A comment at Thomas Lumley’s blog pointed me to this discussion by Terry Burnham with an interesting story of some flashy psychology research that failed to replicate.
Here’s Burnham:
[In his popular book, psychologist Daniel] Kahneman discussed an intriguing finding that people score higher on a test if the questions are hard to read. The particular test used in the study is the CRT or cognitive reflection task invented by Shane Frederick of Yale. The CRT itself is interesting, but what Professor Kahneman wrote was amazing to me [Burnham],
90% of the students who saw the CRT in normal font made at least one mistake in the test, but the proportion dropped to 35% when the font was barely legible. You read this correctly: performance was better with the bad font.
I [Burnham] thought this was so cool. The idea is simple, powerful, and easy to grasp. An oyster makes a pearl by reacting to the irritation of a grain of sand. Body builders become huge by lifting more weight. Can we kick our brains into a higher gear, by making the problem harder?
This is a great start (except for the odd bit about referring to Kahneman as “Professor”).
As in many of these psychology studies, the direct subject of the research is somewhat important, the implications are huge, and the general idea is at first counterintuitive but then completely plausible.
In retrospect, the claimed effect size is ridiculously large, but (a) we don’t usually focus on effect size, and (b) a huge effect size often seems to be taken as a sort of indirect evidence: Sure, the true effect can’t be that large, but how could there be so much smoke if there were no fire at all?
Burnham continues with a quote from notorious social science hype machine Malcolm Gladwell, but I’ll skip that in order to spare the delicate sensibilities of our readership here.
Let’s now rejoin Burnham. Again, it’s a wonderful story:
As I [Burhnam] read Professor Kahneman’s description, I looked at the clock and realized I was teaching a class in about an hour, and the class topic for the day was related to this study. I immediately created two versions of the CRT and had my students take the test – half with an easy to read presentation and half with a hard to read version.
Within 3 hours of reading about the idea in Professor Kahneman’s book, I had my own data in the form of the scores from 20 students. Unlike the study described by Professor Kahneman, however, my students did not perform any better statistically with the hard-to-read version. I emailed Shane Frederick at Yale with my story and data, and he responded that he was doing further research on the topic.
This is pretty clean, and it’s a story we’ve heard before (hence the image at the top of this post). Non-preregistered study #1 reports a statistically significant difference in a statistically uncontrolled setting; attempted replication #2 finds no effect. In this case the replication was only N = 20, so even with the time-reversal heuristic, we still might tend to trust the original published claim.
The story continues:
Roughly 3 years later, Andrew Meyer, Shane Frederick, and 8 other authors (including me [Burnham]) have published a paper that argues the hard-to-read presentation does not lead to higher performance.
The original paper reached its conclusions based on the test scores of 40 people. In our paper, we analyze a total of over 7,000 people by looking at the original study and 16 additional studies. Our summary:
Easy-to-read average score: 1.43/3 (17 studies, 3,657 people)
Hard-to-read average score: 1.42/3 (17 studies, 3,710 people)Malcolm Gladwell wrote, “Do you know the easiest way to raise people’s scores on the test? Make it just a little bit harder.”
The data suggest that Malcolm Gladwell’s statement is false. Here is the key figure from our paper with my [Burnham’s] annotations in red:
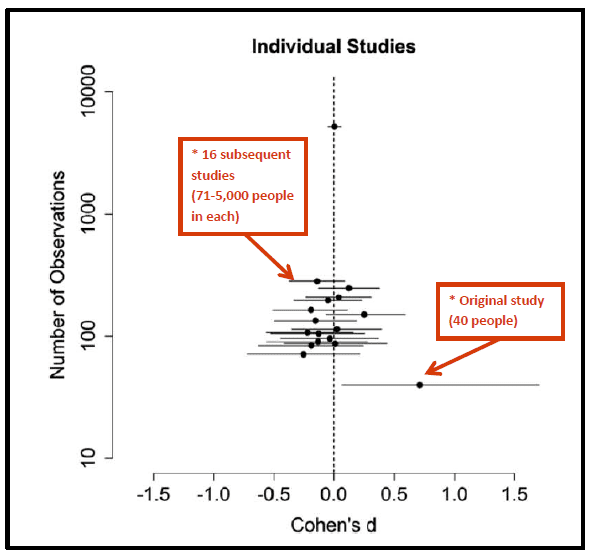
What happened?
