This post is by Elliott Morris, Merlin Heidemanns, and Andrew Gelman.
We have written a lot about both our presidential election model at the Economist and Fivethirtyeight’s since they both launched in the summer. We even wrote a journal article (with Jessica Hullman and Chris Wlezien) about what we can learn from them about Bayseian model testing and the various incentives toward (or against) expressing uncertainty. But it’s fair to say we’ve done a bit more criticizing of 538’s method than our own. Of course, we think ours is “better” (though there’s no way of knowing for sure—we can’t actually run the election 40,000 times) so this makes sense, but there are some things in our model that we’ve been reconsidering over time.
Recall that we think some of the probabilities in 538’s model are implausibly large given both polls so far and the political fundamentals. Some of their simulations have Joe Biden winning by 10 percentage points in Alabama or 25 in Florida, which seem to us to be impossible outcomes today. Still it is hard to gauge the likelihood of these events given the design of their primary state-level graphics (they pick 100 simulations out of 40,000 to represent individual odds, which may exaggerate the perceived probability of tail events) or even to interpret probabilities as low as 1 or 2 in 40,000.
We also think there’s a reason for these fat tails. The 538 model also appears to have between-state correlations that are too low, once you add all its errors; right now it seems to be giving Joe Biden a 50% chance of winning in the electoral college conditional on him losing California, despite the fact that it’s the fourth most Democratic state in the country. But such low between-state correlations necessitates higher state-level errors to arrive at a given target uncertainty for national error.
On the flip side of this is our Economist model, which has high state-level correlations and comparatively skinny tails. This introduces some downstream effects worth taking a second look at.
Various readers have suggested that our high correlations and normally-distributed tails might be leading to some implausible conditional probabilities. For example, commenter Adam wrote:
Your latest simulation contains 13,789 outcomes where Biden wins Ohio. In all cases where Biden wins Ohio, he also wins the electoral college. This is pretty astonishing, I would think. Is it really true that given Biden winning Ohio, Trump has basically no chance (<0.01%) of winning Pennsylvania and Wisconsin? (This never happened in 40,000 simulations.)
We weren’t sure what to think about this particular conditional probability, so we decided to get some context by looking at our simulations for all 50 states.
The chart below plots Biden’s average share of the national popular vote in simulations where he loses, ties or wins in each state:
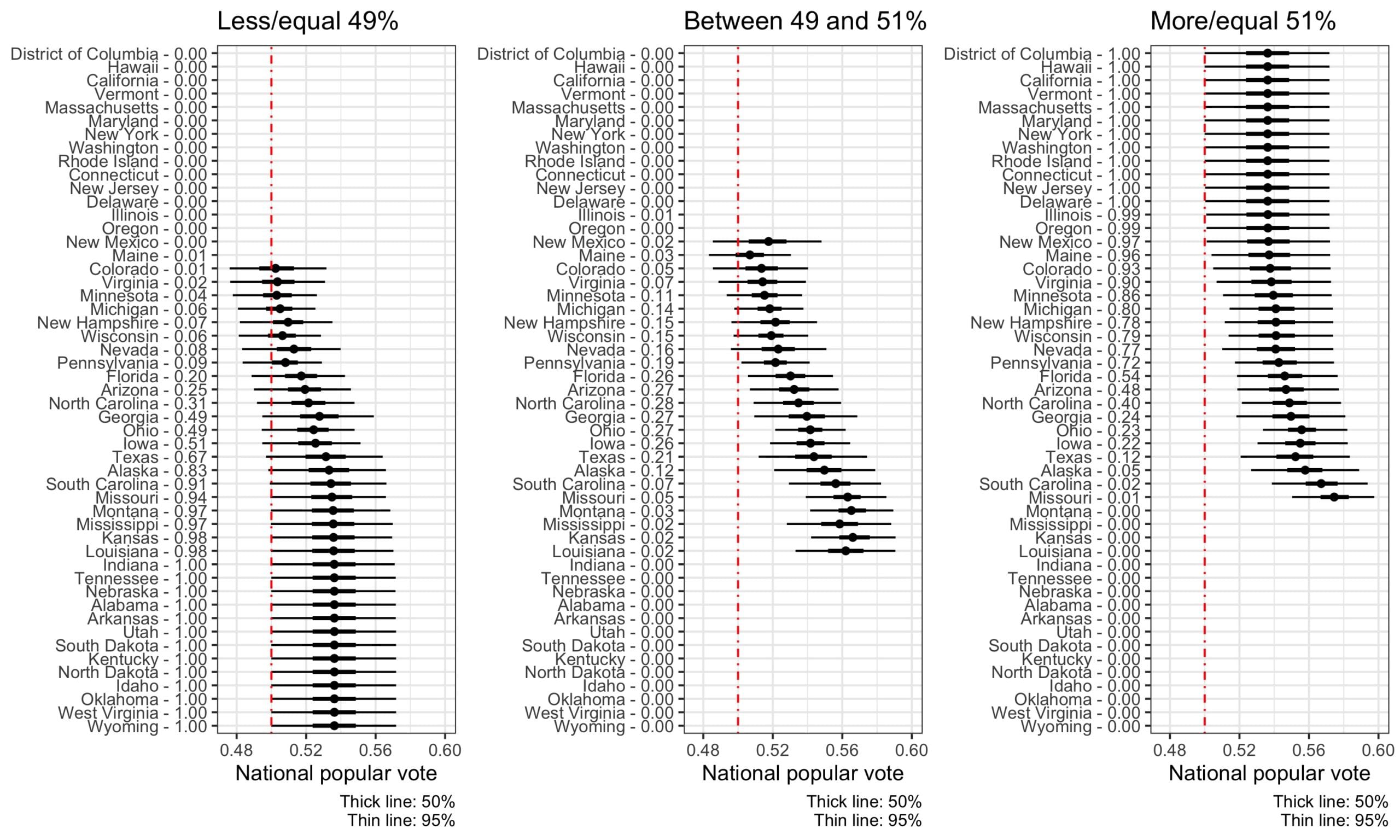
We counted simulations as ties when each candidate got between 49% and 51% of the two-party vote—we had to give this interval some width so as to get enough simulations to be able to compute conditional distributions (here summarized by median, 50% interval, and 95% interval) in each case.
