About 80 people pointed me to this post by Uri Simonsohn, Joe Simmons, and Leif Nelson about a 2012 article, “Signing at the beginning makes ethics salient and decreases dishonest self-reports in comparison to signing at the end.” Apparently some of the data in that paper were faked; see for example here:

Uri et al. report some fun sleuthing:
The analyses we have performed on these two fonts provide evidence of a rather specific form of data tampering. We believe the dataset began with the observations in Calibri font. Those were then duplicated using Cambria font. In that process, a random number from 0 to 1,000 (e.g., RANDBETWEEN(0,1000)) was added to the baseline (Time 1) mileage of each car, perhaps to mask the duplication. . . .
The evidence presented in this post indicates that the data underwent at least two forms of fabrication: (1) many Time 1 data points were duplicated and then slightly altered (using a random number generator) to create additional observations, and (2) all of the Time 2 data were created using a random number generator that capped miles driven, the key dependent variable, at 50,000 miles.
This is basically the Cornell Food and Brand Lab without the snow.
Uri et al. summarize:
We have worked on enough fraud cases in the last decade to know that scientific fraud is more common than is convenient to believe, and that it does not happen only on the periphery of science. Addressing the problem of scientific fraud should not be left to a few anonymous (and fed up and frightened) whistleblowers and some (fed up and frightened) bloggers to root out. The consequences of fraud are experienced collectively, so eliminating it should be a collective endeavor. What can everyone do?
There will never be a perfect solution, but there is an obvious step to take: Data should be posted. The fabrication in this paper was discovered because the data were posted. If more data were posted, fraud would be easier to catch. And if fraud is easier to catch, some potential fraudsters may be more reluctant to do it. . . .
Until that day comes, all of us have a role to play. As authors (and co-authors), we should always make all of our data publicly available. And as editors and reviewers, we can ask for data during the review process, or turn down requests to review papers that do not make their data available. A field that ignores the problem of fraud, or pretends that it does not exist, risks losing its credibility. And deservedly so.
Their post concludes with letters from four of the authors of the now-discredited 2012 paper. All four of these authors agree that Uri et al. presented unequivocal evidence of fraud. Only one of the authors handled the data; this was Dan Ariely, who writes:
I agree with the conclusions and I also fully agree that posting data sooner would help to improve data quality and scientific accuracy. . . . The work was conducted over ten years ago by an insurance company with whom I partnered on this study. The data were collected, entered, merged and anonymized by the company and then sent to me. . . . I was not involved in the data collection, data entry, or merging data with information from the insurance database for privacy reasons.
