1. An estimate of the geography of partisan prejudice
My colleagues David Rothschild and Tobi Konitzer recently published this MRP analysis, “The Geography of Partisan Prejudice: A guide to the most—and least—politically open-minded counties in America,” written up by Amanda Ripley, Rekha Tenjarla, and Angela He.
Ripley et al. write:
In general, the most politically intolerant Americans, according to the analysis, tend to be whiter, more highly educated, older, more urban, and more partisan themselves. This finding aligns in some ways with previous research by the University of Pennsylvania professor Diana Mutz, who has found that white, highly educated people are relatively isolated from political diversity. They don’t routinely talk with people who disagree with them; this isolation makes it easier for them to caricature their ideological opponents. . . . By contrast, many nonwhite Americans routinely encounter political disagreement. They have more diverse social networks, politically speaking, and therefore tend to have more complicated views of the other side, whatever side that may be. . . .
The survey results are summarized by this map:
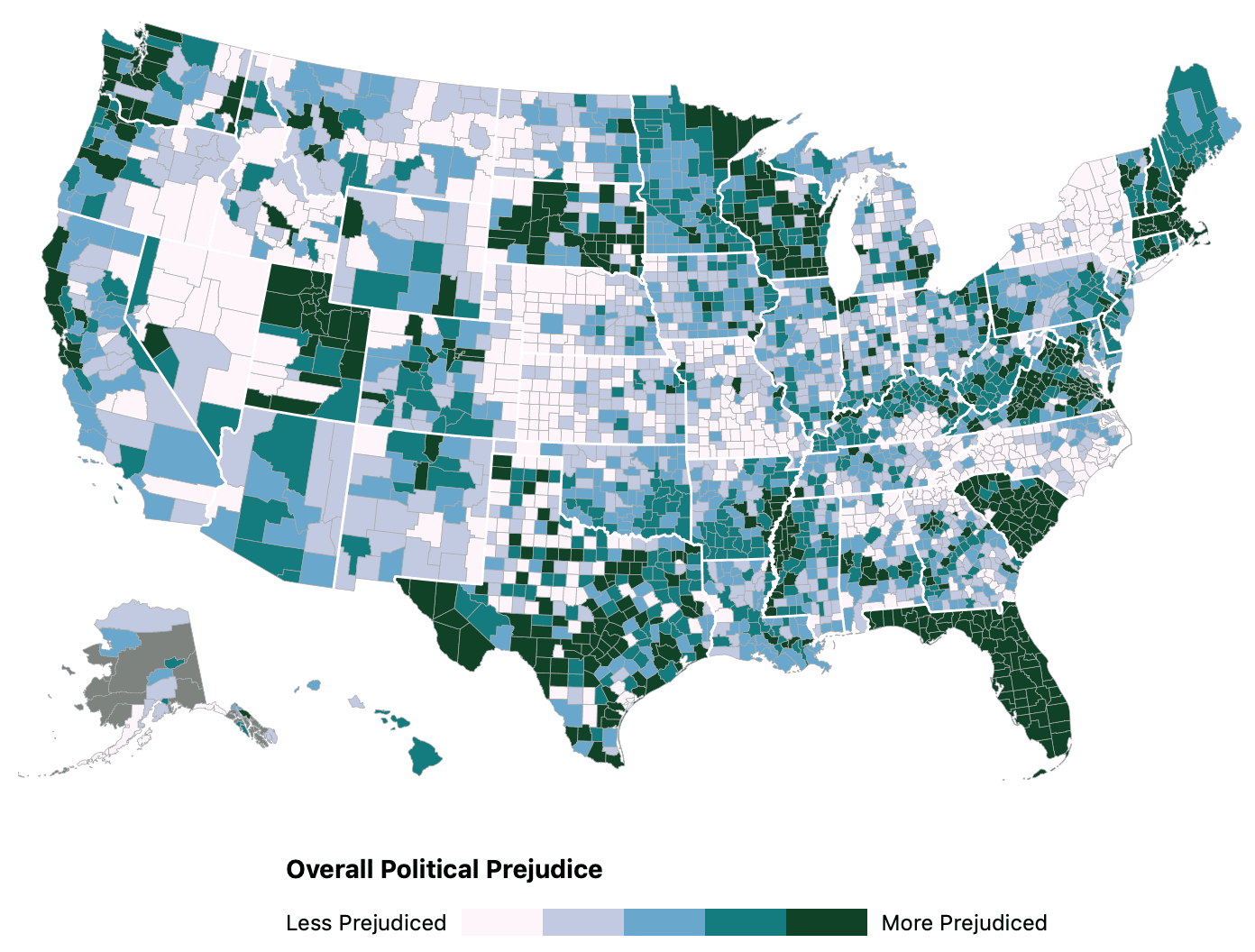{kind=link}

I’m not a big fan of the discrete color scheme, which creates all sorts of discretization artifacts—but let’s leave that for another time. In future iterations of this project we can work on making the map clearer.
