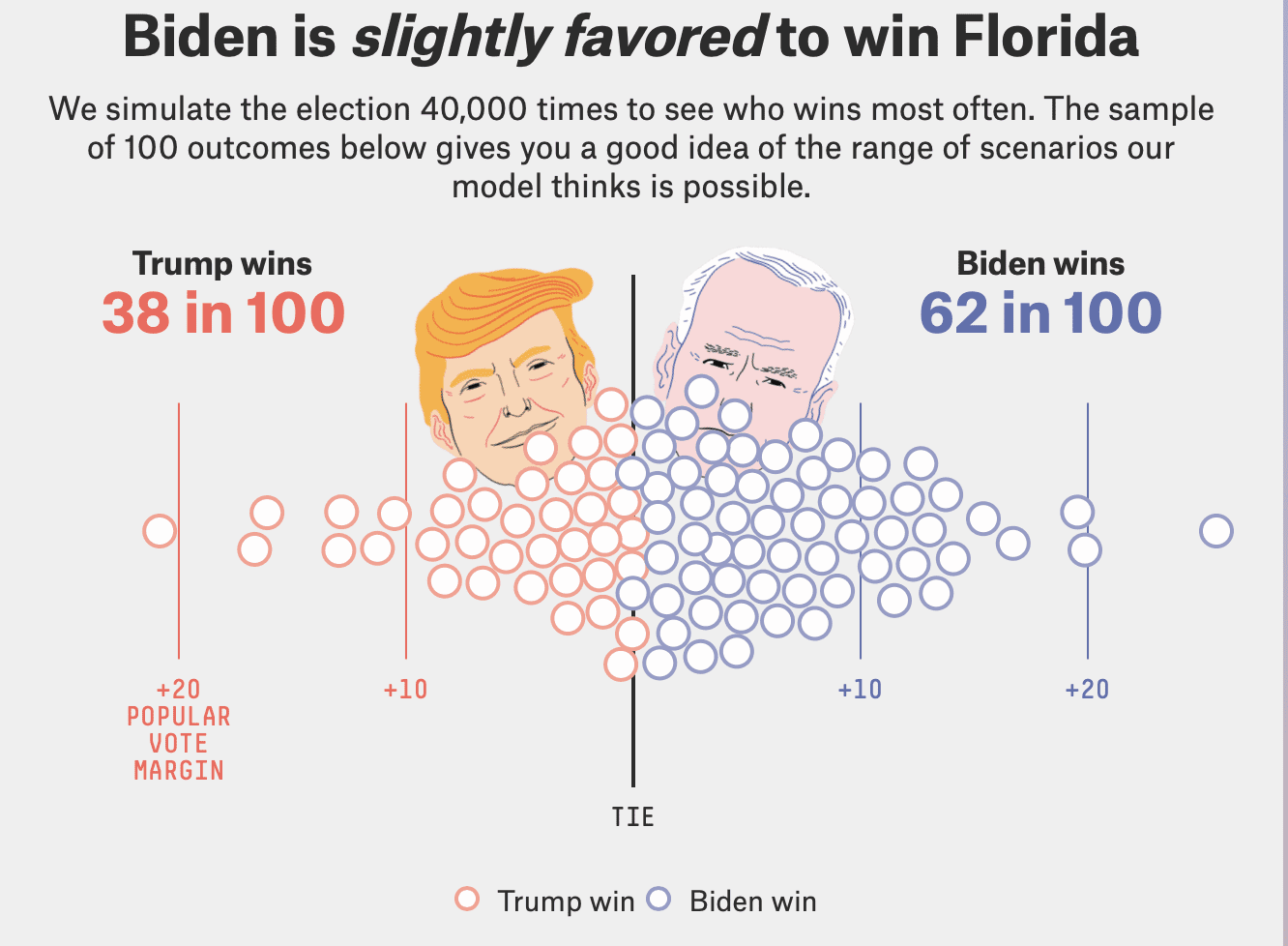
I’ve been chewing more on the above Florida forecast from Fivethirtyeight.
Their 95% interval for the election-day vote margin in Florida is something like [+16% Trump, +20% Biden], which corresponds to an approximate 95% interval of [42%, 60%] for Biden’s share of the two-party vote.
This is buggin me because it’s really hard for me to picture Biden only getting 42% of the vote in Florida.
By comparison, our Economist forecast gives a 95% interval of [47%, 58%] for Biden’s Florida vote share.
Is there really a serious chance that Biden gets only 42% of the vote in Florida?
Let’s look at this in a few ways:
1. Where did the Fivethirtyeight interval come from?
2. From 95% intervals to 50% intervals.
3. Using weird predictions to discover problems with your model.
4. Vote intentions vs. the ultimate official vote count.
1. Where did the Fivethirtyeight interval come from?
How did they get such a wide interval for Florida?
I think two things happened.
First, they made the national forecast wider. Biden has a clear lead in the polls and a lead in the fundamentals (poor economy and unpopular incumbent). Put that together and you give Biden a big lead in the forecast; for example, we give him a 90% chance of winning the electoral college. For understandable reasons, the Fivethirtyeight team didn’t think Biden’s chances of winning were so high. I disagree on this—I’ll stand by our forecast—but I can see where they’re coming from. After all, this is kind of a replay of 2016 when Trump did win the electoral college, also he has the advantages of incumbency, for all that’s worth. You can lower Biden’s win probability by lowering his expected vote—you can’t do much with the polls, but you can choose a fundamentals model that forecasts less than 54% for the challenger—and you can widen the interval. Part of what Fivethirtyeight did is widen their intervals, and when you widen the interval for the national vote, this will also widen your interval for individual states.
Second, I suspect they screwed up a bit in their model of correlation between states. I can’t be sure of this—I couldn’t find a full description of their forecasting method anywhere—but I’m guessing that the correlation of uncertainties between states is too low. Why do I say this? Because the lower the correlation between states, the more uncertainty you need for each individual state forecast to get a desired national uncertainty.
Also, setting up between-state uncertainties is tricky. I know this because Elliott, Merlin, and I struggled when setting up our own model, which indeed is a bit of a kluge when it comes to that bit.
