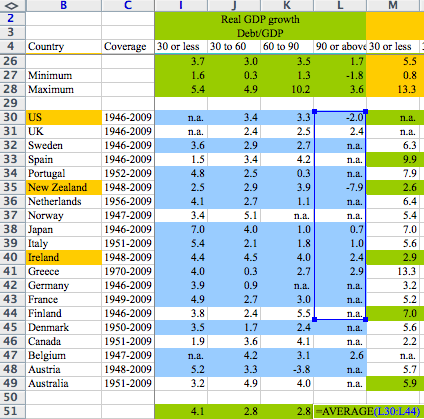
Jeff Ratto points me to this news article by Dean Baker reporting the work of three economists, Thomas Herndon, Michael Ash, and Robert Pollin, who found errors in a much-cited article by Carmen Reinhart and Kenneth Rogoff analyzing historical statistics of economic growth and public debt. Mike Konczal provides a clear summary; that’s where I got the above image.
Errors in data processing and data analysis
It turns out that Reinhart and Rogoff flubbed it. Herndon et al. write of “spreadsheet errors, omission of available data, weighting, and transcription.” The spreadsheet errors are the most embarrassing, but the other choices in data analysis seem pretty bad too. It can be tough to work with small datasets, so I have sympathy for Reinhart and Rogoff, but it does look like they were jumping to conclusions in their paper. Perhaps the urgency of the topic moved them to publish as fast as possible rather than carefully considering the impact of their data-analytic choices.
A disappointing response from Reinhart and Rogoff
Reinhart and Rogoff posted a response to the critique.
On the methodology, they do not deny any of the data and methodological errors pointed out by Herndon et al. I don’t know if that means they’ve known for awhile about these problems, or if they quickly checked and realized that, yeah, they’d screwed up the spreadsheets and, yeah, they did some funky averaging.
But they don’t admit anything either. As always, I find that sort of behavior annoying. It’s a step forward that they’re not denying it, but to not admit it—that’s just tacky.
And I speak as someone who’s made serious data errors myself, most notably in this retracted paper (background here).
In another case, I dodged a bullet by detecting a data error shortly before publication. (The story: “the problem was in the name of one party (the Popular Party)—it had an extra comma in its name and when we read in the data, we mistakenly counted it as a different party.”)
In yet another case, I posted (just on the blog, not in a publication) a set of maps that had problems, not from bad data but from poor assumptions in my statistical analysis (which, for me, is even more embarrassing). The criticisms came from an angry and somewhat uninformed blogger—but many of his points were correct! It took me some months to redo the analysis in a more reasonable way. But, before I did that, I engaged with the critics. I wrote things like:
I appreciate the careful scrutiny. One of my pet peeves is people assuming a number or graph is correct, just because it has been asserted. BorisG and Kos and others are doing a useful service by subjecting my maps to criticism.
Kos was not polite to me. But that’s not the point. Science isn’t about being polite. Herndon, Ash, and Pollin weren’t polite to Reinhart and Rogoff. So what.
I also wrote:
Because of the small sample size, I couldn’t just take the raw numbers. But I’m wiling to believe there are problems with the model, and I’m amenable to working to improve it.
and
I agree that the sharp color change of the map can make things look more dramatic than they really are.
and
Kos is right––there’s something wrong with my New Hamphire numbers. McCain only won 45% of the vote in New Hampshire, and the state is nearly 100% white, so clearly I am mistaken in giving him 50% of the vote in each income category. My guess as to what is happening here is that, with such a small sample size in the state, the model shifted the estimates over to what was happening in other states. This wasn’t a problem in my map of all voters, because i adjusted the total to the actual vote, but for the map of just whites it was a problem because my model didn’t “know” that New Hampshire was nearly all white. In the fuller model currently being fit by Yair [i.e., our recent AJPS paper!], this problem will be solved, because we’ll be averaging over population categories within each state.
In the meantime, though, yeah, I should’ve realized New Hampshire had a problem.
So, yeah, I think Reinhart and Rogoff should admit they have a problem too.
On to the substance
I don’t know anything about macroeconomics so all I can report here is what was written in the recent exchange. Here’s Reinhart and Rogoff defending themselves:
It is hard to see how one can interpret these [corrected] tables and individual country results as showing that public debt overhang over 90% is clearly benign.