Some related material
Lots of people sent me the above-linked post by Uri, Joe, and Leif. Here are a few related things that some people sent in:
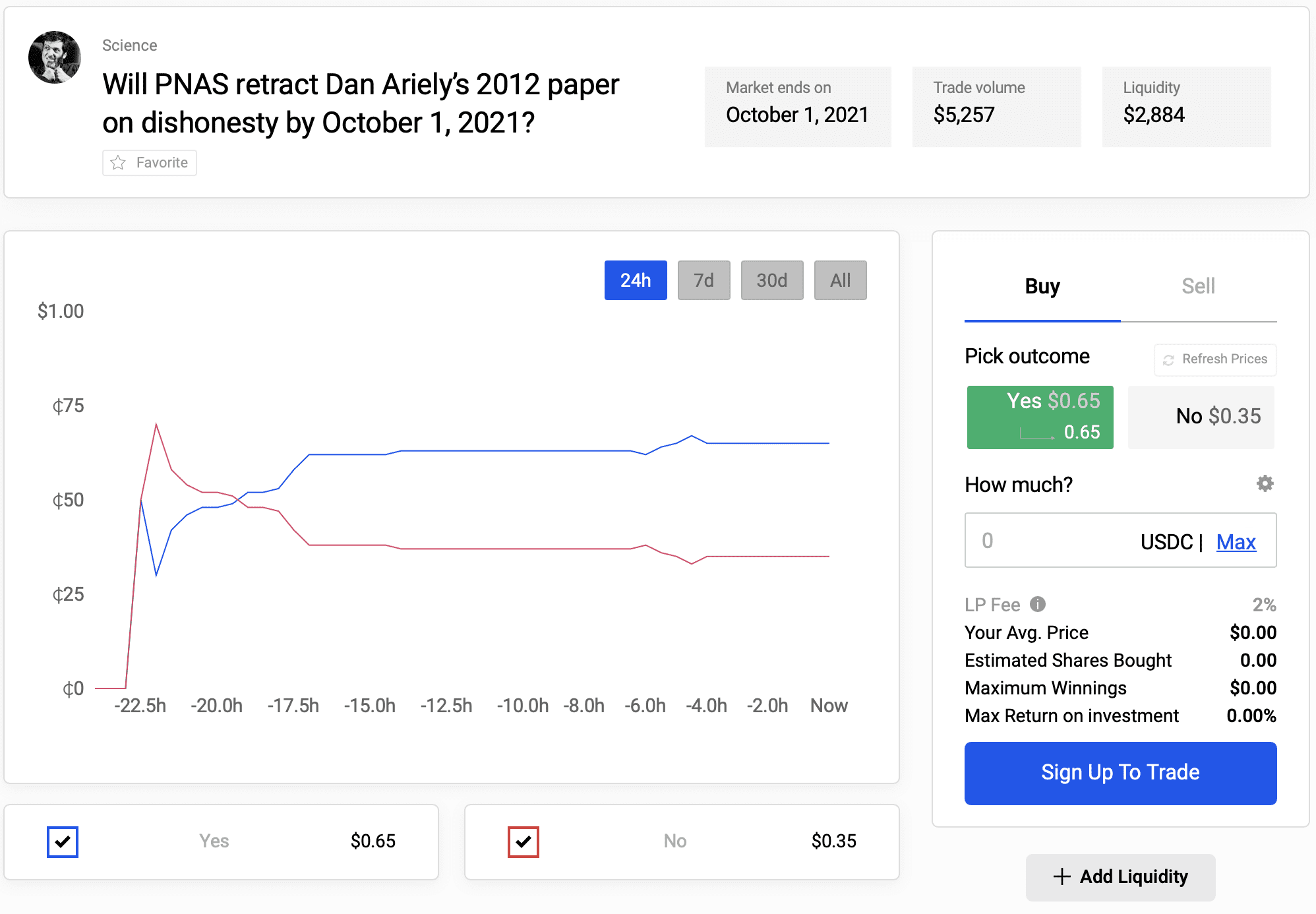
– Kevin Lewis pointed to the betting odds at Polymarket.com (see image at top of post).
– Gary Smith pointed to this very recent article, “Insurance Company Gives Sour AI promises,” about an insurance company called Lemonade:
In addition to raising hundreds of millions of dollars from eager investors, Lemonade quickly attracted more than a million customers with the premise that artificial intelligence (AI) algorithms can estimate risks accurately and that buying insurance and filing claims can be fun . . . The company doesn’t explain how its AI works, but there is this head-scratching boast:
A typical homeowners policy form has 20-40 fields (name, address, bday…), so traditional insurers collect 20-40 data points per user.
AI Maya asks just 13 Q’s but collects over 1,600 data points, producing nuanced profiles of our users and remarkably predictive insights.
This mysterious claim is, frankly, a bit creepy. How do they get 1,600 data points from 13 questions? Is their app using our phones and computers to track everywhere we go and everything we do? The company says that it collects data from every customer interaction but, unless it is collecting trivia, that hardly amounts to 1,600 data points. . . . In May 2021 Lemonade posted a problematic thread to Twitter (which was later deleted):
When a user files a claim, they record a video on their phone and explain what happened. Our AI carefully analyzes these videos for signs of fraud. [AI Jim] can pick up non-verbal cues that traditional insurers can’t, since they don’t use a digital claims process. This ultimately helps us lower our loss ratios (aka how much we pay out in claims vs. how much we take in).
Are claims really being validated by non-verbal cues (like the color of a person’s skin) that are being processed by black-box AI algorithms that the company does not understand?
There was an understandable media uproar since AI algorithms for analyzing people’s faces and emotions are notoriously unreliable and biased. Lemonade had to backtrack. A spokesperson said that Lemonade was only using facial recognition software for identifying people who file multiple claims using multiple names.
I agree with Smith that this sounds fishy. In short, it sounds like the Lemonade people are lying in one place or another. If they’re really only using facial recognition software for identifying people who file multiple claims using multiple names, then that can’t really be described as “pick[ing] up non-verbal cues.” But yeah, press releases. People lie in press releases all the time. There could’ve even been some confusion, like maybe the nonverbal cues thing was a research idea that they never implemented, but the public relations writer heard about it and thought it was already happening.