Alternatively, you could argue that [42%, 60%] is just fine as a 95% interval for Biden’s Florida vote share—I’ll get back to that in a bit. But if you feel, as we do that this 42% is too low to be plausible, then the above two model features—an expanded national uncertainty and too-low between-state correlations—are one way that Fivethirtyeight could’ve ended up there.
2. From 95% intervals to 50% intervals.
95% intervals are hard to calibrate. If all is good with your modeling, your 95% intervals will be wrong only 1 time in 20. To put it another way, you’d expect only 50 such mispredicted state-level events in 80 years of national elections. So you might say that the interval for Florida should be super-wide. This doesn’t answer the question of how wide: should the lower bound of that interval be 47% (as we have it), or 42% (as per 538), or maybe 37%???—but it does tell us that it’s hard to think about such intervals.
It’s easier to think about 50% intervals, and, fortunately, we can read these off the above graphic too. The 50% prediction interval for Florida is roughly (+4% Trump, +8% Biden), i.e. (0.48, 0.54) for Biden’s two-party vote share.
Given that Biden’s currently at 52% in the polls in Florida (and at 55% in national polls, so it’s not like the Florida polls are some kind of fluke), I don’t really buy the (0.48, 0.54) interval.
To put it another way, I think there’s less than a 1-in-4 probability that Biden less than 48% of the two-party vote in Florida. This is not to say I think Biden is certain to win, just that I think the Fivethirtyeight interval is too wide. I already thought this about the 95% interval, and I think this about the 50% interval too.
That’s just my take (and the take of our statistical model). The Fivethirtyeight is under no obligation to spit out numbers that are consistent with my view of the race. I’m just explaining where I’m coming from.
In their defense, back in 2016, some of the polls were biased. Indeed, back in September of that year, the New York Times gave data from a Florida poll to Sam Corbett-Davies, David Rothschild, and me. We estimated Trump with a 1% lead in the state—even while the Times and three other pollsters (one Republican, one Democratic, and one nonpartisan) all pointed toward Clinton, giving her a lead of between 1 and 4 points.
In that case, we adjusted the raw poll data for party registration, the other pollsters didn’t, and that explains why they were off. If the current Florida polls are off in the same way, then that would explain the Fivethirtyeight forecast. But (a) I have no reason to think the current polls are off in this way, and one reason I have this assurance is that our model does allow for bias in polls that don’t adjust for partisanship of respondents, and (b) I don’t think Fivethirtyeight attempts this bias correction; it’s my impression that they take the state poll toplines as is. Again, I do think they widen their intervals, but I think that leads to unrealistic possibilities in their forecast distribution, which is how I led off this post.
3. Using weird predictions to discover problems with your model.
Weird predictions can be a good way of finding problems with your model. We discussed this in our post the other day: go here and scroll down to “Making predictions, seeing where they look implausible, and using this to improve our modeling.” As I wrote, it’s happened to me many times that I’ve fit a model that seemed reasonable, but then some of its predictions didn’t quite make sense, and I used this disconnect to motivate a careful look at the model, followed by a retooling.
Indeed, this happened to us just a month ago! It started when Nate Silver and others questioned the narrow forecast intervals of our election forecasting model—at the time, we were giving Biden a 99% chance of winning more than half the national vote. Actually, we’d been wrestling with this ourselves, but the outside criticism motivated us to go in and think more carefully about it. We looked at our model and found some bugs in the code! and some other places where the model could be improved. And we even did some work on our between-state covariance matrix.
We could tell when looking into this that the changes in our model would not have huge effects—of course they wouldn’t, given that we’d carefully tested our earlier model on 2008, 2012, and 2016—so we kept up our old model while we fixed up the new one, and then after about a week we were read and we released the improved model (go here and scroll down to “Updated August 5th, 2020”).
4. Vote intentions vs. the ultimate official vote count.
I was talking with someone about my doubts that a forecast that allowed Biden to get only 42% of the vote in Florida, and I got the following response:
Your model may be better than Nate’s in using historical and polling data. But historical and polling data don’t help you much when one of the parties has transformed into a cult of personality that will go the extra mile to suppress opposing votes.
I responded:
How does cult of personality get to Trump winning 58% of votes in Florida?
He responded:
Proposition: Vote-suppression act X is de-facto legal and constitutional as long as SCOTUS doesn’t enforce an injunction against act X.
This made me realize that in talking about the election, we should distinguish between two things:
1. Vote intentions. The total number of votes for each candidate, if everyone who wants to vote gets to vote and if all these votes are counted.
2. The official vote count. Whatever that is, after some people decide not to vote because the usual polling places are closed and the new polling places are too crowded, or because they planned to vote absentee but their ballots arrived too late (this happened to me on primary day this year!), or because they followed all the rules and voted absentee but then the post office didn’t postmark their votes, or because their ballot is ruled invalid for some reason, or whatever.
Both these vote counts matter. Vote intentions matter, and the official vote count matters. Indeed, if they differ by enough, we could have a constitutional crisis.
But here’s the point. Poll-aggregation procedures such as Fivethirtyeight’s and ours at the Economist are entirely forecasting vote intentions. Polls are vote intentions, and any validation of these models is based on past elections, where sure there have been some gaps between vote intentions and the official vote count (notably Florida in 2000), but nothing like what it would take to get a candidate’s vote share from, say, 47% down to 42%.
When Nate Silver says, “this year’s uncertainty is about average, which means that the historical accuracy of polls in past campaigns is a reasonably good guide to how accurate they are this year,” he’s talking about vote intentions, not about potential irregularities in the vote count.
If you want to model the possible effects of vote suppression, that can make sense—here’s Elliott Morris’s analysis, which I haven’t looked at in detail myself—but we should be clear that this is separate from, or in addition to, poll aggregation.
Summary
I think that [42%, 60%] is way too wide as a 95% interval for Biden’s share of the two-party vote in Florida, and I suspect that Fivethirtyeight ended up with this super-wide interval because they messed up with their correlation model.