But nobody claimed that! The words “clearly benign” are from Reinhart and Rogoff. What Herndon et al. actually wrote was:
The full extent of those errors transforms the reality of modestly diminished average GDP growth rates for countries carrying high levels of public debt into a false image that high public debt ratios inevitably entail sharp declines in GDP growth. Moreover, as we show, there is a wide range of GDP growth performances at every level of public debt among the 20 advanced economies that RR survey.
Herndon et al. don’t say that high debt is “clearly benign,” they say that it’s not inevitably bad. This is quite different. Reinhart and Rogoff have a real quantitative point to make—the point is that “modestly diminished average GDP growth rates” can be a big deal. “Modest” sounds like no big whoop but it can matter a lot when you’re talking about a big economy. But, hey, don’t make a straw man and say that they’re talking about “clearly benign.” What’s the point of that??
Uh oh
Between this and the notorious “Out of Africa” paper, it hasn’t been such a good year for the American Economic Review. And it’s still only April! This is almost as embarrassing as when Statistical Science published that Bible Code paper back in 1994.
Here’s more from Tyler Cowen and Paul Krugman. I haven’t looked at the data myself so I can’t offer any informed statistical commentary, but not a single person in the discussion seems to be denying that Reinhart and Rogoff messed up with their data, so I assume this actually happened. Which makes it even seem even more awkward that they didn’t directly admit it.
In summary
Reinhart and Rogoff may have a point that the corrections to their analyses have little practical import, merely reducing the magnitude of their claim without changing its sign. Maybe Konczal is overstating it when he writes, “one of the core empirical points providing the intellectual foundation for the global move to austerity in the early 2010s was based on someone accidentally not updating a row formula in Excel.” I have no informed opinion on that at all. Really. I’m not being polite and circumspect, I know nothing about this stuff.
But unless they want to enter the competition for the lamest, grudgingest, non-retraction retraction ever, I recommend they start by admitting their error and then going on from there. I think they should also thank Herndon, Ash, and Pollin for finding multiple errors in their paper. Admit it and move forward. (That’s something we’ve been saying a lot here lately.)
P.S. But I don’t want to be too hard on Reinhart and Rogoff. As a statistician, I’m acutely aware of the potential for error in myself as well as others, but I don’t think researchers in other fields get this sort of training. And of course I have decades of experience making research errors of different degrees of seriousness. Reinhart and Rogoff may well have been closer to error-free in the past. Also, this is a high-profile case and their immediate response was defensive. Had this happened to me, I might have reacted the same way (especially if I didn’t already have many previous experiences of admitting error). I hope that, tomorrow or sometime soon, Reinhart and Rogoff will admit their mistakes, profusely thank their critics, and move on.
I thought the important points were more important than coding. First is the exclusion of certain years from some countries while those same years were included for others. I’ve seen rationales offered that this would make sense to handle high post-war debt loads but they start in 1945 for Great Britain and only pick up New Zealand (I think) in 1951 when there was a quick recession after years of growth. So that’s a data exclusion choice which needs to be explained.
More damning on a rational basis is the weighting by country. The entire point was how economies function under high debt load so it makes sense to look at how a country has functioned for more than 1 year under their qualifying high debt threshold. They instead weighted by country. So for example this means they took 19 years of Great Britain, took a single average, and weighted that the same as one year of New Zealand. And that one year of New Zealand comes after they’ve excluded the previous years of growth. So the 19 years of growth under high debt load are put in a bag with one year of negative growth. If that isn’t bad work, what is it?
The coding errors amount to tiny piece of the whole.
Jonathan:
Yes, I agree. As I wrote, the spreadsheet errors are the most embarrassing, but the other choices in data analysis seem pretty bad too.
Reinhart and Rogoff might still might be right that a correct analysis of these data, along with a full accounting of the rest of the literature, won’t change their conclusions much. But I’d much prefer for them to make that argument after acknowledging their serious errors.
So, they basically used ‘episodes’ rather than years, didn’t explain that, and didn’t run even a simple sensitivity analysis (e.g., using each country-year as a single data point) to see how that affected their results?
