Blake McShane writes:
I wanted to write to you about something related to your ongoing posts on replication in psychology as well as your recent post the ASA statement on p-values. In addition to the many problems you and others have documented with the p-value as a measure of evidence (both those computed “honestly” and those computed after fishing, the garden of forking paths, etc.), another problem seems to be that academic researchers across the biomedical and social sciences genuinely interpret them quite poorly.
In a forthcoming paper, my colleague David Gal and I survey top academics across a wide variety of fields including the editorial board of Psychological Science and authors of papers published in the New England Journal of Medicine, the American Economic Review, and other top journals. We show:
[1] Researchers interpret p-values dichotomously (i.e., focus only on whether p is below or above 0.05).
[2] They fixate on them even when they are irrelevant (e.g., when asked about descriptive statistics).
[3] These findings apply to likelihood judgments about what might happen to future subjects as well as to choices made based on the data.
We also show they ignore the magnitudes of effect sizes.In case you have any interest, I am attaching the paper. Unfortunately, our data is presented in tabular format due to an insistent AE; thus, I am also attaching our supplement which presents the data graphically.
And here’s their key finding:
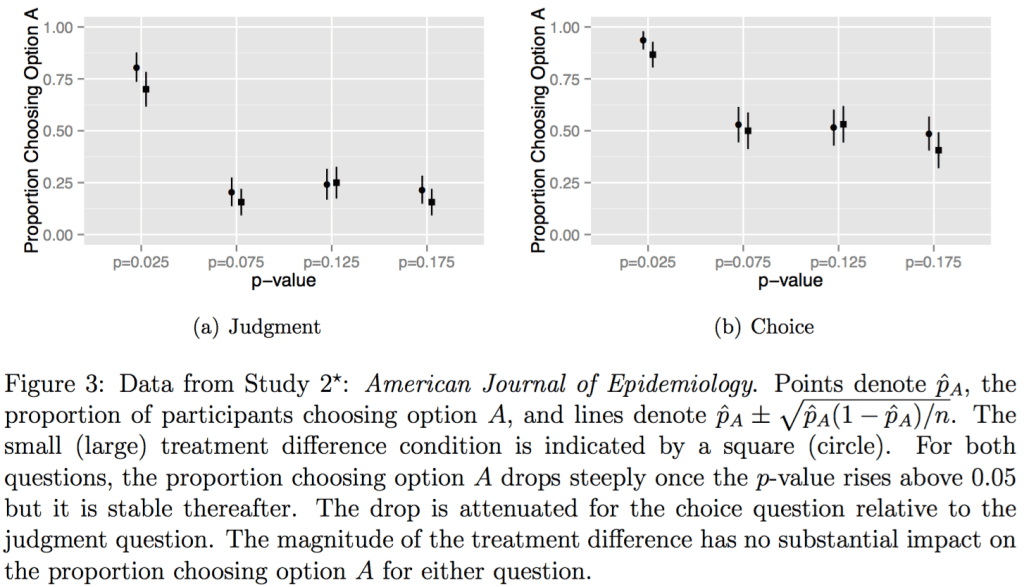
Bad news. I’m sure researchers would also misinterpret Bayesian inferences to the extent that they are being used in a null hypothesis significance testing framework. I think p-values are particularly bad because, either they’re being used to make (generally meaningless) claims about hypotheses being true or false, or they’re being used as an indirect estimation tool, in which case they have that horrible nonlinear transformation that makes them so hard to interpret (the difference between significant and non-significant not being itself statistically significant and all that, which is part of the bigger problem that these numbers are just about impossible to interpret in the (real-world) scenario in which the null hypothesis is not precisely true.
It’s an interesting fact that the point null is very unlikely to be literally true, but that most/many effects are likely to be near zero (e.g., the power posing stuff, but also psych/ling stuff). Most of the time there’s no information in the data.
It’s also interesting that low power can lead to both (a) exaggerated effect sizes and/or the wrong sign, (b) uninformative effects near zero.
It’s hilarious that by adding a p-value, you can make (very smart) people confused about whether a larger number is actually bigger than a smaller number.
Alex:
Maybe they’re not so damn smart.
Perhaps they are. As Gigerenzer might argue, their rules of thumb/heuristics need to work in the environment they find themselves in (publishing), so a focus on the all important p<0.05 makes perfect sense.
You can confuse smart people by a convoluted definition. The definition of a p-value rarely aligns with any goal a person may have in mind.
I feel that the main issue is not the smartness level of the people involved, but the way this stuff is taught. What I learnt as a grad student, at least implicitly, that if p<0.05, then the hypothesis of interest is true, otherwise it is false. And that's how it has always been, especially in top journals.
But that’s exactly my point: People almost always *want* to know “Is my hypothesis true?” That’s a natural question that comes to their mind.
Which applied practitioner ever thinks in terms of “the probability of obtaining a result equal to or “more extreme” than what was actually observed, when the null hypothesis is true.”
People subconsciously take a p-value to be answering whatever question they want answered.
Basically the field of statistics has focused on a metric that no one ever wants to really know. A p-value provides an answer to a very very unnatural framing of the question.
Yes, even the way statisticians are trained seems to have this problem of framing. At Sheffield, there were a lot of word gymnastics involved in explaining to the student that the p-value wasn’t really delivering anything useful (although nobody ever said or wrote that in the lecture notes). The implicit thread even there (again, this was never made explicit) was that we have the MLE and the 95% CI and we are going to use that to make the argument for a specific alternative. Surprisingly to me, even medical statistics was taught using p-values. Everything was focused on statistical significance. Heck, even the after-five journal of the ASA and RSS is called Significance. I guess Bayesians will remain on the fringe, the way things are set up.
This seems more like an argument against education and for going with your gut. What natural question individuals with their untutored intuitions want to have answered is not something I think we should base ourselves on.
Furthermore, the question that individuals want to have answered most of the time is not really “is my hypothesis true”, but rather, “should I act as if it is?” and for this a p-value is great. If you have to decide between two alternatives and act on it, then making a decision based on the p-value being below a certain threshold can help you to make the right decision.
Finally, this argument against the p-value is a bit like arguing against hammers because some might use them on screws instead of nails. The p-value is a tool and a very useful one at that.
What should I do if it happens to turn out that the distribution of the p-value under repeated sampling is uniform under the null hypothesis, between 0 and 1? Should I still act as if the null is false if p is very small?
PS I have used hammers on screws, especially when the screw wouldn’t do what I want (go into the wall already).
Toby:
You write, “The p-value is a tool and a very useful one at that.”