The above graph includes all cases with at least 1% probability in our simulations. For example, in the states at the top of the above graph, Biden is close to a lock—there’s less than a 1% chance of Biden winning less than 49% of the vote, or winning between 49% and 51% of the vote—so we only display the distribution of his national vote share conditional on Biden winning more than 51% of the vote. For the states in the middle of the graph—from Colorado to Missouri—all three possibilities are live options. And the states on the bottom are almost certainly going for Trump.
Now let’s look at Ohio. In the simulations where Biden wins more than 50% of the vote in Ohio, we estimate he would be winning close to 56% (95% interval [53%, 58%]) of the national two-party vote. If Biden pulls off a tie in Ohio, we estimate he’d win 54% [52%, 56%] of the national vote. And if Biden loses Ohio, we still expect he’d win the popular vote, but there’s a small chance he could lose the election (as can be seen from the 95% interval overlapping 50%).
What about the Electoral College? We made the same plots, this time showing the forecast median, 50%, and 95% intervals for Biden’s electoral vote total, conditioning on each of the state outcomes:
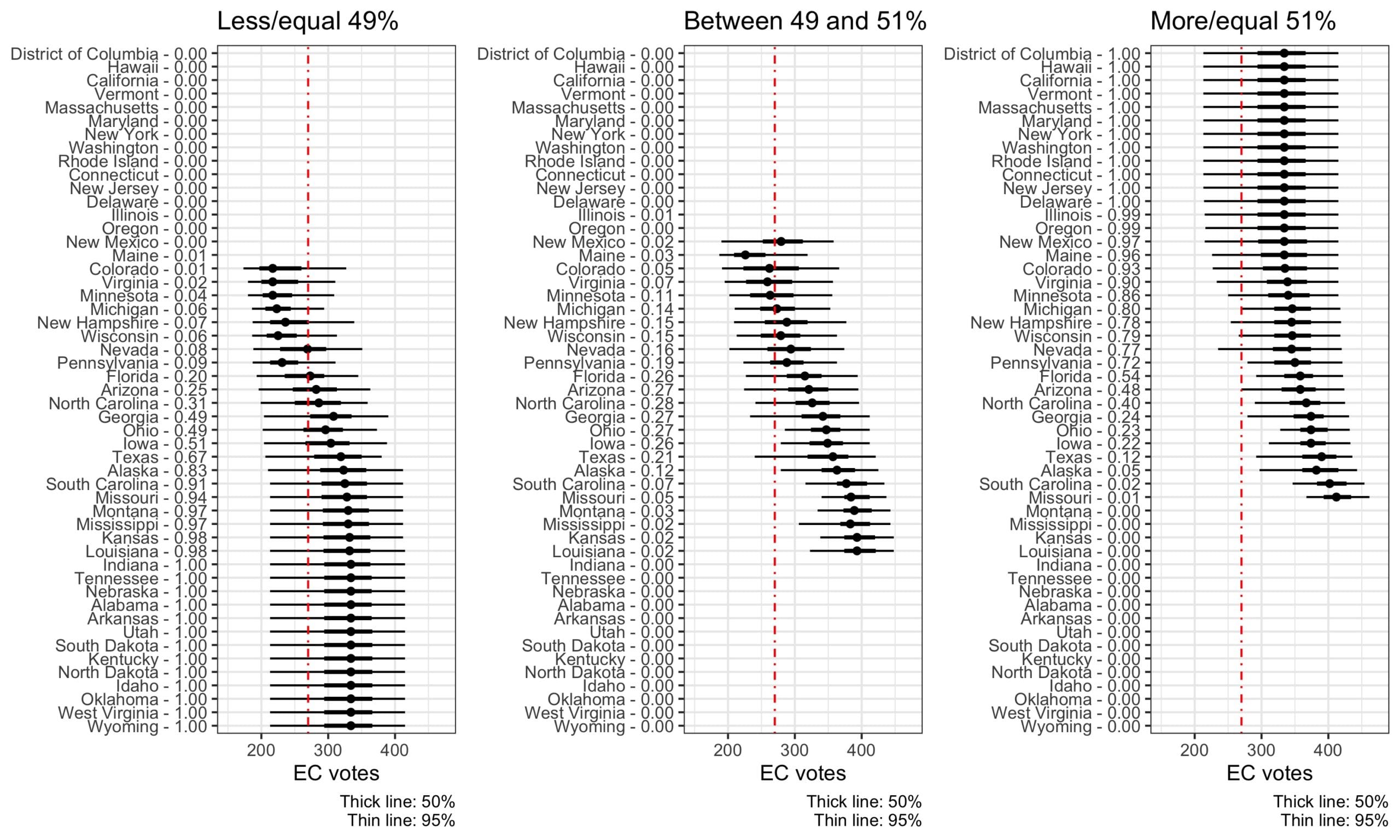
And, indeed, if Biden ties in Ohio, our forecast gives him over a 97.5% chance of prevailing in the electoral college.
Biden’s popular vote and electoral college averages for the conditional Ohio win make sense to us. Given how red the state is relative to the nation as a whole, Biden would have to be doing very well nationally to win the majority of Ohio voters. But the uncertainty in our predictions has raised a flag.
