Matt Hoffman and Pavel Sountsov write:
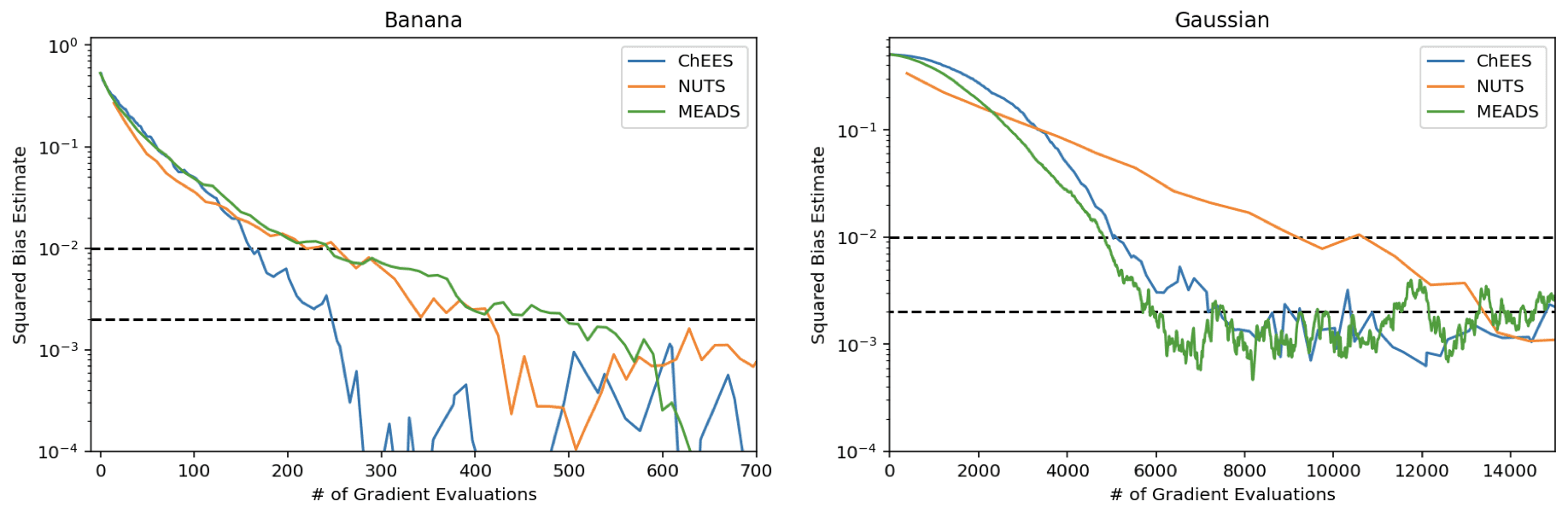
Hamiltonian Monte Carlo (HMC) has become a go-to family of Markov chain Monte Carlo (MCMC) algorithms for Bayesian inference problems, in part because we have good procedures for automatically tuning its parameters. Much less attention has been paid to automatic tuning of generalized HMC (GHMC), in which the auxiliary momentum vector is partially updated frequently instead of being completely resampled infrequently. Since GHMC spreads progress over many iterations, it is not straightforward to tune GHMC based on quantities typically used to tune HMC such as average acceptance rate and squared jumped distance. In this work, we propose an ensemble-chain adaptation (ECA) algorithm for GHMC that automatically selects values for all of GHMC’s tunable parameters each iteration based on statistics collected from a population of many chains. This algorithm is designed to make good use of SIMD hardware accelerators such as GPUs, allowing most chains to be updated in parallel each iteration. Unlike typical adaptive-MCMC algorithms, our ECA algorithm does not perturb the chain’s stationary distribution, and therefore does not need to be “frozen” after warmup. Empirically, we find that the proposed algorithm quickly converges to its stationary distribution, producing accurate estimates of posterior expectations with relatively few gradient evaluations.
Sounds like it could be really important. Just the other day I was talking with someone about how abrupt it is that HMC jumps so abruptly between Hamiltonian trajectories and random walk. I hadn’t been aware of generalized HMC, and now that there’s some auto-tuning, it seems like it’s time to learn more about it!
So it is introducing a dependence between chains. But the point of multiple chains is to have different initializations that we see all converge to the same place, which gives us reason to think where they all converged is a global optimum.
It seems interesting, but dangerous. It would be nice to see some examples of “pathological” posteriors where this fails.
If you initialize the chains in different places, you can still use things like R-hat to test for non-convergence. The algorithm doesn’t have any “warping” moves that would mask a failure to mix.
I would expect MEADS to perform very badly on (for example) target distributions with well-separated modes. Because MEADS blends adaptation signals across chains it’s liable to fail spectacularly. In particular, it might use a damping coefficient that’s way too small, a diagonal preconditioner that has nothing to do with any local curvature, and a step size that’s a little too large for the highest-curvature mode and much to small for low-curvature modes.
Of course, no gradient-based MCMC algorithm is likely to mix well between modes without a lot of special care (live by the local function approximation, die by the local function approximation). But if the chains are truly independent then at least you might get good within-mode samples, which might still be useful for prediction, e.g., using stacking.
Thanks, that is good. I took a closer look at the paper now.
I wonder if you could first start off each chain independently then cluster them according to whatever hyperparameters you get. So there could be multiple “meta-chains” if some regions are too different from the others.
Anon:
Yes, this is related to nested R-hat.
Is there a public implementation available? Maybe not, at least I couldn’t find one easily.
Yes! There’s a complete implementation here:
https://github.com/tensorflow/probability/tree/main/discussion/meads
Thanks!