The p-value is very useful in getting papers published in PPNAS, Psych Science, etc. Not so clear that it’s been very useful in the advancement of science and engineering (beyond, for example, simply plotting data).
You described yourself as, “a pragmatist who finds P values useful in some settings but not others,” in this paper: https://www.stat.columbia.edu/~gelman/research/published/pvalues3.pdf
Has your opinion on p values shifted so much in the past four years or am I misinterpreting somethign?
Crh:
I’ve seen p-values be useful in some settings. But, speaking pragmatically, I wouldn’t call them very useful.
Andrew, I don’t think that we’ll disagree that the practice is bad. That, however, seems to be more a of problem of incentives than of method. Give some people a pencil and they’ll demonstrate that e = mc^2 or they’ll compose la traviata, whereas others will use it to stab each other with it. It all depends on what situation they’ll find themselves in, what their abilities are, and what their hopes and dreams are.
Do you genuinely think that other methods are for some reason immune from this problem once they’re adopted widely? It used to be the case, or so I am told, that Linux and Apple’s OS were relatively virus free. Now that these operating systems are more widely adopted, more viruses are being made for it. I am sure that if Bayesian methods will be adopted more widely, similar problems will appear. The problem seem to be the incentives not the methods.
I’ll immediately admit though that I have very little knowledge of Bayesian methods. I am sure, however, that you’d be able to game the system using these methods if you’d want to. Surely, it’s not the first human invented technology that’s both idiot-proof and that cannot be used by knaves for their purposes?
What I however meant by that the p-value is a useful tool, is that it is a useful tool if used properly.
Toby:
I never said that other methods are immune from problems, nor do I believe such a thing. What I do think is that p-values, even when they’re appropriate, don’t do much. Even when used properly, I don’t think p-values are so useful. And, yes, all methods can be abused, but some methods are more useful than others. There’s a reason why I wrote a book on Bayesian data analysis and a book on regression and multilevel models, and the reason is that these methods can do a lot!
Andrew,
I don’t dispute that those methods can do a lot. However, p-values have been very useful when used properly and seemed to have lead to some advancements in science. For example, the Higgs-boson, if I recall correctly, was announced as discovered because the p-value in an experiment was below a certain threshold. I think that this is an example of the p-value being a very useful tool.
@Toby
Even if we all used Linux & all the virus writers in the world focused on writing Linux viruses things will never get as bad because the architecture of the system inherently contains most of the damage a virus can inflict.
Ergo, all designs / strategies are not equally robust.
Rahul,
I am not a computer scientist by training so I don’t know if that is true. What I do know, however, is that people have routinely made such comments by underestimating human ingenuity. We don’t know how bad things can get unless we have enough people who are incentivized enough to try. I am, therefore, a bit skeptical about such claims.
Furthermore, the people who work at Microsoft are without a doubt very clever and very good at what they do. Probably they are just as clever as those who work to develop Linux and/or Apple’s OS. I, therefore, doubt stories that there is an inherent design flaw in Windows that cannot be compensated for. Moreover I doubt that this design flaw is absent in Linux. All I know is that people have much more of an incentive to look for such flaws in Windows than they do in Linux.
The same story applies to rival methods in statistics.
“All I know is that people have much more of an incentive to look for such flaws in Windows than they do in Linux.”
I hope this one was meant as a joke.
About p-values, I think that p-values suddenly become very plausible as a tool for decision making if we repeatedly run an experiment and steadily get low p-values. However, we could have determined this without using p-vals, what they call the secret weapon in the Gelman and Hill book (in a footnote IIRC!). Just plot the means and CIs under repeated runs.
Toby,
Well put when you say that what we really want to know is, “Should we act as if our hypothesis is true?”.
But exactly wrong when you say the p-value is “great” for that purpose. It is very easy to describe two situations with identical p-values but where the sensible person would confidently reject the null for situation 1 and confidently hold on to the null in situation 2. The p-value can never tell you how certain you should be that any particular hypothesis is true or false.
Tim
To me, the main point here even precedes p-values: the confusion is really about whether the statement being made is descriptive or inferential. The multiple choice questions asked about purely descriptive quantities, but added in an irrelevant p-value (which is itself a descriptive statistic as well). The problem is that once they read the magic words “p-value”, the researchers immediately misinterpreted the question as being about a statistical inference about populations, and not a question about what was actually observed in the sample. Relevant discussion from paper:
“””
One potential criticism of our findings is that our question is essentially a trick question: researchers clearly know that 8.2 is greater than 7.5, but they might perceive that asking whether 8.2 is greater than 7.5 is too easy a question and hence they focus on whether the difference is statistically significant. However, asking whether a p-value of 0.27 is statistically significant is also trivial, so this criticism does not resolve why researchers focus on the statistical significance of the difference rather than on the difference itself. A related potential criticism regards our question as a trick question for a different reason: by including a pvalue, we naturally lead researchers to focus on statistical significance. However, this is essentially our point: researchers are so trained to focus on statistical significance that the mere presence of a p-value leads them to automatically view everything through the lens of the NHST paradigm even when it is not warranted. Moreover, in further response to such criticisms, we note that we stopped just short of explicitly telling participants that we were asking for a description of the observed data rather than asking them to make a statistical inference (e.g., response options read, “Speaking only of the subjects who took part in this particular study, the average number of post-diagnosis months lived by the participants who were in Group A was greater than that lived by the participants who were in Group B” and similarly; emphasis added).
“””
This concern…
“[1] Researchers interpret p-values dichotomously (i.e., focus only on whether p is below or above 0.05).”
… was actually taught as part of the standard curriculum in my psychology undergraduate program. Not the criticism, I mean, but that this was standard practice; students (of which I was one) were explicitly instructed to interpret p-values dichotomously, and to ignore any information available in the magnitude of the p values.
Same for every course (not many) I took over many years. There were sometimes cautions, but these were discounted.
Wouldn’t that be the right way to proceed in the Neyman-Pearson framework of hypothesis testing as a decision problem ? You fix an alpha in advance and reject the hypothesis or not depending on which side your calculated p-value falls.
I know theoretically alpha is supposed to be a simple dichotomous decision yadda yadda and that Student supposedly used these sorts of approaches quite effectively for Guinness Brewery, but I can never see how exactly setting a p-value of 0.1 or 0.05 or 0.01 leads to sensible decision-making. Are there any worked out examples of how the N-P framework *should* work and is reasonably competitive with a Bayesian decision theory approach?
I don’t know if it is reasonable, but it’s quite simple. You set a value of alpha and by rejecting when your statistic is above the corresponding critical value you’ll have the desired rate for Type I errors (in the frequentist long-run sense).