Are we really sure that Trump would win 0 out of 40,000 elections in which he loses Ohio? On the one hand, it’s hard to even imagine what 40,000 elections means. Our model is saying that an upset Trump popular vote victory if he’s losing Ohio would require a never-before-seen combination of polling error and vote swing in one direction for Ohio while a large swing in the opposite direction is happening in the rest of the country. And given the high correlations between states (in fact, in our model, Ohio has the highest average correlation with all other states, which is reflected in its relatively narrow prediction intervals for Ohio in the above graphs) it makes sense to assign a relatively low probability to this outcome. But is 0 out of 40,000 too low?
Given the potential problem here, it might make sense for us to use a fat-tailed distribution in our model. Not quite as fat as Fivethirtyeight’s (which gives Biden an approximate 3% chance of winning Alabama and Trump a 1% chance of winning California Hawaii [see here), but a compromise between the two. At one point, we were using a t distribution with 7 degrees of freedom, but we scrapped it because it didn’t address other issues we were concerned with at the time.
We’re open to feedback here. On the one hand, we can talk ourselves into believing the graphs above. On the other, a forecast probability of less than 0.000025 chance does seem too low. (Or does it?)
To push this further, what’s the chance of Trump winning California? As of two years ago, say, either such event was highly unlikely, but maybe we shouldn’t say impossible—after all, Reagan won 49 states in 1984. But right now, a month before the election with the incumbent president down by 8 points in the polls, with an approval rating in the 40% range, and a dismal economy . . . it’s hard to imagine. (Remember, our model is predicting vote intention, and it’s conditional on all the votes being counted and neither candidate dying, becoming incapacitated, or being removed from the ballot before election day.) For that matter, it’s hard at this point to picture Biden winning Wyoming. Are the probabilities of either of these events less than 1 in 40,000? What about the probability of Trump winning D.C.? Do we call that 1 in a million?
The probabilities of such super-unlikely events seem to us to be essentially unquantifiable with any precision.
A few years ago, we wrote an article, Estimating the probability of events that have never occurred: When is your vote decisive?, where we promoted the idea of estimating the probability of rare events by extrapolating from less rare “precursor events.”
For example, what’s the probability that a single vote would be decisive in a large election? It’s hard to get any direct empirical estimate of the probability of a tied election, but we can empirically estimate the probability that the election is within 10,000 votes, and then divide that probability by 10,000. (See the appendix on the very last page of this article for an explanation of why such calculations make sense even in the presence of possible recounts.)
Unfortunately, we can’t see how one could define precursors for events such as “Trump wins California,” “Biden wins Wyoming,” or “Biden loses the national election conditional on winning Ohio.” We can get a somewhat reasonable estimate of the probability that Trump gets at least 35% of the vote in California (we currently forecast him at 33% in that state), but any model taking him from there to 50% seems completely speculative.
Regarding Trump winning California or Biden winning Wyoming: we could just say: Hey, anything could happen, and we don’t want the probability to be less than 1 in 40,000—but that just pushes the decision back one step. Should we then say that Trump has a 1 in 10,000 chance of winning the state? 1 in 1000? 1 in 100? 1 in 50? Any of these choices has an element of arbitrariness. You could say that 1 in 100 or 1 in 50 is a more conservative choice; on the other hand, assigning too-high probabilities to uncertain events could create problems if this encourages people to overreact to extremely unlikely possibilities. Both the creation and evaluation of such predictions are strongly model-based, and ultimately we have to think of these not as pure forecasting problems but as questions of political science: how wrong do we think the polls can be, and how large do we think swings could be in the month before the election?
If you do want to change our forecast and allow fat-tailed errors—which you can do, as all our code’s on Github!—we recommend you include these fat-tailed errors as a national error term, not as independent state errors. If Biden really does with Alabama or Trump wins California, this would arise from some combination of unprecedented polling errors and unprecedented last-month swings—and, in this case, it’s hard to imagine this happening in just one state.
How do you feel about events like Pennsylvania disqualifying a large number of mail-in ballots while Ohio does not.
It seems that if that were to occur, you might very well have a Biden loss in Pennsylvania and a win in Ohio.
Do you just wish to ignore the possibility of such events? That might be reasonable given how hard it would be to assign a probability to them. But in this case, your forecast should come with a disclaimer along the lines of “Assuming nothing unusual happens with respect to election procedure. . .”
But if you want to avoid such disclaimers, isn’t one way to account for such events to decrease the correlation between states? (In effect, you would say that there could be large state-specific errors in polling.)
“your forecast should come with a disclaimer along the lines of “Assuming nothing unusual happens with respect to election procedure. . .”
It already comes with stipulation that voters are able to express their will.
What makes you think voters have ever been able to “express their will?” The stipulation is that things are more or less like before.
What makes you think they haven’t?
“The stipulation is that things are more or less like before.”
ie, people go to the polls, vote for who they like and their vote gets counted.
I think it comes down to what do you want to learn by modeling. There’s substantial juice to squeeze from the lemon by figuring out what the vote is likely to be if the votes are counted without interference or fraud, or at least no more interference/fraud than the average election. All that we could learn from the model adjustments you suggest is what the modelers’ wild-ass guesses are about out-of-sample X factors.
Sure you can do that if you think you’ve got a business reason to hedge your bets, drive clicks or whatever but I think the search for the truth and opportunity to test hypotheses (e.g., high polarization leading to low volatility) is more interesting and useful.