After the plane crashes, we go to the black box to see the decision errors that led to the catastrophe.
So what happened with that original study? Here’s the description:
Main Study
Forty-one Princeton University undergraduates at the student campus center volunteered to complete a questionnaire that contained six syllogistic reasoning problems. The experimenter approached participants individually or in small groups but ensured that they completed the questionnaire without the help of other participants. The syllogisms were selected on the basis of accuracy base rates established in prior research (Johnson-Laird & Bara, 1984; Zielinski, Goodwin, & Halford, 2006). Two were easy (answered correctly by 85% of respondents), two were moderately difficult (50% correct response rate), and two were very difficult (20% correct response rate). The easy and very difficult items were omitted from further analyses because the ceiling and floor effects obscured the effects of fluency on processing depth. Shallow heuristic processing enabled participants to answer the easy items correctly, whereas systematic reasoning was insufficient to guarantee accuracy on the difficult questions. Participants were randomly assigned to read the questionnaire printed in either an easy-to-read (fluent) or a difficult-to-read (disfluent) font, the same fonts that were used in Experiment 1.
Finally, participants indicated how happy or sad they felt on a 7-point scale (1 = very sad; 4 = neither happy nor sad; 7 = very happy). This is a standard method for measuring transient mood states (e.g., Forgas, 1995).
Results and Discussion
As expected, participants in the disfluent condition answered a greater proportion of the questions correctly (M = 64%) than did participants in the fluent condition (M = 43%), t(39) = 2.01, p < .05, η2 = .09. This fluency manipulation had no impact on participants' reported mood state (Mfluent = 4.50 vs. Mdisfluent = 4.29), t < 1, η2 < .01; mood was not correlated with performance, r(39) = .18, p = .25; and including participants' mood as a covariate did not diminish the impact of fluency on performance, t(39) = 2.15, p < .05, η2 = .11. The performance boost associated with disfluent processing is therefore unlikely to be explained by differences in incidental mood states.
Let’s tick off the boxes:
– Small sample size and variable measurements ensure that any statistically significant difference will be huge, thus providing Kahneman- and Gladwell-bait.
– Data processing choices were made after the data were seen. In this case, two-thirds of the data were discarded because they did not fit the story. Sure, they have an explanation based on ceiling and floor effects—but what if they had found something? They would easily have been able to explain it in the context of their theory.
– Another variable (mood scale) was available. If the difference had shown up as statistically significant only after controlling for mood scale, or if there had been a statistically significant difference on mood scale alone, any of these things could’ve been reported as successful demonstrations of the theory.
What is my message here? Is it that researchers should be required to preregister their hypotheses? No. I can’t in good conscience make that recommendation given that I almost never preregister my own analyses.
Rather, my message is that this noisy, N = 41, between-person study never had a chance. The researchers presumably thought they were doing solid science, but actually they’re trying to use a bathroom scale to weigh a feather—and the feather is resting loosely in the pouch of a kangaroo that is vigorously jumping up and down.
To put it another way, those researchers might well have thought that at best they were doing solid science and at worst they were buying a lottery ticket, in that, even if their study was speculative and noisy, it was still giving them a shot at a discovery.
But, no, they weren’t even buying a lottery ticket. When you do this sort of noisy uncontrolled study and you “win” (that is, find a statistically significant comparison), you actually are very likely to be losing (high type M error, high type S error rate).
That’s what’s so sad about all this. Not that the original researchers failed—all of us fail all the time—but that they never really had a chance.
On the plus side, our understanding of statistics has increased so much in the past several years—no joke—that now we realize this problem, while in the past even a leading psychologist such as Kahneman and a leading journalist such as Gladwell were unaware of the problem.
P.S. It seems that I got some of the details wrong here.
