From this Washington Post article:

But . . . wait a second. The University of Chicago’s Energy Policy Institute . . . what exactly is that?
Let’s do a google, then we get to the relevant page.
I’m concerned because this is the group that did this report, which featured this memorable graph:
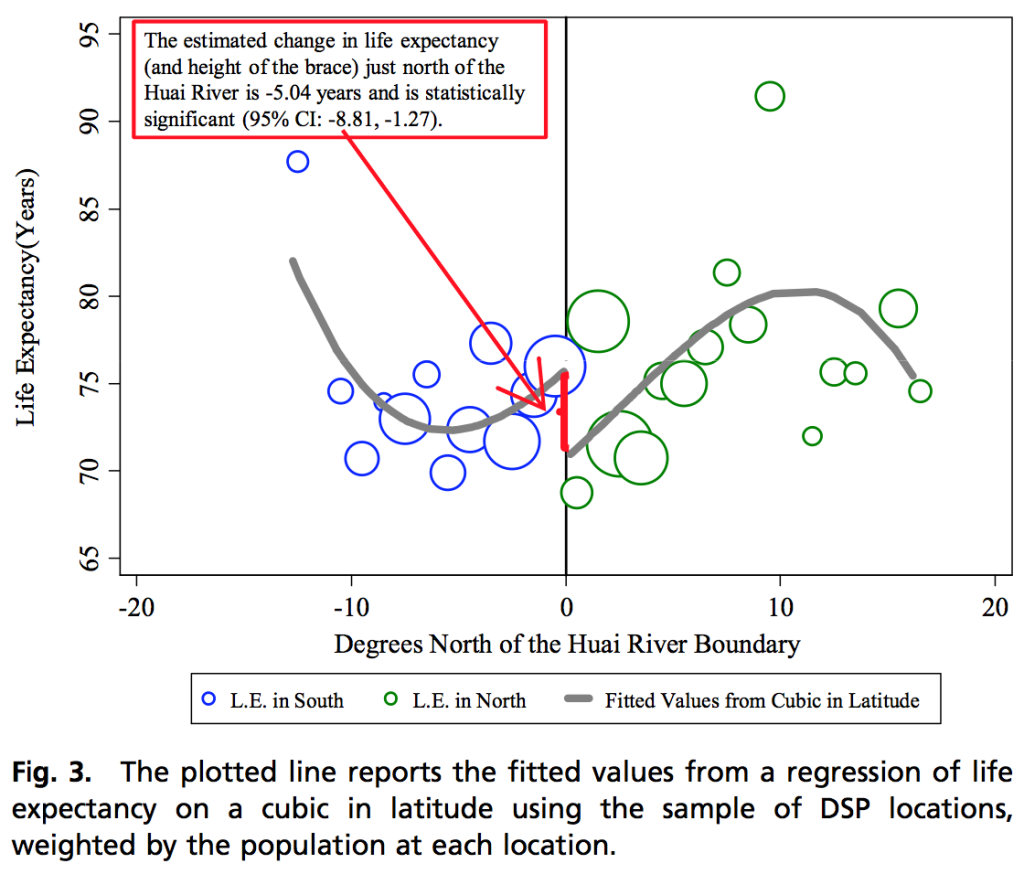
See this article (“Evidence on the deleterious impact of sustained use of polynomial regression on causal inference”) for further discussion of statistical problem with this sort of analysis.
Anyway, the short story is that I’m skeptical about these numbers.
Does this matter? I dunno. I’m pretty sure that air pollution is bad for you, and I expect it does reduce life expectancy, so maybe you could say: So what if these particular numbers are off?
On the other hand, if all we want to say is that air pollution is bad for you, we can say that. The contribution of that Washington Post article and associated publicity is, first, the particular numbers being reported and, second, the claim about the magnitude of the effects.
So if I don’t trust the stats, why should I trust a claim like this?

I just don’t know what to think. Maybe the press should be careful about reporting these numbers uncritically. Or maybe it doesn’t matter because it’s a crisis so it’s better to have falsely-precise numbers than none at all. I’m concerned that the estimates being reported are overestimates because of the statistical significance filter.
“…even more than cigarettes.”
