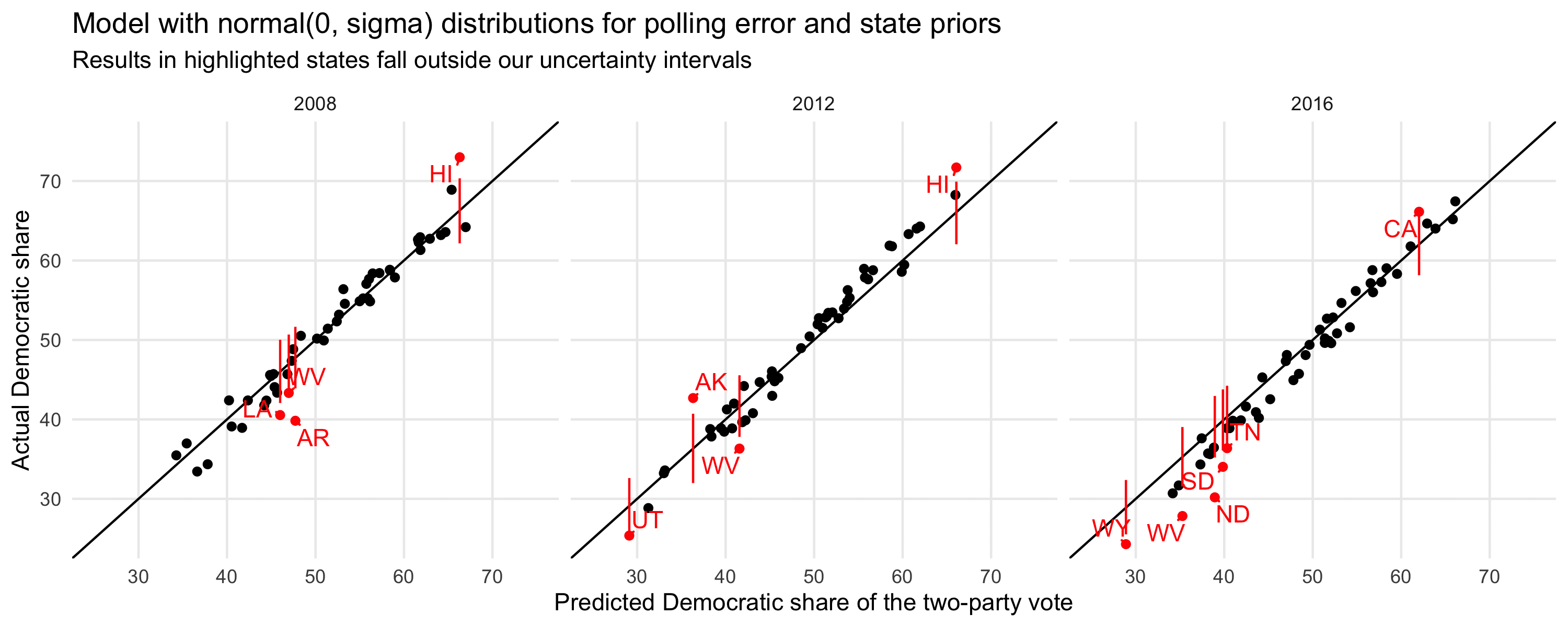
Following up on the last paragraph of this discussion, Elliott looked at the calibration of our state-level election forecasts, fitting our model retroactively to data from the 2008, 2012, and 2016 presidential elections. The plot above shows the point prediction and election outcome for the 50 states in each election, showing in red the states where the election outcome fell outside the 95% predictive interval. The actual intervals are shown for each state too and we notice a few things:
1. Nearly 10% of the statewide election outcomes fall outside the 95% intervals.
2. A couple of the discrepancies are way off, 3 or 4 predictive sd’s away.
3. Some of the errors are in the Democrats’ favor and some are in the Republicans’. This is good news for us in that these errors will tend to average out (not completely, but to some extent) rather than piling up when predicting the national vote. But it also is bad news in that we can’t excuse the poor calibration based on the idea that we only have N = 3 national elections. To the extent that these errors are all over the place and not all occurring in the same direction and in the same election, that’s evidence of an overall problem of calibration in the tails.
We then made a histogram of all 150 p-values. For each state election, if we have S simulation draws representing the predictive distribution, and X of them are lower than the actual outcome (the Democratic candidate’s share of the two-party vote), then we calculate the p-value as (2*X + 1) / (2*N + 2), using a continuity correction so that it’s always between 0 and 1 (something that Cook, Rubin, and I did in our simulation-based calibration paper, although we neglected to mention that in the article itself; it was only in the software that we used to make all the figures).