Turns out it’s actually worse if you’re interested at all in honesty: they now say they didn’t include the earlier years for New Zealand because they had not yet determined if it was accurate or not. First, nothing was stopping them from doing that work before presenting their paper or at the very least saying that additional data might be coming. Second and worse, they’ve had years to redo their work and they’ve given a substantial number of talks, written about this work and even spoke to a group of senators about this … and they didn’t make a peep about data they now say they knew about. That’s really bad.
Wait a second. Am I to assume they did the data collection, management and analysis in Excel?! What part did Excel play in this work?
(I know nothing about econometrics and did not read the paper)
Excel is bad but I would not jump to the conclusion Stata or R is better. That is an empirical question, and I am sure there is a lot of heterogeneity.
For example, these are more powerful tools, less transparent to the uninitiated, and therefore capable of untold damage.
But, contrary to Excel, they do leave a paper trail, including the code itself and the log of the session.
PS I have replicated another highly cited empirical paper implemented with Stata and found many errors. It is an open question whether there would have been more or less errors if done in Excel.
PPS Just to be clear, I am not defending Excel just being skeptical of a one-size-fits-all solution or jumping to conclusions.
They have a total of 1175 data points (country-years) divided into 4 categories, and their analysis is limited to calculating the mean and the median in each category. I don’t know much about R or Stata, but it seems to me that anything more than Excel would be overkill here.
In R (or any procedural language, really), it’s easy and natural to write code in such a way that adding points to the data set requires no change in the actual analysis code. In Excel, adding data often requires changes to formulae that calculate the results. (I’ve done both.)
While Excel is not the tool one should choose for data analysis, it’s missing the point to think that processing errors are non-existent if one uses R or Stata or SAS or any other language. The probability that a given data analyst will make a processing error is 1. The more careful analyst can reduce the error rate but it will never be zero. The observed error rate might be zero but that is a diagnosis problem. If one switches from a GUI to a coding platform, the processing errors materialize as software bugs. That happens with probability 1 too.
From a data analytic perspective, I don’t understand why we should even bother with this type of analysis where there is no attempt to set up controls. If you have a theory, and you go look for data to support it, you will find the data. If I take the inverse of your theory, I will be able to find data to support that too. I suppose this is why Freakonomics was such a big deal in economics – it’s an attempt to locate data that is amenable to being analyzed as test v. control.
“Probability 1” is an exaggeration but it’s true that I often have some coding errors (in R) and I’m sure I sometimes never find them. I’ve taken note of some specific types of errors that I’m prone to making, and I have made some changes in the way I work to try to improve my performance. In fact…hmm, yeah, I am going to start another post on data coding errors, and methods for reducing them, and try to collect some comments. I have my own foibles and my own fixes but I’m probably missing out on some really good ideas.
I took a look at R. At the core level, it’s not unlike Python, with which I am familiar. If that is the case, doing this analysis in R instead of Excel would prevent the silly data-loss error, but would expose the user (especially one inexperienced with R) to the risk of 10 other less visible coding bugs.
Interestingly, Herndon/Ash/Pollin did do their analysis in R.
It looks to me like the error that the analyst introduced IS a function of using Excel instead of a statistical software package. In any stat software, the formulas are applied to the entire column. In a spreadsheet, the cells are independent of each other: that’s how some rows in the highlighted column were accidentally computed from a different formula that others. This could not happen in Stata or any other stat software. I see a lot of errors like this in Excel analyses.
If it isn’t their biggest problem, then they were just lucky. It certainly could have been. The real issue is that so many researchers just don’t know how to analyze data. This story is the tip of an iceberg of shoddy data analysis. Statistics education concentrates on concepts and petty much ignores data analysis. Why?
Sorry, I strongly have to dissent. Have you ever used array formula in Excel? I think no. Because from the point of view that “the formulas are applied to the entire column” Excel is perfectly equivalent to any other stat software.
FWIW, AER Papers and Proceedings is rather different from the AER.
R&R don’t help things when they keep calling it an AER paper.
I would give them credit for making the code and data available so that the EXCEL error could be found by an independent group of researchers. That being said, the more I see the economics policy people talk about this paper, the more central the paper seems to have been to economic decision making. The size of the effect seems directly relevant to decisions to cut government spending in a period of high unemployment (just like the Laffer curve may be correct but it matters a lot if revenue maxes out at 5% of income being taxed or 67%).