Something that I find curious (admittedly without having read the article). The news clipping notes that should one be able to remove the deadliest types of pollution from the air, life expectancy would increase 2.6 years on average. Doesn’t smoking reduce life expectancy far more then that?
The CDC suggests it’s at least 10 years: https://www.cdc.gov/tobacco/data_statistics/fact_sheets/health_effects/tobacco_related_mortality/index.htm
Or is the claim that it’s worse than smoking meant in some sort of absolute total life lost sense (because everyone would be affected by that 2.6 years whereas with smoking it’s just smokers and those in heavy second-smoke situations)? What kind of use is that?
Regardless. It’s a pretty bold claim; that it’s the greatest risk to human health at the moment. The likelihood that they actually present strong (or even moderate) support for their claim is between slim and none, and slim left town.
Allan:
Yes, I assume it’s total population risk, not risk conditional on exposure. Total risk is relevant for public health purposes. The trouble is that I doubt their estimate of total risk. I’m not saying I think their estimate is wrong, I’m saying I just don’t know. I don’t think the evidence is nearly as strong as these researchers seem to think it is.
Part of this is that I fear that the researchers have succumbed to what might be called “the economist’s fallacy”: the belief that their profession is the guardian of rigor, and so any strong claim they make should automatically be believed.
Sometimes I think the world would be a better place if, every time an economist or a journalist saw a published claim by an economist, they were to be told that the research had been performed by a sociologist, or an anthropologist. This would induce in them an appropriate level of skepticism.
Similarly with medical research: Suppose that every time a doctor or a journalist saw a published claim by a M.D., they were told that the research had been done by a nurse, or a social worker. Again, then maybe they’d be appropriately skeptical.
Oooh, I like this game. Here’s another one: Every time you see a paper by a Harvard professor, mentally change the affiliation to State U. Then you’ll be appropriately skeptical.
And, every time you see a paper endorsed by a member of the National Academy of Sciences . . . ummm, I guess that one’s ok, we already know not to believe it!
+1
From the CDC’s source:
Jha P, Ramasundarahettige C, Landsman V, Rostrom B, Thun M, Anderson RN, McAfee T, Peto R. 21st Century Hazards of Smoking and Benefits of Cessation in the United States [PDF–738 KB]External. New England Journal of Medicine, 2013;368(4):341–50 [accessed 2015 Aug 17].
As I mentioned in the other thread, how do they know they are including (“adujsting for”) all the relevant variables? Seems like they could be missing something big that correlates with smoking that would totally change that estimate… You can even see they are not confident because they tried out including race, then didn’t use it, etc.
To channel Fisher, there could be a propensity to smoke (eg, it is more rewarding due to low baseline dopamine levels) in people who tend to have shorter lifespans anyway (eg, due more risky behavior in general).
For example, let’s say smoking is correlated with heroin use:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3367288/
Would avoiding smoking extend the lifespan of people in that group by 10 years?
“factor X reduces average lifespan by Y years” an example of fallacy of using linear models language while talking about clearly non-linear models.
That may be, but my problem here is just that interpreting the coefficients requires us to take these models seriously. Yet, these models seem to be arbitrary and primarily determined by convenience.
Ie, the “structure” of the model is chosen for its ease of calculation (it is already in the stats software, etc), while the variables included are chosen/tried just because that data is readily available.
Using such models to try to predict things is fine, but I don’t see any basis for interpreting the individual coefficients. Of course, there is a vast literature based on doing just that.
I’m already resigned to throwing it all out due to other issues corrupting the conclusions (NHST), so it makes little difference to me. However, perhaps this problem will lead others who want to ignore the NHST issue reconsider what has been passing for science.
Or somehow I’m wrong and there is some justification for interpreting the coefficients of these arbitrary statistical models I am missing.
If you are not already aware, there are some serious (and Bayesian) methods that try to address your concerns Good practices for quantitative bias analysis. Lash et al https://www.ncbi.nlm.nih.gov/pubmed/25080530
I saw some econometric papers that claimed to address this somehow using lots of assumptions and equations, but don’t see how any amount of manipulation of (and assumptions about) the same info can help here. Eg, in this case:
https://stats.idre.ucla.edu/stata/code/why-dont-my-regression-coefficients-make-sense-signs-of-model-misspecification/
If we are blissfully ignorant about x2, does bias analysis claim to help us get a better estimate of the coefficient for x1? I would think we must be stuck with the y~x1 estimate of (positive) ~0.235 when the true value was (negative) -0.2. Then all the downstream incorrect inferences that would entail.