Here’s what we found

There are too many p-values below 0.025, which is consistent with what we saw in the plots with the interval coverage. But the distribution is not quite as U-shaped as we might have feared. The problem is at the extremes: the lowest of the 150 p-values are three values of 0.00017 (even one of these should happen only about once in 6000 predictions), and the highest are two values above 0.9985 (and one of these should happen only about once in every 600 cases).
Thus, overall I’d say that the problem is not that our intervals are generally too narrow but that we have a problem in the extreme tails. Everything might be just fine if we swap out the normal error model for something like a t_4. I’m not saying that we should add t_4 random noise to our forecasts; I’m saying that we’d change the error model and let the posterior distribution work things out.
Let’s see what happens when we switch to t_4 errors:
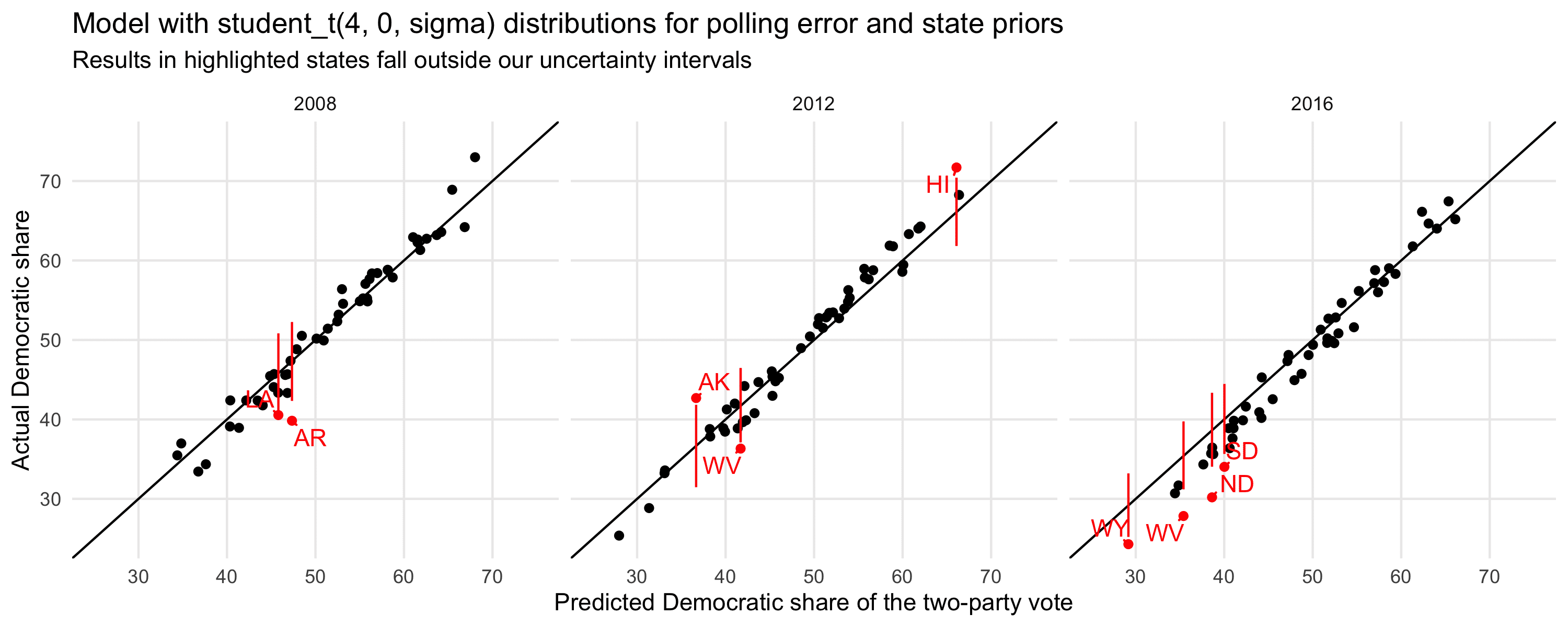
Not much different, but a little better coverage. Just to be clear: We wouldn’t use a set of graphs like this on their own to choose the model. Results for any small number of elections will be noisy. The real point is that we had prior reasons for using long-tailed errors, as occasional weird and outlying things do happen in elections.
At this point you might ask, why did it take us so long to notice the above problem? It took us so long because we weren’t looking at those tails! We were looking at national electoral votes and looking at winners of certain swing states. We weren’t checking the prediction for Obama’s vote margin in Hawaii and Trump’s margin in Wyoming. But these cases supply information too.
