Palko points to this amusing juxtaposition:

I was curious so I googled to find the original story, “Forecast for US Recession Within Year Hits 100% in Blow to Biden,” by Josh Wingrove, which begins:
A US recession is effectively certain in the next 12 months in new Bloomberg Economics model projections . . . The latest recession probability models by Bloomberg economists Anna Wong and Eliza Winger forecast a higher recession probability across all timeframes, with the 12-month estimate of a downturn by October 2023 hitting 100% . . .
I did some further googling but could not find any details of the model. All I could find was this:
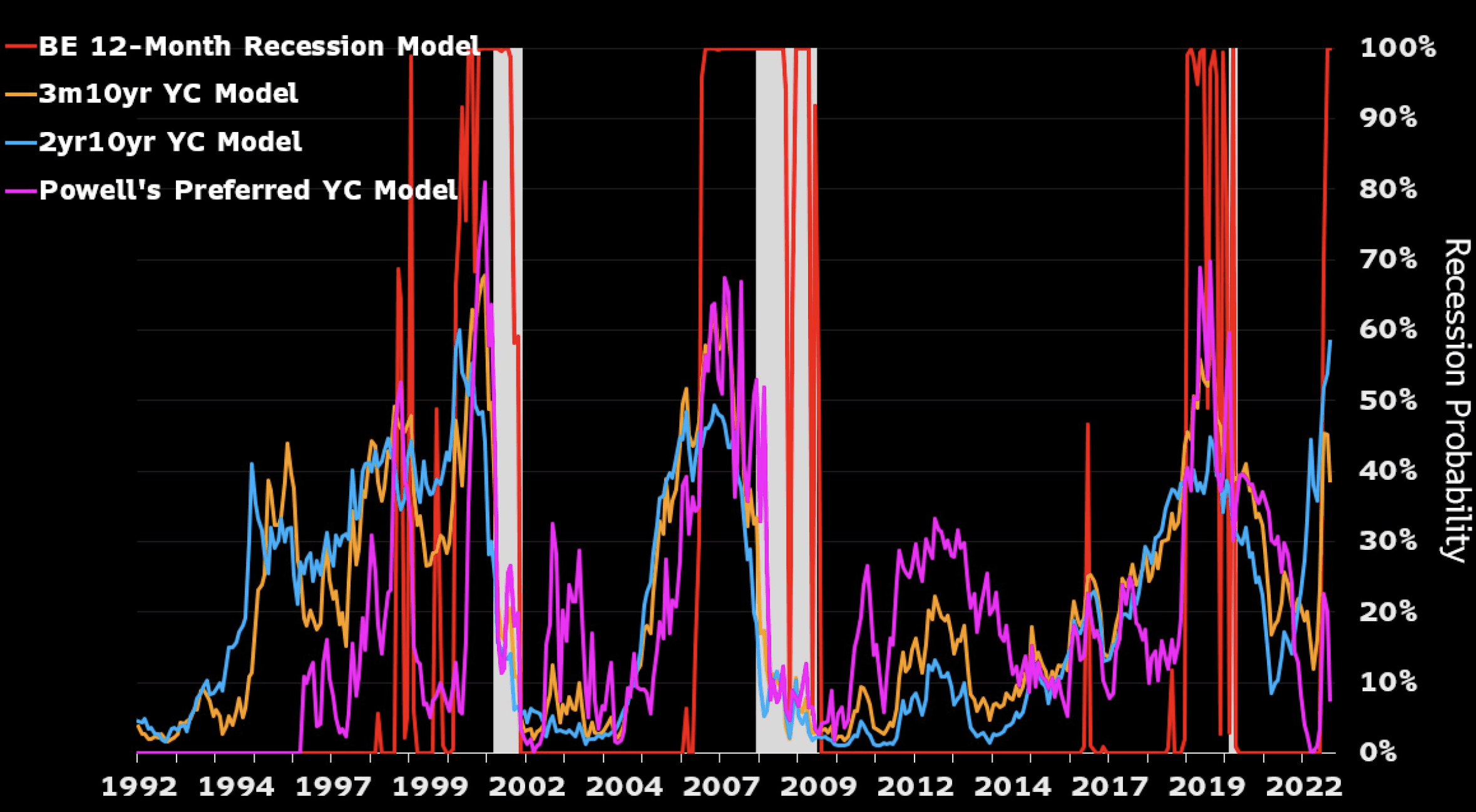
With probabilities that jump around this much, you can expect calibration problems.
This is just a reminder that for something to be a probability, it’s not enough that it be a number between 0 and 1. A real-world probability don’t exist in isolation; they are ensnared in a web of interconnections. Recall our discussion from last year:
Justin asked:
Is p(aliens exist on Neptune that can rap battle) = .137 valid “probability” just because it satisfies mathematical axioms?
