
- Wombats sh*ttin brix in the tail . . . (6 comments)
- The Data Detective, by Tim Harford (6 comments)
- Scaling regression inputs by dividing by two standard deviations (6 comments)
- Conference on digital twins (6 comments)
- Life is long. (6 comments)
- A fun activity for your statistics class: One group of students comes up with a stochastic model for a decision process and simulates fake data from this model; another group of students takes this simulated dataset and tries to learn about the underlying process. (6 comments)
- logit and normal are special functions, too! (6 comments)
- Who’s afraid? (6 comments)
- “Reversals in psychology” (6 comments)
- Theoretical Statistics is the Theory of Applied Statistics: Two perspectives (6 comments)
- When to use ordered categorical regression? (6 comments)
- American Causal Inference Conference 2022 (6 comments)
- Rainy Day Women #13 & 36 (6 comments)
- Bayesian approaches to differential gene expression (6 comments)
- Journalists and social scientists team up to discover that Census data is not perfect (6 comments)
- What should we expect in comparing human causal inference to Bayesian models? (6 comments)
- James Loewen (6 comments)
- Patterns on the complex floor: A fun little example of simulation-based experimentation in mathematics (6 comments)
- Hey! Here’s a cool new book of stories about the collection of social data (5 comments)
- I was drunk at the podium, and I knew my results weren’t strong (5 comments)
- The Mets are hiring (5 comments)
- State-level predictors in MRP and Bayesian prior (5 comments)
- “Prediction Markets in a Polarized Society” (5 comments)
- “Analysis challenges slew of studies claiming ocean acidification alters fish behavior” (5 comments)
- Still cited only 3 times (5 comments)
- Webinar: Theories of Inference for Data Interactions (5 comments)
- Neel Shah: modeling skewed and heavy-tailed data as approximate normals in Stan using the LambertW function (5 comments)
- Incentives and test performance (5 comments)
- Adjusting for pre-treatment variables: Coronavirus vaccine edition (5 comments)
- “Citizen Keane: The Big Lies Behind the Big Eyes” (5 comments)
- Fun example of an observational study: Effect of crowd noise on home-field advantage in sports (5 comments)
- Standard Deviation by Katherine Heiny (5 comments)
- Some unexpected insights from Dan Ariely’s Wall Street Journal’s advice column! (5 comments)
- Nudge! For reals. (5 comments)
- Summer internships at Flatiron Institute’s Center for Computational Mathematics (5 comments)
- “Accounting Theory as a Bayesian Discipline” (5 comments)
- Typo of the day (4 comments)
- Thanks, commenters! (4 comments)
- Infer well arsenic dynamic from filed kits (4 comments)
- “Better Data Visualizations: A Guide for Scholars, Researchers, and Wonks” (4 comments)
- Webinar: On Bayesian workflow (4 comments)
- Is he … you know…? (4 comments)
- HCQ: “The clinical trials they summarized were predominantly in young healthy people so even the best drug in the world wouldn’t look good under their framework.” (4 comments)
- Pittsburgh by Frank Santoro (4 comments)
- Is this a refutation of the piranha principle? (4 comments)
- LambertW × FX transforms in Stan (4 comments)
- Instead of comparing two posterior distributions, just fit one model including both possible explanations of the data. (4 comments)
- “Hello, World!” with Emoji (Stan edition) (4 comments)
- Webinar: Kernel Thinning and Stein Thinning (4 comments)
- My slides and paper submissions for Prob Prog 2021 (4 comments)
- 0/0 = . . . 0? That’s Australian math, mate! (4 comments)
- “The Truants,” by William Barrett (4 comments)
- General Social Survey releases new data! (4 comments)