Put another way, since there is no way to honestly model the likelihood or impact of unprecedented events (e.g., death or withdrawal of a candidate in the last 60 days), all you could do by “accounting” for such things is obscuring the things you can usefully model. Even 538, which includes a big fudge factor for distortions (explained as higher uncertainty based on increased use of mail-in voting) is constantly offering disclaimers that they haven’t accounted for even bigger distortions, such as a meteor strike, a major state refusing to count mail-in ballots, or a state legislature voting to certify electors for a candidate who did not win their state’s vote.
Yeah, for this election specifically, where a number of states have changed election procedures at the relative “last minute” due to COVID, there might be weird individual-state errors.
This wouldn’t require any ‘nefarious intent’ just change in procedures meaning that, say, Pennsylvania has way more invalid ballots (due to being filled out incorrectly) than otherwise ‘correlated’ states like MI/WI.
But the statement that “our model is predicting vote intention” I think excludes these sort of things.
All models are wrong, some are useful. If you propose a change in a model, explain how the change makes it more useful.
The point of this model is to predict an election outcome, whatever that’s worth. It is not to predict the probability of Penn voting one way conditional on Ohio’s voting.
Clifton thinks ballot fraud in Penn makes ballot fraud less likely in Ohio. I think it maybe correlates the other way, which would increase the between state correlation. But without a model and data, what’s the point?
Well, I think one of the difficulties is that a lot of the extremely unlikely – or even just “pretty unlikely” or “surprising” – outcomes depend on stuff that isn’t really predictable from polling etc. and may not be included in the model’s uncertainty.
Like game-changing last-minute news (for example, one of the candidates has some kind of bad health event for example) or much higher ballot rejection rates in one state or something weird happens in Las Vegas and NV has absurdly low Election Day turnout.
And disqualifying a whole lot of ballots in one state doesn’t require or even necessarily imply ballot fraud – it could be a result of unfamiliar procedures in this election.
It occurs to me that this sort of thing is probably asymmetric, since Trump is much more widely disliked than Biden (a very different situation from 2016, where Trump had no political history and Clinton was widely disliked).
So if something like a COVID diagnosis for one of the candidates happens… well probably more people would still show up to vote *against* Trump (even if it were unclear whether Biden or Harris would actually be president) than vice versa.
Bad Github link in the post. Here’s the correct one – https://github.com/TheEconomist/us-potus-model
This is a pretty hand-wavy, but it just feels like I have some kind of innate heuristic prior on ‘something unexpected happens’ that doesn’t allow for the kind of certainty that is implied by a < 1/40000 chance. I can easily imagine things (crazy things, of course) that might lead to the example. For instance, what if Trump starting campaigning on a cynical platform to increase taxes specifically in Ohio and subsidize a swing state like Florida? The probability of this specific thing happening seems extremely small (one in a million?) but because I can think of many similar examples they just go in a mental bucket labeled 'unexpected things' and I slap some small combined probability on that and call it good. This is basically an availability heuristic fallacy I think. It doesn't seem optimal but it might be generally advantageous because the world IS unpredictable in a real sense.
Whether that means it should be included in a model is a different question. It would almost have to be something like: leave the model exactly as it is, but for every output you include a term for "there is an x% chance that this model is completely wrong and missed something absolutely critical".
Jm:
I know what you mean, but there’s still the question of where do you draw the line? See the second-to-last paragraph above.. What’s the probability that Trump wins California? If you don’t want to say 1/40,000, would you say 1/10,000? 1/1,000? 1/100? 1/10? At some point you have to bite the bullet, right?
Trump winning California does seem pretty near zero.
OTOH I could totally see Biden win Alabama and a ton of other traditionally-R states if there is some bad health news about Trump that leaves it uncertain whether he would actually be able to be President. The chance of that is low, since there is very little time remaining to election, but given Trump’s age it probably wouldn’t be 1/40,000 or even 1/10,000 low even without COVID.
I think places like California would still have decent D turnout even if Biden’s health were uncertain, since it’s largely voting *against* Trump. I don’t think the opposite necessarily applies (not that R voters would vote for Biden, but that tons wouldn’t vote).
> The chance of that is low, since there is very little time remaining to election
A few hours after you wrote that, Trump tested positive for coronavirus. There’s now a lot of question as to whether he gave it to Biden during the debate… Maybe neither one of them will be alive by Nov 3
Wow. Yeah that could change things… given that early voting is already happening, the uncertainty itself could have an effect even if it’s asymptomatic.
No argument here about it being arbitrary, but I think you might be able to get a little bit better guess than something that varies over 4 orders of magnitude. I think part of the problem comes from trying to specify a single unlikely event: Trump wins California. That seems really hard, so I have no idea what number to put on it. But you can cheat a little bit by saying what are the chances Trump wins at least one of CA or MA or VT or NY or… essentially integrating over enough unlikely events that you get to some ‘interpretable’ probability. Then maybe you can reasonably say this cumulative probability is definitely in the 0.5-1% range, which is something you can rationally think about.
The only real reason to do this would be to have a way to intuitively check your model output. But that could be useful if you were planning to make more principled changes to, for instance, make the tails fatter.
Jm:
We were thinking about that idea of considering “at least one of . . .,” but I don’t know that this would help much , given that the outcomes are so highly correlated.
It seems like there is a fair amount of uncertainty in the correlation between states, but I don’t fully understand how that is incorporated in the model. I assume there is some prior for the correlation, but I’m not sure how that could be updated based on data from this election cycle. If polling in Ohio is very unusual based on polling in several similar states, does that information update the prior for the correlation between states? If polling matches expectations for related states, does that data reduce the uncertainty in the correlation between states? I guess I am conflating correlation across different election cycle outcomes with correlation between state polling within a single cycle.
N:
We could do some version of what you suggest, but what we actually do is choose a fixed covariance matrix for the states based on old data; we don’t learn anything about from the 2020 polls.