There was the nice past post on that https://faculty.washington.edu/kenrice
I think your link got cut off, that’s just a home page.
Sorry – here is the correct link https://statmodeling.stat.columbia.edu/2014/04/29/ken-rice-presents-unifying-approach-statistical-inference-hypothesis-testing/
Carlos:
Sure, but that’s not what people do, nor (as Gwern says) would this lead to sensible decision making, even if people did follow these rules. One problem is that people want “p less than .05” and they can get it, one way or another.
Well, that’s what people would do if they followed what they were taught and ignored the p-value beyond its role in the decision. I’m not trying to defend this approach. I agree that there are better ways to use the data at hand. But at least it makes sense. I have more issues with FIsher’s significance tests and the hybrid NHST.
In the Neyman-Pearson framework, statistical significance is indeed commonly taught as a dichotomous choice. The next step (which is all-too-often ignored) is to assess the effect size for practical significance. Far too many researchers forget this part of the process — and it is shocking to me how many Ph.Ds (and of course MDs) aren’t even sure what an effect size is. More emphasis needs to be put on interpreting effect size, standardized and otherwise, in the course of statistics education.
+1
>”In the Neyman-Pearson framework, statistical significance is indeed commonly taught as a dichotomous choice. The next step (which is all-too-often ignored) is to assess the effect size for practical significance. Far too many researchers forget this part of the process…”
I don’t believe this next step exists for the Neyman-Pearson procedure/framework, you seem to be talking about some kind of hybrid.
I agree, I don’t think it is. But most disciplines are not trying to apply a specific framework in that way. In fact, contrary to what people are implying, in some disciplines there is much more concern about big effect sizes in small samples and that’s why their statistics texts have emphasized the need to do NHST, because those would not be significant. On the other hand, in other disciplines, you’ll see students learning to check for “statistically significant but not clinically meaningful” results when reading articles.
Clark:
Except not. Forking paths and the statistical significance filter ensure that statistically significant estimates are overestimates (type M errors; see my paper with Carlin), hence the commonly-taught strategy of looking for “practical significance” can be a disaster.
“looking for “practical significance” can be a disaster”
I agree. But so can declaring “significance” just because there is statistical significance, but the effect size is too small to be of practical significance.
Forking paths and the statistical significance filter are indeed a problem, whatever the statistical methodology. Just as many researchers learn that 1-sided t-tests are more likely to give them the result they want, others will realize that selecting a favorable prior is more likely to do the same with Bayesian methods — and there will be a tendency to choose some arbitrary significance cut-off either way. The point is that, with whatever statistical approach is used, researchers need to move away from simply contemplating significance and factor in effect size and variation when assessing how seriously to consider a result (and I’m just repeating a point made in the recent ASA statement on p-values).
>The next step (which is all-too-often ignored)
>is to assess the effect size for practical significance.
But we do not know the effect size. We just have an effect size measure, based
on sample data. This effect size measure differs from the true effect size. So
what do we actually gain from effect size measures within the significance testing
framework (except when we make reviews across stduies or meta-analyses etc.)?
We’re talking about sample effect size, but the sample effect size is the best available proxy for the population effect size. In my experience (clinical research), when a “significant” effect is due to noise, the observed effect size tends to be miniscule, so a small effect size suggests that either the significant effect is noise or simply too small to be clinically relevant. For instance, we might find a significant 1 percent difference in some outcome between two groups.
Of course, this presumes that we have properly controlled for various biases. Most of the projects I work with have been retrospective, rarely nicely randomized. I’ve seen a lot of stuff published with retrospective data where the groups were not particularly well matched and no attempt was made to control for the biases — this sort of thing is disturbing, as a lot of MDs assume anything that gets through peer-review is correct, and practice accordingly.
Clark:
No, the sample effect size can be a terrible, terrible proxy for the population effect size. See here.
I appreciate the point you are making in your paper, that with small(ish) Ns the sample effect sizes are often exaggerated, perhaps in the wrong directions. I think this is generally understood of small samples, at least by statisticians, but often they are what we have to work with and so we make the best of it — understanding that we’ll be led astray some fraction of the time (not all results will be reproducible). One of many reasons why important results need to be replicated.
I never saw the Type S and M error stuff discussed in any statistics course I ever did, and never in any written work (except Andrew’s). I have seen papers by a psychologist who wrote a paper (I can’t find it unfortunately) saying that statistical significance with a small sample size is much more convincing than with a larger one; intuitively this made sense because if one can detect the effect with even a small sample, then it must be a yuge effect. I don’t think it occurred to anyone to question that until the Type M and S error paper came along. Or am I wrong about this?
“when a ‘significant’ effect is due to noise, the observed effect size tends to be minuscule”
This is only true when the sample size is very large. When the sample size is small, the opposite is true, statistical significance means that the observed effect size must be big enough to get outside the confidence bounds, and with small sample size the confidence bounds are large, hence if there is a spurious noisy result, it will appear large. This is what Andrew calls “Type M” errors.
Yes and other people have already explained that, but I want to emphasize that I think there is a tremendous inter-generational transmission issue. I think I was a student during something of a transition period, but we were certainly taught that way. I think it also relates to the fact that we really did look those numbers up in books using fixed p values. Yes you would learn to interpolate but really, I think there is no arguing that those printed tables shaped people’s practices. So the people who learned that way still think that way and lots of basic text books are still like that.
This inter-generational issue is sort of my point; I think my undergraduate psych curriculum was quite on point, and impressive in its fealty (in most respects) to rigorous experimental-statistical methodology. For them to fall prey to a common error suggests, to me, that the cultural-teaching problem faced by the ASA and statisticians more widely is deeper even than redressing researcher malpractice. I suspect there’s extremely widespread institutional misteaching of basic concepts.
Addendum: I suppose that’s really inserting a point where I originally had none. I am pleased to see it’s generated a lot’ve discussion, including folks with similar experiences.
I know that reading Nassim Taleb is frowned on, but the situation in the second experiment described in the paper reminds me of the following passage from “The Black Swan”:
I know that it is rare for Fat Tony and Dr. John to breathe the same air, let alone find themselves at the same bar, so consider this a pure thought exercise. I will ask each of them a question and compare their answers.
NNT (that is, me): Assume that a coin is fair, i.e., has an equal probability of coming up heads or tails when flipped. I flip it ninety-nine times and get heads each time. What are the odds of my getting tails on my next throw?
Dr. John: Trivial question. One half, of course, since you are assuming 50 percent odds for each and independence between draws.
NNT: What do you say, Tony?
Fat Tony: I’d say no more than 1 percent, of course.