- DeclareDesign (4 comments)
- Lee Wilkinson (4 comments)
- Published in 2021 (and to be published in 202 (4 comments)
- Webinar: Functional uniform priors for dose-response models (3 comments)
- Sharon Begley (3 comments)
- Hierarchical stacking, part II: Voting and model averaging (3 comments)
- Summer research jobs at Flatiron Institute (3 comments)
- Priors for counts in binomial and multinomial models (3 comments)
- StanConnect 2021: Call for Session Proposals (3 comments)
- We’re hiring (in Melbourne) (3 comments)
- MRP and Missing Data Question (3 comments)
- Progress! (3 comments)
- Several postdoc, research fellow, and doctoral student positions in Aalto/Helsinki, Finland (3 comments)
- Webinar: A Gaussian Process Model for Response Time in Conjoint Surveys (3 comments)
- The Feud (3 comments)
- Famous people with Tourette’s syndrome (3 comments)
- “Tracking excess mortality across countries during the COVID-19 pandemic with the World Mortality Dataset” (3 comments)
- Bill James on secondary average (3 comments)
- The comments we live for (3 comments)
- Remote workshop happening today: “Bayesian Causal Inference for Real World Interactive Systems” (3 comments)
- The horrible convoluted statistical procedures that are used to make decisions about something as important as Alzheimer’s treatments (3 comments)
- “Students and Their Style” (3 comments)
- Learn Stan, get a job doing Bayesian modeling. How cool is that?? (3 comments)
- Comparison of MCMC effective sample size estimators (3 comments)
- TFW you can add “Internationally exhibited” to your resume (3 comments)
- A new approach to scientific publishing and reviewing based on distributed research contracts? (3 comments)
- Computation+Journalism 2021 this Friday (2 comments)
- A Bayesian state-space model for the German federal election 2021 with Stan (2 comments)
- Rob Tibshirani, Yuling Yao, and Aki Vehtari on cross validation (2 comments)
- Can you trust international surveys? A follow-up: (2 comments)
- “The Multiverse of Methods: Extending the Multiverse Analysis to Address Data-Collection Decisions” (2 comments)
- Statistical Modeling, Causal Inference, and Social Science gets results! (2 comments)
- When are Bayesian model probabilities overconfident? (2 comments)
- This one has nothing to do with Jamaican beef patties: (2 comments)
- Network of models (2 comments)
- Post-doc to work on developing Bayesian workflow tools (2 comments)
- The Tampa Bay Rays baseball team is looking to hire a Stan user (2 comments)
- From “Mathematical simplicity is not always the same as conceptual simplicity” to scale-free parameterization and its connection to hierarchical models (2 comments)
- “I’m not a statistician, but . . .” (2 comments)
- How to convince yourself that multilevel modeling (or, more generally, any advanced statistical method) has benefits? (2 comments)
- I got an email from Gabe Kaplan! (2 comments)
- Ph.D. position on Bayesian workflow! In Stuttgart! With Paul “brms” Buerkner! (2 comments)
- Webinar: Towards responsible patient-level causal inference: taking uncertainty seriously (2 comments)
- Is There a Replication Crisis in Finance? (2 comments)
- Causal inference and generalization (2 comments)
- Stan for the climate! (2 comments)
- “The most discriminatory federal judges” update (2 comments)
- Simulation-based calibration: Two theorems (1 comments)
- Multivariate missing data software update (1 comments)
- My talk’s on April Fool’s but it’s not actually a joke (1 comments)
- PhD student and postdoc positions in Norway for doing Bayesian causal inference using Stan! (1 comments)
- How much granularity do you need in your Mister P? (1 comments)