Anoneuioud: another way to say this is you can’t get good science without building mechanistic models from some basic principles. throwing days into regressions doesn’t do it. another consequence is that you should investigate complex models of complex phenomena. I often start throwing stuff into my models that make sense to me and complicate things extremely, while others might say it’s crazy. like for example in a model on air pollution, you obviously will need a submodel on migration patterns because exposure over decades is the determinant of total health impact.
I think just throwing stuff into regressions has its place (this is essentially what machine learning is), but if your goal is to estimate the parameters of a model then that model should mean something. Be derived from some principles, like you say.
I was thinking maybe somehow these simple additive models can be seen as taking the first taylor series term of the true (nonlinear) function for each variable… or something like that. But still I don’t see how you can ignore the unknown variable missing from your model.
Like we know smoking a lot is correlated with all sorts of “risky” behavior (promiscuity, motorcycles, violence, alcohol, drug use, tattoos, etc) and stress in general. Wouldnt it make sense if this reflected some genetic/developmental profile that generates people who “live fast, die young”? Evolutionarily it would also make sense for this type of person to suffer from health issues at an earlier age (even if they don’t act on their impulses) since usually they don’t get to old age anyway so why waste the energy…
So if we added something like that to their model do we still see smoking reduces life expectancy by 10 years? Even then, is there any reason to think the new model really correct?
So yeah, I don’t get why people are putting so much stock in these coefficients.
Right, throwing data into a regression is perfectly fine for prediction without interpretation. For example “smokers as a general group tend to live 10 years less than the population of non-smokers” is a prediction we can make from a sample of data on life expectancy and smoking etc.
But it’s also entirely plausible that for example “soldier’s who smoke during wartime are 10% less likely to be killed by surprise attacks” or some such thing.
It’s also plausible “people who engage in the same types of behaviors as smokers live 10% shorter lives if they don’t smoke” for example.
All of these and more relationships can simultaneously be true in the large population of people we have.
If you want to interpret coefficients at me you need a specific mechanistic model that is somehow plausible for me to entertain, and furthermore you probably need several of them, and to have compared them to each other within a Bayesian model averaging scenario and come up with one of them dominating the others.
That this isn’t basically day one of “social science methods 101” (and not just day 1 but basically every day after that too) is largely what leads to this kind of research.
Andrew said,
“Part of this is that I fear that the researchers have succumbed to what might be called “the economist’s fallacy”: the belief that their profession is the guardian of rigor, and so any strong claim they make should automatically be believed.
Sometimes I think the world would be a better place if, every time an economist or a journalist saw a published claim by an economist, they were to be told that the research had been performed by a sociologist, or an anthropologist. This would induce in them an appropriate level of skepticism.”
As it happens, just a few minutes ago, I was listening to an account on the radio of another instance of “the economist’s fallacy”: the emphasis in ‘The war on drugs” on restricting supply (heavy sentences to small time dealers) rather than reducing demand (providing effective treatment for addiction). I can’t find a transcript online, but there’s a podcast at https://www.marketplace.org/2019/03/21/wealth-poverty/uncertain-hour/president-and-his-baggie-crack
I went to the site to figure out how they estimated life expectancy impacts. You’re not going to like it.
Page 12 has “FACT 5” which includes the regression discontinuity chart you took apart.
Then on page 22, they say “Using the satellite PM data and the results from the Huai River studies, the AQLI reports the gain in life expectancy from reducing each region’s particulate concentration to the WHO’s safe guideline or existing national air quality standards, or by user-selected percent reductions.” So the entire index is built from that one graph.
Eeeeeeekkkk!
So, basically they are doubling down on their polynomial regression discontinuity chart fiasco by using it as an established method.
At least they’re consistent. But then “A foolish consistency is the hobgoblin of little minds, adored by little statesmen and philosophers and divines.” [not many statisticians in 1841] (Ralph Waldo Emerson)
And so the flimsiest of unicorn feathers becomes transmuted into a rock solid basis for enviro hysteria.