And Martha sagely replied:
“p(aliens exist on Neptune that can rap battle) = .137” in itself isn’t something that can satisfy the axioms of probability. The axioms of probability refer to a “system” of probabilities that are “coherent” in the sense of satisfying the axioms. So, for example, the two statements
“p(aliens exist on Neptune that can rap battle) = .137″ and p(aliens exist on Neptune) = .001”
are incompatible according to the axioms of probability, because the event “aliens exist on Neptune that can rap battle” is a sub-event of “aliens exist on Neptune”, so the larger event must (as a consequence of the axioms) have probability at least as large as the probability of the smaller event.
The general point is that a probability can only be understood as part of a larger joint distribution; see the second-to-last paragraph of the boxer/wrestler article. I think that confusion on this point has led to lots of general confusion about probability and its applications.
Beyond that, seeing this completely avoidable slip-up from Bloomberg gives us more respect for the careful analytics teams at other news outlets such as the Economist and Fivethirtyeight, both of which are far from perfect, but at least we’re all aware that it would not make sense to forecast a 100% probability of recession in this sort of uncertain situation.
P.S. See here for another example of a Bloomberg article with a major quantitative screw-up. In this case the perpetrator was not the Bloomberg in-house economics forecasting team, it was a Bloomberg Opinion columnist who is described as “a former editorial director of Harvard Business Review,” which at first kinda sounds like he’s an economist at the Harvard business school, but I guess what it really means is that he’s a journalist without strong quantitative skills.
In this case, it appears that the journalist understands the issue more than the modelers. The article uses the phrases “near certainty” and “effectively certain” although the headline (editor’s influence?) did not have those caveats. Of course, the qualifiers are not adequate, but they at least indicate that the journalist was aware that a 100% probability of a recession was not credible. It would appear that the modelers saw nothing wrong with their model. It is interesting how many times their model did produce 100% probabilities of recessions – and, each time, it looks like there were recessions. If it were me, I’d want to see when those forecasts were produced. If they were prior to the actual recessions, then my model might be valuable once it was better calibrated. On the other hand, if these “forecasts” essentially tell us when a recession has already begun, then the problem is more than just calibration.
Dale:
Yes, all good points. By the way, it seems from the article that the modelers as well as the author of the article work at Bloomberg, hence the title of my post!
I also think the graph you found besides illustrating calibration problems, raises more fundamental issues with the purpose of such models. There are various definitions of “recession” with the most common being 2 successive quarters of negative GDP change. The Bloomberg model must produce forecasts of GDP growth and the accuracy of their forecasts should be evaluated on the basis of those forecast growth rates compared with actual GDP growth rates. The binary distinction of recession/no recession is not very interesting – to anyone other than popular news broadcasts. Announcements of “recession” certainly impact people emotionally, but they are of little consequence in themselves. How much GDP declines is far more relevant. I’m sure the Bloomberg models produce granular forecasts which are then translated into recession probabilities for popular consumption. The calibration issue might concern that translation – in which case, I am less concerned about calibration than I am concerned that the focus is largely irrelevant and potentially misleading. What I want to see is the quantitative forecasts and there may or may not be calibration issues with those. But I couldn’t find any further documentation on the models.
The two forecasts quoted in Bloomberg are exactly a year apart. To be so breathtakingly different must surely have engendered some sort of explanation or at least a mea culpa. Did Bloomberg at least learn anything about why its 2022 forecast was off the mark? How much better are Bloomberg’s forecasts as compared to the various predictions of the coming of the Antichrist by religious leaders?
You would think that Bloomberg would try to learn from their mistake, but I remember one commentator with appropriate credentials who 1) predicted that Putin did not have enough forces to conquer Ukraine so would probably not invade and promised to apologize if he was wrong, 2) in his first public appearance after 24 February announced that resistance was hopeless and Putin would win quickly, and 3) never addressed how he made either mistake or apologized.
Mass-media punditry just does not reward admitting you messed up, discussing what went wrong, and explaining what you will do differently next time.
Sean:
Yes, I agree on your last point. And it’s not just mass-media pundits who don’t seem to understand the idea that we can fractally learn from our mistakes.
Andrew, I see the Nudgelords, the Freakonomics team, or Fivethirtyeight as all engaging in punditry. They all claim to offer practical advice and predictions based on learned wisdom, whether that learning and wisdom is economics or astrology or liver omens changes with fashion and audience. If you want people who behave like good scientists, look for people who are secure but not famous (eg. associate professors who didn’t experience too much trauma on the job hunt).
Trade books are a mass medium! So are the popular psychology mags which offer life advice based on ‘science.’
> The two forecasts quoted in Bloomberg are exactly a year apart.
What two forecasts?