Is the method used to learn the covariance matrix specified anywhere? Based on the github and the Economist page, it looked like it could be based on demographics, how states voted in the past, urbanicity, religiousness, etc, but if it was described in one of the papers or calculated by a script in the github then I must have missed it. I’m wondering if the model might be a little off on states having undergone large shifts in voting behavior the past 4 years. In particular, Virginia has drifted the opposite politically of correlated states such as Michigan and Pennsylvania. Arizona has also experienced a larger change in voter behavior, when compared with Florida and Nevada. Perhaps the covariances would look slightly different after taking into account the 2020 polls, as well as factors such as education, which have become more pronounced over the past decade. While practically this might not affect the predicted outcomes too significantly, I was surprised to see Virginia and Arizona with the same tipping point probability (admittedly low at 4%).
Maybe a more interesting question than “is the chance of Trump winning California <1/40,000 or 1/1,000" is "what does shifting this parameter do to the model's predictions"?
Presumably if you were _just_ interested in Trump winning CA, the answer would be "nothing", since you're not really generating predictions to the third decimal. But if you have a whole background of low-probability events, or if you're tuning your parameters to increase the size of the tails to what you think is reasonable, that could have a significant effect.
The whole thing reminds me of the physics concepts of an effective theory and the renormalization group. When we're working at a certain energy regime of a physical system and we don't know what it behaves like at much higher energies, we can pick some arbitrary, unphysical cutoff behavior, write down the model, and then tune its parameters so that the outputs fit the measurements we take within the physical regime.
Likewise, for the election model, you shouldn't really care whether outlandish results happen 1-in-1,000 simulations or 1-in-40,000 – just pick a tail model, and then make sure the 1-in-10 or 1-in-20 results make sense.
Yariv:
Yes, exactly. The reason to care about these predictions of outlandish events is that they can give us insights into our model and can help us improve it. And we did indeed tune our between-state covariance matrix so as to get reasonable predictions for more predictable outcomes.
I believe it is incorrect, and misleading at best, to say 538 gives Trump 1% chance of winning California.
Their forecast of California (along with other states like Massachusetts and New York) says “Trump wins <1 in 100" compared to their Hawaii forecast of "Trump wins 1 in 100".
Fred:
I wrote that Fivethirtyeight’s forecast “gives Biden an approximate 3% chance of winning Alabama and Trump a 1% chance of winning California” based on their graphics for the two states. Their graphic for California showed 100 dots, 99 of which corresponded to Biden winning California and 1 of which corresponded to Trump winning California. As I wrote, this is an approximation. It could be, for example, that the FIvethirtyeight forecast gave Trump a 0.8% chance of winning California, which is approximately 1% but less than 1%.
I have no idea what you mean by “misleading at best” to report this approximate probability. I’m just reading off their graph.
Fred:
I was curious so I went to the Fivethirtyeight site. Unfortunately it doesn’t seem to have their simulations, but you can click on “Model outputs” and get some summaries. If I’m reading it right, they have Trump’s chance of winning California as only 0.2%. That still seems too high to me, but you’re right that it’s much less than 1%. (As you say, the Fivethirtyeight forecast gives Trump a 1% chance of winning Hawaii, which seems too high too.)
Anyway, given all that, I’m baffled as to why their dotplot for California with 100 dots shows a dot with Trump winning. Sure, this can happen, but if his chance of winning under the model is 0.2%, then with 100 dots you’d expect to see zero that have Trump winning the state.
I actually wonder if the dots on those dotplots are not completely chosen at random. Maybe they purposely try to pick at least one winning dot for each candidate, as a way of emphasizing uncertainty in the outcome. I say this because I also checked Wyoming, where Fivethirtyeight gives Biden a 0.2% chance of winning . . . but one of the 100 dots is a Biden win. Hmm . . . where else to check? Delaware: their model gives Trump a 0.08% chance of winning (that’s 0.0008 if you write it as a probability) but, again, one of the 100 dots shows Trump winning. Same with Idaho (Biden with a 0.4% chance of winning but one of the 100 dots is on his side). Also Oklahoma, NE-3, and New York. They didn’t do it with D.C., though.
I wonder if those plots are programmed to include at least one dot for each candidate, but with DC hardcoded as an exception.
Here’s what the dotplots say:
“A good idea of the range” . . . so they’re not actually saying it’s a random sample.
I wish they’d share their code and simulation output so we wouldn’t have to do this sort of reverse engineering.
Apparently, they are not completely chosen at random:
https://twitter.com/natesilver538/status/1293654976313655296
Definitely
Can I ask why the t distribution was scrapped?
There isn’t enough presidential election data to really check calibration of the model’s tails. Because tail shape can’t be calibrated, using normal tails seems similar to thinking that lighter-than-normal tails and heavier-than-normal tails are equally probable. Yet, in my and (I think) most others’ experience, lighter-than-normal tails are quite rare and heavy tails are common. So, it seems better to use a t distribution.
Is it possible you didn’t tune the degrees of freedom based on personal judgement, but instead obtained that from fits to the data and got unhelpful results? If so, have you considered that, without enough data in the tails, the fitted degrees of freedom could be mostly influenced by the available data near the distribution’s center or shoulder, which can be unrepresentative of the actual, unobserved tails?
Thanks for continuing to write these blog posts on the 2020 model! They are always great to read.
Thanks for the very detailed reply.
If you’re just looking for opinions, I personally feel like slightly fatter tails would make me more comfortable. How much fatter I’m not qualified to say, 0/40000 makes an outcome seem absolutely inconceivable to me in a way that 10/40000 or 40/40000 does not. And I’m just not sure that (Biden wins Ohio but loses Wisconsin and Pennsylvania) and (Biden wins Ohio but loses the EC) feel like quite at that level to me. Just gut instinct on that.