A naive take on this might be that the super-wide interval could be plausible because maybe some huge percentage of mail-in ballots will be invalidated, but, if so, this isn’t in the Fivethirtyeight procedure (or in our Economist model), as these forecasts are based on poll aggregation and are validated based on past elections which have not had massive voting irregularities. If you’re concerned about problems with the vote count, this is maybe worth being concerned about, but it’s a completely separate issue from how to aggregate polls and fundamentals-based forecasts.
P.S. A correspondent pointed me to this summary of betting odds, which suggests that the bettors see the race as a 50/50 tossup. I’ve talked earlier about my skepticism regarding betting odds; still, 50/50 is a big difference between anything you’d expect from the polls or the economic and political fundamentals. I think a lot of this 50% for Trump is coming from some assessed probability of irregularities in vote counting. If the election is disputed, I have no idea how these betting services will decide who gets paid off.
Or you could disagree with me entirely and say that Trump has a legit chance at 58% of the two-party vote preference in Florida come election day. Then you’d have a different model than we have.

I strongly suspect Silver cooked the books. In 2016 his model was overresponsive to input-the probabilities would undergo wild swings from smallish events. Still, in retrospect, the model was useful in arguing that the election was more in play than pundits claimed, in particular in arguing that polls in similar states are strongly correlated, thus Trump’s chances merely rely on not enormous polling errors in a few states. Still-Silver like other prognosticators took public lumps for somehow “getting it wrong” (which is silly-there was nothing grossly “wrong” with the polls. People were just shocked by an outcome that went against their biases). This time around it almost seems like Nate went back to the model and said-“how can we bake even more uncertainty into things here?” so that, in the end, no one can accuse him of being wrong. To that end he might as well just fake a model that assigns 50-50 odds for all elections. Then he is always “right.” Probably the psychology of the betting markets as well. At least his model does not swing by 5 points based on a single poll anymore…:-).
Dave says “..he might as well just fake a model that assigns 50-50 odds for all elections. Then he is always “right.” ”
Yup, but skip the models and stat mumbo-jumbo — and look at the historical facts.
US presidential elections are always close (roughly 50-50) in past 200 years.
Total popular votes between Republican/Democrats over the long term are near equal.
Even the unusual 1964 LBJ “Landslide” win had LBJ withe just 61.1% of the popular vote — Johnson won the highest percentage of popular vote since year1820.
Leo:
You write, “US presidential elections are always close (roughly 50-50) in past 200 years.” This statement is mostly (if not entirely) correct when it comes to vote shares—even in 1924 when the Democratic candidate got destroyed, he still received 29% of the votes—but not when it comes to win probabilities. Expecting to get 55% of the vote will give you much more than a 55% chance of winning.
I’ve spoken to 538 employees, who said in the past Silver tweaked the data as the race wore on to match an outcome. Not sure the books are cooked so to speak but he’s bene open that he’s fitting models to his priors.
I also think they may have messed up between state correlations. Of course, you can never tell from just a few sim runs but from looking at some of their simulated outcomes, truly bizarre maps (e.g. Trump winning Oregon and Hawaii but losing a 300 EV landslide) seem to happen much more than most people would predict.
Hmm, yes, there’s some weirdness here.
Last time round Nate gave a choice of a Nowcast, and a Forecast. I guess he pulled it for being too confusing, but that would be useful I guess for seeing what exactly is going on here.
I wouldn’t accuse Nate of cooking the books to get an intended result. My guess is that there’s a contradiction between the polls and whatever fundamentals model he’s using and that creates uncertainty at this point in the campaign.
I usually skip these election forecast posts, but I today I feel compelled to ask: Is there any falsifiability to a claim that the lower bound of the confidence interval is 42% or 47%? How would I actually test which claim is right or wrong? Also given that one “can choose a fundamentals model,” which I find an amusing use of the word “fundamental,” the whole exercise strikes me as bizarre.
“How would I actually test which claim is right or wrong? Also given that one “can choose a fundamentals model,” which I find an amusing use of the word “fundamental,” the whole exercise strikes me as bizarre.”
I think this is the whole point-when I say cook the books-I mean that I think all of these models are so heavily reliant on what ingredients you want to include and how you include them, that they all reflect, in some way, your prior “feelings.” I suspect (but have no way of knowing) that Silver’s goal was safety.
Raghu:
1. Not much falsifiability here. As I wrote in item 3 of the above post, the point is that if some of the forecast predictions don’t make sense, this can motivate the Fivethirtyeight team to go back and look at their procedure more carefully. Our code had bugs and conceptual errors that we only fixed after our results were live and we noticed problems. So it doesn’t seem implausible to me that this could be happening to Fivethirtyeight as well.
2. “Fundamental” refers to the inputs to the model. Public opinion, incumbency, and economic performance are fundamental (in the view of political scientists) to the vote. There are lots of ways to include this information to create a prediction model.
A one time social event like this is not sensibly described by falsifiability because that requires repeated trials of a single process. Similarly, one can only “choose” the model in social science; there is no way to appeal to an ontologically real model like in physics. This is why the models here are all subjective Bayesian models.
I hate to reduce this conversation to a pissing contest, but when it comes to disagreements over a set predictions it seems like this is one of those rare opportunities where the thing that everyone wants to know is, indeed, who can piss the farthest. I appreciate posts like this that go into detail about why the two models generate different predictions, but the thing I really want to know after the election is: Which model produced the most accurate predictions?
Perhaps I can only speak for myself, but would you and Nate be willing to come to some sort of agreement about how the two sets of predictions can be compared after the election? Maybe set a deadline for submitting predictions for each state (or county or whatever) and decide on how exactly to quantify the accuracy of each set of predictions. I know that all the information needed for readers to do this kind of comparison is/will be available, but the reason I’d prefer you and Nate AGREE to a method for comparison is because you guys are the pros. I, as a reader, want to see how two professionals would make that comparison partly so I can learn about the best ways to make such comparisons and partly so I can have an “answer” that I can be sure wasn’t influenced by my own biases (e.g., choosing a comparison method that favors the modeler I like the most).
It’s definitely possible that the pissing contest is already mapped out somewhere and I missed it? If so, please let me know so I can follow along! If not, I’d absolutely love if you and Nate could arrange an adversarial collaboration.