For years to come advocacy groups will cite this as gospel.
Here’s a different take: if we removed those pollutants, might that cost more in average lives? The pollutants are related to industrial processes. Those processes feed, clothe and otherwise care for human beings. So one way the change could cost more is if we imagine we don’t have all these industries and then calculate what we could support on this world. It would be far fewer people than the earth manages now. There’s another obvious path too: since the idea appears to idealize the end of these pollutants, we can assign an idealized cost to that effort. At one end of the range, the transition is seamless: we find some magical technology that is both clean and which generates at least equivalent income and wealth. At the other, the transition is expensive, kludgy, and causes a lot of dislocation. Putting that in a model is doable, so we could estimate lives lost.
And there’s another obvious one, that the elimination of one class of deadly pollutants causes unintended increases in other pollutants. I’m distinguishing this from lack of funds, etc. because maybe we end up with more wood burning or that allocations away from industrial pollutant processes generates more agricultural pollutants (like the need to increase local food production near large populations causes significantly greater …).
So aside from the ridiculosity of the estimate and the untrustworthiness of even the basic approach they’re taking, they’re assuming they can see in the future a stable result when the paths to that result aren’t even vaguely specified. Is there a real term for this kind of blind dart throwing?
I’m sorry, Jonathan, but the first paragraph of your argument is ridiculous. Did industry shutdown when we regulated child labor? Did farms stop producing food when we started food inspection? Your positing in narrative form a much simpler dynamic then is realistic plausible.
So to do that model justice you’d have optimize the relationship between reducing pollutants and reducing profits. It’s clearly not as simple as remove pollutants and you remove industry. But then there are other dynamics we need to consider. For example hot do we model how the profits of industrial activity are distributed? In our model, we could simply leave pollutant and wealth production the same, but alter how each are distributed. For example, we could concentrate all the pollutants in the estate of executives and majors shareholders of our hypothetical polluting corporation, and redistribute the wealth produced on the backs of the workers to a greater share of the population. That would increase net number of human beings fed, clothed and otherwise cared for. We’d of course have to model that transition as well. At one end of that ranges, it’s a seamless shift to our Marxian utopia, and we only lose a few executives to a cathartic choking on their own concentrated externalities. On the other hand, if goes the way of most human endeavors – trending to corruption, mismanagement, and violent hubris – well that’s a different movie.
We also of course have to consider the obvious potential for the unintended increase in killer sentient robots when we replace all labor with machines in an effort to realize our post-scarcity fever dream. The final output of that model is simply a base R plot (ggplot being outlawed by the state for being way too bourgeois) of a tombstone that reads: “We should of never trained the machine learning algorithms on Heideggerian postmetaphysical hermeneutics.”
Industries also commission ridiculous reports. Producing scary costs of compliance is a staple of that literature. Assuming nobody adapts in any way to the new regulation is a common tactic to produce large numbers.
And of course underlying the whole premise is “we-used-to-have-clean-air” fallacy: 5000 years ago most humans probably spent their winters in tiny shelters with a wood fire burning almost all winter long.
The underlying report is by a serious researcher, and the report he and his team generated is pretty serious. So, it isn’t to be dismissed out of hand. (Whenever I have dug into a “report” by an environmental advocacy group, it has almost always turned out to be hysterical nonsense.)
That said, the report is very suspicious because it reaches the “right” “alarming” conclusion. As Kaiser above points out, it is based on the highly dubious non-linear graph Andrew takes apart. A single dubious graph is all it takes for a motivated research to reach the “right” “alarming” conclusion. It is a heck of an extrapolation from a dubious graph.
The report is also not peer-reviewed, so it doesn’t have the modest imprimatur that peer-review brings.
The underlying report is here. https://aqli.epic.uchicago.edu/wp-content/uploads/2018/11/AQLI-Annual-Report-V13.pdf. The dubious non-linear graph is at page 12.
I don’t think your concerns about the estimates being off are overblown or anything. Even if they don’t largely change the fact that air pollution is bad for us, getting the numbers right is important both for policy changes and interventions.