Recently I had a disagreement with Larry Bartels which I think is worth sharing with you. Larry and I took opposite positions on the hot topic of science criticism.
To put things in a positive way, Larry was writing about some interesting recent research which I then constructively criticized.
To be more negative, Larry was hyping some sexy research and I was engaging in mindless criticism.
The balance between promotion and criticism is always worth discussing, but particularly so in this case because of two factors:
1. The research in question is on the borderline. The conclusions in question are not rock-solid—they depend on how you look at the data and are associated with p-values like 0.10 rather than 0.0001—but neither are they silly. Some of the findings definitely seem real, and the debate is more about how far to take it than whether there’s anything there at all. Nobody in the debate is claiming that the findings are empty; there’s only a dispute about their implications.
2. The topic—the effect of unperceived messages on political attitudes—is important.
3. And, finally, Larry and I generally respect each other, both as scholars and as critics. So, even though we might be talking past each other regarding the details of this particular debate, we each recognize that the other has something valuable to say, both regarding methods and public opinion.
What it’s all about
The background is here:
We had a discussion last month on the sister blog regarding the effects of subliminal messages on political attitudes. It started with a Larry Bartels post entitled “Here’s how a cartoon smiley face punched a big hole in democratic theory,” with the subtitle, “Fleeting exposure to ‘irrelevant stimuli’ powerfully shapes our assessments of policy arguments,” discussing the results of an experiment conducted a few years ago and recently published by Cengiz Erisen, Milton Lodge and Charles Taber. Larry wrote:
What were these powerful “irrelevant stimuli” that were outweighing the impact of subjects’ prior policy views? Before seeing each policy statement, each subject was subliminally exposed (for 39 milliseconds — well below the threshold of conscious awareness) to one of three images: a smiling cartoon face, a frowning cartoon face, or a neutral cartoon face. . . . the subliminal cartoon faces substantially altered their assessments of the policy statements . . .
I followed up with a post expressing some skepticism:
Unfortunately they don’t give the data or any clear summary of the data from experiment No. 2, so I can’t evaluate it. I respect Larry Bartels, and I see that he characterized the results as the “subliminal cartoon faces substantially altered their assessments of the policy statements — and the resulting negative and positive thoughts produced substantial changes in policy attitudes.” But based on the evidence given in the paper, I can’t evaluate this claim. I’m not saying it’s wrong. I’m just saying that I can’t express judgment on it, given the information provided.
Larry then followed up with a post saying that further information was in chapter 3 of Erisen’s Ph.D. dissertation and presented as evidence this path analysis:
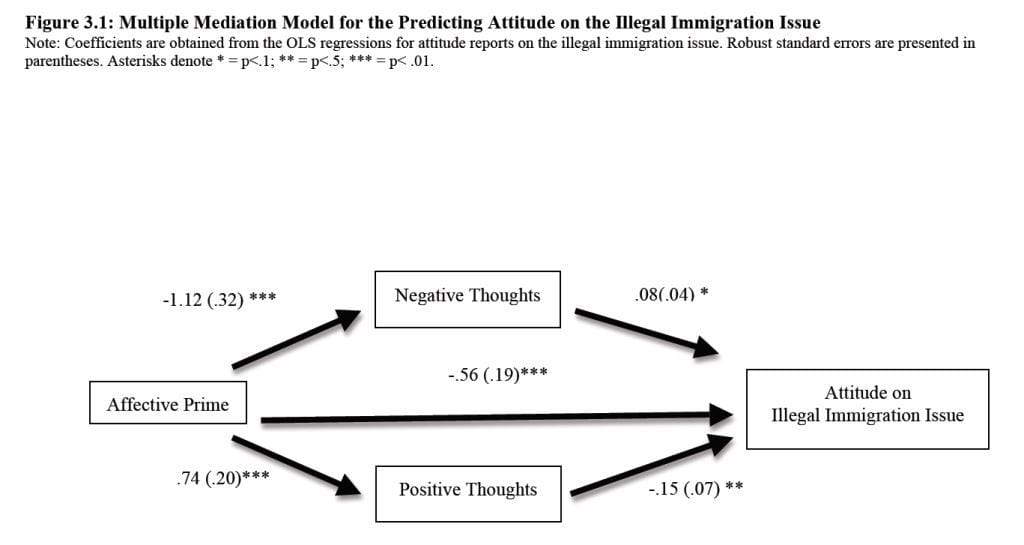
along with this summary:
In this case, subliminal exposure to a smiley cartoon face reduced negative thoughts about illegal immigration, increased positive thoughts about illegal immigration, and (crucially for Gelman) substantially shifted policy attitudes.
