As youall know, as the coronavirus has taken its path through the world, epidemiologists and social scientists have tracked rates of exposure and mortality, studied the statistical properties of the transmission of the virus, and estimated effects of behaviors and policies that have been tried to limit the spread of the disease.
All this is difficult. Exposure rates are estimated based on nonrepresentative samples, death rates are hard to pin down, latent parameters such as the famous R_0 are themselves highly variable and not so clearly defined, and estimated causal effects are inherently model dependent given the observational nature of the data, even beyond all the challenges of measurement and of parameters that vary within countries and over time.
Some of the most prominent research in this area is being conducted by the research group at Imperial College London, and one of the most influential papers from this group is “Estimating the effects of non-pharmaceutical interventions on COVID-19 in Europe,” by Seth Flaxman et al. and published in the journal Nature in June.
I’m positively disposed to this work because they did a multilevel Bayesian analysis using Stan, and my colleagues and I gave them some advice on modeling, computation, and graphics. Just to be clear: I’m not trying to claim any credit here; I just felt that their general approach was reasonable, they were open to criticism, and they were working in an appropriately open-ended fashion. Also, I know Flaxman, as he visited our research group a few years ago before going to England.
Anyway, the Flaxman et al. paper has been controversial as well as influential; one criticism of his work came from Philippe Lemoine and was discussed in our blog comments the other day.
When I heard about that critique, I contacted Flaxman and asked what their team thought about it.
Here’s Flaxman’s response, not just to that particular post by also to other, related criticisms that they received:
With colleagues at Imperial College London, we’re currently working around the clock trying to understand a new variant of the virus that causes COVID-19 here in the UK. A preprint and report are coming soon. In addition to groundbreaking genomic work by my colleagues, we’re relying on the Bayesian hierarchical semi-mechanistic epidemiological methods that we developed for Imperial College report 13, published in Nature in June, and which underlie our daily estimates of the situation in the UK and our publications on the US and Brazil.
I’m writing as readers may be interested in a newly published discussion in Nature: Soltesz et al. along with our response. For background, readers might also watch our StanCon plenary, and my Samsung award talk. And finally, if anyone is interested in trying our methods (which we’ve successfully applied to integrate data streams on deaths, cases, hospitalisations, and serological surveys), we have an R package called epidemia, based on rstanarm. This is what we use for the UK website.
The newly published discussion, and other criticism online, have focused on our use of a particular partial pooling approach to estimate the effect of non-pharmaceutical interventions (NPIs) on the time-varying reproduction number R(t), and also on the implication of our results for and in the context of Sweden’s less stringent measures. You can read what we hope is a measured exploration of these important issues in our response to Soltesz et al. Here’s what I think is the key figure in our response, showing the uncertainty inherent in single-country estimates, and comparing a meta-analysis approach to various pooling approaches:
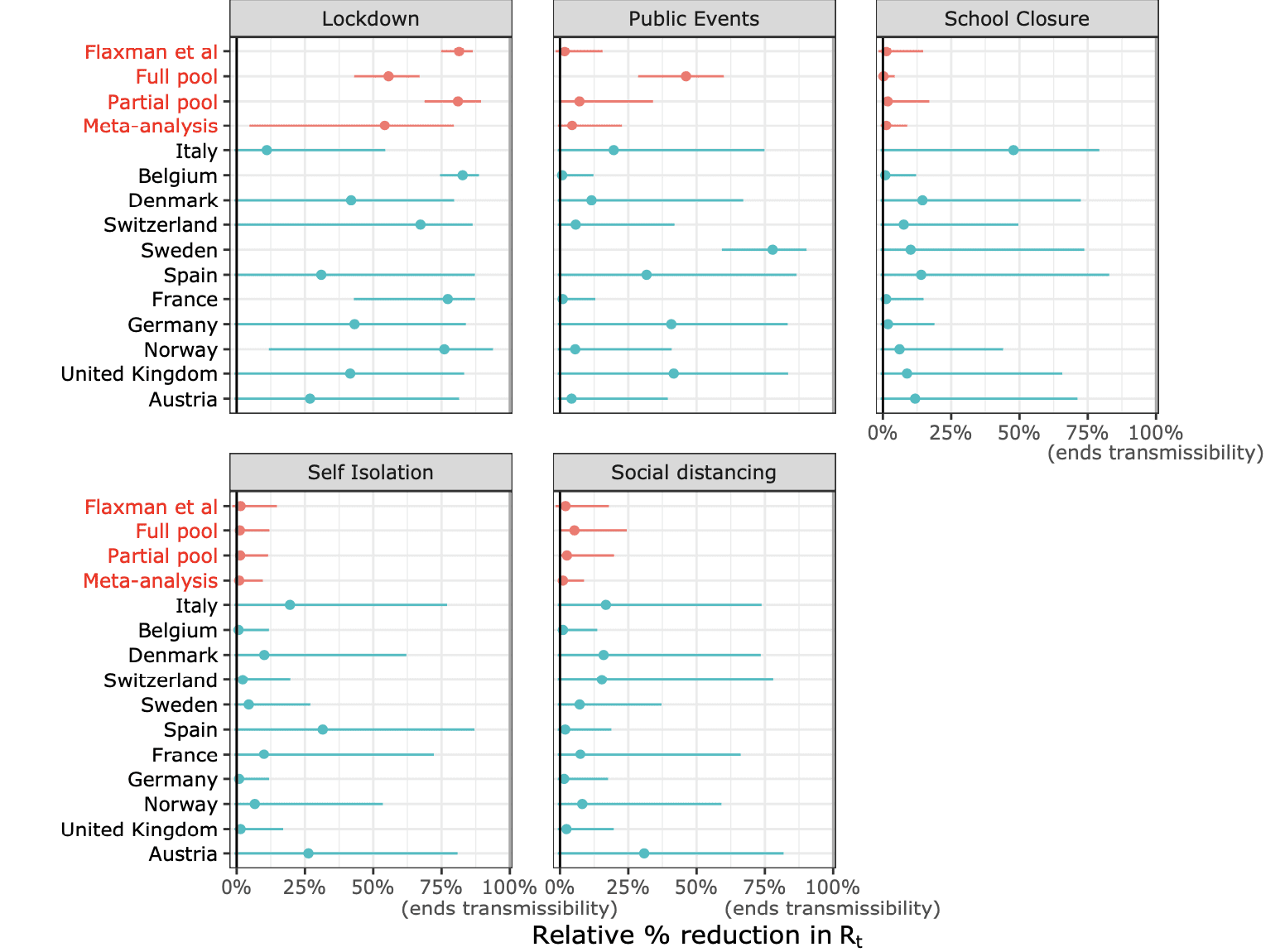
And here’s our concluding paragraph (but read the whole thing, it’s not so long!):
In summary, we believe that the additional evidence we present here confirms that the key conclusion from our paper is robust: within our model we can conclude that all NPIs together brought the epidemic under control; lockdown had the strongest effect and was identifiable; and the precise effect of the other NPIs was not identifiable. Although our work shows that lockdowns had the largest effect size, we did not and do not claim that they were the only path to controlling the virus; merely that among the NPIs we considered, lockdown was the most effective single measure. We of course acknowledge that improvements could be made to our model, such as including random processes, partial pooling (see above) or more prior analysis. Improved models and more granular information on NPIs and population behaviour will in future hopefully give a more nuanced understanding of which measures—whether mandatory or voluntary—contributed most to reductions in transmission.