In terms of a field’s likelihood to issue retractions, I do try to train epidemiologists to do this and I do live in fear for the day that I need to do a retraction or admit to an error. It makes me check results very carefully.
+1
I’d like to see how many researchers expose themselves to such criticism. Uploading a raw dataset is one thing but allowing people to see all your intermediate calculations in messy detail is rare.
There’s enough criticism of errors but not enough of the legions of “data hiders” out there.
Rahul:
I agree. Here’s my article slamming some people who refused to share their data with me. It happened 25 years ago and I’m still annoyed.
I’ve been writing about people who refused to share data withe me as well (https://politicalsciencereplication.wordpress.com/2013/01/03/replication-frustration-in-political-science) and I’m regularly publishing anonymized email answers to my replication data requests. It’s amazing how many people have to ‘dig up’ their data, ‘clean’ their data, or are ‘traveling’ and will get back to me later (never). My students in our replication workshop had similar experiences…
Absolutely an outrage and these people deserve to be shamed into submission. One question I have to those of you privileged enough to be on journal editorial boards or on NSF Funding Committees: Why don’t you take a stronger stand about data dissemination. Require submission of all code and raw data before you will even review an article.
This problem won’t solve itself. It needs more pressure to resolve.
In natural sciences it is the norm that journals require a data upload with (!) submission: For example, Science and Nature require authors to deposit their data first, and then submit the ‘accession number’ of that record together with the paper draft (https://www.sciencemag.org/site/feature/contribinfo/prep/gen_info.xhtml#dataavail and https://www.nature.com/nature/authors/gta/).
For political science journals, the policies are less strict (if they have a policy at all!). AJPS’ policy: “If a manuscript is accepted for publication, the manuscript will not be published unless the first footnote explicitly states where the data used in the study can be obtained” (https://www.ajps.org/manu_guides.html)
APSR’s policy: “You must normally indicate both where (online) you will deposit the information that is necessary to reproduce the numerical results and when that information will be posted (such as “on publication” or “by [definite date]”).” https://www.apsanet.org/content_43805.cfm?navID=264
The reason people aren’t giving them credit for making the code and data available now is that it’s taken 3 years.
Prof Bill Mitchell says:
“I should note that when the paper came out in 2010, I immediately tried to replicate the results and failed. I wrote to Carmen Reinhart because I had met her a few years earlier at a function in the US. I requested the data. It appears I was in a queue of researchers asking for the data. I received no reply.”
https://bilbo.economicoutlook.net/blog/?p=23467
Since publication it has been cited an impressive number of times and used as definitive justification for savage cuts by politicians. The faulty source material would have been best released up front, and certainly on request shortly after publication.
And if they had set it up in Excel properly (using README sheets and in-cell comments explaining formulae and data sources), then simply posting that workbook on their website would have allowed everybody to check their work.
It took them three years to do so, after numerous researchers had failed to replicate their results, and asked for the data.
In my opinion, the biggest thing that should attract statistician’s attention is not just coding and transcription errors. It’s the fact that R&R and HAP arrive at radically different results because HAP use the full data set and R&R accidentally lose some data points at random.
This by itself is a huge red flag. If you can go from 1.6% GDP growth to -0.1% GDP growth by losing some data points, your data set is too small to make any conclusions at all! Proper statistical analysis would involve calculating the growth estimate as well as error bars. And you’d immediately see that error bars are so wide the growth estimate has no predictive value.
I took a look at the original paper and at the debunking and I don’t see any error bars in either paper.
I took the data and tried to recalculate results and confidence intervals. And the results are (drumroll):
for countries with debt to GDP ratio under 30%, mean annual GDP growth is 4.2% (95% CI: -1.4% to 9.8%)
for countries with debt to GDP ratio over 90%, mean annual GDP growth is 2.2% (95% CI: -4.7% to 9.0%)
clearly, there’s no predictive value here. Original R-R estimate of -0.1% for the second category is well within the confidence interval, as expected.
Strike that. Forgot to divide by sqrt(n) (d’oh!) Should be 3.9% to 4.4% and 1.5% to 2.8%. That’s a different story.
Now I think that it’s going to work one way only. Since R-R did averaging in two steps, they have a small number of points and a wide confidence interval. HAP estimate should be within R-R confidence interval, but not the other way around.