And Erisen sent along a note with further explanation, the centerpiece of which was another path analysis.
Unfortunately I still wasn’t convinced. The trouble is, I just get confused whenever I see these path diagrams. What I really want to see is a direct comparison of the political attitudes with and without the intervention. No amount of path diagrams will convince me until I see the direct comparison.
However, I had not read all of the relevant chapter of Erisen’s dissertation in detail. I’d looked at the graphs (which had results of path analyses, and data summaries on positive and negative thoughts, but no direct data summaries of issue attitudes) and at some of the tables. It turns out, thought that there were some direct comparisons of issue attitudes in the text of the dissertation but not in the tables and figures.
I’ll get back to that in a bit, but first let me return to what I wrote at the time, in response to Erisen and Bartels:
I’m not saying that Erisen is wrong in his claims, just that the evidence he [and Larry] shown me is too abstract to convince me. I realize that he knows a lot more about his experiment and his data than I do and I’m pretty sure that he is much more informed on this literature than I am, so I respect that he feels he can draw certain strong conclusions from his data. But, for me, I have to go what information is available to me.
Why do these claims from path analysis confuse me? An example is given in a comment by David Harris, who reports that Erisen et al. “seem to acknowledge that the effect of their priming on people’s actual policy evaluations is nil” but that they then follow up with a convoluted explanation involving a series of interactions.
Convoluted can be OK—real life is convoluted—but I’d like to see some simple comparisons. If someone wants to claim that “Fleeting exposure to ‘irrelevant stimuli’ powerfully shapes our assessments of policy arguments,” I’d like to see if these fleeting exposures indeed have powerful effects. In an observational setting, such effects can be hard to “tease out,” as the saying goes. But in this case the researchers did a controlled experiment, and I’d like to see the direct comparison as a starting point.
Commenter Dean Eckles wrote:
The answer is that those effects are not significant at conventional levels in Exp 2. From ch. 3 (pages 89-91) of Cengiz Erisen’s dissertation (from https://dspace.sunyconnect.suny.edu/handle/1951/52338) we have:
Illegal Immigration: “In the first step of the mediation model a simple regression shows the effect of affective prime on the attitude (beta=.34; p [less than] .07). Although not hypothesized, this confirms the direct influence of the affective prime on the illegal immigration attitude.”
Energy Security: “As before, the first step of the mediation model ought to present the effect of the prime on one’s attitude. In this mediation model, however, the affective prime does not change energy security attitude directly (beta=-.10; p [greater than] .10. Yet, as discussed before, the first step of mediation analysis is not required to establish the model (Shrout & Bolger 2002; MacKinnon 2008).”
So (the cynic in me says), this pretty much covers it. The direct result was not statistically significant. When it went in the expected direction and was not statistically significant, it was taken as a confirmation of the hypothesis. When it went in the wrong direction and was not statistically significant, it was dismissed as not being required.
Back to the debate
OK, so here you have the story as I see it: Larry heard of an interesting study regarding subliminal messages, a study that made a lot of sense especially in light of the work of Larry and others regarding the ways in which voters can be swayed by information that logically should be irrelevant to voting decisions or policy positions (and, indeed, consistent with the work of Kahneman, Slovic, and Tversky regarding shortcuts and heuristics in decision making). The work seemed solid and was supported by several statistical analyses. And there does seem to be something there (in particular, Erisen shows strong evidence of the stimulus affecting the numbers of positive and negative thoughts expressed by the students in his experiment). But the evidence for the headline claim—that the subliminal smiley-faces affect political attitudes themselves, not just positive and negative expressions—is not so clear.
