Russ Lyons points to an excellent article on statistical experimentation by Ron Kohavi, Alex Deng, Brian Frasca, Roger Longbotham, Toby Walker, Ya Xu, a group of software engineers (I presume) at Microsoft. Kohavi et al. write:
Online controlled experiments are often utilized to make data-driven decisions at Amazon, Microsoft . . . deployment and mining of online controlled experiments at scale—thousands of experiments now—has taught us many lessons.
The paper is well written and has excellent examples (unfortunately the substantive topics are unexciting things like clicks and revenue per user, but the general principles remain important). The ideas will be familiar to anyone with experience in practical statistics but don’t always make it into textbooks or courses, so I think many people could learn a lot from this article. I was disappointed that they didn’t cite much of the statistics literature—not even the classic Box, Hunter, and Hunter book on industrial experimentation—but that’s probably because most of the statistics literature is so theoretical.
Several of their examples rung true for me; for example this pair of graphs which illustrates how people can be fooled by “statistically significant” or “nearly significant” results:
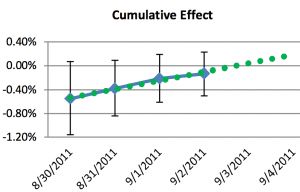
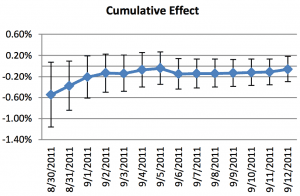
The graphs aren’t so pretty but I guess that’s what happens when you work for Microsoft and you have to do all your graphs in Excel . . . anyway, this sort of thing is what’s behind problems like the notorious sex-ratio study. And their point about autocorrelation of cumulative averages reminded me of the “55,000 residents desperately need your help!” study that was featured in my book with Jennifer.
I was impressed that this group of people, working for just a short period of time, came up with and recognized several problems that it took me many years to notice. Working on real problems, and trying to get real answers, that seems to make a real difference (or so I claim without any controlled study!). The motivations are much different in social science academia where the goal is to get statistical significance, publish papers, and establish a name for yourself via new and counterintuitive findings. All of that is pretty much a recipe for wild goose chases.
P.S. Sorry, they do cite Box, Hunter, and Hunter—I’d missed that!
I found interesting the carryover effect. At one level it is simply a spillover but the issue is that these effects may interact with subsequent treatment so it matters whether the experiment is carried out in a system at equilibrium or not.
Take Africa as an example. Many field experiments are being carried out in Africa so maybe what we are learning are the effects of interventions when many overlapping experiments are being carried out. That may or may not be interesting but it strikes me as asking Nature to reveal her softly spoken secrets in a very loud bar.
Ditto for online subjects: Bing’s subjects might also be Google’s.
I think it’s easy to overstate the presence and importance of field experiments, or development work in general, in Africa. We hear a lot about it since that’s what lots of Westerners are doing on the continent, and it gives you this sense that people who live in Africa are constantly bombarded by experiments. It is true that there are weird and noticeable effects in some areas – high-skill labor markets function strangely since the best jobs are all in development and/or surveys. There are also lots of signs with the names of organizations in certain places.
But for the most part, in people’s actual lives, experiments and development aid are of very minor importance. I’ve had people who run major, multi-million dollar village development initiatives tell me not to bother visiting their villages unless I’m on a guided tour or there’s an event going on, because I wouldn’t see any difference from the surrounding area. Looking at the numbers gives a similar picture: total US foreign aid to Africa was $7.8 billion in 2012, which is a bit less than $9 per African. Even for people living on a dollar a day, that’s a tiny fraction of annual income. So if you run a targeted experiment in a given area, especially if it’s a very cost-effective intervention, it’s not hard to distinguish from the background noise.
“Working on real problems…”
I’m sure this comes as no surprise!
As I recall, you have worked some in an industrial R&D lab that had some interest in statistics.
I’d certainly agree that statistics in corporations is very different.