- Discuss our new R-hat paper for the journal Bayesian Analysis! (1 comments)
- One reason why that estimated effect of Fox News could’ve been so implausibly high. (1 comments)
- Hierarchical modeling of excess mortality time series (1 comments)
- A new journal dedicated to quantitative description focused on digital media topic (1 comments)
- Nicky Guerreiro and Ethan Simon write a Veronica Geng-level humor piece (1 comments)
- Frank Sinatra (3) vs. Virginia Apgar; Julia Child advances (1 comments)
- Webinar: Fast Discovery of Pairwise Interactions in High Dimensions using Bayes (1 comments)
- Short course on football (soccer) analytics using Stan (1 comments)
- The Alice Neel exhibition at the Metropolitan Museum of Art (1 comments)
- StanConnect 2021 is happening this summer/fall! Topics are Simulation Based Calibration, Ecology, Biomedical, and Cognitive Science and Neuroscience. (1 comments)
- The Xbox before its time: Using the famous 1936 Literary Digest survey as a positive example of statistical adjustment rather than a negative example of non-probability sampling (1 comments)
- Martin Modrák’s tutorial on simulation-based calibration (1 comments)
- Hiring postdocs and research scientists at Flatiron Institute’s Center for Computational Mathematics (1 comments)
- Approximate leave-future-out cross validation for Bayesian time series models (1 comments)
- Webinar: The Current State and Evolution of Stan (1 comments)
- “That Viral List of Top Baby Names Is BS” (1 comments)
- Design of Surveys in a Non-Probability Sampling World (my talk this Wed in virtual Sweden) (1 comments)
- Summer training in statistical sampling at University of Michigan (0 comments)
- Postdoc in precision medicine at Johns Hopkins using Bayesian methods (0 comments)
- Meg Wolitzer and George V. Higgins (0 comments)
- Work on Stan as part of Google’s Summer of Code! (0 comments)
- “Bayesian Causal Inference for Real World Interactive Systems” (0 comments)
- Formalizing questions about feedback loops from model predictions (0 comments)
- Postdoc position in Bayesian modeling for cancer (0 comments)
- The Brazilian Reproducibility Initiative wants your comments on their analysis plan! (0 comments)
- “Causal Inference for Social Impact” conference (0 comments)
- Bayesian forecasting challenge! (0 comments)
- Job opening at the U.S. Government Accountability Office (0 comments)
- “Sources must lose credibility when it is shown they promote falsehoods, even more when they never take accountability for those falsehoods.” (0 comments)
- Postdoc opportunity on Bayesian prediction for human-computer interfaces! In Stuttgart! (0 comments)
- “Measuring the sensitivity of Gaussian processes to kernel choice” (0 comments)
- Job opening for a statistician at a femtech company in Berlin (0 comments)
- Rodents Performing Visual Tasks (0 comments)
- posteriordb: a database of Bayesian posterior inference (0 comments)
- Postdoc in machine learning and computational statistics for cosmology (0 comments)
- PhD position at the University of Iceland: Improved 21st century projections of sub-daily extreme precipitation by spatio-temporal recalibration (0 comments)
- Your projects for the Communicating Data and Statistics course (0 comments)
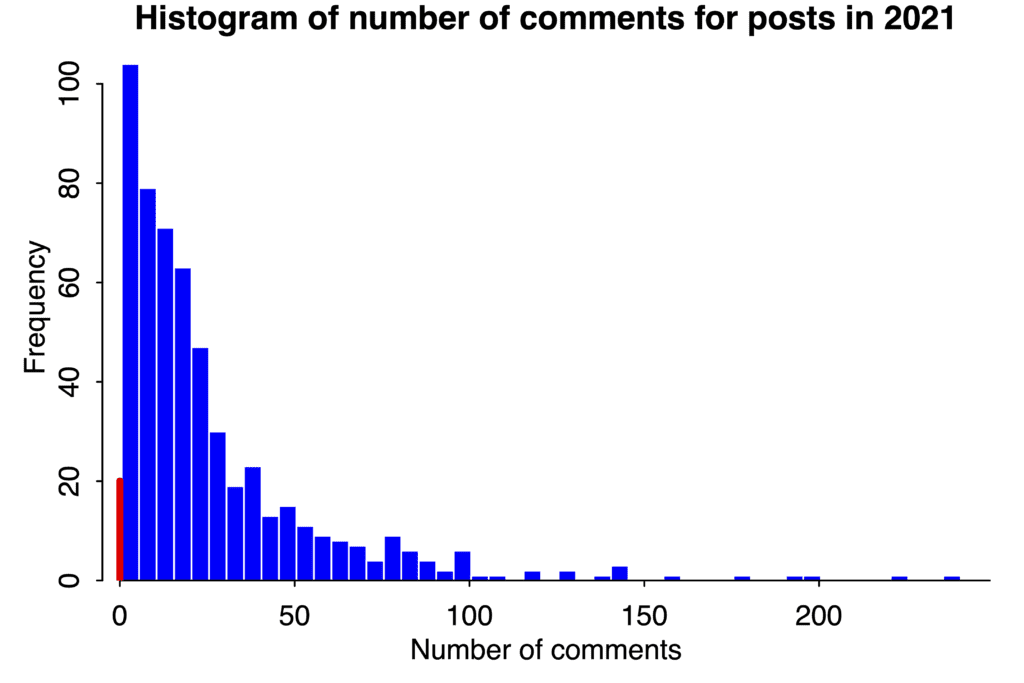
Above is a histogram of the number of comments on each of the posts. The bars are each of width 5, except that I made a special bar just for the posts with zero comments. There’s nothing special about zero here; some posts get only 1 or 2 comments, and some happen to get 0. Also, number of comments is not the same as number of views. I don’t have easy access to that sort of blog statistic, which is just as well or I might end up wasting time looking at it.