The first article reported that a model from Bloomberg Economics did output 100% probability of recession – and also that the average probability estimate according to a survey was 60%.
The second article reports GDP forecasts from a few sources but not from Bloomberg Economics. They still expect a recession soon, by the way: https://www.bloomberg.com/news/articles/2023-10-01/6-reasons-why-a-us-recession-is-likely-and-coming-soon
“Using consensus forecasts for those key numbers, Bloomberg Economics built a model to mimic the committee’s decision-making process in real time. It works fairly well to match past calls. What it says about the future: There’s a better-than-even chance that sometime next year, the NBER will declare that a US recession began in the closing months of 2023.”
Note also that when they announced in Oct 2022 that the probability of recession according to their model had increased to 100% they wrote “Of course, models don’t always get it right” and discussed different models and the economic context.
Carlos:
Indeed, models don’t always get it right. The point of the above post is not just that the model was retrospectively wrong (for example, predicting a recession with 80% probability and then this being one of the 20% of cases where such predictions went wrong), it’s that it was prospectively wrong in the sense that it made no sense for a model to predict such an uncertain event with 100% probability, and the fact that the model spit out such a number implies that it is fundamentally flawed as a prediction model.
Giving a predicted probability of 100% is not as bad as giving a predicted probability of, say, 108%, but it’s still pretty bad, and any numerate forecaster would see this and immediately go back, try to figure out what went wrong with the model—and do this before rushing to publish the ridiculous “100% probability” claim.
Just to be clear I was not defending the model (and I agree with the “probabilities that jump around this much” critique – even though it has to be noted that the probabilities at each point in time refer to different things as the “next twelve months” period rolls).
However, I think numerate analysts can publish a model-based forecast of 100% without believing it’s correct – just like they can publish a model-based forecast of 99% without believing it’s correct – if that’s what that particular model produces as long as they don’t oversell their significance. Economists have two hands and multiple models after all.
99% or 99.99% is a categorical difference from 100%. With a 100% forecast, the event must take place, and if it doesn’t, probabilistic reasoning breaks entirely, kullback leibler divergence goes to -infinity, all hell breaks loose, cats and dogs live together, etc
Imo, a model should be forbidden from reaching 0 or 1 by construction, working on a logit scale or whatever. If the output is 0 or 1 by under/overflow or rounding for presentation, the display should say >0.999 instead of 1, and the modeler should also be double checking their system
Carlos:
If a forecasting model gives a probability of 100% for an event that’s uncertain, then it’s not actually a probabilistic forecasting model. That’s the key technical point of my above post: a probabilistic model is not just a set of numbers between 0 and 1; the numbers also have to fit together.
Somebody:
I agree with you as a matter of general principle. But in this case if the model gives a probability of 0.999 of a recession, it’s still so screwed up that I wouldn’t call it a probability model. I don’t think it would be part of a coherent network of probability statements. In that sense, “correcting” the 1.000’s to 0.999’s would not solve the problem. In some sense, I’d actually say that the probability of 1 is a good thing in that it reveals a problem with the model.
> If a forecasting model gives a probability of 100% for an event that’s uncertain, then it’s not actually a probabilistic forecasting model.
The tables at https://github.com/TheEconomist/us-potus-model show a lot of probabilities 1.000 and 0.000.
Should we conclude that the forecasting model is not probabilistic or that there was no uncertainty regarding those events?
Or maybe we are supposed to interpret that the 100% from the Bloomberg’s model is unacceptable for a probabilistic model because it’s exactly one but the 1.000 and 0.000 from The Economist’s model are acceptable because they are close to one and zero but not one and zero?
That’s a table rounded off to 3 significant digits for developers to look at on github. The public forecast shows 99%, which is appropriate for stuff like “Democrats win California”. If you gave a less than 99% that Democrats win California, I’d say there’s something wrong with your forecast. That’s very unlike the probability that there’s a recession in this year.
It should be “greater than 99%” and “less than 1%” but this site eats the angle brackets
Carlos:
Yes, if I’m reading that page correctly, the model was retroactively forecasting Hillary Clinton’s probability of winning as being 0.000 in Kansas, 0.001 in Missouri, 0.999 in Illinois, and 1.000 in New Jersey, as reported to three decimal places. It would be fair, even prospectively, to argue that these probabilities are too extreme.
In some settings, of course a probability of 0.00001 or whatever is just fine, if we’re talking about events of inherently low probability such as “The vote for president in Pennsylvania is exactly tied” or “My next lottery ticket will win big bucks.”
An event such as “Clinton wins Kansas in 2016” is somewhere in between. Given all the elections we’ve seen, here’s no realistic way that this could happen based on what was known pre-election in 2016, but it’s hard to account for the unaccountable.
Whether there is a recession a year from now, though, that’s another story. Recent economic history should make it clear that 0.999 is not going to make sense for that.