The connection to the earlier story is that Dan Ariely works at Lemonade; he’s their Chief Behavioral Officer, or at least he had this position in 2016. I hope he’s not the guy in charge of detecting fraudulent claims, as it seems that he’s been fooled by fraudulent data from an insurance company at least once in the past.
– A couple people also pointed me to this recent Retraction Watch article from Adam Marcus, “Prominent behavioral scientist’s paper earns an expression of concern,” about a 2004 article, “Effort for Payment: A Tale of Two Markets.” There were inconsistencies in the analysis, and the original data could not be found. The author said, “It’s a good thing for science to put a question mark [on] this. . . . Most of all, I wish I kept records of what statistical analysis I did. . . . That’s the biggest fault of my own, that I just don’t keep enough records of what I do.” It actually sounds like the biggest fault was not a lack of records of the analysis, but rather no records of the original data.
Just don’t tell me they’re retracting the 2004 classic, “Garfield: A Tail of Two Kitties.” I can take a lot of bad news, but Bill Murray being involved in a retraction—that’s a level of disillusionment I can’t take right now.
Why such a big deal?
The one thing I don’t quite understand is why this latest case got so much attention. It’s an interesting case, but so were the Why We Sleep story and many others. Also notable is how this seems to be blowing up so fast, as compared with the Harvard primatologist or the Cornell Food and Brand episode, each of which took years to play out. Maybe people are more willing to accept that there has been fraud, whereas in these earlier cases lots of people were bending over backward to give people the benefit of the doubt? Also there’s the dramatic nature of this fraud, which is similar to that UCLA survey from a few years ago. The Food and Brand Lab data problems were so messy . . . it was clear that the data were nothing like what was claimed, but the setup was so sloppy that nobody could figure out what was going on (and the perp still seems to live in a funhouse world in which nothing went wrong). I’m glad that Uri et al. and Retraction Watch did these careful posts; I just don’t quite follow why this story got such immediate interest. One person suggested that people were reacting to the irony of fraud in a study about dishonesty?
The other interesting thing is that, as reported by Uri et al., the results of the now-discredited 2012 article failed to show up in an independent replication. And nobody seems to even care.
Here’s some further background:
Ariely is the author of the 2012 book, “The Honest Truth About Dishonesty: How We Lie to Everyone—Especially Ourselves.” A quick google search finds him featured in a recent Freakonomics radio show called, “Is Everybody Cheating These Days?”, and a 2020 NPR segment in which he says, “One of the frightening conclusions we have is that what separates honest people from not-honest people is not necessarily character, it’s opportunity . . . the surprising thing for a rational economist would be: why don’t we cheat more?”
But . . . wait a minute! The NPR segment, dated 17 Feb 2020, states:
That’s why Ariely describes honesty as something of a state of mind. He thinks the IRS should have people sign a pledge committing to be honest when they start working on their taxes, not when they’re done. Setting the stage for honesty is more effective than asking someone after the fact whether or not they lied.
And that last sentence links directly to the 2012 paper—indeed, it links to a copy of the paper sitting at Ariely’s website. But the new paper with the failed replications, “Signing at the beginning versus at the end does not decrease dishonesty,” by Kristal Whillans, Bazerman, Gino, Shu, Mazar, and Ariely, is dated 31 Mar 2020, and it was sent to the journal in mid-2019:

Ariely, as a coauthor of this article, had to have known for at least half a year before the NPR story that this finding didn’t replicate. But in that NPR interview he wasn’t able to spare even a moment to share this information with the credulous reporter? This seems bad, even aside from any fraud. If you have a highly publicized study, and it doesn’t replicate, then I think you’d want to be damn clear with everyone that this happened. You wouldn’t want the national news media to go around acting like your research claims held up, when they didn’t.
I guess that PNAS might retract the paper (that’s what the betting odds say!) NPR will eventually report on this story, and Ted might take down the talks (no over-under action on this one, unfortunately), but I don’t know that they’ll confront the underlying problem. What I’d like is not just an NPR story, “Fraud case rocks the insurance industry and academia,” but something more along the lines of:
We at NPR were also fooled. Even before the fraud was revealed, this study which failed to replicate was reported without qualification. This is a problem. Science reporters rely on academic scientists. We can’t vet all the claims told to us, but at the very least we need to increase the incentives for scientists to be open to us about their failures, and reduce the incentives for them to exaggerate. NPR and Ted can’t get everything right, but going forward we endeavor to be part of the solution, not part of the problem. As a first step, we’re being open about how we were fooled. This is not just a story we are reporting; it’s also a story about us.