I also tried a time series plot:
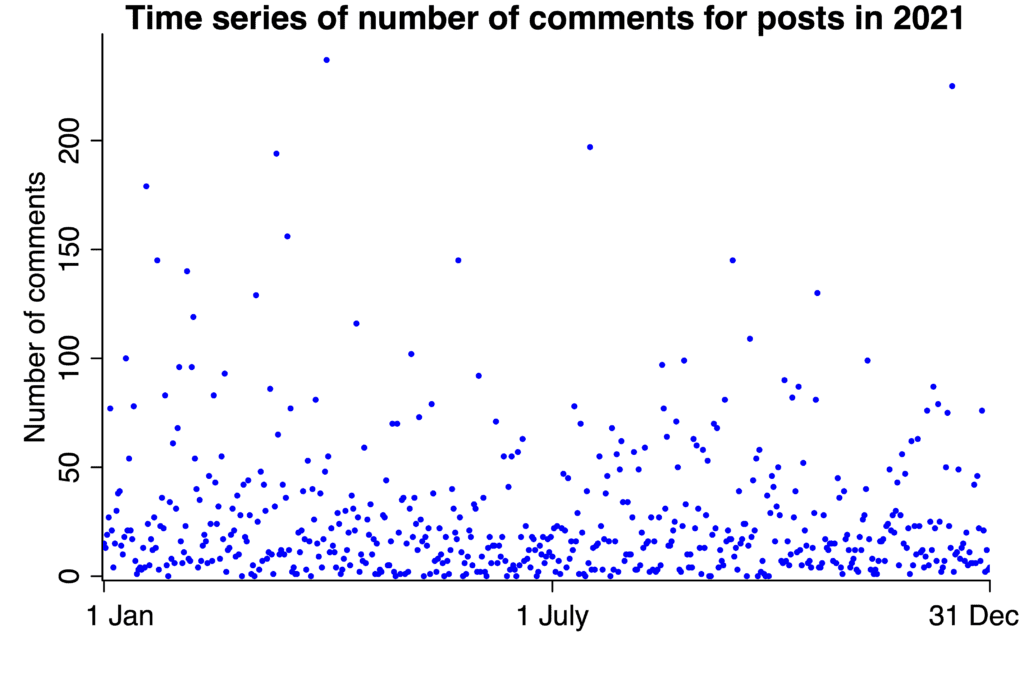
We learn something from this graph, which is that there are no clear time patterns. Sometimes we forget that an absence of surprise is itself informative.
Happy new year! And thanks to all of you commenters (except the spammers).
P.S. Here’s the (ugly) scraping I used to prepare the above list and graphs. I started things off by copying and pasting some summaries from the blog’s interface, which gave me a file that started like this:
Published in 2021 (and to be published in 2022) — Classic editor Edit (block editor) | Edit (classic editor) | Quick Edit | Trash | View Andrew 4 4 comments Published 2021/12/31 at 9:00 am Select A new approach to scientific publishing and reviewing based on distributed research contracts? A new approach to scientific publishing and reviewing based on distributed research contracts? — Classic editor Edit (block editor) | Edit (classic editor) | Quick Edit | Trash | View Andrew 3 3 comments Published 2021/12/30 at 9:23 am Select Stop talking about “statistical significance and practical significance” Stop talking about “statistical significance and practical significance” — Classic editor Edit (block editor) | Edit (classic editor) | Quick Edit | Trash | View Andrew 12 12 comments Published 2021/12/29 at 9:34 am
As you can see, it saved each blog entry as 8 records. I had to do some cleanup on the cases with No comments—I just did a search and replace in Emacs to change No to 0 and add a 0 row above it—and then I wrote the following (ugly) R code:
blog2021 <- readLines("blog2021.txt")
n <- length(blog2021)
titles <- blog2021[seq(1,n,8)]
titles <- substr(titles, 8, nchar(titles)-2)
comments <- as.numeric(blog2021[seq(5,n,8)])
ordering <- rev(order(comments))
titles_new <- titles[ordering]
comments_new <- comments[ordering]
post_list <- paste("<", "LI", ">", titles_new, " (", comments_new, " comments)", sep="", collapse="\n")
write(paste("<", "UL", ">\n", post_list, "\n<", "/UL", ">", sep=""), "post2021.html")
july1 <- (1:n)[substr(blog2021, 6, 10) == "07/01"] / 8
pdf("2021comments_a.pdf", height=4, width=6)
par(mar=c(3,3,1,1), mgp=c(1.5, 0.5, 0), tck=-.01)
hist(comments[comments>0], bty="l", breaks=seq(0.5,650.5,5), xlab="Number of comments", main="Histogram of number of comments for posts in 2021", col="blue", border="white", xaxs="i", yaxs="i", xaxt="n", xlim=c(-5, max(comments)*1.05), ylim=c(0, 110))
axis(1, seq(0, max(comments)+50, 50))
axis(2, seq(0, 100, 20))
lines(c(0,0), c(0, sum(comments==0)), lwd=4, col="red")
dev.off()
pdf("2021comments_b.pdf", height=4, width=6)
par(mar=c(3,3,1,1), mgp=c(1.5, 0.5, 0), tck=-.02)
plot(c(0, length(comments)), c(-2, max(comments)*1.05), bty="l", xaxt="n", yaxt="n", xaxs="i", yaxs="i", xlab="", ylab="Number of comments", main="Time series of number of comments for posts in 2021", type="n")
points(1:length(comments), rev(comments), pch=20, cex=.5, col="blue")
axis(2, seq(0, max(comments)+50, 50))