NNT: Why so? I gave you the initial assumption of a fair coin, meaning that it was 50 percent either way.
Fat Tony: You are either full of crap or a pure sucker to buy that ” 5 0 pehcent” business. The coin gotta be loaded. It can’t be a fair game.
(Translation: It is far more likely that your assumptions about the fairness are wrong than the coin delivering ninety-nine heads in ninety-nine throws.)
NNT: But Dr. John said 50 percent.
Fat Tony (whispering in my ear): I know these guys with the nerd examples from the bank days. They think way too slow. And they are too commoditized. You can take them for a ride.
Never liked this little story.
It would be more persuasive if Dr John gave that answer when actually, physically confronted with 99 consecutive flips of heads. As a thought experiment, it merely shows the inability of the Fat Tonies of this world to engage in hypothetical reasoning.
From Guys and Dolls: One of these days in your travels, a guy is going to show you a brand-new deck of cards on which the seal is not yet broken. Then this guy is going to offer to bet you that he can make the jack of spades jump out of this brand-new deck of cards and squirt cider in your ear. But, son, do not accept this bet, because as sure as you stand there, you’re going to wind up with an ear full of cider.
I thought that was Mark Twain
I agree with your point: this thought experiment would have been better if it had been a regular thought experiment, and hadn’t gone full Inception by implanting a thought experiment (coin tosses) inside a thought experiment (the dialogue).
Wow, I guess my sentence is proof that you can in fact complicate simple matters by over-explaining them.
I think this paper (like almost all of them) gets caught up in technicalities and misses the primary problem with NHST. In the vast majority of cases, there is no reason we should care about whether p [less than] 0.05. This is because there is a tenuous to nonexistent connection between the statistical null hypothesis and the hypothesis/theory/model of interest:
“The problem here, basically, is that statistical rejection of the null hypothesis tells the scientist only what he was already quite sure of-the animals are not behaving randomly. The fact the null hypothesis can be rejected with a p of .99 does not give E an assurance of .99 that his particular hypothesis is true, but only that some alternative to the null hypothesis is true. He may not like the bubble hypothesis because it is ad hoc. But that is quite irrelevant. What is crucial is that the bubble hypothesis, or some other hypothesis, may be more probable than his own. The final confidence he can have in his scientific hypothesis is not dependent upon statistical significance levels; it is ultimately determined by his ability to reject alternatives.”
https://psycnet.apa.org/psycinfo/1964-00038-001
Doesn’t this just show the halo effect as it applies to statistics?
p<.05 is good, therefore this is good, which carries over to other things via unconscious bias.
Maybe when the authors do the next study they might also investigate what happens as p-values increase up to one using this background for their theory of how people should vary their choices using -log(p) as explained by Sander Greenland here – https://errorstatistics.com/2016/07/21/nonsignificance-plus-high-power-does-not-imply-support-for-the-null-over-the-alternative/#comment-141791
I’m sorry, but no. In the second experiment option A is not the best when p=0.175 (unless I’m just reading too quickly and missing some trick). Option D is the only valid option in this case. Drawing the conclusion that the authors do places far too much emphasis on observed point estimates, which by themselves carry no statistical information (or requires a Bayesian interpretation of the resulting confidence interval). I agree that in most real world scenarios it doesn’t make sense to think of the null being precisely true, but in a randomized trial it most definitely does make sense to test the hypothesis that the null is precisely true (this is the strong null of no effect for any randomized participant that is tested in randomization-based inference).
Also, I’d like to say that testing the primary outcome in a randomized trial IS NOT part of the “NHST paradigm” that is typically criticized. This is a valid use of hypothesis testing. The same is certainly not true for hypothesis testing in observational studies.
>”but in a randomized trial it most definitely does make sense to test the hypothesis that the null is precisely true (this is the strong null of no effect for any randomized participant that is tested in randomization-based inference).”
One thing often forgotten here is that the null hypothesis has much more content than mu1 == mu2, the additional content is usually referred to (misleadingly) as “assumptions”, but is in no way second class. As an example of the damage this confusion has caused, see this paper discovering the null hypotheses used for 40,000 MRI papers were always false: https://www.pnas.org/content/113/28/7900.full
>’testing the primary outcome in a randomized trial IS NOT part of the “NHST paradigm” that is typically criticized.’
It is often criticized under the heading “statistical significance isn’t practical significance”. Disappointingly the criticism usually stops there, when that is only the tip of the iceberg.
The null being tested has nothing to do with mu or any other model parameter.
>”The null being tested has nothing to do with mu or any other model parameter.”
Sorry for any confusion, by mu I was referring to the usual population average that is highlighted part of the t-test null hypothesis. The exact test does not matter for my point, but usually a null hypothesis involves at least one parameter? Can you give an example of what you mean by “the null [hypothesis?] being tested”?
I realize you were referring to the population average, and I’m saying that’s irrelevant in a randomization-based test, as are all model parameters. The null hypothesis is that none of the randomized participants would have had different outcomes had they been (counterfactually) randomized to the other group. With no loss, the only required “assumption” (not really an assumption since we know it to be true) is randomization. With loss, which is nearly ubiquitous, we require somewhat stronger assumptions. This paper is an easy read: https://www.ncbi.nlm.nih.gov/pubmed/?term=Stewart+and+%22groundhog+day%22
>”I realize you were referring to the population average, and I’m saying that’s irrelevant in a randomization-based test, as are all model parameters. The null hypothesis is that none of the randomized participants would have had different outcomes had they been (counterfactually) randomized to the other group.”
I read through the paper. I think there is an affirming the consequent fallacy here. On page 99 (pg 7 of the pdf) we see this clearly:
” H_0: no effect on any patient,
H_a: ACT population mean – PBO population mean 0
I’ll just ignore this for now and treat H_a as if it is:
ACT population mean – PBO population mean != 0
2) It is clear that if H_0 is true, then:
ACT population mean – PBO population mean = 0
This is the *actual statistical hypothesis* being tested. It is deduced from the H_0 *as written* by simple deduction. Great, but obviously there are other possibilities. For example, the drug increases the blood pressure of 50% of patients by x mmHg and decreases it by the same amount for the other half. By that I mean we can deduce the same *actual statistical hypothesis* just as well from that second scenario.
My point is that what is really being tested is the statistical hypothesis:
H_0: ACT population mean – PBO population mean = 0
It is important to distinguish this from what got written as the null hypothesis:
“H_0: no effect on any patient”
So I have to disagree with the claim that: “The null being tested has nothing to do with mu or any other model parameter.” There is a bait and switch going on here. What is getting tested is the statistical hypothesis (involving parameters like mu1/mu2) which is deduced from the “no effect on any patient” hypothesis. However these two hypotheses are not equivalent, there is a many to one mapping of these “higher up” hypotheses to the statistical hypothesis.