P.S. Recall the Armstrong Principle.
P.P.S. More on the story from Stephanie Lee.
P.P.P.S. And more from Jonatan Pallesen, who concludes, “This is a case of fraud that is completely bungled by ineptitude. As a result it had signs of fraud that were obvious from just looking at the most basic summary statistics of the data. And still, it was only discovered after 9 years, after someone attempted a replication. . . . This makes it seem likely that there is a lot more fraud than most people expect.”
The fact that you find Lemonade noteworthy makes me think you don’t spend enough time looking at the San Francisco startup scene. Literally every company posts a load of nonsense about what their AI is doing in the background. If you ever get a chance to talk to their data scientists they laugh and tell you they think that post is referring to a linear regression they helped build a couple years back.
Why as a society do we put up with this? I want people serving jail time for false advertising. Snake oil is snake oil whether it’s actually extracted from snakes or not.
Startups are predicated on ideas that don’t exist yet. It’s a fine line between “this really could exist and be amazing if we had $50 million to hire the engineers to build it” and “this is a pipe dream, but if I can convince some venture capitalists, maybe they’ll give me $50 million.” Unfortunately, far too many people are comfortable with taking the second route and selling it as the first.
+1 And FWIW, there’s an entire industry centered around helping venture capitalist groups try to figure out whether the former or latter scenario is most likely. I’m sure many of these blog readers would do quite well in such a gig.
Clearly what they need is a startup that uses AI to determine which scenario it is.
+1
+1
They’re enormously bad at it. Even their success stories are failure. Uber is not profitable. Lyft is not profitable. Mealkits are not profitable. The algorithms that are supposed to conquer their unit-economics are always 2 years away. The startup scene is as frothy as it is because the federal reserve has no way to enact stimulus that doesn’t involve running it through the banks.
>The startup scene is as frothy as it is because the federal reserve has no way to enact stimulus that doesn’t involve running it through the banks.
THIS 100% I’ve been saying that for years! A big part of my support for UBI is that you could simply bump the size of UBI when you have liquidity issues which would run monetary stimulus through 320M people’s preferences instead of a few tens of large corporate finance group’s preferences.
Actually, right now only the banks can do any stimulus. The fed can only influence them via bank reserves. But if banks refuse to lend anyway for whatever reason, then the fed is impotent.
Your idea would be a huge power grab by the fed.
“Uber is not profitable. Lyft is not profitable. ”
?? Not to defend either of these companies but many companies run negative earnings for years living from seed capital and eventually become highly profitable. Facebook and Amazon, for example! :)
Also the selling point of UBER and LYFT had nothing to do with AI. It was promise of the efficiency of ride sharing and the efficiency and freedom of the gig economy that drove the popularity of these companies. The results were always dependent on their success at circumnavigating min wage laws – which many local governments at least openly condoned for years, which in turn contributed to their stellar climb in value.
“The startup scene is as frothy as it is because the federal reserve….”
The froth in the startup scene is due to the same credulity that allows papers like the one discussed in this blog to go unchallenged. Lemonade is extremely popular among the 20ish set, and the credibility of Ariely – rooted in his (dubious) academic accomplishments – has a lot to do with that.
“In the U.S. and Côte d’Ivoire, highly educated people make decisions that are less consistent with the rational model while low-income respondents make decisions more consistent with the rational model.”
See this paper.
The point is that many companies have no plan at all for monetization.
1. I never said it has anything to do with AI. All that said, it actually has a lot to do with AI. The “efficiency of ride sharing” is an AI product–their core matching algorithm and especially their surge pricing algorithm are both ML-based products.
2. AI autonomous vehicle driving is Lyft’s core future growth strategy. Check out this earnings call
https://www.fool.com/earnings/call-transcripts/2021/02/09/lyft-inc-lyft-q4-2020-earnings-call-transcript/
Count the number of times autonomous vehicle or AVs are referenced.
3. Circumventing minimum wage laws is an unworkable strategy, which is obviously borne out by the fact that their ride-hailing business has never been profitable at any time in their history. The fact is that they need to pay drivers enough to justify the cost of their capital, in this case their car and insurance, but charge riders little enough that they’ll take the rides. The math doesn’t work out–people aren’t willing to pay what it costs, minimum wages or not. So uber and lyft are and have been constantly rolling out incentive programs and promotions to drive up both supply and demand. I can start a business where I pay people to make food and then give it away for less, and I’d have a very large volume of transactions, but I wouldn’t make money–it’d be a charity.