I think it’s great that we’re getting this sort of open post-publication review. That’s what modern science is all about, and indeed this topic is way too important not to be the subject of robust discussion. I appreciate the work done by Lemoine and others (even if I think some of their criticisms miss the point), and I also appreciate that Flaxman et al. took the criticisms seriously and responded.
Many of the criticisms ultimately come down to a desire to fit more realistic models, as well as to more carefully display and diagnose issues with existing fitted models, and both these steps are important parts of statistical workflow; they represent forward motion and improved integration of models, data, and science.
This is the way to go. So much better than a twitter fight.
P.S. The record of the peer review for this article is public; here it is.
P.P.S. More from Flaxman here in the comments.
In what way is the epidemic is currently “controlled”?
The original idea was to lockdown for 2 weeks. If it is “controlled” why are there still lockdowns everywhere? In fact in some places like the UK they seem to be getting more extreme as time goes on.
Anon:
“Under control” is not the same as completely controlled. There are different levels of control. On one extreme would be a country with zero cases, or with so few cases that each one could be tracked. On the other extreme would be the virus rampaging, with so many cases that the public health system is overwhelmed. We’re somewhere in between.
Right, where do they place the cutoff? There is no place that locked down and has now returned to normal, which is the optimal outcome.
“. . . there is no place that locked down and has now returned to normal.”
I don’t know anything about the reliability of this report. Well, actually, I do—in a Bayesian sense. I distrust (1) info from highly-controlled nations and (2) the Guardian. But this article claims that once-locked-down Wuhan is close to normal.
https://www.theguardian.com/world/2020/dec/11/wuhan-in-then-and-now-pictures
Bob76
There were videos from Wuhan of people collapsing in the street, etc in January too.
“normal” is a similarly subjective term.
NZ is pretty near normal – the boarder is highly controlled but that’s about it. Oz and Taiwan, except for each having a small geographic outbreak, are pretty similar (last time I checked).
New Zealand is not back to normal at all. This is not normal:
https://www.theguardian.com/world/2020/nov/13/new-zealands-mystery-auckland-covid-case-linked-to-previous-cluster
That’s from early November – 6 weeks ago. One person in the community caught it from someone working in a quarantine hotel for overseas arrivals – traced back through genomics. That’s the last known case in the community (i.e. a case outside of boarder control/quarantine).
Since then it’s gone back to near-normal.
Next time there’s a positive test the government will be putting people in quarantine and shutting down neighborhoods again.
That is not normal. And the longer this goes on the more population immunity will wane towards the many infectious pathogens that are normally circulating. Things can probably never go back to normal in NZ.
Anoneuiod:
“And the longer this goes on the more population immunity will wane towards the many infectious pathogens that are normally circulating. ”
It’s almost as though we should consider developing and deploying a vaccine, isn’t it?
Theres nothing wrong with vaccines in general, but Ill be very surprised if one developed withput actually looking for ADE where it was expected is going to go smoothly. We will be very lucky if that works out.
Wait for vaccinated nursing home patients to be exposed, and/or after waning, and/or when new strains with mutations in the S1 subunit of the spike protein start circulating (Pfizer and Moderna both subsituted two consecutive prolines into the top of the helix of the S2 subunit, and have not been reporting anti-S2 results).
Then there is the new info about reactions to PEG. What happens when you inject PEG into millions of people with an adjuvant? We are about to find out.
Appropriate treatments are a far superior solution. Correct the antioxidant vitamin deficiencies with vitamins and oxygen deficiency with HBOT. This was being done in China since Feb.
https://mobile.twitter.com/DSM/status/1224262885729349633
The point is that there are some places that have had lockdowns that are now back to near normal. NZ and Oz are examples.
Anything could happen in the future, who can tell, but that doesn’t change the facts as they are now.
Living in fear the government decides to shut down your business, work, favorite pub, ability to see family, etc at any moment due to no fault of your own is not near normal though.
Then there are the travel restrictions and contact tracing apps.
This is not normal. It is an expensive and intrusive intervention.
Above got submitted without the link, etc: https://www.tvnz.co.nz/one-news/new-zealand/nz-covid-tracer-app-gets-major-bluetooth-upgrade-allow-auto-contact-tracing
And yes, it is very expensive:
https://www.nzherald.co.nz/nz/budget-2020-governments-50b-covid-19-recovery-budget-biggest-spending-package-in-history/TIKIKSKNZP4US7KO4LYV46ED2M/
>Living in fear the government decides to shut down your business, work, favorite pub, ability to see family, etc at any moment due to no fault of your own is not near normal though.
Given recent election results in NZ, I think that “living in fear” of fovefent actions is not a very apt description. In fact the opposite might be a better description – that people are living in fear of what would happen should the government stop making such decisions.
Again, “normal” is a subjective term. And it’s also always amidst a context. With the existence of a virus out and a out that is as virulent and highly contagious as COVID, there is no “normal” – but various degrees of being closer to normal. Peope in NZ seem to think that a state where their government intervenes proactively is closer to a normal state than a government that follows a policy of letting it rip.
> This is not normal. It is an expensive and intrusive intervention.
>> Then there are the travel restrictions and contact tracing apps.
By your standard, nothing is “normal” because we aren’t living in caves.
> This is not normal. It is an expensive and intrusive intervention.
“Expensive” and “intrusive” here are also subjective and context-dependent. Expensive as compared to the alternative? Intrusive as opposed to there being an unchecked pandemic? Seems that the people of NZ don’t think so. You shouldn’t decide for them what is or isn’t intrusive.
I have to admit that, in a way, ever increasing spying and debt every year with the resulting growth of wealth inequality has been normalized.
2020 saw such a large quantitative increase relative to previous years that it seems qualitative though.
Do we know that vaccine escape mutations are even possible? IIRC none are yet known (increase in infectiousness, yes probably, vaccine escape, no). If the vaccines work against the spike protein, which the virus needs to enter the cell…
I also remain *extremely* skeptical about ADE being a thing for SARS-COV-2. Besides all the factors we’ve argued about here before, it’s now almost 10 months since the first big spikes of infection outside China in ~early March. I’d expect we should be seeing it by now if it was more than vanishingly, irrelevantly rare, as antibodies ought to have had time to wane; yet we don’t see this in, say, New York which is now being hit again. Reinfection remains rare.
It would go against decades of science to think otherwise. The idea they would be impossible makes little sense.
It is pretty much guaranteed to show up… when there are few and/or low affinity antibodies. Which only one paper checked, and saw ADE in vitro.
I will bet you if you want. It is coming at some point unless the virus dies out. We just don’t know the exact details of what antibody affinities/concentrations or mutations can do it. But it is coming.
So would you like to!bet on this?
I’m not claiming that vaccine escape *is* impossible – but I don’t know how we can say it is definitely possible at this point, either. If the Spike protein is needed to enter a cell (and therefore be infectious), it seems quite possible that any change large enough for vaccine escape would make it nonfunctional.
I don’t bet over the internet (or at all, actually), and I’m also not sure that there will be a clear way to determine it. I mean, how does one demonstrate that a case of severe disease post-vaccination or after reinfection was ADE vs. vaccine failure/failure to develop immunity the first time?
It depends on what we are arguing about. I’m not claiming that ADE won’t *ever* happen – people are individual and biology is weird. I am claiming that it won’t be a major problem, i.e. the vaccine will be within reasonable bounds about as effective as it is claimed to be.
The latter proposition should be pretty clearly known to be true or false within say a year or so after most of the population has been vaccinated, so maybe mid-late 2022.
IE, there may be a difference between ADE as a rare wacky individual fluke of people’s immune systems, and ADE as a major distinct broadly-clinically-relevant phenomenon e.g. the dengue case. The latter is what I am arguing against.