Obviously if we reject the statistical hypothesis we must also reject the “no effect on any patient” hypothesis, but that doesn’t mean these parameter values are irrelevant…in fact there are many mentions of parameters like mu1/mu2/etc that wouldn’t be there if they were really irrelevant.
Here’s the setup from the paper:
“The study aimed to test how two different drugs impact whether a patient recovers from a certain disease. Subjects were randomly drawn from a fixed population and then randomly assigned to Drug A or Drug B. Fifty-two percent (52%) of subjects who took Drug A recovered from the disease while forty-four percent (44%) of subjects who took Drug B recovered from the disease.
A test of the null hypothesis that there is no difference between Drug A and Drug B in terms of probability of
recovery from the disease yields a p-value of 0.175. Assuming no prior studies have been conducted with
these drugs, which of the following statements is most accurate?”
So this is a textbook example of comparing average scores of two groups. In simple, but workable terms understandable to the average person the null is “There is no difference between the groups” and the alternative is: “The is a difference” (i.e. H_0 is mean score in group A = mean score in group B; H_a is mean score in group A != mean score in group B).
The top part of this post got eaten. It should be:
”
[…]
I read through the paper. I think there is an affirming the consequent fallacy here. On page 99 (pg 7 of the pdf) we see this clearly:
” H_0: no effect on any patient,
H_a: ACT population mean – PBO population mean [less than] 0 ”
1) Oddly, the choices of H_0/H_a here does not exhaust the hypothesis space. Obviously we are missing:
ACT population mean – PBO population mean [greater than] 0
I’ll just ignore this for now and treat H_a as if it is:
ACT population mean – PBO population mean != 0
2) It is clear that if H_0 is true, then:
[…]
Mr. T wrote:
>”Here’s the setup from the paper:”
In the post you responded to I was referring to the Stewart (2002) Groundhog day paper: https://www.ncbi.nlm.nih.gov/pubmed/12413233
Anyway. I am essentially saying that this is a misleading description:
>”In simple, but workable terms understandable to the average person the null is “There is no difference between the groups” and the alternative is: “The is a difference” (i.e. H_0 is mean score in group A = mean score in group B; H_a is mean score in group A != mean score in group B).”
Apparently for whatever “randomization-based test” that is being discussed in the Shewart (2002) paper the statistical null hypothesis consists of only mu1=mu2 (ie mu1 – mu2 = 0). However, usually there are other components (usually called assumptions*) of the statistical null hypothesis that when violated will mean the null is correctly identified as false (even if mu1 really does equal mu2). As an example, in the case of the MRI paper they identify a major reason for deviations from the null hypothesis. In that case it is apparently “spatial autocorrelation functions that do not follow the assumed Gaussian shape”.
There is more to the null hypothesis *that is actually tested* than is included in those short statements.
[1] https://en.wikipedia.org/wiki/Student%27s_t-test#Assumptions
[2] https://www.pnas.org/content/113/28/7900.full
“This is the *actual statistical hypothesis* being tested.” No, it’s not. Using a t-test to compare means is one way to conduct the test, but it serves only as an approximation to the randomization-based test which has nothing at all to do with means … you don’t actually have to use a t-test, there is a better test to use. Here is another paper that provides more analytic detail: https://www.ncbi.nlm.nih.gov/pubmed/?term=tukey+and+%27tighening+the+clinical+trial%22
To be fair: that paper got a correction and the findings apply to about three thousand papers rather than 40,000 (this is obviously still not good but the paper was misinterpreted).
Thanks, it is bizarre that no mention of this correction can be found on PNAS site. Instead you need to go to pubmed and a blog to see it:
https://www.ncbi.nlm.nih.gov/pubmed/27357684
https://blogs.warwick.ac.uk/nichols/entry/bibliometrics_of_cluster/
Thanks for the write-up of the Groundhog Day paper–I’ll be sure to give it a read. I’ll come back to this thread to reread your comments about the null. I fully agree with you that “there is more than meets the eye” in such studies, but at some point a decision has to be made, and those usually come at a cost of simplification (in this case you want to have some info about whether some knowledge of p-values may be a potential problem–even if it’s the people’s fault). I also think that certain things are implied, and others must be simplified for the sake of the thought experiment (as far as I’m concerned the success rate provided in percentage points suggests a dichotomous outcome and we don’t have to dwell on it: it worked for 44% and that’s it; that’s all the info you got, make your decision. I’m sure you could make similar complaints about the trolley problem: is the fat guy you’re about to push off the bridge a millionaire about to give away his wealth? We don’t know, we know it’s live or die for him or five other people).
Yes, the some of the premises of this paper can be questioned, but the authors do provide information about option D and explain what they mean regards the consistency required for the follow-up question. I’m not sure I see this inconsistency necessarily as a mistake: the fist question reads like a “what does a p-value entail” and the second one is more about whether it makes sense to discard evidence just because the p value is too high (the “not statistically significant” is itself not “not significant”?). In the end however this doesn’t change the fact, that apparently the very introduction of a p-value makes people confused about whether 8 > 7.
Anyway, I quite like these kinds of papers, because reading them–and all the critical comments that ensue–helps me understand the philosophy behind statistics a bit more (e.g. “Misinterpretations of Significance: A Problem Students Share with Their Teachers?” by Haller & Krauss, 2002).
And, yes, I agree that the entire battle between frequentists and Bayesians is not a priority unlike introducing maximum transparency in science (pre-registration is nice, open data is crucial, paywalls are evil, criticism is the very heart of science).
Mark, the authors do not seem to be taking a position on which option is “correct” in their Study 2. Their point seems to be that a p-value is a continuous measure of the evidence but it is treated dichotomously. As the figure Andrew posted shows, there are sharp differences between the p 0.05 conditions but no real differences among the p > 0.05 conditions. They show this for Option A in the figure but the table in the paper shows it also applies for the Option D you favor. That said, under a non-informative prior the posterior probability A is better than B is one minus the two-sided p-value divided by two so even with p = 0.175 there is a ~91% probability A is better which seems large to me.
Further, as Mr T. points out, this doesn’t change their hilarious Study 1 result “that apparently the very introduction of a p-value makes people confused about whether 8 > 7”.