We have no plans to fix this aspect of our model between now and November, as it won’t have any real effect on our predictions of the national election. But it will be good to think harder about this out going forward.
General recommendation regarding forecasting workflow
I recommend that forecasters do this sort of exercise more generally: produce multivariate forecasts, look at them carefully, post the results widely, and then carefully look at the inevitable problems that turn up. No model is perfect. We can learn from our mistakes, but only if we are prepared to do so.
The one thing that might be worth noting is that West Virginia seems to be not only a “consistent outlier” (is that an oxymoron?) in all original forecasts but also a “robust outlier” (gotta be an oxymoron) surviving in 2/3 scenarios with t_4 errors.
Could it be that WV is a non regularly polled red state that “should” be more of a blue state given its similarities with other states? Its “consistently outlier” behaviour seems to be also consistently overestimating the democratic vote share.
I agree the polling is clearly overestimating Dem share. But it’s not clear to me why – even with less intensive polling – this would be so consistently biased.
IMHO, based on absolutely nothing, this looks like a Dewey-defeats-Truman problem: I suspect that there are WV residents who both: (1) for some reason are consistently difficult to poll (inaccessible? no telephone, even in 2000s?); and (2) are consistently active, reliable voters.
There is, of course, another possibility that would explain data that appears increasingly incongruent, but that’s perhaps not helpful.
My general impression is that West Virginia is indeed an outlier in lots of ways (not just in this study).
It is kind of unusual – partly because it’s a state that is “all Appalachian”; even PA and TN aren’t. (Of course, it was originally just the Appalachian part of Virginia before the Civil War!)
“We have no plans to fix this aspect of our model between now and November, as it won’t have any real effect on our predictions of the national election.”
I for one would appreciate you just implementing the change in your online model! It seems like you’ve already done the work of rewriting it.
Andrew and Elliott:
Thank you for looking into the tail miscalibration problem that I brought to your attention a week ago. I’ll need to think through this blog post, but some quick questions:
1. How did you obtain the 95% state prediction intervals in the first plot (normal errors)? The widths of the intervals look different from 2 * 1.96 * the SDs of the state’s simulation samples, and from their empirical 2.5-97.5 percentile intervals.
Your R scripts estimate “se” as (high – mean)/1.68, where “high” is the 97.5th percentile of the state’s samples and “mean” is their mean. Are your 95% prediction intervals 2 * 1.96 * se? I don’t know where 1.68 comes from. Excuse my ignorance, where does 1.68 come from?
2. Could you post the stan file for the student t model? It would be instructive. Thank you.
Fogpine:
The intervals in the graphs are just the (0.025, 0.975) quantiles from the posterior simulation draws. At least that’s what they should be! We have enough simulation draws that it makes sense to just do these directly without messing around with normal approximations. Even when the error model is normal, the posterior distributions won’t be normal.
Andrew:
Yes, that is what I used for my analyses: the 0.025 and 0.975 quantiles reported as “low” and “high” on your github page. Yet my analyses showed different results than yours, including substantially worse calibration.
If I change my analyses to use 2 * 1.96 * se, I get calibration results more similar to yours. Here, “se” is the value reported on your github that is calculated with the strange (to me) 1.68. No sense of where that 1.68 comes from?
You’re right — they need to be logit-transformed first. After that they are either normal or so close I can’t tell the difference.
Fogpine:
The issue is that, for some reason, at some point, I was exporting 90% confidence intervals in our 2008-2016 models rather than 95% intervals. So we got the standard deviation from that by dividing by 1.68, which is a typo because it should be 1.64.
All these errors are fixed in the most recent local copy of the repo and I’ll push it to GitHub later today.
Elliott:
Thank you for looking into that. Please note that the “1.68” bug needs to be fixed in multiple places — I see 11 appearances of this bug in the current Economist 2020 model code. If this were my model, I’d think about getting a code review from someone with fresh eyes.
For what you call “se”, can I suggest that you replace your current calculation with sd(x)? (high-mean)/1.96 won’t be correct for the normal-error model predictions (because of the logit link) and won’t be correct for the t distribution either.
Because of the bug, the results and figures in this blog post are incorrect too.
As Ian says below, thank you for pursuing this open process.
Fogpine:
Please pull again. They have been removed.
And either way, please see the code in the updated readme.rmd. We are calculating p values with a different formula and confidence intervals with the quartile function. I am pretty sure the figures are correct this way.
* not `quartile` but `quantile`
Elliott: Thanks, but of the 11 occurrences of this bug that I saw, 9 are still in the code I see on github.