There are some funny things about this map and I’ll get to them in a moment, but first let’s talk about what’s being plotted here.
There are two things that go into the above map: the outcome measure and the predictive model, and it’s all described this post from David and Tobi.
First, the outcome. They measured partisan prejudice by asking 14 partisan-related questions, from “How would you react if a member of your immediate family married a Democrat?” to “How well does the term ‘Patriotic’ describe Democrats? to “How do you feel about Democratic voters today?”, asking 7 questions about each of the two parties and then fitting an item-response model to score each respondent who is a Democrat or Republican on how tolerant, or positive, they are about the other party.
Second, the model. They took data from 2000 survey responses and regressed these on individual and neighborhood (census block)-level demographic and geographic predictors to construct a model to implicitly predict “political tolerance” for everyone in the country, and then they poststratified, summing these up over estimated totals for all demographic groups to get estimates for county averages, which is what they plotted.
Having done the multilevel modeling and poststratification, they could plot all sorts of summaries, for example a map of estimated political tolerance just among whites, or a scatterplot of county-level estimated political tolerance vs. average education at the county level, or whatever. But we’ll focus on the map above.
2. Two concerns with the map and how it’s constructed
People have expressed two concerns about David and Tobi’s estimates.
First, the inferences are strongly model-based. If you’re getting estimates for 3000 counties from 2000 respondents—or even from 20,000 respondents, or 200,000—you’ll need to lean on a model. As a results, the map should not be taken to represent independent data within each county; rather, it’s a summary of a national-level model including individual and neighborhood (census block-level) predictors. As such, we want to think about ways of understanding and evaluating this model.
Second, the map shows some artifacts at state borders, most notably with Florida, South Carolina, New York state, South Dakota, Utah, and Wisconsin, also some suggestive patterns elsewhere such as the borders between Virginia and North Carolina, and Missouri and Arkansas. I’m not sure about all these—as noted above, the discrete color scheme can create apparent patterns from small variation, and there are real differences in political cultures between states (Utah comes to mind)—but there are definitely some problems here, problems which David and Tobi attribute to differences between states in the voter files that are used to estimate the total number of partisans (Democrats and Republicans) in each demographic category in each county. If the voter files for neighboring states are coming from different sorts of data, this can introduce apparent differences in the poststratification stage. Their counting problems are especially cumbersome because we have to estimate the total number of partisans in each demographic category in each county
3. Four plans for further research
So, what to do about these concerns? I have four ideas, all of which involve some mix of statistics and political science research, along with good old data munging:
(a) Measurement error model for differences between states in classifications. The voter files have different meanings in different states? Model it, with some state effects that are estimated from the data and using whatever additional information we can find on the measurement and classification process.
(b) Varying intercept model plus spatial correlation as a fix to the state boundary problems. This is kind of a light, klugey version of the above option. We recognize that some state-level fix is needed, and instead of modeling the measurement error or coding differences directly, we throw in a state-level error term, along with a spatial correlation penalty term to enforce similarity across county boundaries (maybe only counting counties that are similar in certain characteristics such as ethnic breakdown and proportion urban/suburban/rural).