In many cases, the issues are:
1) Making a decision based on the best analysis of the data available at the time.
Or
2) Sometimes, deciding that the decision can be deferred until more data were available.
OR
3) Deciding that adequate data was not endemically not available, and allocating resources to improve that,
Building 5 at BTL, MH, certainly did a lot of this.
In the 1980s, microprocessor architecture became much more quantitative, but sometimes we had to do 1), because we had to freeze a design, and while differences between designs might not be statistically significant, we had to choose.
Likewise, I’ve been in lots of board meetings.
Somehow, I don’t recall p-values being discussed :-)
Thanks for the heads-up. Looks interesting.
FYI, Box, Hunter and Hunter is reference #10 (Statistics for Experimenters: Design, Innovation and Discovery, 2nd edition).
“We present our learnings”
I thought it was a joke paper when I read that in the abstract. Skimmed through, looks legit, I’ll be sure to read it.
Link doesn’t seem to work. Do you have the title to google for?
i think if you go here
https://robotics.stanford.edu/~ronnyk/ronnyk-bib.html
and click on the second paper in the publication list
PS: I thought that for excel graphs they looked darnded good, altho that is like batting 400 in triple A
Single-A, maybe.
Cool paper and the graphs are good enough.
I’m glad to see “Fail fast” has finally sunk in. When I first starting talks saying thatt 35 years back, people were freaked out.
I PERSONALLY believe that one possible issue with traditional statistical philosophy lies in the concept of population. On the one hand, the true spirit of statistical science is “conditional-on.” On the other hand, “population” is universally accepted by both statistical researchers and practitioners as an unconditional concept: whenever we conduct a study, our default assumption is that there is a pre-existing data population. And, observed data is randomly selected from the static population. But, this theoretical assumption seems to disconnect with the real world in that the real-world data population is well conditional on which data generating process raises it. That is the take-home message I can (again, personally) get and confirm from this paper.
Our point of view on population conditional on data generating process is detailed in the following paper
https://onlinelibrary.wiley.com/doi/10.1111/j.1467-9639.2012.00524.x/pdf
it seems the lesson here is that field specific knowledge is required in order for experimentation and inference to be done well. an expert experimenter then is tied to their field and does not have general purpose tools beyond the pretty generic principles of good design. For Experiments 1 & 2: it is hard to generalize what they found beyond their domain other the lesson that one should be vigilant for threats to construct validity in your measurements and your manipulations. Not much here, but it does seem you have to learn the hard way unless you have a really good theoretical understanding of the behavior of your experimental units. For Experiment 3: okay, regression to the mean can make a trend illusory, and treatment effects can be temporary, this is textbook stuff, I see no reason why they should have to learn the hard way on this one. For Experiment 4: when the support of a random variable’s distribution grows over time, why would you expect CIs to narrow? this should only be a surprise for someone who starts with the tools, if one starts with the problem this will be an obvious consideration, no? For Experiment 5: yes, okay, re-using subjects can invalidate results… the mitigation is rather straightforward, no discovery here. I guess I don’t understand what is special about this report other than getting to see what people do at these internet companies?
Josh:
I’m not saying it’s a great research paper. I’m saying it’s a great expository paper. That’s why I think everyone should read it. You describe this as “textbook stuff,” but have you looked carefully at a statistics or research methods textbook lately? These books tend to be full of formulas but not such a clear sense of what experimentation is really like.
Andrew-
I was hoping to be changed, I see now you didn’t sell it that way. I agree that the examples are good, surprisingly good given my lack of interest in their subject. I guess that is because the inferences actually have to work in the real world. As far as research methods textbooks, the Cook, Shadish and Campbell seems to cover all bases, if you can get through the dry, mind-numbing categorizing and repetitive exposition. I haven’t seen a textbook that gives many examples of mistakes and bad design in a useful way, they usually list “validity threats” with one line examples that are too divorced from the context of the research question for a student to internalize the lesson. I don’t understand why there aren’t any research methods books with effective exposition; are they trying to appeal to too many disciplines at once?