Plenty of viruses seem to provide usually lasting immunity (though not completely 100%, e.g. I had chickenpox twice, probably because the first case was mild), I don’t see why this shouldn’t be one of them.
https://www.biorxiv.org/content/10.1101/2020.12.28.424451v1
There you go.
That’s stronger than what I’ve seen so far, admittedly.
Though the comment about England/South Africa seems contradictory to what I’ve read about the England variant elsewhere (why aren’t there hundreds of thousands of reinfections there if it’s really acting similarly to this antibody-escape mutation?), so I remain not wholly convinced that this would act as suggested in vivo.
> I have to admit that, in a way, ever increasing spying and debt every year with the resulting growth of wealth inequality has been normalized.
People make an assessment of what they consider to be the net value tradeoffs.
Your assessment seems to be largely in the minority
Oops. Posted too early.
… largely in the minority on certain issues.
Apparently you think people would be better off if they aligned themselves more with your assessment of what’s more valuable. That’s “normal” to think that.
But it doesn’t make your assessment equal what is factually true.
And your determination of what has been “normalized” recently is arbitrary. I’d say that people forming opinions about what’s in their best interests has been “normal” forever.
For example, people have long been engaged in deciding what they wanted to do to gain short term benefits and security over longer term risk. Your determination for how to characterize the attributes of that process of normalization to identify recent trends, is subjective.
The question was locked down and then got better—many of the countries that are doing great, like Taiwan, never locked down at all. So they provide no information about the effectiveness of a lockdown.
I’m from Melbourne, Australia. We had a second wave peaking at 725 new community cases in a day (too many to properly track) and shortly afterwards 6768 active cases. We locked down, and we’re now on 58 (?) days of zero community cases.
I agree that “control” is an unfortunate term. It’s not unlike your recent blog post where you say that authors would be better using terms like “suggest” or “is consistent with” as opposed to language that overstates conclusions of causality.
Of course, people with an axe to grind can sometimes make too much of such terminology and ignore more general conclusions to nit-pick. It’s a balancing act.
Nothing wrong with using language that is…er…consistent with…uh…the data. :)
Personally I love the word “allow”, which can be used honestly even when the weight of the data is clearly against one’s hypothesis or conclusions! Compare to “support”, which it implies that there is actually some suggestion from the data that the expressed H/C are correct, while “allow” implies merely that one’s H/C can be snaked improbably through the maze of facts without hitting a brick wall.
Someone should compile a list of important science words like “support” and “allow” and “confirm” and “show” and work out their specific properties. Maybe there’s something to be discovered – some sort of periodic table kind of structure, with different words having different bonding with other words and sets of properties that allow them to be used in specific circumstances…
A weasel word which has found its way into the discourse is “may”.
Parse for “may” in a large set of Conclusions sections and you’ll see it!
Why is offering conjecture with an appropriate caveat (“may”) a weasel word? Better to ignore uncertainties or not speculate?
I don’t disagree. However I call it a weasel word because I see it in a preponderance of cases “wearing the pants” — the under-powered or ill-focused “study” finding its raison d’etre in the last-sentence, to the extent that the results “may lend support to X” where “X” is some hypothesis of fundamental interest to all, but well beyond the reach of the weak work at hand. Sometimes this “may” indeed expresses appropriate caution or modesty; but more often than not it’s the other way around: the non-entity being reported attaches itself to something significant, as the curtain goes down.
I don’t disagree with your more detailed explanation.
I have a reaction to the “weasel word” phrasing because in the climate “skeptic” blogosphere that term is often loosely applied to criticize appropriate caveats related to uncertainty.
Joshua said,
“Why is offering conjecture with an appropriate caveat (“may”) a weasel word? Better to ignore uncertainties or not speculate?”
I don’t think that offering a conjecture with a caveat such as “may” is putting enough emphasis on the uncertainty. To be intellectually honest, one needs to give at least some support for a conjecture, but also emphasize that the conjecture is not expressing certainty.
“Better to ignore uncertainties or not speculate?”
Better to report the primary outcome of the work in concrete terms, then proceed to clearly labeled speculation.
All pandemics are dynamic. To control a pandemic is to act to flatten the curve of contamination each time it is necessary. Lockdowns for two weeks had big success, they flattened the curve very well, the historical curves show that. But what did it happen in sequence? The distancing social that was very high in a lockdown goes diminishing each more after a lockdown. The virus increases of tax of contamination and the curve begins to increase. So, it’s necssary more lockdowns to flatten the curve again. A smart child understand this. Did you understand or I need to paint for you?
The patient’s cancer keeps returning, requiring increasing doses of chemo and radiation. Would you call that “controlled”?
Compared to “the patient got cancer, a tumor the size of a grapefruit grew and stopped their heart and they died in 3 weeks” yes.
A thing is controlled to the extent that it doesn’t proceed in the way that it would have without the efforts to control it. The more effort, the better the control obviously. This is all well understood in “control systems engineering”. “Controlled” doesn’t mean “zero infections” it means infections aren’t exponentially growing.
Of course in the US at the moment they are exponentially growing, but that’s because individuals stopped doing the control things. Sending the control commands from the controller doesn’t work if the wires are cut or the servos are stuck either.
If continuing and even more extreme interventions kept being required and the doctor said its “controlled” because maybe if they had done nothing it would have become worse faster, I doubt most people would be optimistic.
I think that when we use the word “controlled” we need (to be intellectually honest) to give it an appropriate qualifier, e.g. “somewhat controlled”, “largely controlled, or “completely controlled” as appropriate to the evidence and
My point is the way “controlled” is being used could mean anything really.
A virus spraying in the population is not a cancer, asshole. We are not using chemotherapeutic. We are using social distancing, this works very well. Your comparison is ridiculous. In biological terms, yes, it is a controlled situation whenever the contamination curve is flattened, having lockdowns spaced over time. See the case of Israel, see the contamination curve of Israel, they will do the third lockdiwn soon to keep the situation under control. Will I need to continue painting?
Albert:
Hey, no need to call people assholes. This is a family blog here! In all seriousness, let’s try for our comments to add to the conversation. If you just want to throw insults around, we have twitter, 4chan, etc.
Ask the patient.
I do not find their rebuttal convincing.
Firstly: per their rebuttal they find that in Sweden, banning public events had a huge effect. However, Sweden did not ban all public events, just those with over 500 people. Do lockdowns work homepathically – the weaker the dose, the more effective they are?
Secondly: and maybe this is a point that only affects part of the data, but it’s the part I’m most familiar with so it’s a little concerning – they claim that Germany did a “full lockdown” at some particular date. I’m a little surprised because I was in Germany then, and the way things worked here is that every state did something a little different. In most states, there never was a “full lockdown” – people from two households were always allowed to meet. In the state of Bavaria, harsher measures were decreed earlier than in other states, but even there people were allowed to leave their homes to exercise with a friend in contrast to (say) France. Flaxman et. al can’t really take “Germany” as a single entity given that different states had different measures.
It’s also a bit hard to separate cause from effect here – by the time the measures were instituted, everyone was panicking about the virus and not leaving home anyways. Did the measures cause people to stay home, or did the measures happen because of the panic about the virus? It would be nice if they could have a “fear of the virus” parameter in their model, but they don’t.
There used to be occasional serious arguments between serious people about whether the propensity in some individuals to develop lung cancer may in fact have stimulated the appetite for tobacco. It’s not out of the realm of comprehension is it?