axis(1, c(1, length(comments) + 1 - july1, length(comments)), c(" 1 Jan", "1 July", "31 Dec "))
dev.off()
There seems to be something wrong with the timeseries plot. There are a couple of points over 200 which is consistent with the list you give
> A tale of two epidemiologists: It was the worst of times. (237 comments)
> Economics as a community (225 comments)
but the dates don’t look right (the second one should be mid-December).
D’oh! Fixed. Thanks.
Yet another way to view the data is to have a histogram of the number of unique commenters for a specific entry. Often enough, a particular blog will generate a heated back and forth between a couple of incensed and committed participants whose hot buttons are pressed and thus, the numerical counts are inflated. I assume that this suggestion may be rejected outright because of the possible difficulty in programming. Nevertheless, as a measure of the audience for a topic, it would be interesting to see how the histogram changes when uniqueness is taken into account.
Another technical issue arises: how to count Andrew himself, a person with perhaps a vested interest who may or may not be tempted to influence the count by responding to the responders?
Paul:
Yeah, I don’t have those data easily accessible. I’d have to do some serious scraping and programming to put together data on the comments. Number of comments for each post is easier, as it’s right there on the dashboard.
I’m guessing you could extract it from the SQL database that backs WordPress without any scraping at all. Not that you should, just that the appropriate level to access that stuff is at the backend.
+1 to that, but scraping isn’t too bad. I made a csv file of unique counts (title, num unique authors, num comments, url) and then put the file here:
https://drive.google.com/file/d/1YvRZusbEC3evuyqWa8UFyYx-Eji2i4qX/view
First five lines of that file ordered by number of comments:
A tale of two epidemiologists: It was the worst of times.,42,237,https://statmodeling.stat.columbia.edu/2021/03/30/a-tale-of-two-epidemiologists/
Economics as a community,35,225,https://statmodeling.stat.columbia.edu/2021/12/15/economics-as-a-community/
What is a “woman”?,44,197,https://statmodeling.stat.columbia.edu/2021/07/18/what-is-a-woman/
What is the landscape of uncertainty outside the clinical trial’s methods?,29,194,https://statmodeling.stat.columbia.edu/2021/03/07/what-is-the-landscape-of-uncertainty-outside-the-clinical-trials-methods/
What about that new paper estimating the effects of lockdowns etc?,39,179,https://statmodeling.stat.columbia.edu/2021/01/20/what-about-that-new-paper-estimating-the-effects-of-lockdowns-etc/
And here’s a gzipped csv of comment metadata (post date, url, title, comment author, comment author email, comment date):
https://drive.google.com/file/d/1Tv8nVBvUUV34d-ajemESmJrsc_1zdwpu/view
Paul –
That would be an interesting alternative way to look at that data – I say as someone who made a lot of comments on each of the “most controversial” posts.