Andrew Meyer supplies the correction:
That’s actually the black box from the wrong flight. Alter et al.’s paper included four tests of the underlying conjecture. All four experiments shared the same basic features: a noisy dependent variable, a subtle manipulation, a small sample size, and an impressive result. The data Gelman describes are Alter et al.’s fourth study, whose dependent variable was the number of correct judgments of syllogistic validity. Meyer & Frederick et al. attempted to replicate Alter’s first study, whose dependent variable was the number correct on a 3-item math test (Frederick’s CRT). A post-hoc examination of Alter et al.’s first study reveal some somewhat subtler issues. Quoting footnote 2 from Meyer & Frederick et al.:
It is often implied and sometimes claimed that disfluent fonts improve performance on the bat-and-ball problem. In fact, there was no such effect even in the original study, as shown in row 1 of Table 1. The entire effect reported in Alter et al. (2007) was driven by just one of the three CRT items: “widgets,” which was answered correctly by 16 of 20 participants in the disfluent font condition, but only 4 of 20 participants in the control condition. The 20% solution rate in the control condition is poorer than every other population except Georgia Southern. It is also significantly below the 50% solution rate observed in a sample of 300 Princeton students (data available from Shane Frederick upon request). This implicates sampling variation as the reason for the original result. If participants in the control condition had solved the widgets item at the same rate as Princeton students in other samples, the original experiment would have had a p value of 0.36, and none of the studies in Table 1 would exist.
Alter et al.’s fourth study actually has been successfully replicated once (Rotello & Heit, 2009). But it has failed to replicate on at least four other occasions (Exell & Stupple, 2011; Morsanyi & Handley, 2012; Thompson et al., 2013; Trippas, Handley & Verde, 2014).
We should also note that, since Meyer & Frederick et al. came out, we became aware of one additional “successful” test of font fluency effects on CRT scores: an experiment in a classroom setting at Dartmouth. So, the current count, including the 17 CRT studies mentioned in Meyer and Frederick et al. and the 2 that were not mentioned (the small one by Burnham and the moderately substantial one at Dartmouth), comes to 2 observations of a statistically significant disfluent font benefit on CRT scores and 17 failures to observe that effect.
Dear Andrew,
My sense is that one big problem is that few people who cite the study read the details about the study carefully. Even when they are writing vignettes about the study. Another perhaps more egregious version of the point about researchers not reading the study they citing is where they miscite the claim — attributing something that the study doesn’t say.
I think one of your points is also about the peer review process that was (is) obtuse enough to not catch such issues.
>>> given that I almost never preregister my own analyses.<<<
Perhaps you could start?
I never understand your antipathy towards pre-registration: at the worst, it can do no harm?
Don’t take everything Andrew says seriously :). He doesn’t actually do any experiments himself. He’s more of an armchair statistician (obviously a very good one), like we have armchair linguists in linguistics. In ling, many of the things that armchair linguists say are really deep and insightful. Some of the things they say, well, best ignored.
As a practicing experimentalist, I think pre-registration is a great idea and we should all do it in experimental sciences. Nothing Andrew says will ever convince me otherwise.
Although preregistration with p-value based inference is a pretty pointless thing to do. Maybe that’s what Andrew means. One has to concede that his antipathy to p-values is very well founded. It’s the most ridiculous idea that psychology passed on to linguistics and cognitive science generally.
What I mean is, dump p-values but still pre-register!
Makes a lot of sense to me.
Shravan:
“Armchair statistician,” huh! That’s what I call trolling.
:). I was just being tongue in cheek. I think your armchair statisticianing has made a huge and positive difference in my and my lab members’ lives. We’ll never publish in Psychological Science or PNAS or the like, and will forever debate amongst ourselves the ambiguity of our findings, but thank god for that. Your work has sharpened our bullshit filters a great deal, and we are very grateful for that. And oh, did I mention Stan? We use nothing else when we get serious about our research problem.