(Let me provide an example — a real life example. Many years ago the family cat disappeared for a spell and I finally found him hidden in a dark corner in the garage; I’d heard a scratching sound and it led to the cat. The scratching sound was the cat licking a rusty iron pipe! The cat was taken to the doctor’s and the blood work showed: advanced leukemia, RBC near zero! Thus, the craving for iron.)
Back to the topic at hand. Are our commitments to one or another scholastic orthodoxy so rigid that we cannot conceive of public guidance being given in an emergency — without waiting until the peers of the publishing review have finished their needlework and made the ex-cathedra pronouncment, that as it turns out effect does follow cause, after all?
Well yes, if one demands evidence for claims in general then sometimes one demands evidence also for claims that later turn out to be true. I personally find it difficult to unquestioningly just accept the true claims, but if you know a way do let me know…
This isn’t about “scholastic orthodoxy”, it’s about trying to find out what is *true*. And if we don’t know what is true, why give “public guidance” at all? “Public guidance” by scientists is often notoriously bad, at least historically speaking.
Personally, I don’t care much for the “peers of publishing review” to establish truth, I’d much rather read a convincing paper myself…but maybe I don’t understand what you are trying to say.
In an emergency decisions have to be taken. They will be taken for better or for worse. Grounds for diffidence there may be; but not knowing “the truth” may impress the peers of the publication circuit; but some approximation to “truth” — which indeed may turn out to be wrong — is going to be better than boasting that science takes no position at all until the needlework is done with. In actuality what happens — and this is *exactly* what has happened in the last xx months: when legitimate authority fails to exercise its prerogative, the pretenders overwhelm it, and in force!
I’m having a hard time understanding what you’re trying to say. It sounds like you’re saying that in an emergency, scientists should lie about how confident they are in their results?
In the past year there has been no shortage of “scientific advice” that turned out to be wrong.
Don’t paint your own daemons onto my shadow! All I am trying to say is that decisions will be made; good or bad; decisions *have* to be made, with the best information available at the time. That has nothing to do with “lying”. The discussion was about enforced social separation. I stupidly interjected the obvious: that the decision to keep people apart could not wait for the sophisticated study that “proves” a correlation between separation and a drop in the incidence rate. Like most of the others I haven’t anything really to contribute and it is as easy for me as for anyone else to play the armchair gumshoe.
>stupidly interjected the obvious: that the decision to keep people apart could not wait for the sophisticated study that “proves” a correlation between separation and a drop in the incidence rate.
Ah, it’s nice that we can agree that the sophisticated study is basically useless for the important questions of what we should actually do. However, this discussion is about the sophisticated study, not about what the “correct” policy on lockdowns is.
You also confuse “enforced social separation” with “mandated social separation”. That actually enforcing real social separation leads to less cases is probably true, but it’s less obvious that instituting complex laws about what people are allowed to meet how and where is as effective. Where I am, for example, one is only allowed to visit people at night if one also sleeps at the place on visits. Does this push people to visit for longer than they would otherwise? The answer is obviously “sometimes”, but could this lead to a net increase in social contact (my personal opinion: probably not, but these kinds of effects turn up everywhere).
But the cheaper and safer intervention of correcting vitamin and oxygen deficiencies, long known to lead to health problems, does require this because covid is a new thing? Basically, 100 years of accumulated knowledge might not apply in the new case for some reason, so we need a large RCT first.
I know you didnt say that, but that is what is going on.
> However, Sweden did not ban all public events, just those with over 500 people.
500 became 50 a couple of weeks later. It was never relaxed and was lowered to 8 last month.
https://en.wikipedia.org/wiki/COVID-19_pandemic_in_Sweden#Ban_on_gatherings
Flaxman et. al only consider the 500 people restriction for their analysis (see p.29 of the supplementary material of their original paper).
Note that 50 is still an order of magnitude larger than what was allowed in most places.
I was just correcting what seemed a factual mistake. I’ve not looked in much detail at the substance of the discussion, But, fwiw, I agree that the country-level analysis is problematic and I mentioned that when the paper was discussed here six months ago.
May be” entails “may not be”, so in effect it means “not certainly not.” Which is meaningful/informative, but not a lot. As in “we don’t know, more research funding is needed.”
Given how important this issue is, have you considered pausing some of your other work and jumping in to try to steelman (opposite of strawman) both sides and try to improve both sides’ arguments?
+10 !
Country, Rm:
You’re probably right that I should be doing that rather than responding to blog comments etc. That said, I have a feeling that if I did do something, it would end up looking something like what Flaxman et al. did. It’s not like I think what they did was perfect, but the things I do aren’t perfect either. But, sure, if I spent a bunch of time on it I guess I could help. I’ve corresponded with their team regarding the various questions and criticisms they’ve received, so maybe I can do more of that. Or maybe this blogging will encourage them to perform additional sensitivity analyses.
I know that I’m a bit late to this party, but in case someone is interested, I have written a reply to this post and Flaxman et al.’s response. I would have replied sooner, but I’m visiting my family and, to be honest, I already spent way too much time arguing about that stuff, so it was hard to find the motivation.
Why not ask to do a guest post here.
Philippe:
Thanks for the detailed reply. I don’t really know what you’re talking about regarding “scientific gaslighting”—I think it’s fine to just say we disagree and explore the disagreements without supposing that any psychological manipulation is going on—but I guess that doesn’t really matter. Regarding the specifics, at this point I think it will be best for Flaxman et al. to address your questions. In your linked post, you argue that the data from Sweden represent a serious model violation (“according to the prior they used for the country-specific effect, the probability that it would be that large was only ~0.025%”) and that their estimates are not scientifically plausible (“their model found that banning public events had reduced transmission by ~72.2% in Sweden, but only by ~1.6% everywhere else”). Regarding the latter point, I wonder if this is an artifact of the difficulty we’ve already discussed, that policies don’t happen in a vacuum. If Sweden wasn’t doing lockdowns and other countries were, then the effect of banning public events could be larger in Sweden than other countries, no? But there are a pieces here that I still don’t understand. If we go to the second panel of the figure in the above post (which is Figure 1 from Flaxman et al.’s response to Soltesz et al.), the effect of banning public events in Sweden is estimated at about 80%, it looks like (not 72.2% but I guess that came from a different analysis) and the Flaxman et al. estimate for all countries is right around 0 (maybe 1.6% or something like that). I’ve seen this sort of thing before, in my own work as well as others, that when a model gets complicated, it can be hard to understand how all its pieces fit together.
> If Sweden wasn’t doing lockdowns and other countries were, then the effect of banning public events could be larger in Sweden than other countries, no?
But that’s the point, isn’t it? Taking it to the extreme it’s obvious that if you’re locked at home lifting the ban on public events doesn’t change anything. And if you knew that banning public events is highly effective the marginal effect of doing or not a full lockdown would be small. The right conclusion wouldn’t be “lockdowns saved millions of lives” but “lockdowns and banning public events saved millions of lives and for all we know banning public events could have been enough”. (Again, this is for the sake of the argument, not something I’m putting forward.)
The reduction of ~72.2% is what I obtain when I take the fit of the partially pooled model they used in the Nature paper and add the country-specific effect of the last intervention in Sweden to the effect of banning public events. If I understand figure 1 in Flaxman et al.’s response to Soltesz et al. correctly, the effect of banning public events it shows for Sweden, which I think should be closer to 75% than 80% (I can’t check because I uploaded the results on Dropbox to save space on my hard drive and the Internet connection is extremely slow at my parents where I am right now, but that’s what I remember from when I fitted the model separately on each country for my original post a few weeks ago and eyeballing the chart), is what you get when you fit the model on Swedish data without any kind of pooling. It’s possible that Flaxman et al. obtained slightly different results because I think they ran more chains for more iterations than I did to sample the posterior distribution, I really had to push my poor laptop to fit their model, but presumably there is no real discrepancy here and indeed I was able to replicate all their results before as far as I can tell.