That’s my perspective. Now for Larry’s. As he saw it, my posts were sloppy: I reacted to the path analyses presented by him and Erisen and did not look carefully within Erisen’s Ph.D. thesis to find the direct comparisons. Here’s what Larry wrote:
Now it seems that one of your commenters has read (part of) the dissertation chapter and found two tests of the sort you claimed were lacking, one of which indicates a substantial effect (.34 on a six-point scale) and the other of which indicates no effect. If you or your commenter bothered to keep reading, you would find four more tests, two of which (involving different issues) indicate substantial effects (.40 and .51) and two of which indicate no effects. The three substantial effects (out of six) have reported p-values of <.07, <.08, and >.10. How likely is that set of results to occur by chance? Do you really want to argue that the appropriate way to assess this evidence is one .05 test at a time?
Hmmm, I’ll have to think about this one.
My quick response is as follows:
1. Sure, if we accept the general quality of the measurements in this study (no big systematic errors, etc.) then there’s very clear evidence of the subliminal stimuli having effects on positive and negative expressions, hence it’s completely reasonable to expect effects on other survey responses including issue attitudes.
2. That is, we’re not in “Bem” territory here. Conditional on the experiments being done competently, there are real effects here.
3. Given that the stimuli can affect issue attitudes, it’s reasonable to expect variation, to expect some positive and some negative effects, and for the effects to vary across people and across situations.
4. So if I wanted to study these effects, I’d be inclined to fit a multilevel model to allow for the variation and to better estimate average effects in the context of variation.
5. When it comes to specific effects, and to specific claims of large effects (recall the original claim that the stimulus “powerfully [emphasis added] shapes our assessments of policy arguments,” elsewhere “substantially altered,” elsewhere “significantly and consistently altered,” elsewhere “punched a big hole in democratic theory”), I’d like to see some strong evidence. And these “p less than .07” and “p greater than .10” things don’t look like strong evidence to me.
6. I agree that these results are consistent with some effect on issue attitudes but I don’t see the evidence for the large effects that have been claimed.
7. Finally, I respect the path analyses for what they are, and I’m not saying Erisen shouldn’t have done them, but I think it’s fair to say that these are the sorts of analyses that are used to understand large effects that exist; they don’t directly address the question of the effects of the stimulus on policy attitudes (which is how we could end up with explanation of large effects that cancel out).
As a Bayesian, I do accept Larry’s criticism that it was odd for me to claim that there was no evidence just because p was not less than 0.05. Even weak evidence should shift my priors a bit, no?
And I agree that weak evidence is not the same as zero evidence.
So let me clarify that, conditional on accepting the quality of Erisen’s experimental protocols (which I have no reason to question), I have no doubt that some effects are there. The question is about the size and the direction of the effects.
Summary
In some sense, the post-publication review process worked well: Larry promoted the original work on the sister blog which gave it a wider audience. I read Larry’s post and offered my objection on the sister blog and here, and, in turn, Erisen and various commenters replied. And, eventually, after a couple of email exchange, I finally got the point that Larry had been trying to explain to me, that Erisen did have the direct comparisons I’d been asking for, they were just in the text of his dissertation and not in the tables and figures.
This post-publication discussion was slow and frustrating (especially for Larry, who was rightly annoyed that I kept saying that the information wasn’t available to me, when it was there in the dissertation all along), but I still think it moved forward in a better way than would’ve happened without the open exchange, if, for example, all we’d had were a series of static, published articles presenting one position or another.
But these questions are difficult and somewhat unstable because of the massive selection effects in play. This discussion had its frustrating aspects on both sides but things are typically much worse! Most studies in political science don’t get discussed on the Monkey Cage or on this blog, and what we see is typically bimodal: a mix of studies that we like and think are worth sharing, and studies that we dislike and think are worth taking the time to debunk.
But I don’t go around looking for studies to shoot down! What typically happens is they get hyped by somebody else (whether it be Freakonomics, or David Brooks, or whoever) and then I react.