One interesting outcome: the latest (10/01) Fivethirtyeight model had a perfect Biden sweep (538 EC votes) in exactly one simulation. At first I thought it must be a fluke, but then noticed they had seven outcomes with Biden at 537, which I assume are cases where Trump holds NE1 or NE3. Seems too high to me, but once again that’s just my instinct. As you point out in this post, calibrating for unprecedented events is very difficult.
One more puzzling thing that I’d be curious to hear your take on. Fivethirtyeight currently has Biden at 0.424 to win Georgia and 0.538 to win Ohio. You give Biden 0.49 to win Georgia, and 0.42 to win Ohio. So you have the relative probabilities reversed between the two states: think they Biden is more likely to win Ohio than Georgia, you think Biden is more likely to win Georgia than Ohio. What significant differences between your models make this the case? (I must admit that seeing Georgia as a swing state is more surprising to me than Ohio, but that instinct is just based on past elections.)
Always banging on about foundations of probability, I wonder what is exactly meant by “the probability seems to high”. If it’s a subjective probability, obviously it can be too high for one person and fine for another; this whole idea that there is one true probability for these things to happen doesn’t work. Actually it doesn’t work either in a frequentist concept (as I understand it, namely as a thought construct that assists us thinking about these things), because then a probability is defined within a model and different models imply different probabilities; so the fact that a probability is too high in one model in terms of another shouldn’t be that surprising either. Again the idea that there is a single “true” probability doesn’t wash.
I do agree though with Andrew’s point that when exploring implications of a model and maybe criticising it, it can be useful to look at such probabilities, ask whether they “seem too high”, ask, how can they be explained within the model and for what reason do they seem too high, and then maybe see that there’s something missing in the model that we may want to add. I like to say that sometimes the most worthwhile thing about a model is how it’s wrong and how we can learn from that. The danger always is that if we take our own intuition over what the model says, can we trust our intuition more to be right? The attitude when doing these things should not be that “we have a more correct intuition what the true probability is”, because there is no such thing.
This whole discussion is always difficult regarding events that can essentially not be repeated. A probability of 1% means, in a frequentist setup, that in 1 or 100 situations that are exactly the same one should expect the event to happen. If ultimately it doesn’t happen the one time it has the chance to happen, and by quite some margin, this really doesn’t say anything about whether the 1% were too high or about right. We’ve got to live with the fact that this issue can be discussed for long, but reality ultimately will not give anything remotely close to a decision who is right.
“I like to say that sometimes the most worthwhile thing about a model is how it’s wrong and how we can learn from that. The danger always is that if we take our own intuition over what the model says, can we trust our intuition more to be right? ”
Yes what about where intuition agrees with the model but both are wrong?
Going through the model and “correcting” the things that “seem wrong” is just biasing it your existing beliefs and negating the purpose of building it. What’s the point in going to all that trouble if you’re just going to tune it to what you already think?
Figuring out the consequences of what you already think. There are lots of things where even if you know basically “for sure” what certain outcomes will be, other outcomes that are downstream from that or otherwise related are not at all clear. If everyone just automatically knew every logical consequence of every assumption, we wouldn’t need Mathematicians at all, we wouldn’t build models, and we wouldn’t bother to have computers.
“Figuring out the consequences of what you already think. ”
Well if you’re just going to keep pruning to what you already think, then you already think you know the consequences of what you think, right? :)
I’m sure we need mathematicians. But I’m not sure we need statisticians, and I’m very sure we have *way* to many people modelling their beliefs and then claiming that the model is a respectable forecast. That’s a general opinion, not particularly pointed at election forecasts, but there are certainly shades of predetermination in the way Andrew thinks about this.
The upshot is that – at least for the moment – it hardly matters, since Biden is almost a shoe-in, and all this trimming bias is really just fine-tuning the noise.
@jim: “Yes what about where intuition agrees with the model but both are wrong?”
Well, one of my points was that arguably (at least) in a situation like this, where eventually there is only one observation, a “true” probability does not exist. Surely it is not observable, only later we can see whether the event of interest has happened or not. So what then do you mean by “intuition and model both wrong”? “Wrong” compared to what?
PS: I’ve got to admit that I myself used the term “wrong model”, but I meant this *relative* to intuition or another model, as explained in my comment – or in situations in which more can be observed, relative to later observed data.
The thing is, in the Bayesian interpretation of probability, probabilities are **never** observable. They aren’t frequencies, or even limits of frequencies, they don’t exist in the world. They are useful fictions for inference from one set of accepted facts to another set of accepted facts.
probability to a Bayesian is always conditional on a model/knowledge base. The probability basically looks like
Normalize{p( something | parameters) p(parameters | background,assumptions) }
the background and assumptions are assumed true, and assumed to imply the form of the p function over the space of both “something” and “parameters”. We then take observations of “something” which are additional facts we know from measurement, and back calculate new knowledge over the space of unknown parameters.
Although the measurements of “something” are definite facts about the world (or at least about the measurement instruments) the p function itself is not observable. At best we can argue over whether the assumptions really should be allowed to dictate that given form of the p function. It’s a *logical* question, not an empirical one.
In this context then, what it means to have a “wrong model” is that you don’t really believe that the background knowledge and assumptions actually imply the given form of the p function. it should be somehow different in a way that results in lower/higher probabilities for certain events.
This is because of the difficulty of *encoding* knowledge into a formal model.
Daniel said,
“This is because of the difficulty of *encoding* knowledge into a formal model.”
A point well worth emphasizing, over and over again. So often people “fall in love with” their models, and get off into fairly tale land.