I find this framing pretty much useless. People are fallible, people make mistakes, people should strive to improve themselves and have better judgement. The point of an economic system like free-market capitalism is supposed to be, at least in the textbooks, that such credulity is punished, that those who don’t learn are filtered out of capital markets, and not too many capital resources can be allocated to useless endeavors as measured by profit. So the question remains–why do the idiots remain? How come the money still keeps flowing to dumb ideas, and how can they remain unprofitable for so long? You need to follow the money–where does it all come from?
“The “efficiency of ride sharing” is an AI product
Uh, no! It’ just a simple matching query. Dude.
“I find this framing pretty much useless. ”
“VEDANTAM: Wow.”
A relatively economics recent paper by Chen, Rossi, and Chevalier identifies the hourly wage of an Uber driver, etc. There is solid research on this topic. Why a yo e would trust Lemonade or Ariely on this stuff is ridiculous.
Mass incarceration at a prosecutor’s whim is far worse than some idiotic claims.
You’re suggested mea culpa for NPR has in fact already happened in almost the same words — namely in 2010, the last time when Ariely told them things that didn’t check out! https://www.npr.org/sections/publiceditor/2010/11/08/131079116/should-you-be-suspicious-of-your-dentist-or-nprs-source
> [Ariely] holds the James B. Duke Professor of Behavioral Economics chair at Duke University. So when he appeared on NPR’s air, there was every reason to trust him. […] But what is NPR’s responsibility? This is a tough one. NPR can’t re-report and check out every thing that an on-air guest says. […] ATC has other pre-taped segments with Ariely, and those should be double-checked before they are aired. There’s no doubt that Ariely is both entertaining and informative about how irrational we humans are — but he also must be right.
OMG this is perfect
Good spotting the NPR interview… from the transcript of the segment itself:
https://www.npr.org/transcripts/805808486
“VEDANTAM: Wow.”
ha ha ha, that’s hilarous! NPR’s Dr. Oz.
VEDANTAM: And there’s research to suggest that being surprised by things actually CHANGES OUR BRAINS in significant ways.
+1
Jim:
I’ve heard that if he says Wow at the beginning of the interview it has more effect than if he says Wow at the end.
Dean:
Wow—that’s a lot worse than I imagined! I’d supposed that the NPR interviewer had picked up on that old article and Ariely had then just gone with the flow. But Ariely was out-and-out promoting the study that he himself had just shot down. This is entering Bizarro World territory.
Though turns out it was recorded in 2017!
https://twitter.com/taranoelleboyle/status/1429066878513713162
That’s not clear from https://www.npr.org/2020/02/13/805808486/liar-liar-liar but I guess available somewhere else.
Jeez . . . NPR shouldn’t be re-running false stories!
Your link for the Lemonade article points to the betting odds.
Link fixed; thanks.
I suspect this story gets attention in a certain kind of academia because it is Dan Ariely, but I could be wrong
Another bitter-sweet irony: Dan Ariely is interviewed in the documentary The Inventor, which is about Theranos. He discusses in depth the psychology of fraudsters in general, with the movie of course focusing on Elizabeth Holmes in particular.
>>The one thing I don’t quite understand is why this latest case got so much attention.
Because from day 1 it’s a solid, slam-dunk case of fraud in what much of the world considers a top journal.
In contrast, for the first 12-15 months, the problems affecting Wansink’s work were all mostly of the “WTF?” variety – so stupid that you couldn’t always tell what the right result was meant to be.
In fact we had a couple of cases of what looked like straight-up fabrication or recycling of numbers across studies, but they were in places like the Ruritanian Journal of Cattle Marketing (one editor actually asked me “What do you think I should do?”). The story only went viral when Stephanie Lee uncovered the p-hacking factory and JAMA got pissed off at having to retract an article twice.
And even though the final charge sheet from Cornell included “data falsification” (as well as “a failure to assure data accuracy and integrity, inappropriate attribution of authorship of research publications, inappropriate research methods, failure to obtain necessary research approvals, and dual publication or submission of research findings”; M. Kotlikoff, response to our open letter, 2018-11-05), people still remember it, I think, mostly for the p-hacking and general weirdness.