Josh:
I don’t know, but I don’t think it’s just a problem with textbooks. Most articles don’t clearly state the research process either. I think it’s just difficult to write it all down without lapsing into cliche. Sort of the same reason why it’s difficult to write good fiction or memoir, even if you start out with a good story.
Josh,
I believe you may have missed some of the key points.
Puzzle 1: determining the OEC is a key problem for many web sites running experiments. How should netflix evaluate experiments? Facebook? Linkedin? Amazon? Microsoft support? Office 365? We’ve been involved in multiple discussions around these. “It is hard to generalize” is exactly the point. We show one interesting case for search and show at least one interesting “solution.” Can YOU generalize?
Puzzle 2: billions of dollars rely on click tracking. We share a concrete practical problem that many websites face. Yes, this is “field specific knowledge” that is not well known in a large field with many dollars tied to it: click tracking.
Puzzle 3: I grant you that this one is trivial in hindsight. We were slow to realize it.
Puzzle 4: You missed the point here. In an online controlled experiment, you admit more users into the experiment all the time (e.g., on day two, all users that you haven’t seen on day one are new). Therefore, it was “obvious” that should you need more power or narrower CIs, you run the experiment longer since you’ll get more users, a fact easily observable as the number of users grows monotonically over time. It turns out that you get more power only for some metrics. In fact, if someone wants to dig deeper here, I find it surprising that these two factors essentially have the same growth, something that’s not obvious why. The confidence interval could have continued to shrink, but slower, for example.
The implications for us were extremely important: running longer does not help.
This raises a whole lot of research questions: should you run two one week experiments instead of a two-week one? When is that the right thing to do?
puzzle 5: I worked at Amazon and have talked to multiple people at multiple companies running experiments (Google, Yahoo among them). Practially everyone uses some variant of the bucket system and everyone I know assumed it’s fine to reuse users. We have been doing it for years. The fact that it has such impact was not well understood. The mitigation is easy (almost any problem in computer science can be solved with another level of indirection), but it’s the awareness that’s the key here.
– Ronny
Dear Ronny-
I did not intend to diminish the economic importance of your report for those who do similar work, I should have mentioned that point, but it was difficult for me to judge. I didn’t think about how my comments could be read by someone from your industry who hasn’t read your report, and re-reading what I wrote, I see my comments may be unfair from that perspective. I am sorry. I tried to preface my comments with “the lesson here is that field specific knowledge is required in order for experimentation and inference to be done well.” What I meant by this is that some of your puzzles would be impossible to anticipate ex-ante, or even discover ex-post, without field specific knowledge. So for someone not in your field the only lesson to be gleaned is that one should be vigilant for validity threats of that type, which is pretty generic. So what is the general lesson? Perhaps people should carry around a check-list of common validity threats and go through them when considering a design? Maybe that is a good idea. It looks like with puzzles 1&2 you have found something to add to that checklist for your industry. I don’t doubt the importance of that. For puzzle 3 perhaps your examples are particularly salient and will get others to internalize these important concerns. For Puzzle 4, I didn’t miss the point you make here again, though I probably didn’t think much about how important it is for your work. I just didn’t see what general lesson I could get from it. You say you were measuring Sessions/User, a metric whose support grows the longer a user is observed, which is a problem when you pool together users of different vintage. I don’t think you would have the same problem if you measured (Sessions/Day)/User, though you would have to adjust your standard errors appropriately. For Puzzle 5: I find it a little scary that people were using that system for years unaware that their results could be influenced by subject history. If your report highlights the importance of this for your industry, then it is very important indeed.
Anyway, to be honest, I came with a bias that I wouldn’t be very interested in experiments on user interface design, but instead I found your examples compelling and planned on using them in my course. I should have mentioned that too!
-josh
Pingback: More charity from Microsoft? - David Jinkins : David Jinkins