You’re right that n=1 is not enough for statistical analysis. We can look at the accuracy of a set of forecasts but that won’t tell us much about how good any particular forecast happened to be. It’s not clear what does the following remark mean in practical terms: “if our stated probabilities do wind up diverging from the results, we will welcome the opportunity to learn from our mistakes and do better next time.”
Right now (morning of 10/2), your model has Biden at a 90% chance of winning while the betting market has him at 60.8% (electionbettingodds.com). Based on the Kelly Criterion, you should be betting 74% of your money on Biden winning in the UK election markets.
You might say you’re not a betting man, but this really is a large discrepancy and I think it would add credibility to your model if you publicly made a big bet on Biden.
Garrett:
I discussed this issue several months ago, in a post entitled, “Do we really believe the Democrats have an 88% chance of winning the presidential election?” with followup here. I agree that this is a big discrepancy. Part of the discrepancy could arise from concerns such as vote suppression which are not in our model (see section 1.4 here), but I don’t think that’s the whole story. I think that bettors are overreacting to the experience of 2016.
Back in June, I looked into the possibility of betting on Biden, but I decided not to, for several reasons. First, I wasn’t quite sure exactly how to do so. Second, it didn’t seem like I could bet very much, at least not on Betfair. Third, I felt kinda bad about using my quantitative social science expertise to win money from people who I think are misunderstanding some aspect of forecasting. I don’t think it’s immoral to bet, and I’m cool about betting on sporting events or whatever, but this particular bet made me feel uncomfortable.
In any case, our model is what it is. It includes some but not all information, and people can feel free to make their own judgments about the evidence.
One point I haven’t seen discussed in detail (but mentioned in Information, incentives, and goals in election forecasts), is that predictions made some time before the election will necessarily carry additional uncertainty due to potential changes in i.e. in the fundamentals before the election, or other unexpected events. Fivethirtyeight claims their model take this into account and applies their priors to races they expect to tighten (e.g. Florida), although the actual mechanics of how they implement this is unknown, because they don’t publish their model. However, the tails of their projected vote distributions have been growing thinner: if you look at their forecast of the vote total in Florida today compared the post about 1 month ago, the implied 95% interval has shrunk from [42%, 60%] to [43.4%, 57.4%]. At the same time, Biden has gone from roughly a 2-1 favorite to a 4-1 favorite in their model. I recall reading somewhere that given the current polling numbers, their model would have Biden as a >90% favorite were the election to be held today. Given this, I suspect that within the month, their projected vote distributions will likely narrow further, perhaps even tighter than the Economist model, should the polls remain steady, although this is only a guess, since they don’t publish their model.
Whether this increase truly represents probability in the Bayesian sense of the word I’m not so sure. After all, given the difficulty of modeling a result several months out, it’s not really hard to imagine them initially pumping up uncertainties by adding fudge factors, etc in order to cover for some truly dramatic shift in the race, especially considering all the unexpected events in the past year. However, I think it’s worth noting that it wasn’t so long ago that polls could swing by 10 points in the last month of the race, so perhaps Fivetheirtyeight’s model is built partially on that data. Again I think a lot of words could have been saved had Fivethirtyeight just published their model…
I know Nate has said that a lot of what he’s modeling is “the possibility that something unexpected will happen between now and the election” (as it perhaps did last night.) And I know in his podcast he’s said quite a few times, basically, that if you look back more than twenty years or so, polls were often really volatile in the last month of the election, and he’s considering that as a reasonable part of his training data, so he treats the polls as volatile.
But none of that addresses Andrew’s concern that the correlations between states are too low. If you expect most of the volatility to be in _national_ swings, as it sounds like Andrew does, then you might give Trump a higher chance of winning but you would give him a low chance of winning conditional on losing Ohio.
I think this is actually a disagreement of priors between Andrew and Nate (possibly also driven by different training sets). Nate has said that he’s taking into account the possibility that this election is a realignment (or mid-realignment) for one or more states. So WV went from being a Democratic stronghold to being a Republican stronghold really quickly, and VA went the other way. So sure, Ohio has been a red-ish state in the past few elections, but there’s some probability that it will shift back and be blue of center going forward, and Nate’s model thinks that sort of thing is non-trivial.
Jay:
I agree, but I’d alter your statement so say that I think the low between-state correlations in the Fivethirtyeight model are by accident. Based on what Nate Silver has written, I’m guessing that they started with high between-state correlations and then added long-tailed errors that were independent across states, which had the effect of lowering the correlations between states. You’re right that there are legitimate reasons to allow the possibility of nonuniform swings, but I think some of the weird things going on with the Fivethirtyeight model are artifacts of the way they added in noise terms. This can happen, that when you expand your model you introduce new problems.
I think it’s pretty likely that we are in some kind of realignment, but it may not be obvious except in historical hindsight. If Biden wins back the traditionally-blue states (WI MI PA) that Trump won in 2016, does that mean 2016 was just a fluke?
Maybe not, if this election ends up being more of a referendum on Trump’s handling of COVID and other current problems – depending on who the candidates are in 2024 and 2028, and economic trends, and what happens to the Republican party platform post-Trump, it could be an interruption in a trend that resumes later: we could easily see a bluer Southwest (AZ going blue and TX becoming a swing state?) and a purpler Midwest going forward, IMO.
Economic/environmental policy re: fossil fuels could make a major difference in places like TX and PA too.
I couldn’t find a place to ask this at the Economist site:
Your Senate model gives a 22% chance of Rs getting 51+ seats and 12% chance of a 50/50 split.
Probability of R control is 30%
This implies a probability of a Republican VP breaking ties as (30-22)/12 = 67%
How does that work with an 87% Biden win percentage?
Probability of R control should be 22 + 12*(1-.87) = 23.6%
Andrew R.:
I know nothing about this Senate model.