On the other point you make, I agree that, since Sweden didn’t lock down, it’s possible that banning public events was more effective in Sweden than elsewhere, though I don’t think a difference of that magnitude is plausible. In fact, I did acknowledge that possibility in both my original post and my reply to Flaxman et al.’s response, which is why I wrote this:
Even if we accept the causal story that lockdowns did almost all the work in every country where there was one, but that in Sweden the same work was done by the ban on public events, which again I do not (I think behavioral changes, which are hard to disentangle from interventions because presumably they are prompted in part by them, probably did a lot of work even before the lockdowns started even in countries where they were used), this point is still very important from the point of view of what policy implications we can draw from this analysis. Indeed, it means that we can’t infer from Flaxman et al.’s results that lockdowns are the only way to prevent the epidemic from getting out of control, which I think is the natural interpretation of their findings as they presented them and is the conclusion most people seem to have drawn from it.
Again, I have to fair with Flaxman et al. and not pretend they bear all the responsibility for that, the truth is that people were going to overinterpret their results no matter how careful they were in presenting them. But I do think that, even if they really think it’s plausible to take their results at face value, they should have explicitly noted that even if lockdowns did almost all the work in countries where they were implemented, the epidemic trajectory in Sweden suggests that even in the absence of lockdowns something else would have done a similar work, though perhaps somewhat less effectively.
Andrew, you wrote:
>If Sweden wasn’t doing lockdowns and other countries were, then the effect of banning public events could be larger in Sweden than other countries, no?
As far as I recall, the model by Flaxman et. al. rests on the assumption that interventions are instantaneously effective. Given that most countries banned public events before they locked down, this would mean that either:
(a) the “instantaneously effective” assumption on which the model rests is massively violated.
(b) citizens/the virus are prescient and don’t respond to public event bans because they know there’s a lockdown coming.
(c) governments are able to intuit the true case numbers – sometimes before they even show up in the ‘deaths’ statistics, see also link to supplementary material below – and therefore lock down because they already know the public events ban has failed to have had a strong effect.
(d) some other effect with a strong effect is going on that isn’t being modeled
None of (a)-(d) support the idea that Flaxman et. al’s model isn’t badly misspecified.
There’s also the issue of the raw data that they are using being wrong. Their supplementary material, available at https://static-content.springer.com/esm/art%3A10.1038%2Fs41586-020-2405-7/MediaObjects/41586_2020_2405_MOESM1_ESM.pdf has issues with *every* category they have for “Germany” on page 28.
– They state that school closures were “nationwide” from the 14th of March (a Saturday, so it’s completely unreasonable to assume that they would start having an effect then, in Baden-Württemberg pupils were still attending school on the following Monday.
– They state that public events were banned on the 22nd of March, but in Bavaria this was done from the 16th of March.
– They state that the “lockdown” occured (also) on the 22nd of March, but this varied from state to state if I remember correctly.
– Their “social distancing encouraged” date is just the date of some speech by Merkel, I’m pretty sure people were worried already before and ‘social distancing’ (at least I was).
– Their Case-based measures (allegedly from the 3rd of March, with “Advice for everyone experiencing symptoms to contact a health care agency to get tested and then self-isolate”) don’t seem accurate either, but they don’t give a real source for them so I can’t check what they’re referencing.
So it’s a little concerning that their data is riddled with inaccuracies for the only country where I’m familiar with the situation. Given that they try to pry apart effects of interventions that are closely spaced, I would assume that getting the timings of the interventions right would be really, really important here, otherwise we’re just in a “garbage in -> garbage out” situation…
Nathaniel:
Thanks for the detailed comments. I hope that Flaxman et al. can respond. My only comment here is that the Flaxman et al. are fitting a differential equation model, so even if policies have instantaneous effects, these are blurred over time before they reach the observed data. In addition, as we’ve discussed in various posts, all estimated effects of policies are just approximations because so much is driven by individual behavior. For example, here in the United States they were shutting down schools in some cases in response to many parents pulling their kids out of school. And I actually have no idea what our state and local rules are regarding masks. I see people out in the park jogging with masks on, which seems silly to me, but it just indicates how policies are only part of the story. I still think that studies such as that of Flaxman et al. can be valuable, as long as they are not overinterpreted. Another way of saying this is that people will do comparisons between countries and make statistical conclusions from such comparisons, whether formally or informally. Analyses such as those of the Imperial College team represent a way of performing such analyses systematically, and that’s an important role for applied statistics in policy analysis.
>> Another way of saying this is that people will do comparisons between countries and make statistical conclusions from such comparisons, whether formally or informally.
Is there not, though, a possible risk by *formal* statistical comparisons giving greater weight to the comparisons, if they are in fact not useful/valid?
I’m not necessarily saying this paper IS not useful/valid – I am unqualified to judge – but the “better than nothing” argument may not hold.
Confused:
Yes, I agree completely. Formal statistical analysis is not always good.
confused –
> Is there not, though, a possible risk by *formal* statistical comparisons giving greater weight to the comparisons, if they are in fact not useful/valid?
This kind of picks up on our discussion we were having on another thread (I’m about to respond there as well). What do you propose as an alternative? And it relates indirectly to a discussion that we’ve been having over a period of months. Personally, I look at this as a process of risk analysis, and in the end I weigh-in, in favor of hedging against the largest downside risks. But what do you suggest as an actual alternative. Again, I think there’s certainly nothing wrong with asking questions. But at some point “I’m just asking questions,” IMO, often, is more or less a ruse – it’s advocacy in a disguise.
> I’m not necessarily saying this paper IS not useful/valid – I am unqualified to judge – but the “better than nothing” argument may not hold.
What methods should we use to determine when/whether more information, particularly when provided by people who are seriously invested in developing expertise, is better than nothing or worse than nothing?
>>What do you propose as an alternative?
Alternative for whom?
For the actual scientists, IF* there is not enough/good enough data or the data is too hopelessly confounded to answer the question usefully, the alternative is to say “we don’t know”.
For the decision makers, that’s another question.
*Again, I am not saying the data IS this bad, as I am not qualified to judge.
>>Personally, I look at this as a process of risk analysis, and in the end I weigh-in, in favor of hedging against the largest downside risks.
Sure, but that’s a decision-maker “what policy to use” question not a scientist “what model/paper should I publish” question.
>> What methods should we use to determine when/whether more information, particularly when provided by people who are seriously invested in developing expertise, is better than nothing or worse than nothing?
Methods, in a formal sense, I have no idea. But in a time-crunch, high-stress, questionable-data situation like this I think the question should always be asked before publishing anything ‘formal’ or ‘authoritative-seeming’ – is the data *really* good enough to support models/conclusions that meaningfully increase our understanding? If not, it’s probably “worse than nothing” in that it adds support to something without real basis.
Now, one could argue that if it encourages more people to take the right actions it’s still better than nothing even if poorly based… but I think long-run that’s *really* destructive to science and to science being accepted by society.
confused –
I think we may be reaching the stage of arguing in circles…but I’ll give (not doing so) a shot.
> Alternative for whom?
>> For the actual scientists, IF* there is not enough/good enough data or the data is too hopelessly confounded to answer the question usefully, the alternative is to say “we don’t know”.