(c) Tracking down exactly what happened to create those artifacts at the state boundaries. Before or after doing the modeling to correct the glaring boundary artifacts, it would be good to do some model analysis to work out the “trail of breadcrumbs” explaining exactly how the particular artifacts we see arose, to connect the patterns on the map with what was going on in the data.
(d) Fake-data simulation to understand scenarios where the MRP approach could fail. As noted in point 2 above, there are legitimate concerns about the use of any model-based approach to draw inferences for 3000 counties from 2000 (or even 20,000 or 200,000) respondents. One way to get a sense of potential problems here is to construct some fake-data worlds in which the model-based estimates will fail.
OK, so four research directions here. My inclination is to start with (b) and (d) because I’m kind of intimidated by the demographic classifications in the voter file, so I’d rather just consider them as a black box and try to fix them indirectly, rather than to model and understand them. Along similar lines, it seems to me that solving (b) and (d) will give us general tools that can be used in many other adjustment problems in sampling and causal inference. That said, (a) is appealing because it’s all about doing things right, and it could have real impact on future studies using the voter file, and (c) would be an example of building bridges between different models in statistical workflow, which is an idea I’ve talked about a lot recently, so I’d like to see that too.
Andrew’s suggestions seem sensible and worthwhile to me. But I can’t escape the feeling that with 2000 responses they should abandon the goal of characterizing county level partisan sentiments. Sure, fancy modeling can be used to derive more robust estimates than what the map shows – but should data that sparse really be used for this purpose. If they are constrained to use only 2000 observations, shouldn’t they restrict their attention to state level estimates? Or, if they are intent on county level estimates, shouldn’t they insist on more than 2000 observations? I really can’t see how 2000 observations for 3000 counties will ever be convincing, regardless of how much simulation they conduct.
Another thing: the colors on the map do disturb me, but what disturbs me more is that there appears to be no mention of the scale that is used. I looked through all the documentation and didn’t find a single reference to the scaling. Is it a linear scale, quantile, standard deviation, log, etc? The map will appear quite differently depending on scale – how much “more prejudiced” is one color than another? Without any scaling, I find the map appalling.
In addition, the data/analysis appears to be conducted by PredictWise, and they state:
“PredictWise prides itself in transparency. I am beyond happy to see the kind of healthy and lively debate the Atlantic story created – that is a good thing! And, more data and better models will always improve existing research. In that sense, I cannot wait for these results to be replicated, shared, debunked and improved. Of course, the perfect solution is a survey answered by 100s of Millions of Americans – but that remains elusive. Instead, a combination of novel survey methods, analytics and computing – made possible by recent advancements in statistics and computer science – allows us to get some, any handle on geo-spatial variation in and understanding of phenomena like political tolerance more important than ever in today’s political climate. In that sense, let this be the first of many analyses on this subject. And to all applied researchers: happy replicating, improving, debunking!”
Admirable comments. But, can someone show me where they have made the data available? I can’t find it anywhere, and as I said, I don’t even seem any reference to the scale used in the map. I am finding it hard to square this with the sentiments in the quote.
I’d read the Atlantic piece and my comment at the time was: what the heck are they talking about? It’s not clear what the work means: does partisan ‘prejudice’ mean anything versus how you vote? Is it meaningful that someone where I live might be able to tolerate Republicans* when they wouldn’t vote Republican? Is this about some other form of ‘dislike’? And when that’s attributed across counties, I didn’t know what to think because demographic data is, to me, more something I relate to at a census tract level and not at an abstraction level of county. Example: Norfolk County, which I live, consists of Brookline and a bunch of suburban towns that aren’t attached physically to Brookline and which are enormously different.
From what I could read, I also had trouble with the questions because, for example, in some places it’s more normal to be polite about differences that you don’t really accept. This has been studied many times in the kinds of resume situations the article includes: you can appear tolerant but still reject the minority candidate.