*** Bonus points if you actually call it a “Pissing Contest” so that any journalists who report on it will be forced into adopting a playful attitude about the whole thing. They HATE not being taken seriously! ***
> Which model produced the most accurate predictions?
I would not be concerned with that until just before the election. Right now the real contest is who can make their models/analyses less wrong.
> Right now the real contest is who can make their models/analyses less wrong.
I don’t really care if accuracy is frames as “less wrong” or “more correct”. My point is just that when it comes to predictions, we actually have the ability to make objective comparisons and I’m asking Nate and Andrew to agree on how they will objectively assess the performance of their models after the election.
How could one possibly make post facto comparisons? First all of these models give odds which are based on the equivalent of running thousands of simulations. You can’t compare a single outcome to this in a meaningful way. When the likely outcome of a result that fits near the mean of BOTH models occurs (albeit with Silver’s model with a wider distribution of outcomes), who is the “winner”?
> How could one possibly make post facto comparisons?
Easy. You say “I think X, Y, and Z will happen by this date” and then you wait until the date passes. Then you look at whether X, Y, and Z happened.
> You can’t compare a single outcome to this in a meaningful way.
Perhaps, but that’s why I suggested comparing SETS of predictions, like at the state or county level.
> When the likely outcome of a result that fits near the mean of BOTH models occurs (albeit with Silver’s model with a wider distribution of outcomes), who is the “winner”?
This is why I think it would be interesting to see what Nate and Andrew come up with. If Nate and Andrew decided to use intervals for their predictions, riskier predictions (i.e., models with narrower intervals) would get a higher boost in performance scores for correct predictions and a larger penalty for getting incorrect predictions. Likewise, predictions with wide intervals (i.e., “safe” predictions) would get smaller rewards for being correct, but a smaller penalty for getting it wrong as well. There’s an entire literature on quantifying model performance in this way.
> I suggested comparing SETS of predictions, like at the state or county level.
Outcomes at the state or county level are not independent events so you still can’t compare sets of them to predictions in a meaningful way.
I don’t know think the non-independence of state/county-level outcomes precludes meaningful comparison. I’ll personally defer to Andrew on this one assuming he reads these comments.
Carlos, How would lack of independence prevent calculating Breir scores for the Economist and 538 electoral college predictions, then comparing the Breir scores to determine which prediction was better?
The “right” way to say who’s the winner in my opinion is to use surprisal, that is -log(p_i(x)) for x the actual outcome and p_i(x) the probability density of that outcome for the prediction on day i.
Post election, plot the surprisal as a function of time by plugging in the real vote tally into the historical predictions. You could then either use perhaps the minimum daily averaged surprisal as a measure of the goodness of the predictions.
Hi Daniel,
When writing the original comment it occurred to me that there would be a full range of possible comparisons. I’m generally a fan of outcomes that are as simple as possible so people without any background in stats or probability can understand. For example, a simple count of the number of correct binary predictions for all states would ensure maximum interpretability, but (of course) that would come at the cost of failing to consider nuanced differences like differences in the levels of confidence associated with each prediction. I’m not opposed to something a bit more sophisticated like you recommend, but it would narrow the range of people who could understand the results quite a bit. Just something I’d personally like to be considered if a “contest” like this were to take place in view of the public.
I think you can describe the thing you’re plotting as “a measure of how surprising the real outcome was according to the predictions from the given day”…
What makes a prediction bad is that what actually happens is nothing like what was predicted. surprisal has that behavior… things that are very unlikely have very small probability density and therefore large -log(p).
Really, the purpose of a Bayesian model is not to make 5% probability predictions come true 5% of the time (ie. to be “calibrated”) The purpose of a Bayesian model is to make the thing that actually happens be one of the things that had high probability density associated with it so that it’s one of the things you’d predict would happen using just the model.
If I predict normal(0,1) for some outcome and I see x=13 it’s VERY surprising (surprisal = 85). If I predict normal(0,10) it’s not very surprising (surprisal = 4). If I predict normal(15,2) it’s even less surprising (surprisal=2). If I predict normal(13,.1) even less still (-1.4)
Yes I agree that we can leverage people’s intuitions to make a relatively complex evaluation more easily interpreted. Furthermore, I don’t really think that the best way to compare each set of predictions is to reduce everything to a set of 50 binary predictions. I’m just saying that such an approach has the benefit of being the single easiest outcome to calculate and interpret. I completely agree that the strengths of more sophisticated approaches are well worth their use, but I think we need to remember that Nate and Andrew (and their colleagues) would need to come to an agreement about how their models should be compared. By placing a premium on simpler methods for comparison, it reduces the chance that parties get stuck quibbling over details while also increasing the chances that spectators have a concrete answer to which model performed “best”.
But Daniel the study design still has sample size one. As David Spiegelhalter once put it, in a prediction contest you can always lose to the tortoise (prediction of the outcome of a soccer championship game).
In the vast majority of Bayesian analyses the sample size is 1 (vector of observations). Relatively few things are repeatable in any reasonable way.
The key is to have a notion of goodness of a prediction that doesn’t rely on a frequency notion. Surprisal is such a measure. It’s a measure of whether your prediction does or doesn’t give credibility to the actual outcome.
At the end of the election we’ll know say the vote count rounded to the nearest percentage in each state. We can plug that into the predictions from today, and find out what the negative log probability for those vote counts was. That will tell us “how surprising” such a result was to the model. If the result was highly surprising to the model, then the model did a poor job predicting the outcome. If the result was not that surprising to the model, then it did a good job. If the result was not at all surprising then it did an excellent job.
This is an information measure: how much does the predictive distribution tell you about the real world? There is no notion of repetition or frequency = probability required here.
Andrew keeps providing thoughtful and respectful analyses of the differences between his team’s model and Nate’s model. Nate hasn’t done this yet (except for some yelling on Twitter, which isn’t the place for thoughtful analyses). I’m disappointed in Nate. I’ve stopped following him closely. I much prefer following Andrew on this blog and via his talks. I believe the ball is in Nate’s court…
I too have noticed Nate’s failure to meaningfully engage on this. Its a shame because I’ve tended to use him as an example of how expert predictive modeling can be done well, but his behavior on Twitter is reliably uninspiring. I’ve also stopped following him.