I agree that “we don’t know” is harder for people, scientists included, to say than it should be. And sure, there are institutional disincentives for saying “we don’t know.” But again, I think that you’re not dealing directly with the necessarily subjective nature of when that is the appropriate thing to say.
> Methods, in a formal sense, I have no idea. But in a time-crunch, high-stress, questionable-data situation like this I think the question should always be asked before publishing anything ‘formal’ or ‘authoritative-seeming’
“Authoritative seeming” isn’t only function of what the scientists write. Especially when the analysis explicitly includes an attempt to quantify uncertainty. And that question, isn’t really relevant to the tendency we’re seeing to elevate informal doubt-mongering over formal analysis.
> is the data *really* good enough to support models/conclusions that meaningfully increase our understanding? If not, it’s probably “worse than nothing” in that it adds support to something without real basis.
Whether it’s worth more or less than nothing isn’t a function of the formal analysis itself. OK, but I’m repeating myself.
>>I think we may be reaching the stage of arguing in circles…
Quite possibly.
>>And that question, isn’t really relevant to the tendency we’re seeing to elevate informal doubt-mongering over formal analysis.
I’m not sure increased use of “informal doubt-mongering” *in general public discourse* ought to change the standard for when an analysis is based upon good enough data *in scientific publishing*, though.
IMO we shouldn’t lower our standards because “someone else will be more wrong”.
>>Whether it’s worth more or less than nothing isn’t a function of the formal analysis itself.
Sure, and I didn’t mean to suggest that.
What I meant that if data is not good enough publishing a formal analysis can in some cases be “worse than nothing” because it implies a lesser degree of uncertainty than actually exists, both because many people will read a formally-published analysis as more ‘authoritative’ even if it includes plenty of caveats about uncertainty, and because in a bad-data situation there may well be unknown contributors to uncertainty.
COVID data *may* not be that bad, but until someone can plausibly explain the weird disparity between tropical America and tropical Africa/South Asia, I’m not convinced it isn’t.
Andrew: Thanks for tkaing the time to comment.
Regarding the technical points – sure, I hope Flaxman et al. will respond, I’m assuming they’re probably aware of this blog post and the fact that it has comments.
Regarding your other points about value of this kind of research:
>Analyses such as those of the Imperial College team represent a way of performing such analyses systematically, and that’s an important role for applied statistics in policy analysis.
Commenter “confused” has already made this point, but I don’t think he’s made it in sufficiently strong terms so I will.
I am sure you are mistaken here if we generalize your point of view also to other questions, and think you might be mistaken in this specific case too. Getting science™ to weigh in on questions where the data does not let you make a conclusion can be *actively harmful* as opposed to “an important role in policy analysis”. This is because in questions where the correct answer is “the data isn’t good enough to tell us anything”, I’d rather have a whole bunch of informal analyses that nobody takes seriously than a formal analysis that says “the data tells us X” that lots of people believe and gets published in Nature.
Note also that there is is nothing “systematic” about how this analysis was done – I don’t recall seeing any pre-registration of their model or a commitment for Nature to publish it “no matter what it shows”. Is their model “systematic” just because it is slightly more complicated than an informal analysis?
Nathanael,
I completely agree with your take on this. The fact that an analysis is attempting to answer very, very important questions does not excuse drawing conclusions not credibly supportable by the data used. In fact, I’d argue that the more important the question the higher the standards we should uphold.
I can’t escape that feeling that if a similar analysis and data had been published purporting to show that some specific government policy could “control” obesity or reduce poverty, Andrews and this blog’s would be eviscerating it as an example of hopeless overreach.
I just wanted to say that I completely agree with this point and that I think it’s very important. I tried to make that point at the end of my original post on Flaxman et al.’s paper, but I think Nathanael is making it better than I did.
Phillipe –
When you impugned and assigned motivations to Flaxman et al., were the data you used to make that determination “good enough” to draw your conclusion?
Joshua: Yes.
Phillipe –
> Joshua: Yes.
Well, given that you don’t need to present an “formal” analysis for that, I’d say you’ve created an unfalsifiable conclusion. We can always just assert that we’ve enough evidence to determine motivations.
My own rule of thumb is that to really assess motivations, I need first hand knowledge of that person. Beyond that, the first step is to interrogate my own motivations. To the extent someone can convince me of their ability to divine a 3rd party’s motivations, it helps if they explicate their process of assessing their own motivations.
The easiest person for you to fool is yourself.
Strictly speaking, nothing is falsifiable, claims about people’s mental states are no different from other types of claims in that respect. I’ve said everything I had to say on that issue, so if you still aren’t convinced by what I’ve already said, I doubt there is anything else I could say that would convince you.
Phillipe –
> Strictly speaking, nothing is falsifiable,
Well, I wasn’t really speaking strictly, but yes I guess that’s true.
> claims about people’s mental states are no different from other types of claims in that respect.
But see, that’s exactly my point. There is a difference, IMO, between claims about people’s mental states and claims about empirical analysis. And I think that blurring those lines of distinction is certainly sub-optimal.
So that’s why, when I see people unnecessarily accompanying an empirical form of analysis with confident assertions of an ability to divine mental states – particularly when it’s being done through such an indirect process as reverse engineering from a such a small window of observation (the process and results of a formal analysis) – I think that can be something to help ME to weigh the probabilities behind the associated empirical analysis.
Even looking beyond just the possibility that you’re wrong in your empirical analysis concluding that Flaxman et al. are wrong, you’ve even ruled out the obvious possibility of motivated reasoning on the part of Flaxman et al. as an explanation for their error (with the understanding that “motivated reasoning” is an unfortunate term in that it actually doesn’t speak to motivation).
If I can’t really follow the technical components of a debate, I look for people getting out over their skis in the ancillary aspects. That would apply to Flaxman et al. as well as to your. Of course, I understand that such a process is also sub-optimal, but sometimes it does help to inform me about probabilities.
> I’ve said everything I had to say on that issue, so if you still aren’t convinced by what I’ve already said, I doubt there is anything else I could say that would convince you.
Yeah, I doubt that’s true. You’ve not even come close to addressing fully how you divine motivations of other people by reverse engineering from their empirical process and conclusions. But even more, you haven’t shed any light into your own process of interrogating your own motivations.
You might not “convince” me if you engaged in such a process. There’s no guarantees about such stuff. But the again, you might convince me. Or, more likely, you might move me to re-evaluate the probabilities. Simply stamping your feet and arguing by assertion won’t work. And refusing to explain your own interrogation of your own motivations to divine motivations certainly won’t work.
Obviously, there’s no obligation on your part. I”m just a Internet troll. No reason why you should care what I think. But you might consider it just as an exercise for yourself. Or, it’s at least possible that you might shift the perspective of an observer.
Phillipe –
> claims about people’s mental states are no different from other types of claims in that respect.
Upon re-reading, perhaps I undervalued your qualifier of “in that respect.” Maybe that means that you aren’t saying that there’s not a different standard to apply when assessing the validity of someone’s empirical analysis as when assessing their mental state.
I certainly hope so.
Nathaniel –
> Getting science™ to weigh in on questions where the data does not let you make a conclusion can be *actively harmful* as opposed to “an important role in policy analysis”.
The problem here, IMO, is that this is an objective and binary frame for something that is subjective and non-binary
Assessing whether the data is sufficient to support a conclusion is subjective and often we see it being made, over and over, in ways that align with ideological orientation.
> This is because in questions where the correct answer is “the data isn’t good enough to tell us anything”, I’d rather have a whole bunch of informal analyses that nobody takes seriously than a formal analysis that says “the data tells us X” that lots of people believe and gets published in Nature.