I’m curious how you are using the expression “armchair statistician” The OED defines “armchair” as “amateur, non-professional; (hence) lacking or not involving practical or direct experience of a particular subject or activity”. Surely you’re not claiming that Andrew is an amateur statistician or that he doesn’t have practical or direct experience in statistical analysis. I imagine you are suggesting that he doesn’t direct or practical experience in the field of psychological experimentation, so “armchair statisticianing” is the act of statistically critiquing analyses in a field where one doesn’t have direct or practical experience. Is that what you mean? (I’ve heard armchair linguist used in a lot of different senses, some referring to people without training in linguistics, some referring to linguists who rely upon intuition rather than corpora or experiments for their data, so that reference doesn’t help me either).
The amateur and amateurish statisticians in this story are psychologists and linguistics, in other words, people like myself. Andrew is of course an authority, and I take everything he says seriously, but I think he’s wrong about pre-registration and speculate that this may have to do with his lack of direct experience with doing experiments.
Armchair linguists is a different topic, I will reply to that later.
No real need to respond about “armchair linguists” I’m more or less familiar with the issue :-). Generally, mine was an aside about the semantics of adjective-noun constructions. My default interpretation of the adjective “armchair” as in “armchair statisticians” is that it is privative: the denotation of “armchair statistician” is disjoint from the denotation of “statistician”: an armchair statistician isn’t really a statistician. (And it sounds like Andrew took it that was as well). I didn’t realise until your comment it could be intersective (at least I’ll take it that was until I consider more examples). But this is a statistics blog and not a linguistics blog, so sorry for the sidetrack.
For me, an armchair linguist is a perfectly legitimate linguist. In fact, one could argue that most of the important theoretical development in linguistics was done by using the Hey Sally methodology: you step out of office and call out to Sally, Hey Sally, do you find this sentence grammatical? In fact, in 2016, I would argue that the experimental linguist is mostly in the same position as the psychologist, chasing noise and p-hacking his way merrily through life. So I have recently developed a lot of respect for the armchair linguist. So I didn’t mean it pejoratively; I do realize people use “armchair linguistic” pejoratively, but these are just people with an entirely undeserved superiority complex.
I find this whole discussion funny and ironic. My understanding of linguistics is that the dominant understanding is that language is what people speaking the language create. And yet, here’s a linguist taking a well formed phrase “armchair X” and assigning it a different meaning than the dominant one. Which is simultaneously a creative act which demonstrates the theory, as well as a kind of denial of that theory at the same time.
@Daniel Lakeland
I don’t want to highjack the thread, but it’s not really demolishing linguistic theory. It just raises interesting questions about how we use/process adjective-noun constructions. You’re assuming that “armchair X” is used/understood as a fixed phrase, but that’s not necessarily the case. Shravan’s use of “armchair X” as non-perjorative isn’t capricious. Most adjective-noun constructions are understood intersectionally (a blue car is the intersection of the set of blue objects and the set of cars). So, in this reading, an “armchair statistician” would be the intersection of the set of, say, people theorising about a particular subject or activity without practical or direct experience of that field and the set of statistical analyses, in other words, a professional statistician who doesn’t have direct experience of doing psychological experiments, or a linguist theorising about a language that they haven’t done fieldwork on. Other adjective are non-subjective, like “fake leather” (which is privative: fake leather isn’t leather). And in the same way that typically a subsective adjective like wooden (wooden spoon) can have non-subsective uses (wooden lion), I suppose that a typically non-subjective adjective like “armchair” (for me at least) could have subsective uses. Again, sorry for the derailing . . .
Ouch! And I know this will add to the trolling and derailing :), but I cannot resist the urge.
I really don’t see how “armchair” could possibly be an adjective here. A modifier, for sure, but clearly of the nominal kind. Just like “coal” in “coal mine” or “air traffic” in “air traffic control.” Or else, would Sue think “This linguist is pretty armchair” or “A more armchair linguist than me” are grammatical?
@reader_not_academe:
Dude, you’re like… totally armchair.
This is the 3rd millenium, get with it, leave the slothful and timid to their sinking unregistered galleons.
The ‘floor/ceiling effect’ excuse for discarding data comes up a lot. I think that this is because many researchers can’t recognize anything beyond additive effects of their treatments/predictors.