*That’s a joke: I barely know anyone in the area who feels able to openly express conservative beliefs. I mention this because it gets at the ‘prejudice’ idea: it’s expected that the residents are all either liberal or will publicly appear liberal while the tradespeople, the police and fire, etc. are ‘allowed’ to be conservative unless they say they are. We actually had an instance recently where people complained because an off duty officer from another town had his truck parked while he was on a police detail – directing traffic for a gas work crew (because in MA that’s a huge boondoggle that pumps police pay into 6 figures) – and it had a Trump sticker on it. They wanted to make sure the visiting officers, etc. didn’t, you know, trigger anyone with such an open expression of racism. I wish I were kidding. So this isn’t a joke, but I still don’t know what the work is really trying to say.
As a non-scientist and non-statistician, isn’t all we need to know is:
1) The data is from 2,000 survey responses; and
2) “PredictWise was able to rank all 3,000 counties in the country based on the estimated level of partisan prejudice in each place.”
in order to totally disregard any conclusions from the Atlantic article (and avoid wasting time reading any past or future “studies” produced by the researchers?
No, with a high quality design and 100% response, 2000 survey responses are enough to get some useful information on this topic. The bigger issue is what is the design and what is the response rate.
For example if they chose 10 counties weighted by population from around the country, and surveyed 200 people each county, and got results from all of them, then did MRP and got a Bayesian posterior, then plotted 10 versions of this map to show the variation in estimates.. It’d be nontrivially informative.
Some useful information, sure. (Although a 100% response rate is the stuff of fantasy). But predicting 3000 counties from 2000 people is impossible, and even attempting it is an act of hubris.
+1
not impossible, just imprecise. claiming to have precise point estimates is an act of hubris, doing the work to get realistic uncertainty bounds is an act of science. I haven’t looked at what they did here, but I think it’s important not to write off work as impossible. the whole point of good Bayesian statistics is to quantify in a useful way what we do and don’t know.
I do believe we are trying to deodorize fecal matter.
“…just imprecise” How about that’s an epic understatement? The error terms on those estimates are epic. Especially when you consider the geographic distribution of the population (in megalopolises, not towns, villages and etc.). So in addition to a shortage of respondents, they are in utterly the wrong places to provide a basis for any sort of a rational estimate for the emptier spaces…
Yes, yes, yes, I use modeling, it is useful, and even necessary for placing bets… But this is a bridge too far, nay, not even in the same solar system.
the goal of a good Bayesian model is to quantify the uncertainty, so then we can have a discussion about how imprecise. honestly without seeing the data, the sampling plan, and the model, we can’t really say whether it’s a bit imprecise or ridiculously so. I think this is why we should be requiring people to provide these pieces of the puzzle.
I don’t understand why the scale goes from “less prejudiced” to “more prejudiced” instead of, say, “prejudiced against Republicans” to “prejudiced against Democrats” with something neutral in the middle. I’m guessing people in urban and rural areas are ~similarly “prejudiced”, but in completely opposite directions. In any case, smoothing toward state-specific random effects makes no sense if you think/believe/know that there are urban/rural disparities *within* state.
Similarly, I suppose I’m confused by the desire to analyze prejudice toward a party (which not only seems uninteresting, but is also something you get a proxy of 100+ million data-points on every two years) instead of prejudice toward people with certain beliefs. For instance, questions like “How would you react if someone in your family married someone who is Christian/Muslim/Jewish/Buddhist/Atheist/etc.?” seem more enlightening than Democrat/Republican questions.
And on a slightly unrelated note, I’m a bit confused by Andrew’s “I’m not a big fan of the discrete color scheme” comment. Is that referring to having 5 bins of colors in the map? My understanding is that (geographers claim that scientists claim that) the human eye can only distinguish differences between a handful of colors, and thus if you want users/readers to be able to determine the values you’re mapping, you should limit yourself to 5-7 colors. I suppose argument for a continuous color scheme might include (a) discrete colors suggest that values in one shade are “different” than those in another when the difference itself might not be significant and (b) that if you can’t tell the difference between two regions’ colors in a continuous color scheme, there’s probably little-to-no difference in their actual values…? I understand that argument, but it also seems similar to the “don’t give me so many decimal points in your table” complaint.