I guess I misunderstood when they wrote “The *correct answer* is option A because Drug A is more likely to have higher efficacy than Drug B regardless of the p-value.” I disagree with the very notion of interpreting the p-value as a posterior probability (although I do agree with the notion that a p-value is a continuous measure of evidence that shouldn’t be treated as a dichotomous threshold… however, a p of 0.175 is very weak evidence verging on absolutely no evidence).
I completely agree with what they say regarding their Study 1.
Fair point. Sorry for missing they wrote “correct answer.” That said, given their definition of “correct” seems to be
Pr(A better than B) > 0.5
wouldn’t you agree? I agree with you that the 0.91 from the p-value / non-informative overstates things (a frequent theme of Andrew on the blog and elsewhere), but I would still think the probability is greater than a half in their scenario even if not much greater.
I guess it hinges on how weak your “very weak evidence verging on absolutely no evidence” is.
No, I wouldn’t agree. Personally, I’d head more towards absolutely no evidence as I don’t tend to take point estimates as evidence.
I don’t think randomization based inference tests “the strong null of no effect for any randomized participant”
at best, it tests the null of “no difference in distribution between the two populations” which is a stronger test than “no difference of means” by far, but it doesn’t let you get at “no difference for any individual between the factual outcome and the counterfactual outcome under the alternative treatment” at least not without a lot of additional assumptions.
For example suppose that giving a drug improves some outcome for 50% of the population by 1 point on a given scale, and decreases the outcome by 1 point for the rest. Suppose that the group that is decreased tends to be about 1 point higher to begin with, and the group that is increased tends to be 1 point lower to begin with… Then the drug has an effect, but it doesn’t alter the distribution of outcomes, and wouldn’t show up as different on a randomization based test.
No, it does test the strong null, see the Tukey paper that I referenced above. However, it is not able to detect differences such as the one you hypothesize. Also, the conclusions from a randomization test are really limited to finding evidence that the drug helped at least some people, but you can’t really identify which people. So, the inference is limited… I’m personally fine with that.
I don’t have access to the Tukey paper.
Suppose you have two populations. A_i and B_i. We assume that these are drawn from a super-population U_i by random number generator, and that they are large populations.
Now, we give a treatment to group A and placebo to group B with blinding of everyone involved.
Now suppose that we divide group A into Aa and Ab by random number generator, and the treatment we give is essentially equal in effect to Aa_i exchanging their outcome with the outcome of Ab_i. This clearly leaves the population distribution A_i unchanged. However, there could potentially be large effects on individuals. For example, suppose the “exchange” is that a bank-account balance is transferred between two random people. Now some poor people are rich, and some rich people are poor.
We can generalize this to any set of effects that vary across population A and leave the distribution unchanged…. Unless you are looking at before-after measurements within-person, then you couldn’t detect this using randomization testing. If you ARE looking at before-after measurements, then no test is needed, simply see if after was different from before.
Its the Fisher strict null that Mark is referring to versus the Neyman null that have re-described (there are effects on individuals but they _magical_ cancel out to exactly 0).
Now the simplest case of Fisher strict null is when there are two groups and the outcomes are binary – Fisher’s Exact test which just an excuse to distract people to a really neat poster that Andrew may have forgotten about.
https://statmodeling.stat.columbia.edu/2007/08/21/ken_rice_on_con/
This doesn’t seem an issue specific to randomisation tests. Maybe I didn’t understand the example, though. Could you give an example of any other method that would be able to detect this effect without looking at before-after measurements within-person? Maybe that’s your point after all, but if the effect you want to detect is the change from the baseline, it might be handy to measure the change from the baseline. Otherwise, it seems like complaining that randomisation tests cannot detect drug-induced changes in blood pressure when you only measure the patients height.
No, I’m just complaining the the claim that randomization tests test a *causal hypothesis about individual counterfactuals* is really false, I’m not saying that there’s some better way. The only better way is to have either a causal model and do model-based inference, or to change the design of the experiment.
Ok, understood. Still, I’d be curious to know how could you do it with a causal model if the distributions of A_i and B_i are really identical.
If you have measured covariates and a causal model of how those covariates affected the individuals, then you can get estimates of the individual effects from the model. In the “switching bank balances” case for example if you know the dollar value of the clothes the person was wearing when they came into the bank you can potentially estimate the previous bank balance based on your model of how the previous bank balance affects choice of expensive or cheap clothing… and then you can look at post-treatment bank balance and your uncertain estimate of the pre-treatment bank balance, and get individual estimates of the effect of the treatment. Uncertain, yes, but still individualized.
The reshuffling effect is not just something I made up either. What is the effect of throwing pellets into one end of a fishtank on the spatial distribution of fish in the tank when half the fish eat that kind of food, and half don’t?
What is the effect of giving a drug on the concentration of hormone X that unbeknown to us affects different versions of the hormone receptor differently?
What is the effect of some wealth-transfer policy on various measures of well-being of a population in a county?
Then you can calculate the correlation (or the corresponding output for whatever nice and shiny model you have) between clothing value and account balance for the group A and calculate the correlation between clothing value and account balance for the group B. Compute the difference, and look at the distribution of this statistic when randomising individuals to the group A and the group B. That you are using a randomisation test doesn’t mean you are not allowed to do it in an intelligent way.
No, suppose Aa and Ab are randomly selected subsets of A and we’re doing the balance transfer. Since they’re randomly selected there’s no correlation between the clothes and the outcome. But, there is a correlation between the clothes, and the causal estimate of the pre-treatment value.
So, if you’re saying that you can put a causal model and a randomization test together to get secret sauce, then yes, that’s fine, but without the causal model, the randomization test doesn’t solve the problem of figuring out the *individual effects* because you need to do the estimation of the unobserved stuff using the causal model.
I don’t understand what are you denying exactly. Don’t you agree that the correlation between clothes and accounts will be larger in the group B (where the rich people have nicer clothes and fatter accounts) than in the group A (where you have “re-assigned” accounts “diluting” the correlation with clothes)?
I think what I proposed is quite standard. You have a treatment group A and a control group B. You would like to now if the treatment has an effect on, say, redistribution of wealth. You measure somehow the thing in each group, a very simple model may be to look at the correlation between clothes (a proxy for pre-treatment wealth) and accounts (a proxy for post-treatment wealth). Lower correlation, higher redistribution. Or you estimate the “natural” wealth and compare to the “actual” wealth, whatever. Quite often, the measure will be different for group A and group B. To see how much this difference is suggestive of a real effect, you assume there is no effect and there is no difference between the treatment group and the control group. You are then allowed to exchange the labels freely. You randomise, recalculate your statistic and look at where your outcome falls in the distribution under the null hypothesis.