You’re certainly entitled to your opinion, but if I had to choose just one mechanism I’d rather have the latter system – whereby people who are heavily invested in developing expertise go through a formal system of evaluation conduced by other people who are heavily invested in developing expertise – and present their analysis through such a fashion, than the former system. Of course, that latter system is far from a perfect system. It has risks and dangers. It’s a mistake to consider it foolproof or dispositive.
But the former system is certainly no more foolproof, IMO, and I’d argue likely more beset by risks and dangers. I look at it as a matter of risk management, and a process of hedging against the largest downside risks.
But of course, there’s no need to make a black and white choice. And what I’m finding increasingly disturbing is what I see as a kind of advocacy, on both sides, for framing the context as if it is a matter of choice. Everything gets reduced to a scorched earth, zero sum under an umbrella of scientific purity when what actually lurks underneath is an proxy battle involving identity-protective and identity-aggressive cognition.
> Note also that there is is nothing “systematic” about how this analysis was done – I don’t recall seeing any pre-registration of their model or a commitment for Nature to publish it “no matter what it shows”. Is their model “systematic” just because it is slightly more complicated than an informal analysis?
So is doing this kind of work in a systemic fashion something you’d consider to be a positive attribute? If so, then how would you assess that quality and how would you apply it to “informal analysis?” Or do you think that there’s no net benefit from being systematic as opposed to not systematic?
>But the former system is certainly no more foolproof, IMO
Really? In the former system, people have a more accurate state of the world (thinking “the data doesn’t tell us what is going on”) whereas in the latter people are mistaken (thinking “the data clearly says X”).
>and I’d argue likely more beset by risks and dangers.
This is a somewhat silly argument to have, but the “we make less mistakes because we believe in science™” has been plenty problematic historically. I’m not really able to assess whether “scientific intuition” is net positive or net negative. For more information on my “plenty problematic historically” comment, a nice book is Scott’s “Seeing Like a State”, a good review of which can be found on a number of blogs including on Slate Star Codex. Tangentially related is the replication crisis(es), this blog has a number of great posts in that vein. But at this point the conversation is becoming too philosophical for me and I don’t think this is the place for it.
> Everything gets reduced to a scorched earth, zero sum under an umbrella of scientific purity when what actually lurks underneath is an proxy battle involving identity-protective and identity-aggressive cognition.
I’d rather people asked for scientific purity more so I am ok with this.
>So is doing this kind of work in a systemic fashion something you’d consider to be a positive attribute?
Yes. Pre-registration makes it harder for researcher bias to affect results.
> If so, then how would you assess that quality and how would you apply it to “informal analysis?”
Very carefully. I mean these are hard questions that are really really going off on a tangent that I (frankly) have no interest on going off on any further.
Nathanael –
Don’t know if you’ll see this…
> Really? In the former system, people have a more accurate state of the world (thinking “the data doesn’t tell us what is going on”) whereas in the latter people are mistaken (thinking “the data clearly says X”).
This assumes a binary framing, which might only sometimes apply. Formal analyses include things like confidence intervals. That doesn’t imply that “the data clearly says X,” depending on what “X” is (i.e., is “X” a certain degree of likelihood of an effect?)
On the other hand, less “formal” analyses are (probably?) less likely to contain such an attempt to quantify uncertainty. Now of course, you can always take issue with the quantification of uncertainty. There’s potential for bias all the way down. I guess for me the probabilities are better if at least people are explicitly trying to do it, and being explicit about their process of doing so. No guarantees, but for me it’s a worthwhile gamble.
> This is a somewhat silly argument to have, but the “we make less mistakes because we believe in science™” has been plenty problematic historically.
I’m not interested in discussing your straw man.
> I’m not really able to assess whether “scientific intuition” is net positive or net negative.
See above.
> Tangentially related is the replication crisis(es),
Yeah, well improving research is certainly a worthwhile goal. And certainly broad and widespread problems exist. But that’s a long way off from determining whether “crisis” is really an apt term. Are the problems of research really increasing faster than the benefits? Seems to me that a “crisis” implies certainty of such. Are we worse off for having our research institutions, for all their shortcomings? I tend to think not.
>and I’d argue likely more beset by risks and dangers.
> I’d rather people asked for scientific purity more so I am ok with this.
I see people asking for scientific purity a lot. What I don’t see is people asking for scientific purity that control well for the bias that science they disagree with is by definition impure and science they agree with is necessarily pure.
> Yes. Pre-registration makes it harder for researcher bias to affect results.
You’ll see no arguments from me against pre-registration. In fact, I’m not aware that there are any.
> Very carefully. I mean these are hard questions that are really really going off on a tangent that I (frankly) have no interest on going off on any further.
Ok. Since you brought it up I figured you might….but thanks for the response…
Look at this one. They report 11/212 (5.2%) of covid patients died who had initial vitamin D levels above 20 ng/ml (not deficient, according to their cutoff).
Then 1/128 (0.8%) of those initially deficient that got 60,000 IU of vitamin D died, vs 3/69 (4.3%) of those who were initially deficient but *did not* get vitamin d.
They conclude:
https://www.researchsquare.com/article/rs-129238/v1
Just a cursory scan of the paper shows that you are grossly simplifying it.
Nope. They saw about 80% reduction in mortality and interpreted that as no sign of a benefit.
Anoneuoid, for what it’s worth, I’m giving my family vitamin D supplements mainly because of your posts.
I don’t think it’s clear that large doses have any positive effect, but I’m mostly sold on the idea that being deficient may severely compound negative effects, and I expect my pale north-western family of Netflix bingers have probably not seen any sunlight in months.
I actually think there is some issue with iron metabolism involved that depletes the vitamin c, then when thats gone all the other antioxidants start depleting.
The major role of vitamin c in your body is reducing Fe3+ to Fe2+, even as a cofactor for collagen formation that is what it does.
Something like this:
https://pubmed.ncbi.nlm.nih.gov/33298888/
Keith E, there are good reasons for taking vitamin D supplements in recommended amounts that have nothing to do with covid 19, much less Anoneuoid’s posts.
So if your family wasn’t taking vitamin D supplements before you read his posts, it is good that you are. But you could’ve simply read something like this and reached the same conclusion:
https://www.mayoclinic.org/drugs-supplements-vitamin-d/art-20363792#:~:text=The%20recommended%20daily%20amount%20of,for%20people%20over%2070%20years.
I’m taking vitamin D as well. Better safe than sorry thinking.
Still, FWIW, I’ve seen some stuff out there on the Interwebs that questions whether supplements work as opposed to being out in the sun.
Sigh, now I guess I’ll have to spend some time exposing your dishonest simplification of the result. Maybe I’ll find the time to do so over the next day or two. Or maybe someone else will be motivated to dig into it.
Or perhaps it’s just best to ignore you.
BTW you’re essentially accusing the authors of academic misconduct. If you have a case, perhaps you should make it to the journal and demand that the article be retracted.
Please do explain how 80% reduction in mortality after vitamin d supplementation (same as reported previously) is correctly interpreted as no sign of a benefit.
Thanks everyone for the lively discussion. Our work on the novel variant is now out, lots of it in Stan (of course). As others have mentioned, pre-publication peer review is great, so please send us any comments: https://www.imperial.ac.uk/mrc-global-infectious-disease-analysis/covid-19/report-42-sars-cov-2-variant/
Regarding the Nature paper and follow-ups, if anyone has statistical questions about our approach, we’re happy to try to answer them here. We’ve got a new preprint coming early in the new year comparing the first wave in the UK, Sweden, and Denmark, so keep your eyes out for that.