Jordan:
I’ve conjectured that Nate is in the same situation as David Brooks and Paul Krugman, that he gets so much flak from ignorant people who just want to argue with him about politics, that he got into the habit of treating all criticism as if it’s not worth bothering with. It’s the attitude that criticism is nothing put a public relations problem, not an opportunity for learning. He also seems committed to keeping his method a secret. It’s really too bad.
Long twitter thread from Nate pretty clearly in response to this blog post, today: https://twitter.com/NateSilver538/status/1300825856072454145?s=20. Among other things, he says “In one sim, for example, the model might randomly draw a map where Biden underperforms its projections with college-educated voters but over-performs with Hispanics. In that case, might win AZ but not VA.”
Not sure to what extent that clarifies things…
Ben:
I don’t think that Nate is responding to me in that thread. If he were responding to me, I assume he’d link to what I wrote on the topic. He’s probably just responding to people on twitter.
In any case, see P.P.S. above for links to my response to that thread from Nate.
Regarding Biden winning Arizona but not Virginia: Sure, that could happen. But Trump winning New Jersey and losing the other 49 states: I don’t think so.
He’s responding to you.
Anon:
It could be that he’s replying to us. I can’t really say. I find it annoying when people debate without acknowledging what or who they are debating with, so as a starting point I’ll take people at their word. If Nate only refers to nameless people, I’ll assume he’s responding to various things that people have sent him, not any particular argument. If he’d like to engage with us directly, that would be great.
“…or because they planned to vote absentee but their ballots arrived too late (this happened to me on primary day this year!), or because they followed all the rules and voted absentee but then the post office didn’t postmark their votes, or because their ballot is ruled invalid for some reason…Both these vote counts matter. Vote intentions matter, and the official vote count matters. Indeed, if they differ by enough, we could have a constitutional crisis.”
I haven’t seen any posts from you on universal mail-in ballots (which is different than absentee ballots), local administration of ballots, and the timeline for counting ballots prior to Electoral College certification. That could be an interesting post if you have any particular expertise in the mechanics of election administration.
Given the surge in mail-in ballots, i.e., not an epsilon increase, extrapolating the prevalence of issues you raised is not trivial. Obtaining predictive intervals and putting them in context (i.e., would they switch the election outcome? Is the number just too big for people to be confident in the election?) would be a service.
Elliott Morris’s Economist article is behind a paywall, but the title just mentions recounts. I consider suppression to be malicious, whereas failure to count ballots can just be incompetence. I doubt NY was out to get Andrew when it mailed him his ballot too late.
Tom:
I don’t know if suppression has to malicious, and it certainly didn’t have to be individually targeted. NY State did not consider it a high priority to get people their ballots on time. I consider this a form of vote suppression in that they’re making it unnecessarily difficult to vote.
Andrew-
While I believe you sincere, the linked article and statement is in response to this exchange:
“But historical and polling data don’t help you much when one of the parties has transformed into a cult of personality that will go the extra mile to suppress opposing votes.
I responded: How does cult of personality get to Trump winning 58% of votes in Florida?
He responded: Proposition: Vote-suppression act X is de-facto legal and constitutional as long as SCOTUS doesn’t enforce an injunction against act X.”
That is clearly malicious and you do not provide any indication of your preferred formulation.
Tom:
I agree that looking at potential effects of mail-in ballots etc. is worth doing. It’s not something I’m working on, but Elliott Morris has looked into it and others have too.
Under what sort of scenarios does this election get so far beyond any past experience (going back say 100 years) that the principled response is to say no meaningful model can be computed?
Let’s say two weeks before the election we are under martial law with national guard troops in the streets enforcing a strict lockdown, the post office is completely shut down, the rate of infections and death per day from COVID is three times what it is today and the president declares that the election will be postponed indefinitely. Would Andrew and his associates and Nate Silver still be trying to formulate probabilistic models for Trump vs. Biden?
If not, how close is the current situation to the point where we conclude, “No model based on past elections is remotely believable”?
I don’t think the current situation is really all that unprecedented… it’s just that the precedents are long enough ago that most of us don’t remember them.
I am not sure the current political instability is as severe as that of the late 60s (and there was a pandemic in 1968-9 too, although the response to it was vastly different and much less dramatic). And the 1918-19 pandemic was *far* worse than this, and attended by much greater chaos (World War I) … though technically that’s a bit over 100 years ago.
I wasn’t meaning the pandemic as the unprecedented element but rather the pandemic as the trigger/pretext for precipitating a constitutional or legitimacy crisis. What I was trying to get at was, how close do we have to get to people literally being prevented from voting before the modelers through up their hands and say the outcome can not be modeled?
I mean, imagine the election actually does not take place in November as scheduled. Or it takes place but a sizable fraction (20% ?) of voters are disenfranchised. Surely then it would not make sense to apply public opinion polls and past voting patterns to predict the outcome.
Perhaps I’m wrong in assuming the modelers would give up in that sort of scenario. But assuming they would, how would be identify a slightly less dire scenario that, none the less, invalidates the predictive power of past voting and polling records?
“Perhaps I’m wrong in assuming the modelers would give up in that sort of scenario. ”
The models presume a fair election, where all voters can – and do – express their intent. If 20% of voters are disenfranchised, it’s not a fair election. But I don’t think it would take 20% or even close. Disenfranchising enough voters to shift one significant state could change the outcome of the election.
IMO any election in US history for sure is a basis for modern models, provided it was fair as defined above.
I suppose what I was really saying is that I think possibilities like the election not taking place in November, or 20% of voters who attempted to vote not being able to, are incredibly unlikely even given current conditions, and thus probably not major sources of uncertainty compared to other possible ‘surprise’ events.
I tend to think the current US governmental system is far more robust/hard to mess with in genuinely impactful ways than most people give it credit for… far more so than it was in, say, FDR’s time. (Which has both good and bad sides, as positive change is also extremely difficult and slow.)
Andrew –
> I think a lot of this 50% for Trump is coming from some assessed probability of irregularities in vote counting.
I think there’s another important faxtor…the betting markets set odds largely as a result of public opinion – not simply because of how the odds-setters view the probabilities.