I know that you were being somewhat tongue in cheek about this being a bad year for the AER, but I’ve read the same sentiment elsewhere, and I think that’s being a little unfair to the journal. Although this was technically published in the AER, it was the “papers and proceedings” May issue of the AER; those papers are a selection of short writeups of talks given at the annual meetings in January and are meant to stimulate debate rather than being the definitive answer to a research question. Also, papers in that issue aren’t subject to the same level of referee scrutiny as papers in other issues of the journal because, again, they’re conference proceedings.
The papers are still expected to not contain errors, though.
Gray:
I had no idea about this “papers and proceedings” thing. Reinhart and Rogoff referred to “the AER paper,” and I had no idea that the journal had differently-reviewed subsets.
In any case, though, I don’t know that these sorts of errors would be caught by reviewers. Correctness of results is generally considered to be the responsibility of the authors, not the journals, and referees typically don’t go back to the raw data.
It definitely would be tough for a referee to catch this sort of error, but hopefully addressing the referee’s questions would make it more likely for the authors to catch the error on their own (a very optimistic view, I know). I assume that R&R would have had to spell out their weighting scheme and other conscious decisions that the critique highlights, which would have helped. In any case, the AER has a data and code release policy for regular submissions (https://www.aeaweb.org/aer/data.php), so these errors would almost certainly have been caught much earlier.
@Gary:
I think this practice by journals of having “lightly reviewed” papers should be frowned upon. Often it is very hard to know these were un-refereed especially when the land up in search engines etc.
They have now admitted the Excel error flatly, though they continue to defend the spirit of the result and the other issues. https://blogs.ft.com/ftdata/2013/04/17/the-reinhart-rogoff-response-i/ “On the first point, we reiterate that Herndon, Ash and Pollin accurately point out the coding error that omits several countries from the averages in figure 2. Full stop. HAP are on point. The authors show our accidental omission has a fairly marginal effect on the 0-to-90-per-cent buckets in figure 2. However, it leads to a notable change in the average growth rate for the over-90-per-cent debt group. The median growth rate we report is the right order of magnitude.”
A real WTF answer. Since the growth rates were all within an order of magnitude of each other (4.something to -0.2) in the original paper. Are these clowns claiming that the growth rates might have been >40%?
Andrew,
The paper wasn’t published in AER. It appeared in AER Papers and Proceedings. That issue is put out each year in May from the annual AEA meetings. It is not peer reviewed, does not count towards publications for tenure, for example.
Given the risk of forced disclosure of some or all raw data the _always deny any flaws_ culture may recede.
It’s likely learned through many years of mentoring and keeping upper management (Deans) happy.
I was very lucky. My first venture in doing research was with https://en.wikipedia.org/wiki/James_Fleck doing the analysis for Canada Can Compete! He insisted that the analysis be fully programed and documented so that someone not involved could redo the calculations and also change the data and simply rerun to get an update. He supported and rewarded the effort to do that.
Then I worked for this guy https://en.wikipedia.org/wiki/Allan_Detsky . He provided me with _his_ rules to follow – such as not analysing any data until it had been entered twice and I did the comparison and to not share analysis results until one day after the work had been completed and re-checked. The value of that is that no one complained about _me_ doing this no matter how much of a hurry they were in. Recently, when he obtained data during SARs epidemic in Toronto that the world was anxious to hear about, he insisted the research fellow enter all the data twice before doing any analysis at all.
My sense is that few who manage research, understand the value of such carefulness (they both were Economists).
But with increasing forced raw data exposure, folks may quickly learn about that value.
But, but Andrew’s challenge remains – how to encourage folks to thank people for finding their errors, admit them and especially move on to being less wrong (and being exposed to further inevitable correction).
Keith:
“Risk of forced disclosure”—that’s a good way to put it.
As someone from Europe I have to admit to your discussion that something like this paper is used as an often cited justification for playing the austerity card on depted countries with really devastating effects – as we can directly observe here in real life (see for example The Lancet – “Health in Europe” series, published on May the 27th, 2013, https://dx.doi.org/10.1016/).