I still have to check the code from your calibration figures — they are so different from what I got that one of us has to be wrong. Mine show substantially worse calibration. I’ll check my results more carefully and get back to you afterwards here. That should save you some time in the case that it is me who is wrong.
Elliott: Do you have any reactions to my previous comments about the miscalibration issue? They can be found in the following threads:
https://statmodeling.stat.columbia.edu/2020/10/01/how-to-think-about-extremely-unlikely-events-such-as-biden-winning-alabama-trump-winning-california-or-biden-winning-ohio-but-losing-the-election/#comment-1526387
https://statmodeling.stat.columbia.edu/2020/10/12/more-on-martingale-property-of-probabilistic-forecasts-and-some-other-issues-with-our-election-model/#comment-1534422
The most relevant points are probably:
* State events assigned 8% tail probability by the Economist model actually occurred in 18%, 16%, and 18% of instances in 2016, 2012, and 2008. Similarly, state events assigned 1% tail probability actually occurred in 10%, 8%, and 6% of instances in 2016, 2012, and 2008. So when the Economist model says Trump has an 8% win probability and a 1% probability of winning the popular vote, why should you or I trust those numbers?
* Events with model-assigned probability of less than 1 in 50 000 have actually occurred in the 2008-2016 elections.
* I tried a hacky way of adding wide tails — it increased Trump’s win probability by 50%.
* The difference between predictions of normal- and wide-tailed models gets larger as Trump’s chances diminish. So if Trump’s chances continue to diminish, this is a problem that gets worse rather than going away.
It’s possible the numbers in that first bullet point are wrong because they seem to be different from yours, but that will take a while for me to check. I’ll check that alongside the calibration plots.
I appreciate the open process you’ve adopted here. It would be great if more researchers took this public self-critical approach.
The *trend* when this happens seems to be:
– the losing party ends up worse, (13 of 14, or 8 of 9, (1st vs 2nd set of graphs)), and
– in small population states,
– where the winner’s projected margin of victory was large. (10+ or greater)
p= 0.00017 is probably based on one point from 6000 posterior simulation draws, which itself has very large variance and makes it challenging to compare that histogram directly.
I really wonder why the 538 model gives Trump a 5% chance of winning the *popular vote*. Tails or not – what could possibly make that large a change in the next 19 days?
If my quick read of your methods your code is correct, it appears that all of the states are modeled as having the same variance (the diagonal of the state covariance matrix is constant). However, the estimates of the trends are more precise for some states than for others due the differences in how much polling each state receives. We have much more information about the vote share in Florida than in Hawaii.
As an illustration, the median state had 21 polls in the final month before the 2016 election. Starting with the 2008 outliers, Hawaii had just 3 polls in the final month, West Virginia had 5, Louisiana had 7, and Arkansas had 6. For the 2012 outliers, WV had 2 polls in the final month, Utah had just one, while neither Alaska nor Hawaii had any polling at all. And for 2016, we have Wyoming with 9, none for West Virginia, 10 for South and North Dakota, and 19 for Tennessee. From what I can see, all of the outliers had a below-median number of polls for their given year in the final month of the campaign, with the sole exception being California in 2016.
I suspect that this pattern would hold more generally if you were to plot the prediction error against the number of polls in each state. Isn’t this what we would expect via the CLT? But by imposing a constant variance across all states you would always systematically underestimate the errors in states without polling (and overestimate in states with extensive polling). In this case, we wouldn’t expect that uniformly increasing the width of tails for all states would have much of an effect, as you observe.
A quick and dirty way to test this would be to do a GLS-like adjustment to the state covariance matrix, perhaps by weighting the diagonal by the number of polls in the last month.
Mj:
Equal variance in each state in the prior is not the same as equal variance in the posterior. States with more polls will have more information in the likelihood, thus more information in the posterior for these states.
That’s true, but it’s not exactly what I was trying to say. I’m coming at this from a frequentist perspective, so forgive my imprecise language.
My point is that the likelihood function itself is misspecified. The “standard errors” (or whatever the Bayesian equivalent is called) of the parameter estimates is what is driving the differences in the posterior variances, but the ex ante distribution of the variance for each state is different due to the difference in polling.
Taking an extremely simplified approach, your model is Y = f(X) + sigma, and your likelihood function assumes that the diagonal of sigma is constant. But this is not the case. The errors are certainly heteroscedastic, but the likelihood is imposing homoscedasticity.