If your point is that it works only because I’m looking at a relevant statistic that might actually give information about the effect I’m trying to detect, then you are not wrong. We are in complete agreement, I could do much worse and try to detect redistribution of wealth measuring something unrelated.
Got it. I think ultimately your point is that just because the distribution of one measurement is left unchanged by a treatment doesn’t mean that you can’t construct a different measurement which wasn’t left unchanged, and if you do this using appropriately relevant information you will be able to detect a difference between the populations.
It is however still the case that the randomization test tests the hypothesis of “no difference in distribution detectable by test statistic foo” not “the strong null of no effect on any individual”
To make this mathier, suppose you have a measured finite population of vectors A with distribution D(A) and a similar population of B both drawn using RNG from a super-population U such that A+B = U. Where + is taken to be the union of the two sets of measurements.
we have some test statistic t(D(Foo)) which can take a finite population of measurements Foo with distribution D(Foo) and turn it into a number. Examples are “take the average” or “take the median” or “average f(x) across the x” or “take the inter-quartile range” or “calculate the sum of squares” or whatever. The randomization test tests the following
t(D(A)) is / is not outside the 95%tile bound of t(D(Resample(A+B))) for some allowable set of resampling possibilities.
But that is very different from “there is no effect on any individual element of A”. Whenever the effect on A is such that a moderate number of Resample(A+B) populations have the same t value you will not be able to detect the difference even though from a practical perspective the effects could be practically very significant for the members of A, such as the wealth transfer example where the only information incorporated into t is the final bank account balances (but I agree, not when t incorporates both clothing choice and final account balance and there is a causal connection between clothing choice and pre-balance for example).
From the Tukey (1993) paper:
‘For a small experiment, the use of randomization is simple. We decide in advance which assignments (of experimental units to treatments) are acceptable and what response is to be studied. We choose one of the acceptable assignments “at random”–where the choice can involve a neutral umpire– we conduct the corresponding experiment, we analyze the single set of responses once for each acceptable assignment (analyzing “as if” that assignment had, in fact, been used). Finally, we take all the results, sort them from negative to positive, and ask where the single actual result falls. If it falls in the extreme 5% of all results, we call it “significant.”‘
The key word here is *result*, as in “ask where the single actual result falls”. That result will be mu1 – mu2, so once again I do think mu1 – mu2 = 0 is a central aspect of the null hypothesis being tested.
No, it could be anything of interest, difference in medians, ratio of 3rd quartile, whatever might make scientific sense.
Right, but it CAN’T be “difference between the actual outcome for each subject and the counterfactual outcome that would have happened if they were assigned to the other randomization group”
and that is the point I’m trying to make above, because that is what “the individual effect of the treatment” means.
The title of this post should really be “More evidence that even top researchers routinely misinterpret 0.05”.
I am a PhD student major in psychology. I was wondering if I would like to do hypothesis testing without using the p-value approach, what else can I use? Any links I could further explore this topic?
Paul Meehl is great:
(1967). Theory-testing in psychology and physics: A methodological paradox. Philosophy of Science, 34, 103-115.
(1978). Theoretical risks and tabular asterisks: Sir Karl, Sir Ronald, and the slow progress of soft psychology. Journal of Consulting and Clinical Psychology, 46, 806-834.
(1990). Appraising and amending theories: The strategy of Lakatosian defense and two principles that warrant using it. Psychological Inquiry, 1, 108-141, 173-180.
(1997) The problem is epistemology, not statistics: Replace significance tests by confidence intervals and quantify accuracy of risky numerical predictions. In L. L. Harlow, S. A. Mulaik, & J.H. Steiger (Eds.), What if there were no significance tests? (pp. 393-425). Mahwah, NJ: Erlbaum.
https://meehl.umn.edu/recordings/philosophical-psychology-1989
Also, LL Thurstone and Harold Gulliksen are great examples of how to approach psych problems without NHST:
Thurstone, L.L. (1930). The Learning Function. The Journal of General Psychology 3, 469–493. doi:10.1080/00221309.1930.9918225
Thurstone, L. L. The error function in maze learning.J. gen. Psychol., 1933,9, 288–301. doi:10.1080/00221309.1933.9920938
Gulliksen, H. A rational equation of the learning curve based on Thorndike’s Law of Effect.J. gen. Psychol., 1934,11, 395–434
Thurstone, L. L. “Psychology as a Quantitative Rational Science.” Science 85, no. 2201 (1937): 227-32. https://www.jstor.org/stable/1662685.
Gulliksen, H. A generalization of Thurstone’s learning function. Psychometrika (1953) 18: 297. doi:10.1007/BF02289265
Gulliksen, H. (1959). Mathematical Solutions For Psychological Problems. American Scientist, 47(2), 178-201. https://www.jstor.org/stable/27827302
That should show you there is a light at the end of the NHST doomcave at least…
Thank you so much!
As I am reading this post and nodding my head in agreement, I am also thinking about how does one explain all this nuance to the 19 y/o sitting in your business or psych stats 101 class, when the topic of p values are introduced (about Ch 6 or 7 in most basic applied stats books)? As noted- this is where the problem begins. We needed an understandable way to introduce this topic, and thus likely came the dichotomization of p (and then they still don’t really understand it).
So even agreeing with all the above, I still am thinking how to explain in understandable terms to that young student what is a p value and what do you do with it? Feeding them many of the recommendation of the paper (ie a good dose of Bayesian) will not do the trick. We have professional researchers above debating truth and consequences without full agreement. Thoughts?
Myles:
I don’t think these kids should be taught p-values at all. But I did teach that there’s a 95% chance that the estimate is within 2 standard errors of the true value.
Students mostly need to learn about P-values because they are widely used as the currency for research. Absent some mention of P-values the students will be demonstrably underprepared. However, we certainly need to do better.
A solution to the problem of dichotomisation of P-values will not be available until researchers are coaxed into a mindset where the evidential meaning of the results is evaluated as part of the inferential process. The conventional dichotomisation precludes any proper evaluation of the evidence in the data. Selling the idea that the evidence is important should not be too difficult.
The sole logical use for p values is to tell whether a particular data point is unusual under a meaningful null model. It is after all “the probability of a result more extreme than the observed result under a model of random generation of results where the frequency distribution of results is fixed and specified”
Examples of logical usage given this definition:
1) from 1000 satellite photos of foliated ground-cover in a certain area, fit a model for the frequency distribution of IR intensity in a certain band (a measure of foliage). Then, if you get a new photo, you can ask whether the amount of foliage is outside the range of what you’d expect so that you can detect where lakes, developed land, or recent forest fires occurred.