So, besides of your discussion regarding the question of how the errors in the paper add up to change the reported results, the style they present in admitting (or not, as Andrew says) are the most cruel part in the whole thing for me: A correction would change the results especially for the “90-percent” category, but this is the most tortured group of countries here in Europe. Accordingly, this “little” error may have supported the real world measures that are totally wring. So, when they just do not admit to being false, then it will not help in making the public aware of the implications of their error. For me it’s something like “Alas! There was an error, yes! But okay, it doesn’t change any substantial thing, n.p.! Go ahead and do the same wrong political decision again!”
So, my point is (sorry for beating around the bush), that Konczal is not overstating it at all. He should yell about this even more extreme and so loud as he can, because otherwise we will just not even see a little note in the newspapers like “There maybe was a little coding error, but that does not change the fundamental accuracy of how we deal with these economies here around Europe…this is stated by the experts!”.
Because this here is a thing that reaches out in its consequences far wider than a “normal” research issue, it needs a (maybe polemic) non-research commentary…getting my point?
P.S. And thank you very much for the effort in writing your blog: a good read every time.
P.P.S. The doi-link did not work, sorry for that. Here it is:
https://www.thelancet.com/series/health-in-europe
IF the Excel error was caused by not dragging the range of cells used to calculate the mean/median etc., to me is not just embarrassing, it’s frightening, regardless of the magnitude of error this may have caused. How likely would the very same error have occurred in more statistically appropriate software (no reference to SAS intended)? As we know it is extremely unlikely, with the added benefit of making the authors think even more about those missing values.
I just don’t subscribe to the thought that, given the simplicity of the analysis, anything other than Excel would have been overkill. The authors are not undergraduate students trying to figure out how to do an assignment. More appropriate tools exist and ought to be used.
Thomas:
The redprodicible work I did for Fleck was done in Lotus-123 circa 1985.
Assuming Excel is now as functional, it not the software but how its used and documented.
(Agree that pointing, clicking and copying are hazardous ways to do things.)
Paul Krugman seems to agree with you about the hazards of EXCEL
https://krugman.blogs.nytimes.com/2013/04/17/further-further-thoughts-on-death-by-excel/
SAS has a lot of bad press (some deserved) but it has great documentation properties (the log files for example often provide very clear clues to errors). Unfortunately, even among my own students, there seems to be a culture of “never look at the log files” that I really don’t understand (as they are one of the few actual reasons one might choose to use SAS instead of R).
Lots of Jonathans here.
I want to emphasize that there are two substantive problems. The first is the weighting by country and the second is the omission of years of data. If you read the UMass paper, if you add in the missing years and don’t reweight, meaning you do this as R&R did, their findings essentially disappear. That really bothers me. It creates a suspicion, true or not, that they cheated on the data to get the results they wanted. There is no known reason, for example, to exclude years from New Zealand and then include 1 year when the economy did badly. It looks bluntly like they left out those years because they showed growth and with equal weighting for countries the negative year for New Zealand, well, here’s the paper: “In the case of New Zealand, instead of constituting 5 of 110 country-years at 2.6 percent growth, the country contributes -7.9 percent growth for a full 14.3 percent (one-seventh) of the RR’s GDP growth estimate for the above 90 percent public debt/GDP grouping.”
I’m disturbed that in their new response, Reinhart and Rogoff omit the emphasis that their papers were concerned with “associations” and not “causality”. When their papers are used by politicians and pundits for real world policy prescriptions like austerity, they really ought to to make sure their papers are being interpreted correctly. I think they like the press.
You may want to update with their more detailed response:
https://www.huffingtonpost.com/mark-gongloff/reinhart-rogoff-research-response_b_3099185.html
Policy makers might not change their view of austerity measures after this, but they will have to cite another paper as justification and answer criticism more carefully.
Among researchers and journals the value and possible impact of replication will hopefully be recognized more than before. Let’s not forget, a recent study found that out of 120 political science journals only 18 had a data sharing/replication policy… (https://wp.me/p315fp-aC).
Without replication, economics, political science and policy makers might base their decisions and work on wrong results – even if it’s just because of an excel error.
I’ve been trying to push for more replication, data sharing and integration of replication into methods training on https://politicalsciencereplication.wordpress.com.
Pingback: Replication scandal: We might not need austerity measures after all | Political Science Replication
Here is a comment on another problematic economic paper
www-personal.umich.edu/~albouy/AJRreinvestigation/AJRrev.pdf
The paper is/was supposed to provide some empirical justification to the popular book “Why nations fail”.