Here’s another way of seeing it: Wyoming had 9 polls in October/November of 2016. North Carolina had 99 polls in the same time frame. By the CLT, we would expect to have a much more precise estimate of North Carolina’s vote than Wyoming’s. But the CI for Wyoming is *smaller* (+-0.035) than the CI for North Carolina (+-0.041). According to your model, we are less confident in the vote share for North Carolina than Wyoming, despite North Carolina having an order of magnitude more polling in the final month.
I plotted the range of the confidence intervals for each state against the number of polls in October/November:
https://imgur.com/H1WfQdY
The “outlier” states all have smaller CIs than average (they are more precisely estimated) despite all having far fewer polls than average (excepting California). If anything, more polling is associated with *less* precise predictions. I don’t see how this could possibly be the case if the likelihood function were properly specified.
Mj:
Given the high correlations in state swings, I’d expect all the states should have similar uncertainties. But I’d think that we should still be a bit more uncertain about states with fewer polls, so if that’s not happening, then that does seem to suggest we messed up somewhere, at least for the model we’re using for those previous elections.
Andrew:
I’m not sure why I should expect a high correlation across states to dominate when the difference in the number of polls across states is an order of magnitude. If I naively think of the “mean of means” of each state’s polling as a single mean estimate with the sample size equal to the sum of all the sample sizes from the individual polls, the variance of mean estimate for Florida is sigma/342 (n=117,367 for Oct/Nov of 2016), while the variance of the mean estimate for Wyoming is sigma/62 (n=3,872). I haven’t simulated it, but I suspect that the off-diagonal covariances across states would have to be MUCH larger than what you estimate in the data to make the variance of each state’s prediction appear similar to one another, given the huge differences in sample sizes that are used to estimate the mean vote share.
Your model predictions bear this out as well. Here is a plot of the (squared) prediction error of the posterior mean against the number of polls (top) and the total number of people sampled in October and November (bottom):
https://imgur.com/ysJ0DkU
You can see a strong downward trend that persists even if you remove the previously identified outliers (in red). The model says that prediction accuracy is decreasing in the frequency of polling, but the estimated confidence intervals are (roughly) constant over the same domain. Those two facts appear to be contradictory. The first fact (prediction accuracy increasing in the number of polls) seems quite intuitive to me–this is what I would expect to see given the large differences in polling frequency. In terms of the point estimates, the model is “more uncertain about states with fewer polls”–it’s just not reflected in the standard error estimates.
Despite my belief, however, I STRONGLY disagree with the assessment that you must have “messed up somewhere,” and I’m deeply sorry if I gave you the impression that that was the point I was making! All I’m trying to say is that the “long tails” discussion seems like a red herring, simply because it appears to me to be a classic story of heteroscedasticity. If this were a linear regression, the solution would be as simple as using Huber-White errors. I suspect the fix is similarly as simple in your model. And even if I’m right (a big “if”), I doubt it would have any meaningful effect on your model. The variance in predicted outcomes seems to be correct for the swing states (which have a lot of polling), which is all that really matters.
MJ and Andrew:
On the model link scale, widths of the 95% intervals are narrower for states with more Oct-Nov polls. In other words, (logit(high) – logit(low)) reduces for increasing number of polls, where “high” and “low” are the interval limits. So the relationship is as should be expected on the link scale.
This suggests that MJ’s perceptive observation of narrower outcome-scale intervals for less-polled states results partly from a combination of
* Fewer polls are performed in non-battleground states
* Non-battleground states had Clinton vote shares closer to 0 or 1, where intervals are shrunk more when using a binomial_logit model.
Overall, I think this suggests less problem with the Economist model than you may anticipate. However, maybe I’m missing the point of MJ’s post — excuse me if so! Also, I still have the concerns about the tails mentioned elsewhere.
Here are plots:
On the outcome scale: https://i.postimg.cc/tJj7Fgnh/intervals-vs-n-polls-outcome.png
On the link scale: https://i.postimg.cc/tJj7Fgnh/intervals-vs-n-polls-outcome.png
Notes:
The outcome-scale plot should have identical results to MJ’s, but they are only similar. I don’t know why there are any differences, but it may be due to different definitions of poll dates.
DC isn’t on the plots for consistency with MJ’s plot, but DC follows a more extreme version of the same pattern as other states/regions.
Excellent catch, fogpine! I completely missed that in the code. That does raise some questions with me about how we should be thinking about uncertainty in this model. Could the “tail” issues simply be an issue of choosing a different link function?