I assume it’s like sports betting – where the odds move in association with the numbers of how many are betting on the various outcomes.
My understanding is that the betting markets have it more even because of a widespread belief in the hidden Trump voter and that the polling is wrong (because people perceive that the polling was wrong in 2016>.
https://www.cnn.com/2020/08/30/politics/trump-polling-analysis/index.html
> 95% intervals are hard to calibrate. If all is good with your modeling, your 95% intervals will be wrong only 1 time in 20. To put it another way, you’d expect only 50 such mispredicted state-level events in 80 years of national elections
This is where I can’t quite follow (i.e. I don’t find 538’s prediction all that weird).
I just don’t see “50 such mispredicted state-level events in 80 years of national elections” as the right way to frame it. “State-level” outliers are obviously not independent (as you repeatedly cite throughout this post, and your model). So I don’t find the “50” number very reasonable as a heuristic. My intuition would be that much of the weight of the outlier to fall on these “national-level events”, if that makes sense. In which case, we’re not looking at 50 in the last 80 years… we’re looking at an insufficient sample to draw any sort of inference about tail risk, and all you can do is guess.
In these modeling debates, which I find quite informative, I do wish people would be a bit more clear about how they’re handling these sorts of true outliers. When I see the wide intervals for individual states with 538, they just seem like a fairly natural way of describing the numerous weird tail risks that are inherent to elections. What if Biden has a heart attack? What if there’s a major terrorist attack on American soil? What if Biden walks into an unprecedented scandal? These aren’t *so* critical if you want to debate whether Biden is at 72% or 78% to win an election… but they are absolutely central to any discussion of the 95% intervals for Biden’s Florida count!
So at my first glance, the difference seems pretty intuitive, and not particularly confusing. Nate Silver is accustomed to building calibrated models for a wide range of phenomena. If that’s your job, I think it’s natural to get in the habit of assuming a decent amount of tail risks, because we’re so absurdly bad at actually capturing all of that naturally. So 538’s forecasts across a range of disciplines tend to have those wide tails. And sure enough, random nonsense happens every once and a while, and at my best approximation it seems to be a pretty decent hedge.
But I just fundamentally don’t see 42% of Florida’s vote to be *that* bold a 5% outlier prediction. I see this largely as a national-level prediction, in which case we’re talking a level of outlier that would only happen once a century or so… and if you look at the last century of our history, there are so many crazy things that happened that could have feasibly lead to that sort of unprecedented blowout. I think arguments about correlating state level polling error are *vital* when it comes to those median predictions, and saying whether Biden is 70% or 85%. But I don’t think that’s nearly as relevant when it comes to the 5% outliers, which I again see more about a prediction of the truly unprecedented (health issue, major scandal, shocking foreign policy update, etc).
Dylen:
I agree with your general point about 95% intervals including unlikely events. I just don’t quite believe the 42% number. I dunno. Political polarization . . . unpopularity of the incumbent . . . I see 47% as a more reasonable lower 95% bound for Biden’s two-party vote share in Florida. Even if Biden gets a heart attack and a scandal, it’s hard for me to picture all those Democrats deciding to vote for Trump.
But, yeah, all we can do is guess. What I’m really trying to do with this discussion of the 42% number is get some insight into the Fivethirtyeight forecast. If they want to make that particular prediction, going into it with their eyes open, that’s fine. If it’s an unfortunate byproduct of other modeling choices, that’s another story.
Isn’t it conventional wisdom that if Biden “gets a heart attack and a scandal” a bunch of Democrats will stay home. Not so much vote for Trump.
I wonder which way that’s coded in the various models. I’d think the underlying “fundamentals” would include having a lot of party loyalists on both sides whose choice is show up vs. don’t show up rather than vote their party versus switching to the other party.
Brent:
We’re only modeling two-party vote, not turnout, so I agree this could be an issue. I can’t see it taking Biden down to 42% of the two-party vote, though.
Yes, I suppose that would require a ton of Democrats staying home in order for the Biden share to go that low.
Great analysis and hoping to see more of this. I have a similar view about a seeming divergence in Nate’s probability for PA for Biden vs his probability for Biden to overall. A few days ago, at least, he had Biden winning PA, the tipping point state, about 75% but Presidential odds at 73%.
Given Biden also led in states beyond the tipping point, I couldn’t understand how his national win probability could be lower than his tipping point state probability. My suspicion, as a purely naive outsider looking in, is it might indicate a divergence in how he aggregates state level odds into national level odds. I wonder if the Economist model’s underlying state assumptions tie back closely the national implications.
Given the many modelling choices you have to make, which are legitimately very difficult to evaluate, as Andrew’s post demonstrates, I can’t help but consider wonder about what incentives other than getting it scientifically right these media outlets might have, and the extent to which they affect their modelling. Especially if they are the “incumbent” election modeller. Here’s what comes to mind:
– Non-negligible changes in win probability to new polls is good: That’s news you can write articles about and tweet about.
– But too much volatility is bad: It’s very good content to be able to scold pundits and other non-modeller journalists for overreacting to a poll or economic data.
– Disagreements with the betting odds are good: They’re competitors and people might question the value of the model if it just always coincides with the odds (even though they would add a lot of value still for anyone wanting to really understand how the prediction comes about, but that’s probably a tiny minority of readers)
– A ~70% probability for whoever is the favourite according to everyone is pretty good reputation risk management with respect to a mildly but not overly sophisticated target audience . If the favourite wins, you got it right and you can claim you got the uncertainty right. If the favourite loses, it was a somewhat surprising event for which you can claim you got the uncertainty right.
I think this is an important point. I think 538 tends to do a fairly good job at their primary task (well calibrated forecasts that offer some consistent insight), and you can see exactly how good or not that job is based on their track record, and decide for yourself.
But I do agree that the incentives they face for the presidential election are quite different. When it comes to large samples like individual House races, 538’s only incentives are just to try and get reasonable calibration and discrimination over a large sample, and take whatever modeling choices get them there. When it comes to the all important election forecast, their incentives seem quite different. Given that there will *never* be a large enough sample for falsifiable results (all you can do is just look at the modeling choices, and evaluate them on the merits), it seems like 538 has pretty strong incentives to give conservative forecasts, and rarely go above 70-80%. Because they don’t really get that much more credit for a 95% vs 70% prediction with the public, but “getting it wrong” gets them a lot of flak.