Steven “Freakonomics” Levitt based the most celebrated part of his bestseller, his abortion cut crime theory, on one or two simple coding screw-ups he’d made. He followed the strategy of absolute minimal apology and it worked well for his career.
https://online.wsj.com/public/article/SB113314261192407815-7O0CuSR0RArhWpc9pxaKd_paZU0_20051228.html?mod=tff_article
Pingback: An argument for why careful coding in R is better than an Excel spreadsheet | Sam Clifford
Pingback: Eye of Siva » Reinhart and Rogoff get pasted
“It’s a poor craftsmen who blames his tools.” It’s not fair, I don’t think, to blame these mistakes on Excel.
I can’t really weigh in on their mistakes in economics data formulation because it’s not really my field. That said, this is a problem that extends outside the field of economics and is prevalent within academic research at large. We have a terrible relationship between real research and the media. It’s no longer good enough to make a small, but important impact in your field; no, you have to make to change a paradigm, you have to be published in a top journal, and you have to be controversial. There’s so much pressure to publish something so big and significant that I understand why, when faced with their own errors, Reinhart and Rogoff immediately reacted defensively. Don’t get me wrong, I’m not trying to excuse their negligence, but I think when you’ve turned research into market (and turn researches into celebrities), bad research necessarily follows.
You misunderstand the expression. It’s a poor craftsman who blames his tools because part of the craftsman’s job is to own, maintain, and select a high enough quality tool. It’s totally fair to criticize someone for using the wrong tool. What if they’d done the calculations by hand on paper? Is that still beyond criticism?
I remember in my elementary matrix algebra class some years ago, we had to perform Guassian elimination by hand. After the first test, it became clear to me I wasn’t paying close enough attention to my operations. Sometimes, if I wrote down a number too quickly, my hand would “skip” on the sheet of paper and make it appear as if I wrote a negative number. Imagine if I told my professor, “it’s not my fault, my paper isn’t rough enough to provide the adequate friction to perform these operations.” Or: “My pencil breaks off too much graphite, which makes my mistakes too hard to detect.” Or even: “My calculator’s buttons are too close. I can’t help fat fingering operations.” Even if could show that the pen, paper, and calculator actually contributed to my making mistakes, do you think my professor would (or should) care? Let me put it to you this way: What IF Reinhart and Rogoff had used only pen and paper? Should we blame BIC for making a pen unsuitable for analysis? Should we blame Mead for making unsuitable paper? I don’t think so. Reinhart and Rogoff’s analysis was faulty because they were inattentive. That’s not Excel’s fault.
JPMorgan, according to their internal review, knew the potential for error in the Excel model that ultimately became the London Whale scandal. Managers had even recommended that the model be automated and audited, but never followed through. Why not? Why wasn’t the model thoroughly tested when it provided results that appeared counterintuitive? Because they liked the model’s results and its potential for big returns.
Reinhart and Rogoff—what makes them so different? Are we expected to believe that Excel is responsible for their not rigorously unpacking and verifying their data and model? To me, a more reasonable answer is they really liked their results; and their reviewers really liked their results; and economists looking for more ammunition against government spending loved their results. Their results meant big impact.
That’s my thesis: there’s too much pressure to make an impression, to be different, to be sensational. We’re less likely to be skeptical of work that plays on our own confirmation biases, especially if it’s going to be huge. That same sensationalism, by the way, is behind the blame-excel bandwagon. Here are some headlines: “Quote of the day: Excel error destroys the world” from Mother Jones; “Microsoft Excel: the ruiner of Global Economies?” from arstechnica. To me, blaming Excel feels like more causation creep. Sure, Excel was used both by JPMorgan and Reinhart and Rogoff—but so what?
Jordan’s right. As a person who has modelled plenty of stuff (economics, but microeconomics) in Excel, SAS, Stata and R I reckon it’s nonsense to blame Excel. You can do things at least as rigorously in Excel as in the others, but only if you care about rigour. Excel actually provides better tools for input data validation, debugging and auditing than the others. But you have to use these tools!