Nick:
I get that, but it kinda bothers me that these other things don’t bother people more. Like, what about Ariely promoting a claim on national radio months after he was a coauthor on a paper saying the claim didn’t replicate? Or the Why We Sleep guy distorting data and just making things up? I agree that people should be outraged about the fake data in the 2012 paper, but often when I see these extreme examples, I’m bothered that people let all sorts of comparable things slide by.
The mention of Freakonomics reminded me of the mysterious “factor X” which Levitt claimed to have found in banking data that by itself is extremely predictive of terrorists. Sounds ludricruous for anyone who have built a predictive modeling. And that was a collaboration between him and banking people. Perhaps he too “was not involved in the data collection, data entry, or merging data with information from the … database for privacy reasons.”
Kaiser:
Perhaps factor X was related to those 30 years of global cooling that Levitt couldn’t resist talking about. Ultimately I think the problem here is not Levitt—after all, there will always be people willing to make exaggerated claims in exchange for fame and fortune—but the NYT/NPR/Ted media complex that promotes this sort of thing.
While it is clear the data is fraudulent, it is still not clear how the fraud occurred.
Possibility #1: Ariely cooked the books to get the result he wanted. Plain and simple.
Possibility #2: The insurance company handed him fabricated data, and he either (a) never bothered to check it, or (b) noticed something was wrong but pretended not to know.
Obviously, Ariely is claiming 2(a). 1 is really bad, of course, and he will never admit to it. 2(b) is just as bad, though not judged so in practice.
If it was the insurance company, I would be very curious to know how it came about. The most likely scenario is that the two different forms were never actually given to customers. Someone in one area of the insurance company agreed to do it, but the people responsible for executing the operation realized it was going to be a pain, and ignored the idea (or something like that). Then when Ariely asked for the results, they just fabricated the data using that bounded uniform distribution, and didn’t even bother to do stratify it to appear random.
I bring this up because something like the above scenario is an underdiscussed problem in the world of field experiments in developing countries. Leadership of NGOs and development agencies agree to some research design, the people on the ground find that it is big pain in the ass to adhere to, and they don’t follow the protocols. Sometimes it is obvious. But sometimes it isn’t, and the big name researcher who flies in for a day to talk to the leadership just wants his data, and so they give it to him/her, and the fact that the research is a sham is insider knowledge in the country.
If Ariely didn’t look at the distribution of the numbers, he should hand back his PhD, and for that matter the certificate of completion of undergrad statistics 101. Apparently he was hawking these results on the conference circuit for months before submitting to PNAS, and we’re expected to believe that at no time did he notice that the distribution of miles was completely flat until it fell off a cliff?
Nick:
I have to admit that I’ve hawked lots of results without looking carefully at the raw data. Sometimes I look at the data very carefully; other times I trust my collaborators. I don’t think I’ve ever looked at the raw data from the Monster experiment or the Xbox survey, and I’ve written and spoken a lot on both these examples.
This also struck me as why it got a lot of attention. In particular, there are huge monetary and time costs in getting a PNAS-worthy field experiment implemented in the real world, and so possibility 1 is bad because it undermines the work that many go through to do the experiments (in the same way the lacour scandal undermined that) and 2a is also bad because it suggests a lack of thoroughness in implementation that would seem to undermine his other work involving field experiments with govts or firms.
On the possibility 1 front, it seems easy to refute if he’s able to produce something like a DUA, some sort of MOU between himself and the firm, or other document that could leave the firm de-identified but proves this actually happened.
On the lattermost points, there does seem to be some awareness of these issues in field experiments in developing countries (eg researchers working on data validation techniques to try to detect fabrication: https://journals.sagepub.com/doi/10.1177/1948550617691101). So I think hopefully this sparks similar monitoring in domestic contexts if it’s possibility 2a.
Why would the insurance company manipulate the data? It seems pretty clear that Ariely himself had to be the culprit; he admits it was either himself or the insurance company, the insurance company has no motive, he doesn’t directly deny doing it, his coauthors report some shady behavior (without using his name, but who else), and he has “lost” data and analysis in other cases as well. It would be extremely easy to prove he didn’t manipulate it (show the original data coming from the company), and he hasn’t. Slam dunk of a case. And if he’s willing to do that, it’s not surprising he misleads reporters.