Harryq:
The discrete color scheme introduces discretization artifacts that produces spurious patterns in the map. It’s not that a continuous shading will give you that much more information; it’s more that it will not throw up so many spurious patterns.
hmm… I guess I remain unconvinced. I understand your criticism of discretization in general (it seems similar to dichotomizing between significant and non-significant effects), but I also want people who view my maps to be able to tell what values I’m mapping. In other words, I guess I’d rather the reader *know* that Lac qui Parle County has a value between 50-100 than make the reader try to guess which shade of red it has and estimate its value from a continuous scale — where the accuracy/precision of their estimate will be determined by how well they see and how good of a screen or a printer they have.
Anyhoo, I’m pretty sure (or at least hope) that this was only a minor point, but since most of my work is spatial and Bayesian, I selfishly needed to ask :)
Harryq:
I think this goal of yours can be best achieved by an interactive map where you can click on counties or zoom in on areas to get more precise estimates.
So, can either of you tell me whether the difference between the shades = 0.5, 5, 5 million, or even what the scale is? I remain puzzled by the complete lack of a measurement scale. Perhaps I missed it. But if I didn’t, then why doesn’t this bother everybody?
Based on reading the bottom of the blog post:
https://blog.predictwise.com/2019/03/the-atlantics-the-geography-of-partisan-prejudice-method-addendum/
I think the color represents their estimate of eta_c, the county wide average value of eta… eta is multiplied by lots of stuff to produce numbers that appear in the exponent in the inverse logit… basically none of it has an inherent scale. So I think the only way to interpret it is likely that they’re working with quantiles of the eta parameter for coloring. I suspect given the coloring it’s quintiles of the eta parameter that determine the color.
Thanks. But you shouldn’t have to suspect.
Indeed, I was trying to analyze it further to figure out how the parameterization works enough to decide whether there was a better way… but really its their job.
and upon clicking on the Atlantic article, I see that they *do* make maps of “prejudice toward Dem/Rep”, which is good.
Andrew:
How would you introduce this spatial penalty? Would this be incorporated in the multilevel model of MRP? Or just some sort of penalty after the predictions are made but before the poststratification. I’m really curious as to how include spatial constraints in a multilevel setting. Any reference to this type of work?
Here is a more technical question: as Daniel indicates above, it is possible to get informative information about 3000 counties from 2000 observations – after all, any inference involves doing something like that. And, as Andrew says, it all depends on relying on a model of some sort. So, the model they are using incorporates the following characteristics:
“urbanicity based on home address, age, gender, education, household composition, race, party affiliation, and two variables we use to describe the neighborhood: age variation and variation in partisan identification at the census block where the individual resides.”
This is not a bad list, but nothing about income, employment, labor market structure, etc etc. While they have a number of pertinent variables, the omitted list is also fairly long and potentially important. How does it make this study more enlightening than power pose, shark attacks, or any of the other studies that have pushed the data beyond what it can tell us? Does the magic of MrP somehow provide assurance that the differences between the 3000 counties are somehow being captured by these 2000 observations?
I still have the feeling that this particular data should either be used for national or state level results, and that counties are an over-reach. And, as pointed out by Jonathan above, counties may be too aggregate to be meaningful. Where is the guidance for how granular the results should be given the size (both number of observations and number of variables) of the data? And, where is the data?
>I still have the feeling that this particular data should either be used for national or state level results, and that counties are an over-reach.
I disagree, counties may be less accurate on an individual basis, but states vary a lot from county to county so treating the statewide average as a fixed thing is not very useful. Look at the map of california for example, it has counties that vary across the entire spectrum of colors, and in fact, that level of variation is exactly what I’d expect.
And, some states hardly vary at all across counties – Florida and South Carolina. I guess the question is whether the differences from CA to FL/SC are real differences in the data or artifacts of the model. My point was that the data may not permit disaggregation below the state level – not that state level results are particularly meaningful. It has already been pointed out that counties may be too aggregate for the question being asked. So, there is some relationship between the question being analyzed, the data available, and the degree of granularity in the model: I think there is guidance that could be offered about that relationship. I’m not prepared to articulate that, but perhaps you can.
well the blog post mentions that reporting methods in some states are probably providing bad data and they specifically mention Florida among others.