This sloppiness (or worse – cherrypicking data to that extent is frankly dishonest) in the service of personally convenient conclusions, combined with their attitude to data access and their downright equivocation once their errors were picked up, ought to see these people forced to change profession. But of course it won’t – they’re far too respectable and senior for that. Likely the most we can hope for is that the AER stops publishing unreviewed conference proceedings.
Interesting comment by J.Hamilton (Economist/Time Series Econometrician):
“…for any level of the interest rate, a higher debt load means that the government will permanently need to spend more money just to pay the interest on the debt. This is not a matter for arcane debate, but rather is a consequence of the most basic arithmetic.”
“Higher taxes will be needed to make those higher interest payments, and the adverse economic consequences associated with distortionary taxes are well understood. Moreover, as the debt load gets larger, the government’s creditors usually start to require a higher interest rate, which makes the interest burden of the debt even bigger. This creates a potential adverse feedback loop that can lead (and in many unfortunate historical cases, has led) to a major funding crisis. That higher debt loads are associated with higher interest rates has been found by many different researchers using many different data sets and methodologies.”
“The recent critique by Herndon, Ash, and Pollin (2013) did not discuss either of these first two claims. Instead, their critique concerns Reinhart and Rogoff’s analysis of a third data set, a panel of 20 advanced economies over the last half-century.”
” First, they found a dumb error in Reinhart and Rogoff’s spreadsheet– Reinhart and Rogoff left the first 5 countries in the alphabet (Australia, Austria, Belgium, Canada, and Denmark) out of the set of cells selected for averaging. This is a numbskull error, but it turns out it would only have changed the estimate they reported by a few tenths of a percent.”
“One view one could take is that the expected growth rate when a country has a high debt level is a single number across all countries… Another view you could take is that the expected growth rates for the U.S. and Greece would be different even if the two countries had the same debt levels…The optimal statistical estimate from that perspective would be somewhere in between the Reinhart-Rogoff number and the Herndon-Ash-Pollin number.”
https://www.econbrowser.com/archives/2013/04/reinhartrogoff.html
No, Epanechnikov, its not simple arithmetic because the Debt-to-GDP ratio has a denominator as well as a numerator. If cutting spending in order to reduce the amount of debt causes lower growth in GDP then it is quite possible for such cuts to WORSEN the ratio – read the recent DeLong-Summers paper for calculations of the circumstances in which this can happen. Unless we can demonstrate that they are approaching a debt threshold at which future growth slows dramatically then it is quite clear from these calculations that many (though far from all) countries should be spending more, not less, at the moment if they’re worried about the debt-to-GDP ratio (let alone less esoteric things such as, say, keeping their people in jobs).
This is exactly the reason why the precise causal links between debt and GDP growth is so important, and why we are entitled to be furious at the sloppiness, rising to the level of borderline fraud, of R & R.
My impression is that Hamilton refers to the Debt/GDP ratio hence the denominator is taken into account. And yes cutting public spending will most likely reduce the national product in the short-term. Whether it will reduce it more or less than the debt reduction (and how this would affect the economy on the long-term) is another question. But the Debt/GDP ratio can be decreased by increasing spending too. It all depends on what is the money being spent on. Furthermore from what I’ve understood from the discussion the R-R article does not imply much about whether a country should or should not attempt to reduce the ratio in the short-term by cutting spending. It just claims that ceteris-paribus having a high Debt/GDP ratio may harm your economy’s long-term growth (due to spending significant resources to serve the debt rather than financing public investments). However higher order terms (rates of change, volatilities etc.) as well as other variables are not taken into account in the paper and thus I can not see any obvious short-term policy implications. Finally yes it seems most economies should be spending more at the moment. However some shouldn’t and others can’t (Greece for example). But Hamilton’s comment seems perfectly credible to me.
Pingback: Major screw-up in economics, and what it means for ecology | Dynamic Ecology
Pingback: Philip Pilkington: Defrocking Reinhart and Rogoff – Controversy Ignores Fundamental Issues in the Use and Abuse of Statistical Studies « naked capitalism « olduvaiblog
Pingback: Excel | La Ruta Inconsciente
Pingback: la truffa del debito | sei-uno-zero-nove
Pingback: Spreadsheets and Economics | Quantum Tunnel
Pingback: Rapide retour sur Reinhart et Rogoff | Polit’bistro : des politiques, du café