The only reason that I don’t think this is a big deal, is because I think 538 has a pretty standard approach they take regardless of task. My bet is that they’re more conservative with presidential forecasts than others… but by and large, they have an approach they take to each new problem, and it’s no coincidence it tends to be conservative (conservative approaches tend to be rewarded when you’re forecasting on many diverse domains, because such weird stuff happens). So I think it’s a very good point that 538 has warped incentives compared to some pure objective academic modeler… but I also don’t see anything in their model that stands OUT to me relative to their usual approach. So even if the incentives are different, they’re still the same people applying their same set of skills to the problem (that they apply in every other case, where the incentives are different). But still an interesting point.
“of course they wouldn’t, given that we’d carefully tested our earlier model on 2008, 2012, and 2016”
It’d be interesting to see the results from running the model on earlier elections. For example, what did your model predict Hillary Clinton’s win probability was around this time in 2016? What about the day before the election? What about after the Comey letter?
Is this available somewhere?
I’m sure many will agree when I say humans are not well-equipped to think about extreme probability events.
What are the odds that Trump announces a COVID vaccine/cure, employment numbers reportedly continue to improve, and some police gets shot by protesters with accompanying video?
Would you take over/under on 2.5%?
Of course, just the combination of those events are probably not enough to bring Biden vote share all the way down to 42% in Florida, but lower than 47% seems certainly plausible.
It looks like Nate has (obliquely) responded to you on Twitter. Here’s the copypasta:
“So, every time we run our presidential model, we show 100 maps on our interactive. The maps are randomly selected, more or less, out of the 40,000 simulations we conduct with each model run. People really like looking at these but they can sometimes yield misconceptions.
If you look through these, you can usually find a few maps that look *pretty* weird (say, Biden winning GA but losing FL) and maybe 1 or 2 that look *really* weird.
This is how the model is supposed to work accounting for a small chance of fat-tailed errors.
But it’s important to keep in mind that if we happen to show a given map out of the sample of 100 the program randomly selects, that doesn’t mean it has a 1 in 100 chance of occurring. The odds of that *exact* scenario might be 1 in 10,000 or 1 in a million, etc.
*Collectively*, the long tail of very weird 1-in-1,000 and 1-in-10,000 scenarios might have a 1-5% chance of occurring, or something on that order, depending on what your threshold is for “very weird”, so a few of them will come up when we show a batch of 100 maps.
There is a long discussion about how we generate these maps in our methodology guide. Our model assumes that the majority of the error (something like 75%, although the amount varies over time) is correlated across states rather than applying to any one state individually.
This includes the possibility of clustered errors, where errors are based on demographic, political or geographical relationships between the states, or errors related to mail voting and COVID-19 prevalence.
In one sim, for example, the model might randomly draw a map where Biden underperforms its projections with college-educated voters but over-performs with Hispanics. In that case, might win AZ but not VA.
Or, if Biden happens to win MO in one simulation, he’ll often win KS too.
We spend a lot of time setting up these mechanics. It’s a hard problem. It’s tricky because it’s hard to distinguish say a 1-in-1,000 chance from a 1-in-100,000 chance given the paucity of data in presidential elections.
But we want our projections to reflect real-world uncertainties as much as possible, including model specification error. There are many gray areas here, and there are certain contingencies we don’t account for (e.g. widespread election tampering) but that is the general idea.
If you’re backtesting, you can make highly precise state-by-state predictions (using some combination of polls and priors) in most recent elections (2004, 2008, 2012) but these wouldn’t have been especially good in 2016 and many years before 2000 produce big surprises.
(I don’t want to overly harp on 2016, but it’s not unconcerning. If you think there’s a secular trend toward polls/forecasts being more accurate, then 2016 being quite a bit less accurate than 2004/08/12, especially for state-by-state forecasts, is problematic.)
I’m sure their authors would disagree, but we think some other models are closer to *conditional* predictions. IF certain assumptions about partisanship, how voters respond to economic conditions, etc., hold, then maybe then Biden has a 90% chance of winning instead our ~70%.
These assumptions are *highly plausible*, but they are a long way from *proven*. It is easy to forget how little data we have to work with, including only a handful of presidential elections for which we have particularly robust state polling data.
Further, the map from 2000-2016 was unusually stable by historical standards. There have been SOME shifts (Ohio getting redder, Missouri getting bluer) but these are small in comparison to how much the map would typically change over 16 years.
When will the next major “realignment” be? Probably not this year. But, maybe! Or there could be some one-off weirdness caused by the economy, by COVID-19, or by an abrupt increase in mail voting.
So again, there’s a balancing act here, but we think it’s appropriate to make fairly conservative choices *especially* when it comes to the tails of your distributions. Historically this has led 538 to well-calibrated forecasts (our 20%s really mean 20%).”
Dalton:
Yes, I replied on the other thread.
I don’t know that Nate is responding to me, though. If he were responding to me, I assume he’d link to what I wrote on the topic. He’s probably just responding to people on twitter.
To add two more things:
1. It’s fine to talk about major realignment (“Probably not this year. But, maybe!”), but, again, I can’t see how this leads to Trump winning NJ and losing the other 49 states. That prediction seems like an artifact of the model, not something that should really be there.
2. Nate’s talk of being “conservative” reminds me that there’s no general way of being conservative when it comes to probability statements. We’re familiar with this from Bayesian inference: a uniform prior might seem conservative, but it assigns infinite mass to unrealistically high values of the parameter. Nate’s bumping up against this when he simultaneously is describing his forecast as conservative and calibrated. The essence of being conservative (for example, saying that Biden has a reasonable chance at getting only 42% of the two-party vote in Florida) is that you’re giving up some calibration.
In any case, my main concern is not with that New Jersey map as nobody’s gonna take it seriously; my real concern is that the various bits of Nate’s forecasting model are inducing low correlation which in turn has required him to make very wide intervals for individual states in order to get the wide national uncertainty that he wants.