P = 0.05 is supposed to result in a mistaken conclusion 1 in 20 times (all other things being equal, truly random, etc.). Now we have 17 studies, which is nearly 20. And one of them had p=.05 limits that led to an apparently mistaken conclusion. This seems right in line.
So we have here an excellent example of what p=.05 actually tells us – i.e., maybe something interesting but better check further because it could still be an effect of chance.
Of course, the fact that the odd man out happened to be the first one probably threw some people off.
I also notice that the result is written as “p < .05". That's a bad practice in itself: not giving the actual value. But from the graph we can see that .05 was pretty close – and the difference between .05 and the actual p value (what ever it was) isn't statistically significant anyway!)
But we don’t know he happened to be the first one; he was just the first that reported it. A dozen other people could have run quick studies looking at the same thing, found nothing, and not bothered publishing it. That’s the problem with publication bias.
+1
Why wouldn’t they just give both hard-to-read and easy-to-read questions to every student, and make a within-subject comparison? It’s an obvious source of variability that’s easy to eliminate.
It is very difficult to make people forget what answer they gave previously. Shock treatment might do it, but would interfere with cognitive performance.
It’s also terrible how hard it is to dispel this sort of stuff once it’s taken as gospel.
If anyone has read “The Smarter Screen” by Benartzi & Lehrer, they’ll surely remember how the book devotes something like 10 pages to the “upside of hard”, based largely around the original disfluent font studies.
They do, however, devote an entire paragraph (/s) to the Meyer et al. replication, saying the following:
“It’s worth pointing out, however, that not every study looking at disfluent fonts gets similar results. For reasons that remain unclear, many experiments have found little to no effect when counterintuitive math problems, such as those in the CRT, are printed in hard-to-read letters. While people take longer to answer these questions, this extra time doesn’t lead to higher scores. Clearly, more research is needed”
It’s a bit absurd – imagine applying the time-reversal heuristic to this. You first run 16 studies, with a total n of ~7000 (any sane person would have stopped before that point), and you find fairly conclusive evidence for no substantial difference. But on the 17th study, with 40 people and some creativity, you find a significant result!
Would anyone seriously see that and think “Oh, looks like the jury’s still out, need to do more research!”. No. But flip around the temporal ordering and make a story about it, and suddenly the evidence is balanced. Simply ridiculous.
Thinking Fast And Slow has been one of the most influential books I have read in a long time. But as fail replications accumulate I wonder if there is a point where I should stop taking it seriously.
Andrew: my reading of your posts is that you don’t take seriously most of NPR/TED/Gladwell. Is Kahneman’s work in the same bucket already? If not, is there a point where it will go in to that bucket? Which studies will have to be refuted to get to that point?
Andrew’s wording is a bit unclear: the disfluent font studies aren’t by Kahneman. Kahneman refers to them, perhaps without digging deeply into their methods (as I and I’m sure many others have also done).
I’m wondering the same myself now. Though, some of the studies in TFaS (the biases involved in stock trading) seem to have more support than others (like screen size), so maybe it’s a mixed bag? I’m curious to know what you think, Andrew.
Most of Kahneman’s work from Thinking Fast and Slow has been replicated hundreds of times over – largely because a lot of the phenomena were pretty groundbreaking (or at least, not well studied up until then), so he was examining large effects. The research to follow trying to uncover mechanism is probably where we are getting a lot of wishy-washy effects, mostly because the further down you go in examining why a particular effect exists, the smaller the effect size you should expect.
From a background in mathematics and natural sciences, that seems a very odd expectation. I would expect the opposite when you’re dealing with something real: the further you go in examining why a particular effect exists, the larger and more reliably reproducible the effect you can get.
If an effect exists in a population for 4 or 5 different reasons, then when you examine individuals for the existence of a particular reason, you could have say only 20% of them exhibiting it at all, but if you test for the overall effect without excluding any reasons, you could still see it almost 100% of the time, and larger because some of the reasons might exist at the same time providing some cumulative type strengthening of the effect.