The way it works, they fit a model to the survey, and then use the model, as well as reported data in each county, to predict for that county. for example this might be a case where Florida is reporting state aggregates at the county level, if we used state level data all the states might look like Florida…
Dale, I’d say that it’s irresponsible here to not use a measurement error model.
The process kinda looks like this:
model = fit_model_to_data(survey)
county_demographics_data = get_demographics_from_database()
county_estimate = estimate_county(model, county_demographics_data)
My argument is that in fact, if we know that county demographics data is itself somewhat unreliable, we should do something like:
model = fit_model_to_data(survey)
demographics_model = fit_demographics_model(get_demographics_from_database(), get_other_demographics_sources())
county_estimate = estimate_county(model, demographics_model)
Rather than simply taking the demographics data published in the database as dogma, we should be trying to estimate the actual demographics of the counties using published data from various sources to account for the reporting variation among states, counties, etc.
Short Argument for Discretized Color Maps:
https://ctg2pi.wordpress.com/2019/04/08/short-argument-for-discretized-color-maps/
I remember when I saw that map in The Atlantic, I felt like writing them and saying, Don’t do that, just don’t do that. If you want to publish such a map, do it in an academic journal, not a popular magazine, even one that has an educated readership. As has been indicated, a map pretending to show the degree of “political prejudice”, whatever that is, for 3,000 counties based upon data from 2,000 people is heavily model dependent. Where, outside the confines of Predictwise, has that model been tested? Why should we think that county lines have any meaning with regard to political prejudice? Let experts debate the questions involved, but don’t inflict such a problematic map on a lay readership, even an educated one.
The New York Times once published a map purporting to show which counties were good or bad for the later economic well being of children who were raised there. I have a nephew who lives in a relatively prosperous community in a poor state, which has a good city school system. I emailed him a copy of the map and informed him that the NYT said that for the sake of his kids he should move to a neighboring rural county. He wrote back saying they’ll just have to suffer. We both got a good laugh out of that. ;)
A few times in my life I have observed in person what might be called political prejudice, so I think that there is something there. But I regard this kind of map in an online popular magazine pretty much as I regard click bait.
Isn’t the 3000 predictions vs 2000 observations somewhat irrelevant? Can’t we make as many predictions as we want? It seems like what is important is having responses with a good coverage of the domain of demographic predictors relative to the domain where you will make predictions.
I think that is right. That is why I am concerned that no economic predictors were used – and who knows what else was not included? It strikes me as not fundamentally different than many of the psychological studies that have been criticized so much on this blog. The model’s results comparing counties might be due to political views – or perhaps they are due to economic differences – or perhaps they are due to X,Y,Z. This is true for any statistical analysis – there is always missing data. But when you have data from a relatively small number of counties and claim to make county-level predictions, I would think that you should include as many potentially relevant county level factors. There is readily available data on county level incomes, labor market conditions, industry makeup, etc. and it does not look like any of these were used in the model. They did use demographic data and party/voting data. It is hard for me to have faith in this modeling exercise.
I think you could be right that important predictors are omitted, but I had a slightly different take. I wouldn’t be surprised if many of the county level predictors are fairly correlated. Therefore, it seems like you would want to reduce the dimensionality and score counties on a few composite metrics that explain county variation, then make predictions based on those composites. I would imagine a predictor such as gender hardly explains any variation in counties because it is roughly 50/50. Gender is almost certainly important, but not if the goal of the analysis is to make county level predictions.
However, it seems confusing to a general audience to make predictions based on demographics and then “project” it onto counties as implicitly spatial predictions. I don’t know the distribution of county level demographics, so if you feed that through your model I can’t interpret the results. To me it distorts the causal reasoning to the point of being misleading. For example, based on the map you might think people in Florida are prejudiced, when likely all the model is saying is that more old people live in Florida. If no predictors are provided on the visual, then I think the audience will just fill that gap with whatever personal experience and incomplete/incorrect knowledge they have of how US states or regions differ.
“Can’t we make as many predictions as we want?”
Good point. Of course we can.