In this case, Larry posted on a research finding that he thought was important and perhaps had not received enough attention. I was skeptical. After all the dust has settled, I remain skeptical about any effects of the subliminal message on political attitudes. I think Larry remains convinced, and maybe our disagreement ultimately comes down to priors, which makes sense given that the evidence from the data is weak.
Meanwhile, new studies get published, and get neglected, or hyped, or both. I offer no general solution to how to handle these—clearly, the standard system of scientific publishing has its limitations—here I just wanted to raise some of these issues in a context where I see no easy answers.
To put it another way, I think social science can—and should—do better than we usually do. For a notorious example, consider “Reinhart and Rogoff”: a high-profile paper published in a top journal with serious errors that were not corrected for several years after publication.
On one hand, the model of discourse described in my above post is not at all scalable—Larry Bartels and I are just 2 guys, after all, and we have finite time available for this sort of thing. On the other hand, consider the many thousands of researchers who spend so many hours refereeing papers for journals. Surely this effort could be channeled in a more useful way.
So 3/6 analyses yield marginally significant p-values. One relevant question, posed by Larry, is “how likely is this set of results to occur by chance?” The other relevant question, however, is “how likely is this set of results to occur if there is an effect?”. If you postulate the presence of a reasonably big or interesting effect, the probability of obtaining these marginal results (and nothing more compelling) must be relatively low as well. In other words, when it comes to the assessment of evidence you can’t just focus on one side of the coin.
I agree. I’m more interested in the magnitude of the effect than its “significance.” There pretty much has to be some effect of at least some “irrelevant stimuli” on political attitudes and decisions because there is a recognized, non-negligible effect on personal economic attitudes and decisions. Otherwise billboards would just be black text on a white backgrounds for maximum readability, and companies wouldn’t bother redesigning their logos (which, after all, at least temporarily makes their logo _less_ recognizable to people).
Interesting questions in the political arena include the magnitude of the effect, and what stimuli are most effective and how much does this vary from demographic to demographic. There’s potentially interesting research here. And it surely would be interesting to figure out a bit more about why the effects happen—the sort of thing that can be illustrated in path diagrams.
That said, I agree that the main question of interest is, how much does the stimulus change a person’s political stance, or maybe change how they vote. Sure, we might care about positive and negative “thoughts” too, but if there’s little or no influence on what people do in the voting booth then ultimately who cares? And for this, a direct comparison is surely the best demonstration. Show 100 people Version 1, show another 100 people Version 2, and look at how people “vote” on an issue (even if the vote is simulated). Even a small effect might be important — there are plenty of close votes and close elections — but if something has a big influence on “thoughts” but a very small influence on voting then that’s a very different story from both effects being large.
Finally, I’ll mention that there’s no way the stimuli studied in Erisen’s dissertation just happen to be the most effective such stimuli. Perhaps substantial effects can occur, but didn’t show up in this study. Or perhaps people almost completely ignore irrelevant stimuli, and even “positive and negative thoughts”, when it comes to actually voting.
Andrew: “conditional on accepting the quality of Erisen’s experimental protocols (which I have no reason to question),”
I can usually find at least a dozen reasonable and likely reasons to question almost any social science experiment.
The reason is we are still doing cowboy coding when what is needed is research practice engineering.
As a veteran and inveterate cowboy coder who was trained as an engineer and has a deep and abiding interest in reproducible research, I’m curious as to what your vision for research practice engineering entails.
@Corey:
Working on it but let me just point to the biggest difference:
Unlike coding, where iterative procedures are very useful, research typically requires Big Design Upfront (BDUF) if it is to be credible.
Iteration in science is typically associated with fishing, though there are exceptions if such iterations are well controlled. This is specially true in confirmatory causal experiments (as opposed to exploratory studies, or observational prediction exercises). I touch briefly on experimental failures and fishing here: http://ssrn.com/abstract=2496670
PS are you this type of cowboy coder? http://c2.com/cgi/wiki?CowboyCoder
No, I’m not that narcissistic; I’m a RuggedIndividualistCoder, but only in R (and lately, Lua) — I’ve yet to work in a team in which my R code needed to be legible to others. The C code I wrote on contract to spec was a model of well-commented, well-structured functionality, if I do say so myself ;-).