Speaking of which, I looked back at some of the comments in the “two epidemiologists” post, and as a result reviewed this gem.
https://twitter.com/justin_hart/status/1308904131130781697?s=20
Scott referencing John, Jay, Martin, and Professor Gupta to explain how T-cells provide immunity from infection..
Remember when that group was telling us, in Sept, 2020, how we’d reach “herd immunity” much sooner than thought (that after John saying in April 2020 that we had probably peaked in COVID deaths in Europe and the US).
A perceptive 10 year old can see, and could see FROM THE START, that Covid-19 has nothing to do with real science (ie, it’s a s c a m).
YET…. most adults –including scientists, academics, doctors, and other formally educated folks– are rather profoundly perplexed and befuddled by the various absurdities of the Covid disaster (e.g., the back-and-forth shifting of scientific decrees, the censorship of valid data, the fraudulent fabrication of exaggerated numbers of “covid cases,” etc.). They cannot really make sense out of it all. At best, they can DESCRIBE the absurdities but they cannot explain WHY it is happening and explain WHAT the governing authorities truly are.
Why is that? It is because they lack pieces of vital knowledge, a lack that hinders and disables accurate coherent full understanding (therefore, it impairs the proper decision-making process and the potential for profound constructive action).
Those “missing” pieces of knowledge right in front of our noses are described in a comprehensive article called “The 2 Married Pink Elephants In The Historical Room –The Holocaustal Covid-19 Coronavirus Madness: A Sociological Perspective & Historical Assessment Of The Covid “Phenomenon”” at https://www.rolf-hefti.com/covid-19-coronavirus.html
Without a proper understanding, and full acknowledgment, of the true WHOLE problem and reality, no real constructive LASTING change is possible for humanity.
“2 weeks to flatten the curve has turned into…3 shots to feed your family!” — Unknown
Chris:
Covid killed close to a million people in the U.S. alone, so please take your conspiracy theories to twitter or 4chan or some place like that where you can troll to your heart’s content. Not here, please.
Thanks Andrew!
“take your conspiracy theories”
Condemnation without investigation is the height of ignorance, someone once said. But as Chris said, covid isn’t about science or reason, only politics. So is this site and institution, evidently, maintaining the Covid Scam.
And, Andrew, I take it that by “conspiracy theories” you do NOT mean the criminal establishment’s OFFICIAL conspiracy theories THEY (and you) LOVE, such as THEIR official Irak’s weapons of mass destruction conspiracy theory, or THEIR official Assad’s use of chemical weapons conspiracy theory, or THEIR official Russiagate conspiracy theory, or THEIR official JFK lone shooter assassination conspiracy theory, or THEIR official 9-1-1 inept pilots/fires brought down skyscrapers conspiracy theory, or the Covid virus caused a lethal pandemic conspiracy theory, and on and on with their authorized conspiracy theories THEY LOVE.
Brenda:
There are lots of wacky things believed by X% of the population, where X > 0. Indeed, surveys reveal that lots of Americans believe in ghosts! So it’s no surprise to me that some of our readers believe in JFK conspiracies and 9/11 conspiracy theories etc. I’m not asking you to change your beliefs; I’m just saying that Twitter, 4chan, etc., will be better places for you to discuss them. The internet’s a big place. This blog is good for lots of things, but arguments over conspiracy theories is not one of them. Fortunately, there are lots of places you can go online to have such discussions.
Yea, probably it is a lot of me and Joshua, unanon, et al skewing the results.
Perhaps it is better to make fewer high quality posts.
Anon:
I think all our posts are high quality. If you think they’re low quality and you can do better, start your own damn blog.
Sorry for the miscommunication, I was referring to myself making fewer but higher quality comments.
Oh! Thanks for clarifying.
There’s another way to misinterpret that sentence: this blog has too many high-quality posts and if it had fewer of them, we’d be better off.
That’s actually how I interpreted it – to sarcastically imply there’s an inverse correlation between number of comments and high quality posts.