A few points that I wanted to highlight:
1) We’ve got a nice section in the Matters Arising response (https://www.nature.com/articles/s41586-020-3026-x) on checking that our model works as expected using a simulated data approach: we show that (1) if another intervention in our dataset had had a larger effect than lockdown, our model would’ve picked that up. And (2) that our model is robust to omitted variables (e.g. an intervention that we did not include as a covariate). But of course there’s much more to do, and thanks to our R package (https://github.com/ImperialCollegeLondon/epidemia/) it’s all pretty easy to setup. We welcome further testing, improvement, criticisms, and so on–since our package is based on rstanarm you can use it to draw from the prior, i.e. simulate epidemic trajectories, but something we haven’t had a chance to do much of yet is to use more standard simulators and then fit our model to those simulations. There’s also tons of data available out there on cases, deaths, governmental interventions, and mobility (the R package COVID19 is a good place to start) so if you want to try our approach in a new country, go for it. Let us know how things go on the issues page:
https://github.com/ImperialCollegeLondon/epidemia/issues
2) Subnational analyses are a great idea–that’s why after we did the
Europe report, we put out reports and papers on Italy (https://www.medrxiv.org/content/10.1101/2020.05.05.20089359v1), Brazil
(https://royalsocietypublishing.org/doi/full/10.1098/rsif.2020.0596?af=R & https://www.imperial.ac.uk/mrc-global-infectious-disease-analysis/covid-19/report-21-brazil/), and the United States (https://www.nature.com/articles/s41467-020-19652-6). And that’s of course why we have our UK website
(https://imperialcollegelondon.github.io/covid19local/). Technical details here: https://arxiv.org/abs/2012.00394
3) An explanation for those wondering about what appears to be a big effect of banning public events in Sweden. Our partial pooling approach (labeled “Flaxman et al” in Fig 1 and “Nature model” in Extended Data Fig 1 in https://www.nature.com/articles/s41586-020-3026-x) puts a country-specific effect on the day of the last intervention in our dataset. It’s not the same as the also useful “Partial pool” model which gives every intervention both an overall effect and a country-specific effect. As we write in our response:
“The main goal of our paper was to examine multiple countries to see what worked in most places, not to explain the trajectory of the epidemic in each individual country. Although we feel that Soltesz et al. raise an interesting point, we stand by our assessment that the effectiveness of NPIs can in principle be identified when looking at what worked in most countries, subject of course to the available data.”
With this goal in mind, if you use a full pooling approach (as we did originally for Imperial College Report 13) then you get a big effect for public events when Sweden is included, but not otherwise. This is not ideal—it suggests the model is very sensitive to a single country’s data. Possible remedies (“exit valves” as Andrew calls them) include: a country-specific effect on the day of the last intervention, random effects for each of the interventions, a random walk, or single country models followed by a meta analysis. We chose the first (and included single country models in the supplementals), but as we show all approaches other than full pooling give consistent results. And even with full pooling, we find that lockdown has a stronger effect than the other NPIs.
4) I would like to remind all of us that these debates, especially the ones focused on Sweden, take a very Eurocentric perspective. We focused on Europe because in the time period we started working, it was the epicentre of COVID-19, after China. But a year after this pandemic began, there are many countries whose example is worth studying, from Mongolia to Vietnam to Rwanda. Here are some articles to get started:
– https://www.bmj.com/content/371/bmj.m4720
– https://www.bmj.com/content/371/bmj.m4907
Thanks for the comment and the links.
Hi Seth, happy new year and thank you for being open to criticism here! I greatly respect the fact that you are doing so, thank you also for making the code to your Nature paper public. (This doesn’t seem to be the case for the newer paper you’re asking for pre-publication peer review for?)
That said, your points (1)-(4) really don’t address the main issues already brought up in these comments, which I’ll try to summarize below (links to original sources in brackets). I hope I am not being too direct with my formulations.
(a) You mention the huge country-specific effect for Sweden. Were you aware of this before publication? Do you think this is in any way plausible? If not – does this not suggest that your model is misspecified? You kind of mention Sweden in point (3) of your comment, but why write “this is not ideal” as opposed to “this shows our model cannot be trusted with important questions”? After all, if your model can only fit the Swedish data by assuming a hugely implausible country-specific effect there, this casts serious doubts on the ability of the model to fit any of the other countries accurately. (https://necpluribusimpar.net/lockdowns-science-and-voodoo-magic/, https://necpluribusimpar.net/reply-to-andrew-gelman-and-flaxman-et-al-on-the-effectiveness-of-non-pharmaceutical-interventions/)
(b) Your sentence “Our results show..” in the abstract seems misleading. Not only can your model not show causality, it is also a huge simplifaction of reality. Do you stand by your original formulation? (https://statmodeling.stat.columbia.edu/2020/12/18/inferring-the-effectiveness-of-government-interventions-against-covid-19/#comment-1621700)
(c) Your input data for Germany is not correct (https://statmodeling.stat.columbia.edu/2020/12/25/flaxman-et-al-respond-to-criticisms-of-their-estimates-of-effects-of-anti-coronavirus-policies/#comment-1627133).
To pre-empt variations of your “our model is robust to omitted variables” response – once your omitted variables (plural, but your linked analysis only includes a single omitted variable with an oddly specific prior) are not of the simplistic “instaneous effect” form that you consider, I expect everything to break down. What makes you think that an effect should be uniform and instaneous within a country? Something like a “fear of the pandemic” variable or even a “weather” variable will neither be uniform nor instaneous within a country. Philippe Lemoine’s blog post has a simulated epidemic where your model fails quite badly.
Sorry about the formatting in the above comment, I copy and pasted it from a text editor and it seems to have messed things up.
@Andrew: if you are reading this – is there any way to edit commits to insert some new lines?
@Seth Flaxman: “As others have mentioned, pre-publication peer review is great, so please send us any comments: https://www.imperial.ac.uk/mrc-global-infectious-disease-analysis/covid-19/report-42-sars-cov-2-variant/”
https://judithcurry.com/2020/12/29/the-relative-infectivity-of-the-new-uk-variant-of-sars-cov-2/#more-26827
From the second link: “The apparent rapid spread of this new variant might be due to founder effects”
How would that work?
Carlos –
IIRC, this video touches on that. If you watch, let me know what you think.
https://youtu.be/wC8ObD2W4Rk
It’s an interesting video, the scientist seems quite credible. The argument against reverse engineering from epidemiological data seems logical to me.
Still, the more this goes on the more I have to wonder.
Of possible interest – I and some colleagues published a Bayesian calibration of a more traditional extended-SEIR model for U.S. at the state level https://doi.org/10.1038/s41562-020-00969-7 using MCSim (software maintained by Frederic Bois, a common colleague of myself and Andrew).
However, we made our projections based changes in the latent/lumped parameters (e.g., relative change in contact rates, testing rates, etc.), and shied away from making direct predictions as what kinds of NPIs (lockdowns, masks) are needed because, at least in the U.S., compliance and effectiveness are highly heterogeneous in both space and time. I particularly think that the “same intervention” in different states (e.g., New York vs. North Dakota) and different times (e.g., last Spring vs. this Winter) will likely have very different impact on R0 (not just because of the new more transmissible variant). Thus, I’m no longer a fan of such prediction exercises, and favor an approach with better monitoring so that each jurisdiction can get more empirical data to decide when and whether to increase or relax interventions. Of course in the U.S. right now, it’s to total mess and out of control, and we don’t need any models to tell us that we all need to hunker down.