To put it another way: if a model gives a prediction that looks strange, the next step is to go back and look at the model. I have no prior reason to think that this Bloomberg model has any chance of being a calibrated forecasting model. It’s just some computer program that someone wrote that spits out numbers between 0 and 1. For all I know, it gave an estimated probability of 108% and then truncated that down 100, I have no idea. The mistake would be to think that, just because something is labeled as a probability forecast, and it has a Bloomberg brand name, that’s it’s actually a probability forecast. My guess it that’s not.
Of course, it something is a probability forecast, it doesn’t have to be a good forecast. My point is that if someone has a computer program that calls itself a probability forecast and starts spitting out numbers such as 100%, you’ll want to look at things very carefully and try to figure out what the method is actually doing.
> Whether there is a recession a year from now, though, that’s another story. Recent economic history should make it clear that 0.999 is not going to make sense for that.
I agree. And I’m sure the economists behind the model agree.
> Of course, it something is a probability forecast, it doesn’t have to be a good forecast. My point is that if someone has a computer program that calls itself a probability forecast and starts spitting out numbers such as 100%, you’ll want to look at things very carefully and try to figure out what the method is actually doing.
Sure. The thing is that what they actually wrote sounds to me more like “our computer program spat a 100% and based on the output of that model, and other models, and other considerations, we find that a recession is quite likely” than “we claim the a recession is certain because computer says so”. I find unwarranted to call them innumerate, really.
“Bloomberg Economics’ recession probability model […] suggests that a downturn […] is close to a certainty. […]
Of course, models don’t always get it right […] Still, it’s tough to imagine the Fed taming runaway inflation without a period of negative growth and rising unemployment. […] Bloomberg Economics’ recession probability model, based on 13 indicators, points to a 100% probability of a recession starting in the next 12 months, compared to 65% for the comparable time period in our last update. […] That aligns with the intuition that Fed tightening to control inflation works by cooling the economy and raising unemployment […] The Fed’s own forecasts […] also are consistent with a recession […] The latest Bloomberg survey of economists points in the same direction.
[…] Bloomberg Economics’ model is not alone in predicting a near-certain recession within a year. The Conference Board’s model sees a 96% chance of recession over the same horizon. In the trade group’s recent survey of 136 CEOs, 98% said they’re bracing for a recession in the US. […] The deterioration in the outlook was driven by a broad-based worsening in the economic and financial indicators used as inputs to the model. […] Outside of our indicator-driven models, we also assess the chance of a downturn implied by various yield-curve spreads, which have a good track record of predicting downturns.
Our yield-curve recession-probability models showed recession risks rising to 58% 12 months ahead (vs. 54% prior), based on the further inversion of the 10-year/2-year curve. Looking at the 10-year/3- month curve, however, the probability of recession declined slightly (39% vs. 45% prior). The recession probability based on the Fed’s preferred alternative — the near-term forward spread — was about 8%.”
Carlos:
OK, no need to call them innumerate. Perhaps more accurate to say that they are ignorant in the sense of not realizing that a computer program that spits out numbers between 0 and 1 is not the same as a probability forecast.
It’s true that as soon as someone starts discussing multiple probability forecasts for the same event it becomes clear that they may not be making strong assumptions about the validity of any of them.
> Beyond that, seeing this completely avoidable slip-up from Bloomberg gives us more respect for the careful analytics teams at other news outlets such as the Economist and Fivethirtyeight, both of which are far from perfect, but at least we’re all aware that it would not make sense to forecast a 100% probability of recession in this sort of uncertain situation.
For what is worth, The Economist’s editor-in-chief published last November a piece titled “Why a global recession is inevitable in 2023” stating that “The Federal Reserve’s aggressive rate increases will tip the economy into recession, but with the labour market still strong and household savings copious, it will be a mild one.”
Oof! I guess that “inevitable” isn’t quite as bad as “100% probability” but it’s not so great either.
Aren’t those synonymous?
Sure, but a number seems to me to give more of an inappropriate air of scientism. If someone says something’s inevitable, then that’s their take: if A, B, and C happen, then it’s inevitable that D comes next; it’s a form of logical reasoning. In contrast, if someone says they did a forecast and it gives 100% probability, that seems to imply more of an empirical statement.
https://markets.businessinsider.com/news/stocks/economy-nber-will-not-declare-official-recession-gdp-growth-jobs-2022-8?op=1
Why does anyone care about this? The NBER will obviously say whatever is convenient for them. And typically that means deny during it, then declare a recession after it is over.
And GDP includes government spending, so you can prevent a “technical recession” by adding to the debt (which is rising by ~$1 trillion per quarter now). Only three years ago this was considered an emergency measure justified by an unprecedented global crisis.