Wansink is in a different field and peddles the kinds of claims that economists are skeptical of to start with so you can’t compare the outrage levels. Not to mention Ariely is very famous, and it’s for his work on *dishonesty*, so the stakes and irony make the story extra compelling. And as Nick said, the timing is a huge factor.
Nah, the insurance company told some undergrad IT intern to write a SQL query to get the data, the undergrad intern couldn’t figure out how to do it for a while, so as an intermediate step generated random uniform data to test with… and then when the deadline came, the undergrad went back to school and some guy whose main job was to do something else just ran the undergrad’s query and shipped the data out without even looking at it.
That cannot explain the fonts and him being creator of the Excel sheet, nor that the data matched the hypothesis (after he fixed his faking error). Don’t be so generous.
You’re right, but I wasn’t being generous so much as pointing out that if a researcher doesn’t actually care about the data and the data supplier doesn’t care either, it’s easily possible to have some complete garbage that everyone analyzes and is happy with… Until someone who cares looks into it. This is particularly true if all the researcher wants is some asterisks near his coefficients
No insurance person… probably none actually. If this were the first time for his “mistake” we might turn away. But, it’s not. Lots and lots.
I agree that Ariely should forward the original data/email where he got the data; it would be fairly definitive proof of his innocence. OTOH, if the Office of Research Integrity is investigating, maybe they asked him not to publish something like that until they finish their investigation.
Anyway, you should always be plotting distributions of your data; if he didn’t do that, that alone is enough to call into question his other results, and is extremely embarrassing for Ariely. I’ve been guilty of same – not in published research, but before publishing, running statistical tests before visualizing the data, and realizing that my exciting results were being driven by artifacts in the data.
But its not right that there is not plausible motive for someone at the insurance company to do this. The answer to this is simple. People working at insurance companies are busy, running experiments is hard and time consuming, and not a priority, and so someone just gave Dan simulated data that would give him the result he wanted. Something could have gone wrong, could have gotten lost, or just never happened. And the incentive for an employee to admit that is exactly zero. I am certain this research is one of those things where all the boss cares about is that they don’t have to care about it; no real benefit to the employee for getting it done, only downside is it doesn’t get done and embarrasses someone.
Ariely has reportedly already asked for the paper to be retracted. So, probably no original data will be forwarded; given his response to Retraction Watch in the link here, the retraction request is more, IMO, a CYA move than anything else.
And, that said, per the “star professor” angle, following the motives of Ariely first? Ockham’s Razor.
My guess?
The insurance company probably conducted a defensive-and-crudely-executed form of data anonymization for liability protection.
Are you Danny Ariely?
Would Danny Ariely sport a bushy mustache and Groucho glasses??
Check that: https://twitter.com/R__INDEX/status/1427732562714185733?s=20
One way this seems different than other fraud cases is that the hypothesis seems totally plausible to me. Maybe it’s just me.
Dl:
All these hypotheses (the ESP study excepted) seem plausible enough when expressed directionally: beautiful people have more (or fewer) daughters, women support Obama more (or less) during certain times of the month, people react more (or less) strongly to hurricanes with male names, people each more (or less) soup from bigger bowls, subliminal smiley faces make people more (or less) supportive of immigration, etc. The hitch always comes with the purported size of the effect, along with the claim that the effect is persistent and did not just happen to show up in that one study.
Andrew, I’ve mentioned it here before but never (that I remember) got an explanation. What about ESP is so implausible to you?
This position may have made sense before radio, wifi, bluetooth, etc but now you are surrounded by invisible/inaudible (to you) information all the time. Almost all robots we build have “ESP”, and if it is sufficiently compressed/encrypted/camouflaged it will look like noise.
The implausible thing is that after billions of years of evolution not a single organism has evolved to take advantage of this opportunity. So if that really hasn’t happened we need an explanation for why.
I think the existence of radio, bluetooth, etc., argue *against* your position — we’re now exquisitely sensitive to the ways in which energy and information can be transmitted, and so should be able to discover minute signals above noise. However, we don’t. There are, moreover, all sorts of things that billions of years of evolution haven’t been able to produce, other than via human technology — semiconductor-based transistors, for example, can switch at ~ 1 GHz while our neurons work at ~ 1 MHz; despite its wonders, there isn’t a clear evolutionary path to solid-state engineering of silicon crystals.
I agree, however, that there are areas of human perception that are not well understood, for example detection of magnetic fields. This, for example, is very well done, really fascinating, and severely under-studied: https://www.eneuro.org/content/6/2/ENEURO.0483-18.2019 (see also https://maglab.caltech.edu/). I would trade a million irreproducible, p-hacked psychology studies for even one more of these.