Regardless, the evidence I presented above was not something that I consider a distinct problem with the model, but rather evidence in favor of a specific cause of the previous tail problem that you (fogpine) identified. Basically what I’m saying is that the tail problem isn’t a tail problem at all (to paraphrase Walter Sobchak, “the tails are not the issue here, dude”). In other words, the problem is not that Wyoming had a low probability of voting for Clinton, but rather that Wyoming had low polling. The heteroscedasticity problem is masquerading as a tail event problem. And while I can see how the model does account for polling when calculating prediction intervals, what I’m suggesting here is that there is an additional channel by which we would expect polling frequency to influence intervals that is not being modeled.
I’ll have to give the code and the associated publications a close read. I’ve been avoiding this so far, but I think I’ve reached the limit of where pure intuition can take me here.
The t_4 revision reminded me of an amusing, ancient computation: What t_v is halfway between t_1 and t_oo in KL. Answer: v = 3.43, or so, so 4 is already quite normal. Maybe you should try t_3.
Elliott and Andrew:
It looks like you have been using the incorrect stan model to backtest for 2008 and 2012. Although you use poll_model_2020.stan for the 2020 predictions and the 2016 backtesting, you use a different model (poll_model_2020_no_mode_adjustment.stan) to backtest for 2008 and 2012 on github. I’m not sure exactly how long this issue has been present, but at least a few months.
You can check the presence of the issue by looking at the figure titles on the github readme page, and also by going into the final_2008.R and final_2012.R scripts. It seems important because I’m not sure how one can backtest correctly when using a different model, but maybe there’s an explanation I don’t know about.
I’m also not sure if the issue affects the calibration figures included in the blog post above, or only your earlier testing. However, I am still getting different calibration results than you, and maybe this is why. Correction of the other bug Elliott mentions above (95% and 90% intervals being switched in the script) has affected the calibration analyses for me by improving calibration.
Thanks again for posting the backtesting code. I’m sure other election prediction models have issues no one ever hears about because the backtesting code isn’t public!
Fogpine:
No, the right model for 2008 is the one without the mode or population. That’s because the polling data we have for 2008 and 2012 doesn’t have the right population of mode variables. The source we used didn’t have those data. So the way we’ve written it is correct.
Elliott:
Ah, thanks very much. I now see it is unavoidable for you to have to backtest with a different model if you want to take advantage of newer mode and population information. Hopefully, this will help me get the t distribution running too.
Andrew, Elliott, et al.:
Thanks for continuing to post about the Economist model and for helping me understand how the backtesting worked. I’ve continued to look into the issues of tail miscalibration that I raised before. Below, I summarize all that I’ve found to date and why I think it is important. In short, it is important because correcting the Economist model’s tail miscalibration issue substantially changes the win probabilities of presidential candidates.
— Presence of miscalibration —
The Economist model appears to be substantially miscalibrated in the tails. For example, state election results fall outside prediction intervals much more often than they should in 2008-2016 backtesting. Here’s a figure showing this:
https://i.postimg.cc/FHr70gf9/tail-calibration.png
As can be seen, actual state election results are outside 90% intervals about 1.8 times as often as they should be, outside 95% intervals about twice as often as they should be, and outside 99% intervals about six times as often as they should be. The increasing pattern is as expected for a model with too-narrow tails.
The model’s overall calibration can also be judged by asking what probability the model assigns to state outcomes as or more extreme as the set of outcomes that actually occurred in 2008-2016. This p-value appears to be less than 1 in a million. (For details, please see the end of this comment.) In other words, according to the Economist model, the actual 2008-2016 election outcomes are so unlikely they should not have occurred.
— Consequences of miscalibration —
The figure and p-value indicate miscalibration, but does the miscalibration importantly affect predictions of the candidates’ electoral college and popular vote shares? Yes. Here is evidence for this:
Note that tail prediction interval problems are improved by modifying the Economist model to use a wide-tailed t distribution with 3.5 degrees of freedom (DoF), as seen here:
https://i.postimg.cc/g222xz5j/tail-calibration-w-t-dist.png
However, when using the wide-tailed model, predictions of the Democrat candidate’s electoral college vote share are importantly changed in at least 2 of the 3 backtested elections. This can be seen from CDF plots of predicted electoral college vote share. (The first figure shows the overall results and the second is zoomed-in on the 270-vote threshold, which makes the changes clearer.)
https://i.postimg.cc/htzNyNQM/ev-cdf.png
https://i.postimg.cc/26wtLDgj/ev-cdf-zoom-in.png
With the wide-tailed model, the probability of the Democrat winning the popular vote is also importantly changed in at least 2 of the backtested elections, though one cannot see it without zooming in on the 50% threshold:
https://i.postimg.cc/1z17WXQ5/pv-cdf.png
https://i.postimg.cc/BZzgYb59/pv-cdf-zoomed-in.png
In summary, it appears that miscalibration importantly affects the electoral college and popular vote win probabilities that the Economist model assigns to backtested elections. The miscalibration problem is both present and consequential.