Ultimately, none of this is a huge deal: as I wrote awhile ago, the difference between the Fivethirtyeight forecast and our forecast corresponds to vote forecasts and associated uncertainties that are actually pretty close.
In that sense, neither what we are doing or what Nate is doing is necessary: It would be enough to look at the RCP or Huffpost aggregator, see that Biden’s leading, and go from there. But to the extent that we want to add value by adjusting for polling problems, accounting for discrepancies between state and national polls, etc., then the between-state correlation is going to matter.
I certainly would not say that Elliott, Merlin, and I have got it right, and there could well be good features in Nate’s procedure that are not in our model. I just think Nate and his colleagues could do better by looking seriously at the problems with their forecast and using this to fix some of the problems in their method.
The problem is Nate’s model doesn’t seem to have that much larger of a range for the individual states than for the national popular vote. Yesterday the 80% confidence interval nationwide for Trump’s share of the vote (all of it not two party) went from 42.1%-50.8% while his range in Michigan went from 41.3%-51.2%.
More on “conservatism”: Someone pointed me to this page of calibration plots from Fivethirtyeight. The page shows that the predictions are well calibrated for sports, but that they’re consistently slightly underconfident for politics: when the predicted probability is 80%, the actual frequency is 88%, etc. On that page, they say, “things we say will happen only rarely … tend to happen only rarely”—which is consistent with a goal of underconfident predictions.
Indeed it seems that underconfident is a goal here–just look at the language 538 uses! Right now their model has Biden with a 68% chance of winning–and this is termed this “slightly favored”! Not sure in what universe a 2:1 favorite is a slight favorite…
“Not sure in what universe a 2:1 favorite is a slight favorite…”
That could happen in a world where modelers were blamed for the overconfidence that “caused” Trump’s victory in 2016. Or in a world where they might feel guilty about the possibility that they contributed to Trump’s victory.
Jim, yes I agree–I think the sociology of feeling that way is coming into play in their language. If Biden’s chances move upwards in their model, I will be interested to see when the “slightly” goes away and what the next modifier of “favored” is. Surely a 3:1 favorite cannot be a slight favorite!
Andrew:
Why will being conservative give up some calibration?
If they look at 20% predictions and find they occurred 20% of the time (and conclude they are well calibrated), isn’t that independent of how conservative their confidence intervals were (e.g. 20% +/-5% vs. 20% +/- 10%)?
Anon:
See the above link. When they looked at their 20% predictions, they only occurred 14% of the time. And, of their 80% predictions, these occurred 88% of the time. This represents underconfident.
If your predictions are calibrated, you’d just call them predictions, not conservative predictions. In the predictions context, being conservative is making your intervals extra wide, thus giving overcoverage (i.e., underconfidence) because you really want your interval to include the ultimate outcome.
Andrew:
Okay. But I was looking at their sports predictions, where 20% predictions occurred 20% of the time, 40% predictions 40% of the time, etc. The biggest discrepancy was at the high end, where they seemed to be overconfident, e.g. 80% predictions only occurring 77% of the time. (I can’t remember the exact numbers, so these are just made up.)
That part I don’t understand either. If large-probability predictions are off significantly, then why aren’t complementary small-probability predictions also off? (Their small-probability predictions are off by at most 1 percentage point.) e.g. the 80% prediction is over; why isn’t the 20% prediction of the other side winning under? (It’s a bit more complicated because there can be three results, i.e. draw/tie.)
P.S. Looking again at the link, I can’t find the plot I was referring to above. But maybe the binning has something to do with the issue I wrote about. They write: “for example, we’ll throw every prediction that gave a team between a 37.5 percent and 42.5 percent chance of winning into the same “40 percent” group”.
> (It’s a bit more complicated because there can be three results, i.e. draw/tie.)
You gave yourself the answer there, I think. Apart from ties there are other “non-binary” cases like the probability of some team or player of winning some tournament (they wouldn’t include the complementary “not winning” event).
Carlos wrote: “You gave yourself the answer there, I think. Apart from ties there are other “non-binary” cases…”
It’s possible. I originally thought it was just for matches (they separate “matches” and “leagues” in what they currently show), where they do give probabilities for all results, including draw/tie.
> isn’t that independent of how conservative their confidence intervals were (e.g. 20% +/-5% vs. 20% +/- 10%)?
Probabilities are not (normally) given with confidence intervals. The confidence intervals are for the prediction of values (like share of vote from 0% to 100%), not for the probabilities of events (like getting over or under 50% of vote).
Okay. But even if it’s not normally given with confidence intervals, if you predict an event has a 50% probability of occurring, there’s uncertainty in your prediction, which could be expressed in that way (or some other way), right?
I’m taking the position here that there is a “true probability” of the event occurring, even if it’s just one-off. And predictions will differ from this unknown true probability.
I’m very skeptical of the idea of “true probability” of a future event, since there are so many unknown events that could influence that probability between now and when the even occurs.
Martha:
But that just means we can never know it, not that it doesn’t exist.
Do we believe these are classical events and classically everything is deterministic, though practically unknowable by mere humans?
If “true probability” does not exist, presumably we have to have a source of non-determinism.
> there’s uncertainty in your prediction, which could be expressed in that way (or some other way)
It could be expressed in some other way, but not in that way. Some kind of “meta-probability” model is needed, like Jaynes’ A_p distribution: https://www.lesswrong.com/posts/2xmKZu73gZLDEQw7c/probability-knowledge-and-meta-probability
In this case, one could be tempted to say the “strength” of the winning probability prediction is related to the form of the posterior distribution for vote share but it’s actually something else. A 50% winning probability from a 50%+/-10% vote share prediction could be “stronger” (i.e. less sensitive to additional information) than a 50% winning probability from a 50%+/-1% vote share prediction.
From Nate Silver –
Biden is up *8* points in a *Fox News* poll of *Wisconsin* conducted *immediately after the RNC* and prediction markets have the race as a toss-up.
—-
The betting markets are skewed because few D’s have any confidence in Biden and R’s are over-confident in Trump. The money being put down is making the betting line disagree with the probabilities.