However:
1) Trivially, the more predictions we make the more erroneous predictions we make.
2) The authors assume that all US counties are alike with regard to political prejudice. In fact, they say so; they are applying nationwide statistics to each county. As an example of where I think they may have gone wrong is in their explanation that old, rich, White people are not likely to interact much with people who hold politically different views, and thus get no negative reinforcement to any political prejudice in daily life. But take a look at the Mississippi Delta, that dark band next to the Mississippi river. (Despite the name it is not the delta of the Mississippi River itself.) Ever since slavery days, Blacks and Whites have rubbed shoulders with each other there. Yet it is an area of high political prejudice, contrary to what their explanation suggests. My suspicion is that in the Delta “political prejudice” is a proxy for racial prejudice. Nearly all Republicans are White, and nearly all Democrats are Black or so-called N—–lovers. In other parts of the country, with different histories, “political prejudice” may be quite different.
I am not convinced that “the more predictions we make the more erroneous predictions we make.” I think this is true only to the extent that more predictions means more diverse predictions (i.e., spread out over the design space). For example, we make similar predictions for similar counties so that essentially the same prediction appears multiple times on the map. Moreover, I think we want to make lots of predictions because it might allow us to spot regions in the design space (e.g., demographic combinations) where our model yields nonsensical results.
This confusion is part of the reason I don’t really like presenting the results as a map. First, we have no idea if there is objectively high prejudice in the Mississippi Delta. All we know is that it is “more prejudiced” relative to the other model predictions. Second, the higher values in the Mississippi Delta only exist within the context of the model. Change the model and the predictions change. Conditional on the author’s model being correct, there is higher prejudice in Mississippi Delta. You believe that the author’s post-hoc rationalization for the observed result is inconsistent with the model predictions. You propose an alternative hypothesis that would lead to a different model. Would your model yield similar predictions to the author’s model? If your predictions are different, how would we assess which model is better? The only thing we can compare the predictions to is the 2000 respondents and possibly prior knowledge (if any exists) regarding the spatial distribution of prejudice in the US.
The thing is, you can make up questionnaires about anything you want. But does doing so explain anything? If so, does something else explain that thing better? Since there are alternative explanations, they need to be tested against each other. As an example, for a number of sociological phenomena in the US that on their face are associated with race, class is a better predictor. The question then becomes, why do race and class continue to be so closely associated in the US, over many generations?
Besides such questions, “political prejudice”, as defined by the questionnaire, is predicted to vary in intensity geographically across the US. That’s what their map proposes to show. Not that the predictions in the map have been tested. It has not been shown to hold up in any county in the US, has it? Yet the map suggests to readers that they can use it as a guide to locate political prejudice. To some degree, that is true, but to what degree? If they had said, here is a map that indicates our educated guesses, that would have been better. But then would it have gotten published?
Let me add one thing, political, not scientific. There are those who claim that today the US is a post-racist society. Not that there are no racists at all, but that they are very few. If “political prejudice” is out there as a thing distinct from racial prejudice, politicians may claim that they are discriminating against certain people, not because they are prejudiced against non-Whites, which would be illegal, but because they are prejudiced against Democrats, which is legal. And, dear friends, in the US that is already a thing.
I really like this idea but I agree I am a bit skeptical that you might be too model dependent. I am reminded of a good sensitivity analyses that was presented by Di Cook at the 2018 Rstudio conference.
The idea is build a graphic with a bunch of random maps, to see if you can pick out the true data. She made a R package to implement
https://dicook.github.io/nullabor/index.html
I think I can finally articulate what bugs me about this map. On its face it claims to show what it does not show. I don’t think that any misinformation is intended, it is just inaccurate wording. The legend indicates that the different colors represent “Overall Political Prejudice”, but in no county was any political prejudice measured. Make that “Overall Predicted Political Prejudice”, and it says what it shows.
Thanks for your comment Dale! We could have been a little more specific: The scale used is percentiles of eta_c. We have updated our Methods Addendum to reflect this: last sentence of https://blog.predictwise.com/2019/03/the-atlantics-the-geography-of-partisan-prejudice-method-addendum/