Ha! I think you are a GoodHumorCoder ;-)
At a curiosity what are you using lua for?
I’m so glad you asked! Lua is R-like enough that I’m comfortable coding in it, and it goes on mobile devices with ease, which is what I need to make (my contribution to) this happen.
So why not use r?
Playing devils advocate here… I’ve been toying with embedding lua in my c++ code myself. My impression is that it’s more lightweight and easier to embed than r, python, or other alternatives like julia.
For those who want more detail, here is what I see in the dissertation (https://dspace.sunyconnect.suny.edu/handle/1951/52338):
* All attitude positions are measured on a seven-point scale (page 88).
* Affective primes affect attitudes toward immigration (B = .34, p .1). Page 96.
* When subjects are exposed to an pro-immigration thought prompts, the affective prime “does not predict policy evaluations” (B = .40, p > .1). Page 98.
* “The affective prime does not change energy security attitude” (B = -.10, p = .10). Page 92.
* When subjects are exposed to anti-energy-security thought prompts, affective primes have a significant effect (B = .51, p .1). Page 102.
So: there are six tests. But there are only two distinct issues here — not four, as Larry seems to imply.
Note also that, in the analyses reported in the article, “those who did not report any thoughts in total for the provided statement are excluded from the statistical analysis” (page 195, footnote 2). The dissertation includes a similar statement (page 52). In other words, the authors estimate the effects of primes on attitudes after discarding data from people who were assigned to a treatment condition but subsequently listed zero thoughts in response to the thought prompts. This seems to have led the authors to discard around 15-20% of their cases. For example, they report N = 224 for Experiment 1 (page 192), but their Table 1 suggests that they analyze the data from only 177 or 194 respondents, depending on whether they are studying attitudes toward immigration or energy security.
The implication is that the reported estimates are not really estimates of the average treatment effects for the experimental sample.
The blog mauled part of my comment above. It seems to have trouble with some “less than” symbols. Here are the accurate citations:
* Affective primes affect attitudes toward immigration (B = .34, p less than .07). Page 89.
* When subjects are exposed to anti-immigration “thought prompts,” the affective primes have an insignificant effect on attitudes (B = -.07, p > .1). Page 96.
* When subjects are exposed to an pro-immigration thought prompts, the affective prime “does not predict policy evaluations” (B = .40, p > .1). Page 98.
* “The affective prime does not change energy security attitude” (B = -.10, p = .10). Page 92.
* When subjects are exposed to anti-energy-security thought prompts, affective primes have a significant effect (B = .51, p less than .08). Page 100.
* When subjects are exposed to pro-energy-security thought prompts, “the affective prime does not predict policy evaluations” (B = -.33, p > .1). Page 102.
This is too SM,CI,SS not to pull out and post on its own:
* Affective primes affect attitudes toward immigration (B = .34, p less than .07). Page 89.
* When subjects are exposed to pro-energy-security thought prompts, “the affective prime does not predict policy evaluations” (B = -.33, p > .1). Page 102.
A positive point estimate of .34 has a p-value below .1 and thus “affect(s) attitudes towards migration.” A negative point estimate of -.33 has a p-value above .1 and thus “does not predict policy evaluations.”
I don’t have anything to add other than pointing out that, for anyone not “trained” in experimental statistics, this must seem like an insane conclusion to read, given that the estimated effect sizes are equal. That doesn’t make it right, or wrong, or necessarily over-confident in its writing, it is just a beautifully symmetric realization of a problem we’ve been talking about for a while – the tyranny of NHST-type thinking in statistical inference (in the broadest sense of drawing conclusions from statistical analyses).
Thanks for pointing out the discarded cases. That alone destroys the credibility of the analysis.
But, to continue to beat a dead horse:
1. It’s not at all clear to me why “.34 on a six-point scale” is a “substantial effect.” I’m very skeptical of interpreting differences that are less than the precision of the measuring instrument.