2) from a continuous recording seismometer record for a year, select one thousand 10 second intervals at random. Assuming moderate sized or larger earthquakes occur infrequently (on the order of once every year), all of the 10 second intervals will be noise. Fit a frequency distribution to the intensity of the signal in each interval (say sum of squared acceleration in a certain frequency band). Now, for every 10 second interval in the whole record determine a p value relative to this fitted background noise, and flag all intervals with p < 0.0001 as unusual and needing further study. Now, instead of intensely signal-processing 3.2 million intervals per year, you can signal-process 320. Adjust your p value as needed to allow you to detect smaller events.
3) From a random selection of 1000 credit card owners, and 10000 non-fraudulent transactions evaluate a proposed fraud risk score function F. Now, from a hand-picked selection of fraudulent transactions, evaluate F. If the F under known fraud transactions routinely has low p value under the non-fraudulent reference distribution, start using p(F) as a measure of whether to flag transactions for analysis of risk by a human.
In the absence of a meaningful stable repetitive process and a null model fit to data from that process, a p value is logically useless. In all other cases, logic dictates Bayesian analysis of a model to understand what is going on.
Just teach the truth, not the cargo cult.
>In the absence of a meaningful stable repetitive process and a null model fit to data from that process, a p value is logically useless
Sure, but in the absence of a stable process (or a stable component in the process), the prospects of successfully going beyond description are bleak.
This was one of my more recent attempts
As helpful as a correct nominal definition of p-values and an ability to discern what is and is not a p-value may be, arguably the critical conceptualization involves what to make of a p-value, and thereby in turn, the study under consideration.
Even correct nominal definitions are hard to get agreement on. The American Statistical Society’s recent statement on p-values had 20 published comments. Some support a version of “the null hypothesis is that the treatment and the placebo produce the same effect” but more argued for what I believe is a more purposeful version. This being that it also includes a myriad of background assumptions (e.g. random assignment, lack of informative dropout, pre-specification rather than cherry picking of outcome, etc.). Essentially everything that is required so that the distribution of p-values when the “treatment and the placebo produce the same effect” is (technically) known to be equal to the Uniform(0,1) distribution. Without that last bit of knowledge, no one could sensibly know what to make of a p-value. Even with it, it is very hard, if not debatable.
As for those outside the debate (practicing statisticians and others), perhaps the best sense for them of what to make of a p-value (and thereby in turn the study under consideration), would be simply – if its less than 0.05 folks are likely somewhat over excited about the study and greater than 0.05 likely somewhat overly dismissive of the study. Then perhaps they can better focus on all the other issues involved for understanding studies or at least not overlook them.
I see Andrew’s suggestion below as focusing on something else that has a seemingly simpler nominal definition and more easily discerned instances. What to make of it in turn what it means for the study under consideration is still very hard – but I think students are less likely to get hung up and confused on it and can focus better on other issues for understanding studies.
Now for the seemingly qualification, what if the distribution is highly skewed (i.e. implicit need for approx Normality) or and the estimate confounded so biased and the chance the estimate is within 2 standard errors of the true value is anywhere from 0% to 100% (unless the standard errors are really small compared to the bias in which case it is close to 0%.)
Well, this is perhaps an advantage of sociology but I think it is relevant in psychology too, one thing is that you can talk about how disciplines have cultures and communities of practice, and p values are a part of this that they will see when reading journals and seeing presentations. Also, I think the certainty and definitiveness of many Stats 101 books is problematic and contributes to the problem, and I shock my undergraduates and say that statisticians actually disagree with each other about issues like p values. You could even show them the ASA statement and responses. This is really, really a surprise to most students since they have been taught that statistics is just plug and chug.[1] And therefore you’re going to focus helping them really understand some of the basic issues that have to do with relating samples to populations or understanding results in experiments. And then, personally, I suggest do a lot of simulation and/or boot strapping. Statkey is a good resource for this. Also, fundamentally, I feel it is important to make the decision to focus on understanding rather than covering every variation of everything that is in the text book.
[1] Related to this idea of shocking students,I’ve actually been working on an early weeks lesson about the median that looks at all the options in quantile() in R– not really the math of them, but just the fact that they exist.
This seems relevant: https://m.pss.sagepub.com/content/27/7/1036
Marginally Significant Effects as Evidence for Hypotheses
Changing Attitudes Over Four Decades
Some effects are statistically significant. Other effects do not reach the threshold of statistical significance and are sometimes described as “marginally significant” or as “approaching significance.” Although the concept of marginal significance is widely deployed in academic psychology, there has been very little systematic examination of psychologists’ attitudes toward these effects. Here, we report an observational study in which we investigated psychologists’ attitudes concerning marginal significance by examining their language in over 1,500 articles published in top-tier cognitive, developmental, and social psychology journals. We observed a large change over the course of four decades in psychologists’ tendency to describe a p value as marginally significant, and overall rates of use appear to differ across subfields. We discuss possible explanations for these findings, as well as their implications for psychological research.
For a good laugh (or lament) see https://mchankins.wordpress.com/2013/04/21/still-not-significant-2/
Actually, I have a funny story here. One research lab argued for a null result with p = .13 because that’s what they “wanted”. Then the same research lab published a paper several years later with p = .11 and argued this was significant because that’s what they wanted this time round. As one of my students put it, the methodology can be called Feeling-based Statistical Inference, inspired by John Oliver’s recent comment: https://www.youtube.com/watch?v=zNdkrtfZP8I
It’s a worrying thought that among the many papers published in psycholinguistics, there may be literally nothing there. I think this is OK, if we are open about the fact that the purpose of publishing papers is not actually do science, but to get jobs in academia. Because the number and journal-name of publications is what we look at to decide who to hire. I have strong evidence (p<0.05, because why the hell not) that people don't even read beyond the title of the paper they cite. They don't even read the author names fully once they recognize a brand name researcher, or think they have recognized a name they know.
Actually very appropriate, where as politicians cause to believe and (good) scientists cause to understand most academics just cause to fund and cite.
And if you haven’t seen it, John Oliver on Scientific Studies: https://www.youtube.com/watch?v=0Rnq1NpHdmw
I think actually this is poorly designed as a study of whether .05 is a magic number. It would have been better to use a set of p values all close to .05. With the numbers they have there is no way to know if there is some kind of inflection point at .05 or somewhere else between .025 and .075. Also if they would use a smaller range of of p values the implicit sample size differences would not be as large. I find the certainty of the “correct” answer choice troubling no matter what the p value or effect size. I really do not like their definitive use of the word “is” in the responses and actually think that some people might have thought it was a trick question or that the authors were trying to see if they knew what is usually taught in intro stats.