What could fix the issue? Using a t distribution with 3.5 DoF could help, but away from tails its prediction intervals seem to overcover, so it isn’t a problem-free solution. Modifying the DoF to 4 does not fix the overcoverage and causes tail undercoverage again. Modifying the DoF to 3 causes overcoverage everywhere. However, I have been adding the t distributions in the stan files only where they already appear in commented-out form. Perhaps a different way of adding heavy tails would be better, I don’t know.
I’m not sure quite where to post this comment as the thread is old, so I may repost it if it become relevant elsewhere.
— P-value estimate methods —
The p-value can be bounded by noting that, for any election year and irrespective of between-state correlations, the model-assigned probability that at 1 least state’s outcome occurs in the left or right p percent tails of the model’s predictive distribution is at most min(1, 2 * p * n), where n is the number of states. For example, the model-assigned probability that at least 1 state’s outcome occurs in the state predictive distribution’s left or right 0.1% tails is at most 2 * 0.1% * 51 = 10.2%.
Taking the state outcome most different from model predictions in each election year and noting the independence the model assigns to results across election years, the p-value bound is (2*0.0000001*51)*(2*0.0043*51)*(2*0.00007*51), which is less than 1 in a million.
Additionally, estimating the tiny probabilities required assuming each state’s predictive distribution was normally distributed on logit scale. Though I think this is correct, I am not completely sure. An alternative is to estimate percentiles from N simulation draws as (2*X+1)/(2*N+2), where X counts the draws less than the outcome (this uses the continuity correction previously mentioned on this blog). The estimated p-value bound is then about 1 in 8800.
Under a logit-scale multivariate normality assumption, better p-value estimates could be obtained from Mahalanobis distances, but I did not pursue that.
Fogpine:
If you go from a normal to a t_3.5 distribution, you’ll want to correspondingly change the scale parameter. But, yeah, there are lots of decisions to be made here. Once we consider longer-tailed errors, we’d want to consider them at the state level and also at the national level. I’m not so concerned about p-values because we already know our model is wrong, but in any case this is one of many aspects of the model that we should look into.
Andrew:
I think an issue is your statement that fixing the tail miscalibration won’t have any real effect on your national election predictions. For example, you say this in the post above and several times in previous blog posts. But that’s not correct — fixing the tail miscalibration DOES have real effects on the national election predictions. For example, in backtesting it increased Trump’s 2016 win probability by about 50% and more than doubled McCain’s win probability for 2008! (See the electoral vote plots in my post above.)
Yes, but the problem with the model isn’t only a few outliers — the p-value is so extreme because the problem is larger than that. If you look at the prediction interval figure in my post above, you’ll see that even 85% prediction intervals from your model substantially undercover. And though this can’t be seen in the figure, the prediction intervals start to deviate from reality at around the 75th percentile prediction interval. So the miscalibration is affecting results for roughly 25% of states.
Fogpine:
I think it might be worth creating your own Github repo with your analysis so it is reproducible and then referencing it in an issue on the Economist GitHub describing the issue.
N:
That’s a good suggestion, but I’m not sure it works as a practical matter. The Github repo code would have to be refactored to allow fully-scripted comparisons between fits of multiple models for the same year and that’s too much work for me. Also, getting the repo code running on my machine required many small compatibility edits that probably break it for others (file path format changes due to operating system differences, switching from cmdstan ro rstan…)
As an alternative, I’m happy to share code snippets for any specific stan files, functions, or plots you are interested in.
Fogpine:
Even if you don’t share code for a reproducible example, I think it would be worth submitting an issue on Github. The comments section of a blog isn’t really a good place to document/track this discussion. Most people interested in project will go directly to source code.
Andrew & Elliot:
There are only 2 open issues on Github project and one of them is “What is the goal?” and nobody responded. I think this type of discussion might be better shared on the repository, depending on your goals.
Fogpine:
We’ll have to look into it. As noted in my previous comment, I’d expect that if you switch to the t distribution, you’d also reduce the scale parameter slightly so that it wouldn’t make much of a difference in the overall prediction. But I guess a lot would depend on whether these are state or national level errors, so we should definitely look into this.
Another way of saying this is that our headline probability number is sensitive to model assumptions, which is something that we should be aware of!
Andrew:
Thanks, yes I agree with this. I’d add that the Economist model is demonstrably overconfident in the tails, which suggests that it is probably underestimating Trump’s 2020 win probability.