2. The multiple inference combined with the generous criteria for “significant” strongly underwhelms me.
The inability of political scientists to engage in parison is remarkable. We have one school of political science that preaches a crude economic predeterminism in presidential elections and another that implies that Madison Avenue techniques can determine the election. The interest is not in any particular theory with a few confirmatory pieces of evidence but rather in engaging in analysis where the theories can be differentiated, or, is unfortunately almost certainly the case, not. This is the hallmark of a science.
Remembering when this came up earlier … I don’t buy the importance of the work but it doesn’t seem to fall in the category of a one-off that’s cited over and over as proof without further work. That is, since this is sexy, it will be studied more and subjected to more criticism.
I took a class years ago where we looked at the efficacy of subliminal advertising, meaning messages included in ads like penis shapes, etc. that your mind is supposed to pick up to influence buying. There wasn’t much there, other than looking at pictures to find cool images that may or may not have been hidden on purpose. It wasn’t a rigorous class; we didn’t alter images – couldn’t easily back in the dark ages – and test effects. But it seemed pretty clear that it didn’t affect sales, especially given the relatively weak research on what in the blunt categories of advertising affects sales.
>> The three substantial effects (out of six) have reported p-values of <.07, .10. How likely is that set of results to occur by chance? Do you really want to argue that the appropriate way to assess this evidence is one .05 test at a time?
If power is small, sample size is small, and/or noise was abnormally fat-tailed, we’d expect large (substantial) sample results even if the real mean effect is de minimus. Indeed in the high-noise/lower-power limit we’d expect about half (hmm, 3/6) of the values to be substantial and our preferred direction.
How could we check if this effect was a real threat?
Well first, p-values (at least assuming the statistical model is correct) are designed to compensate for large observations that are just due to noise/lower power, so we’d see them being substantially less enthusiastic about “substantial” sample observations. Which seems to be the case here.
Second, we’d expect some substantial observations in the unexpected direction as well. I haven’t read the thesis, but Larry Bartels clearly tells us that +0.34 is a substantial effect in the desired direction. A comment above claims that there is at least one comparable result of -0.33 (i.e. in the undesired direction.) That’s not good either.
There’s evidence for an effect in a certain direction. I think that properly evaluated, it is likely to be very weak evidence of a small or uncertain effect. A Bayesian should accept this of course!
But if I am tracking back correctly, your original claim was a doubt the evidence for an very clear claim of a “substantial” effect (indeed a chain of two substantial effects).
You should not hand your Bayesian card in just yet.
Work that is evidence for some effect > 0 might indeed be evidence against a “substantial” positive effect, for any given definition of substantial. E.g. the work might be entirely convincing that 0 < effect 0 without agreeing that there is thereby evidence that x is substantially positive. I can see how many formalizations of “evidence of P” could end up implying this implication, but surely that’s not these words work in the real world.
I think it’s useful to keep in mind a general analogy to the Efficient Markets Theory in finance economics. To the extent that subliminal signals can influence votes, it’s likely that both sides in elections figure that out and then their subliminal signals cancel each other out.
This is predicated on there being an underlying real effect – if so, why isn’t it so pervasive/useful/observed in the real world? If you buy the premise, then an interesting suggestion.
But IMO it’s even more useful to keep in mind a yet simpler hypothesis – that there really might be nothing of consequence (of course there’s _something_, there always is) there in the first place. There’s nothing to cancel out, nothing to explain, no just-so stories needed.
(Previous post garbled, used lessthan and greaterthan which caused a disaster). Rewriting the last paragraph…
Work that is evidence for some effect being great than 0 might be evidence against the effect being substantial. Suppose
we get a very reliable point estimate that 0 lessthan ” true effect” which is lessthan “threshold for substantiality”. It’s clear proof of greaterthan 0, but clear proof against substantiality.
But, even aside from the previous point, this is linguisticaly suspect. If I agree that there is evidence that some effect is greater-than 0, I’m just not automatically agreeing that there is evidence that the effect is substantially-greater-than 0. That’s not how our language works. I see how many formalizations of “evidence of P” could end up making this implication, but then we just need to main clarity of whether we are talking in English or “formal system X”.
” I just get confused whenever I see these path diagrams”
+1 Me too!
Pingback: Potpourri: Statistik #17 | Erik Gahner Larsen