From the first link:
> How many decimal places does it make sense to report the win probability?
I pointed to that sentence when the article was shared last month. I see it published unchanged and I wonder if the sentence is correct and I was wrong. If someone wants to comment on its grammatical soundness I will be grateful.
Hi, thank you for all the explanation and material you shared. Could you please also share the code for the stair/airplane plots that you included in this blogpost?
Socrates:
Merlin Heidemanns made the graphs. Some code is here.
I like the idea of using extremely unlikely events to scrutinize a statistical model, but it looks like there are too many events that the Economist 2020 model evaluates as being very unlikely, yet actually occurred.
I tried comparing actual state outcomes with final model predictions for the 2008, 2012, and 2016 elections. In each election, 8 state results fell outside 95% prediction intervals from the model. However, in expectation only about 2.5 states should do so (2.5/51 is about 5%). Additionally, 4, 5, and 5 states fell outside the model’s 98% prediction intervals in 2008, 2012, and 2016, respectively. In expectation, only about 1 state should do so (1/51 is about 2%).
I understand that state results are correlated, so one should only expect state prediction intervals to show good calibration across many elections, and not necessarily within an election or a few elections. But that is exactly the value of thinking about extremely unlikely events! — For extremely unlikely events, we shouldn’t see any occurrence, regardless of between-state correlation. And yet 2, 1, and 3 states fell outside the Economist model’s 99.9% prediction intervals in 2008, 2012, and 2016, respectively.
Results are shown in this figure: https://i.postimg.cc/Y9M8p0Fy/economist-model-tail-check.png
I’m not sure what the solution is. Maybe heavy tails? An alternative would be to shift the state predictive distribution means closer to actual outcomes, but I don’t see how to do that without overfitting and thereby worsening overconfidence. Or maybe no solution is needed because I misunderstood something.
My analysis has limitations too: I calculated intervals by assuming logit-transformed predictions were normally distributed. But maybe too few samples were used (1500), especially because distribution SDs were estimated from empirical 95% intervals of the sample ((high – low)/(2*1.96)).
Elliott Morris, Merlin Heidemanns, and Andrew Gelman,
I re-checked my points above and couldn’t find mistakes. I think the points are relevant to your model, so I hope you consider them. If scenarios like Trump winning but losing Ohio are relevant to interrogating your model, these must be too.
I put together a rare state event estimate that helps explain my points more, especially in reaction to the insightful commentary on “the difficulty of model calibration” and “using anomalous events” in the Gelman, Hullman, Wlezian, and Morris article linked in the post above.
Here’s the rare event calculation:
Three state election results appear to be outside the Economist model’s 99.9% prediction intervals in backtesting for 2016. How surprising is this? If state results were independent, then in only 1 of about 49,778 presidential elections would we see 3 or more state results that are outside 99.9% intervals from a fully calibrated model.* So observing 3 states outside the 99.9% interval would strongly suggest model miscalibration and need for revisions.
However, state results are not independent. This makes checking calibration more difficult, yet still possible, especially by focusing on rare events. In particular, the probability of 3 or more states with results outside 99.9% intervals is bounded above by the probability of at least 1 state with results outside 99.9% intervals, which even with nonindependence cannot exceed 0.051 (0.001*51).
Further, 2 and 1 states had results outside 99.9% intervals in 2008 and 2012 backtesting. So, with a fully calibrated model there would be at most 0.051 probability of observing states outside 99.9% intervals in these years too. Given independence of the differences between model predictions and actual results across years, the probability of observing so many states outside 99.9% prediction intervals is at most 0.051^3, or about 1 in 7500. This suggests the Economist model is miscalibrated.
The probability can be reduced from 1 in 7500 to below 1 in 50000 by switching to higher-coverage intervals or tightening the bound used.
Thank you very much for considering these points, and especially for posting the model on github.
*Calculated from binomial CDF using 51 states (50 + DC).
Fogpine:
Thanks. It does sound like this represents a problem with the model, not one that would have much effect on the headline predictions but still an issue. Elliott is looking into it.
Let’s agree that all models are in the dark regarding unlikely events. There’s simply not enough data to calibrate that kind of predictions. Anything beyond two sigmas is hocus pocus, fat tails or normal tails.
Andrew, I’ve been following your state correlation articles, and wanted to let you know that 538 has now made their 40,000 simulation results public, showing the simulated vote margin in each state/simulation. It is here: https://projects.fivethirtyeight.com/trump-biden-election-map/simmed-maps.json. An initial look at it actually shows that for most (or all?) states their vote margin distribution is actually skinned tailed, ie there’s a bigger peak than a simple normal would have. I want to spend more time with this, but thought I should let you know, as that’s contrary to your hypothesis (or maybe your commenter’s?) that they are adding uncorrelated fat tailed errors. It should also allow you to run much more detailed comparisons between your models if you’d like.
Rui:
I think that Nate wrote that they are using fat tails. The bigger peak and the fat tails go together, as you can see if you plot the t density. It’s clear they have fat tails in the Fivethirtyeight simulations, as that’s the only way to give Trump a chance of winning California, for example. I’m pretty sure the added errors are independent or something like it because that’s how you can have their conditional prediction that, even if Trump wins California, his chance of winning the national election is only about 50%.
Multivariate distributions are tricky, and it’s no surprise that if you slap one down and apply it to data, it can have some undesired artifacts. I think the mistake people are making is to assume by default that the Fivethirtyeight forecast (or any model) is “correct,” in some sense. Their procedure is just something they threw together. I respect the judgment of the Fivethirtyeight team; it’s just that the forecast distribution is complicated, and that will lead to trouble on things that they didn’t look at carefully when they were setting up their procedure.