Based on the backtesting analyses I’ve done, my best guess is that correcting the tail miscalibration would increase Trump’s 2020 win probability by between 50 and 150% of the current value (so from 7% to 10.5-17.5%). However, I can’t be sure of the effect since your team doesn’t publish the code that generates your 2020 predictions — if I understand correctly, only the backtesting code is published, but the actual code for 2020 predictions is kept private. Is that to maintain competitive advantage for your group, or for some other reason? In any case, thank you for sharing the backtesting code which is far more than most do.
fwiw, switching from the normal to t model barely changed any of state mean predictions in 2008-2016 backtesting (range mean prediction changes: -0.0021-0.0026, so about 1/4 of a percentage point or less).
Thanks again for being willing to discuss these matters in ways most others are not.
Fogpine:
Hi again. Of course, it depends on the specification, but I have run the model with student_t(4,0,1) tails on the prior and polling error terms and it only decreases the aggregate Biden probability by 3 points.
Of course, we still don’t *know* if that’s the “right” distribution to use. It seems like you’re suggesting something different?
Elliott: Hi!
I saw that commented out in the current poll_model_2020.stan github file — thanks for adding it. All I did was run the model as you specified it, but with with 3.5 degrees of freedom. That resulted in the changes to 2008-2016 electoral college and popular vote shares discussed above and shown in my figures, including a 50% increase in Trump’s stated 2016 win probability and a doubling of McCain’s 2008 win probability.
3.5 was chosen based on my comment from a week ago here: https://statmodeling.stat.columbia.edu/2020/10/12/more-on-martingale-property-of-probabilistic-forecasts-and-some-other-issues-with-our-election-model/#comment-1540126 .
Yes, I agree. I wanted to stick with the closest option to what you had done, simply so my points were most convincing.
fogpine:
Ah, right, I found that by reading the backlog.
I’ll test out the 3.5 model. I suspect it would bring us closer in line with, eg, 538’s current estimates — maybe the increase from 7 to ~13 that you suggest.
However, one issue I’ve run into when doing this in the past is the choice of optimizing for state-level v national probabilities. When I increase the size of the tails for 2016, 2012 and 2008 models, for ex, we get slightly better state brier scores but worse aggregate electoral college probabilities. (This could point to another issue in how we’ve parameterized state-level correlations.)
But it might just say more about tradeoffs in forecasting. As Andrew said in the first post, we mainly looked to fit to overall EC probabilities when evaluating decisions about tails, covariances, etc that aren’t fit directly to data. But which are right? I don’t know!
Elliott:
Thanks!
There are so few national election results (3? 18?) that I don’t think one can even check the calibration of the model for national results. So the state results seem to be the only basis of evidence that can really be used to assess model validity. But I may misunderstand your point, and you regardless have far more experience with election forecasting than I do.
For anyone still reading this thread, please note that I think I’ve found another bug in the Economist model code which affects all of the above.
The bug is reported here: https://github.com/TheEconomist/us-potus-model/issues/21 It’s a very easy-to-make but consequential type of bug.
The bug definitely affects all results I’ve posted to date. I also expect it affects the results Andrew, Elliott, and the Economist team have posted, unless they use different scripts than those currently available on github.
After fixing the bug, the Economist model still has tail miscalibration. Here’s a figure showing the miscalibration after the bug fix:
https://i.postimg.cc/tC5QN2GR/tail-calibration-after-bug-fix.png
Though the Economist model gives Trump a 7% electoral college win probability and a less than 1% popular vote win probability, events it rated as having 7% and 1% tail probability actually occurred 14% and 7% of the time in testing on available data.
However, after addressing the bug, a t distribution with 3.5 degrees of freedom fixes miscalibration issue less than it did in my previous analyses.
Sigh, so the ‘bug’ is actually my problem — it only appears for versions of R before 4.0.0, like I’m running, but not for more recent R versions, like the Economist team presumably used when writing the code.
If your using the Economist model code, please be aware that it is only compatible with R 4.0.0 (April 2020 R release) and later.
The tail miscalibration problem is still present, however.
I think there’s an interesting question about what sorts of “inputs” are being considered.
In a “normal voting environment” you wouldn’t expect a very blue state like CA to go red unless a lot of less-blue-but-still-generally-blue states also did.
And that’s probably true regardless for CA, which is large and diverse.
But I wonder about states where the population is basically concentrated in one urban area. It seems like localized weird events (like extreme weather drastically reducing Election-Day voting) could do weird stuff to these states’ votes. Or something casino-industry-specific could shift NV’s vote without much affecting the states immediately redder than it.