Why do you think a bunch of crappy studies would be able to detect a signal evolved over millions of years to avoid adversaries? It may be as simple as “threat” vs “all clear”. I doubt it is actual transmission of images or numbers like most of these studies seem to look for, but I have never studied that literature.
I think he’s saying that he would gladly prevent a million crappy studies from happening if he could instead just get a few more of the really high quality studies on magnetism detection or similar.
I did understand that. But what studies have been done to ‘to detect a signal evolved over millions of years to avoid adversaries… as simple as “threat” vs “all clear”.’
If there have been studies done that could be reasonably expected to detect such a signal I would like to see it.
Not that I think ESP is plausible, but there are certainly species thsr detect invisible/inaudible magnetic fields.
It’s certainly true that there are more than the traditional 5 senses, that we probably have senses we’re yet unaware of, that there’s precedent for other animals that sense electromagnetic fields outside the visible range, all that is fine.
That’s quite a different hypothesis than the very specific claim that people can tell the shape on the other side of a card or read minds or something.
As I mentioned above, imagine you send such a signal (an image of what you are seeing) then the adversary/predator may know exactly what you are seeing. That seems unlikely to be advantageous in a natural selection sense, so don’t look for ESP there. Instead it will be a threat/safe signal, or something like that.
My point stands that it seems implausible we use ESP-type transmission all the time now but supposedly not a single organism does. It is far more likely that “ESP” is widespread but we are missing it. Or it is a very bad idea for some reason.
somebody –
> That’s quite a different hypothesis than the very specific claim that people can tell the shape on the other side of a card or read minds or something.
I agree. It seems to me that thinking people can use some ESP sense in a way that enables them to know what card was selected in another room is a classic case of people picking a way to measure something just because their imagination limits their ability to think of measures. If some kind of ESP were to exist in some fashion, it could manifest in so many ways that looking for it by asking someone to picture a card in another room seems funny to me. Reminds me of the logic that extra terrestrials can travel here from other galaxies but can’t prevent people from capturing fuzzy cell-phone images of their spaceships.
On the other hand….hearing about this (galvanic skin response) phenomenon below (not without its critics) does seem like a more plausible way that we have perceptions that we’re not always aware that we use.
f
https://en.wikipedia.org/wiki/Iowa_gambling_task
Reminds me of how I can be talking in my wife in the other room and know (without conscious awareness) that I said something that pissed her off just simply by a split-second delay in her response or the most subtle of alterations in her tone.
I realize how trivial this sounds, but I wonder if the “two fonts” angle was a big part of why this blew up. That’s how I first heard about it, from some colleagues making font jokes. And I saw a good amount of that going around Twitter. Clearly that piece isn’t important from a substantive perspective, but it makes it memorable.
If the after numbers were “before + RANDRANGE(0, 50000)” then how did they get an effect? Did they add a different range of random numbers to the control and experiment?
Is there any version history in Excel files? You could imagine the insurance company doing one sort of fraud, and then the researcher doubling the data to improve the p-values. I’m not sure why the insurance company would be motivated to double the data.
I’m thinking it is because either
(1) the condition assignment failed to be random. Or
(2) it could actually have been: before + coef * condition + randrange(0,50000).
A simple distribution plot of the difference values wouldn’t necessarily reveal that.
Ariely gave the talk to NPR in 2017, before the issues came up, so the 2019 study doesn’t cast suspicion on his NPR story. https://twitter.com/taranoelleboyle/status/1429066878513713162
“2020 episode featuring Dan Ariely [was] a repeat of a podcast that first aired in 2017”
There’s also this story about Ariely’s shredder method not being replicable: https://fraudbytes.blogspot.com/2021/08/top-honesty-researcher-dan-ariely-has.html
Maybe a lot of people are kicking Ariely because, as you note, this alleged fraud happened at the same time as his 2012 book about dishonesty.
Or maybe he, through the *multiple* past issues like the earlier replication problem AND a new report that he, without institutional review board approval in advance, gave participants in a research project electric shocks, maybe he’s pissed off a lot of his academic peers and the long knives are out.
That said, setting aside the wonder at why this one has blown up so fast? Let’s just say that it’s good that it has. My thoughts: https://socraticgadfly.blogspot.com/2021/08/dan-ariely-alleged-fraudster.html