Aren’t you making a mistake that you often point out in others? Measuring one thing (number of comments) and calling it something more enticing (level of controversy)? Or are you being ironic? When I skim the comments it isn’t obvious to me that your highly-commented-upon posts themselves are always controversial!
Ps: What are the conditions for the awarding of the “Zombies” tag?
David:
I’m just frustrated that the literature posts get so few comments. This is the stuff I really love!
Andrew: I like your literature posts! Perhaps you should be happy that they have few comments, instead of their being overwhelmed by irrelevant babbling about Covid. It might be interesting to see the number of views of each post, rather than the number of comments. I would guess that your blog software can easily list this.
Raghu:
I think there must be some sort of hit counter but I don’t know where it is. Also if I knew how to get to it, I might waste time looking at it and counting my hits, and what a waste of time that is. Back in the day, I used to waste time checking the Amazon rankings of my books, and nowadays I’ll check out Google Scholar to see the gradual increase in my pile of
gold piecescitations. Better just not to know, I think. Also I’ve been told that it’s very hard to get a sense of how many readers we have, because people have feeds or come to the posts from twitter. I don’t really know, and, again, that’s probably for the best. Also, I don’t really know how to use the blog software except for writing and scheduling posts and approving comments or sending them to the spam folder.I look forward to the literature posts. I don’t usually comment, but they have led me to writers I was unaware of or reminded me of still unread books.
I am continually impressed by the general high quality of comments on this blog and the relative rarity of trolling and flaming.
Thanks
I like the literature posts too, although they tend to result in my making incomprehensible snarks about obscure corners of Japanese literature…
Is there any suspicion of, perhaps unintended, “click bait” or even “clique bait”? Although, I am not exactly sure what is meant by the last term. Obviously, blogging sites, if only subconsciously, want responses and thus, make an effort to chose topics which generate a large number of responses. If so, are we to look at the tail ends of the above histogram as evidence of failure?
Paul:
If we really wanted clickz, we could add some posts on PC/Mac, emacs/vi, and Israel/Palestine.
Andrew –
Reading Paul’s comment, I’m kind of curious.
Probably you do put up posts to get people to respond. But it wouldn’t seem to me that you’d think a post that fails to get responses or only a few responses is necessarily a “failure.” Likewise, I wouldn’t imagine you’d think a post a “success” merely because it gets a lot of comments.
So then maybe a reasonable question is…how do you evaluate the success or failure of a given post? Or maybe even it doesn’t make sense to evaluate individual posts discretely, and the blog should necessarily be viewed as a whole?
I’ve had a wonderful time reading the posts on Andrew’s blog. Very high quality discussions.
Happy and Safe New Year to Everyone. Regards
Joshua:
If I posted something that nobody read, I guess I’d consider that a failure. Not a complete failure, because I still got the opportunity to think things through by myself, but mostly a failure because the blog is mostly about communication. But I think the posts with 0 comments still get read. So I don’t really have any thought of posts being successes or failures. I think they’re pretty much all successes. Often the comments are helpful, either in revealing that I didn’t explain something well or in revealing that I was confused about some point.
As I’d like to (re-)read some of your old material I suggest two augmentations.
1) That this page of the “Posts of this year, link from the Titles to the Posts so that I could click through the Titles to the post that sounded interesting or that there were a lot of comments on.
2) You have a way for a user to Optionally click [Titles] for each of the areas of interest, e.g. ‘Administration” … to see the titles and then click on the specific title to view the article.
Thanks…
Mike:
I’d like to do that too—it would just take a lot of work for me to do it! The good news is that you can find any of these posts by putting the title in quotes and googling it.
Thanks…
Once again, I am late to the party. I thought I was ever so clever by inventing the term, “clique bait”, when in fact, it is the title of a 2020 novel by Ann Valett. The blurb from goodreads.com is:
“Chloe Whittaker is out for revenge.
Last year her best friend Monica’s life was unceremoniously ruined by the most popular students at their high school, so this year Chloe plans to take each and every one of them down. She’s traded in her jeans and T-shirts for the latest designer …more”
Still, it is early in 2022, so there is time for creation of a neologism.
I would be intetested in an analysis by topic, i.e. for each tag, list the number of blog posts with this tag, and the cumulative total for that tag.
I expect “covid” and “zombies” would come out on top, but the middle part of the analysis could hold some surprises?