However, once you’ve identified if a particular reason is active in a particular person or context you should be able to be more reliable with those subjects or in those contexts, otherwise you’re probably fooling yourself.
*font size, not screen size. My bad.
What are you saying about calling him a professor?
If making instructions hard to read/understand improves comprehension, then why is learning difficult? Concretely, here’s an example from Friday. We were driving north on 93 just past noon and some cars came flying by in the breakdown lane. My wife insisted they could because the signs said it was legal except between 3 and 7PM. She was insistent so I glanced at one as we went by and agreed … but that didn’t sit with me so I read the next one more carefully. The sign says “Driving in the breakdown lane / Prohibited/ Except between 3 – 7 PM weekdays”, with / indicating a line break. This should, per the garbage studies, make it easier to understand you can only drive in the breakdown lane between 3 & 7 weekdays, but it doesn’t, does it? My wife isn’t dumb but the way of writing the sign, which is in the legalese negative case, is misleading … which is obviously then better than saying “you can only drive in the breakdown lane between 3 & 7 PM weekdays” because clarity leads to misunderstanding!
To (foolishly) answer without having read the specific article: the CRT consists of questions that have an answer that seems obvious if read/responded to quickly but is incorrect. The bat and ball question referred to in the post is “A bat and ball cost $1.10 in total. The bat costs $1.00. How much does the ball cost?”
Many people have an immediate feeling that the answer is 10 cents, but this is wrong because then the bat would cost $1.10 and the total would be $1.20. The intuition behind the ‘hard to read’ manipulation is that if you force people to slow down and read the question, they will be more likely to actually reason through the problem instead of snapping off an answer (it’s actually 5 cents, which makes the bat $1.05 and gives the $1.10 total). The goal of the test is to measure people’s willingness and/or ability to engage in some deliberate thought, so the hard-to-read font manipulation would be useful if true because it would be a very easy way to prompt people to think carefully about what they’re reading.
Your example is different in that the signage is just confusingly written (why use the ‘prohibited except’ double negative?), especially when people are driving by at fast speed. There’s nothing about the situation that prompts slower or more considerate reading of the sign, so drivers are stuck hoping that they read and parse it properly in limited time.
I assume you mean: A bat and ball cost $1.10 in total. The bat costs $1.00 more than the ball. How much does the ball cost?
Yes, sorry for the typo.
“A bat and ball cost $1.10 in total. The bat costs $1.00. How much does the ball cost?”
Did you mean: “The bat costs $1.00 more than the ball.”
Because the way you wrote it I think the ball actually costs 10 cents. But I’m no psychologist, I’m just an economist.
Yes, sorry for the typo.
Not to venture off topic, but I was wondering if you mind commenting on bad analysis being done in the private sector. You’ve commented a lot of the crisis in science and lack of statistical training. I’d put forth that the problems are significantly worse in the private sector, be it in tech, marketing, insurance, etc industries. I never hear anyone comment on the ‘crisis’ of poor analysis in the private sector. As an example, I’ll not that I have had several colleagues who told me that they “doesn’t care if something is statistically valid or not”. So all in all, the crisis in science may not be that bad when you compare it what goes on in industry.
Tonym:
Yeah, I guess there’s lots of bad analysis in the private sector too, we just don’t see it because it’s private. Some companies will do internal reviews which can help them get some of the benefits of feedback, as long as they’re motivated to avoid getting wrong answers.
“all of us fail all the time”
This is so important. One example is the huge disconnect between people who code and those who do not. The former get reminded they are idiots multiple times a day due to dumb bugs. There no arguing against when your code fails to compile, while these psych/medical researchers can “explain away” any inconsistencies and never have to recognize this fact that they are in error constantly. Being right is hard, even if all the rules are made known beforehand.
A fairer comparison would be to silent failures in code that do not register any error. That’s more like what these non-coders experience, but coders experience it too. Obviously, since a coder may never realize they missed an error, they feel like they caught all of them through the error messages.
Good point, thanks. Maybe we could also include misleading, inaccurate, or just overly esoteric error messages. The point about thinking you caught them all just because you got called out on so many others is great though.