Lee Wilkinson writes:
I thought you might be interested in this post.
I was asked about this by someone at Skytree and replied with this link to Tyler Vigen’s Spurious Correlations. What’s most interesting about Vigen’s site is not his video (he doesn’t go into the dangers of correlating time series, for example), but his examples themselves.
The GDELT project is a good case, I think, of how Big Data is wagging the analytic dog. The bigger the data, the more important the analysis. There seem to be at least a few at Google who have caught this disease.
The post Lee links to above is called “Towards Psychohistory: Uncovering the Patterns of World History with Google BigQuery” and is full of grand claims about using a database of news media stories “to search for the basic underlying patterns of global human society” and that “world history, at least the view of it we see through the news media, is highly cyclic and predictable.” Also some pretty graphs such as this one:
I responded to Lee:
Yes, I agree, the grand claims seem bogus to me. But it’s hard for me to judge because I’m not clear exactly what they’re plotting. Is it number of news articles each day including the word “protest” and the country name? Or all news articles featuring the country with a conflict theme?
In any case, perhaps the best analogy is to the excitement in previous eras regarding statistical regularity. A famous example is the number of suicides in a country each year. Typically these rates are stable, just showing some “statistical” variation. And this can seem a bit mysterious. Suicide is the ultimate individual decision yet the number from year to year shows a stunning regularity. Other examples would be the approximate normality of various distributions of measurements, and various appearances of Zipf’s law. In each case, the extreme claims regarding the distributions typically end up seeming pretty silly, but there is something there. In this case, the Google researchers are, as they say, learning something about statistical patterns of media coverage. And that’s fine. I wish they could do it without the hype—but perhaps the hype is the price that we must pay for the work to get done.
And Lee replied:
I’m not clear either regarding the dependent variable.
A few (sort of) random thoughts.
1) There’s little attention given to the number of considerable patterns in the second 60 day period. Not the number of *possible* patterns, because the dependent variable is presumably continuous or at least presents many possible values. I mean instead the number of patterns the researcher would have considered different from each other — a sort of JND measure of how they visually interpret the prediction. My guess is that there are not very many such patterns — in other words, they have a categorical prior over very few values. As evidence of this, they seem to be ignoring relatively small-scale variation in the first case and highlighting it in the second. Very subjective and post-hoc.
2) They appear to be willing to compare different series on different time scales in order to find similar patterns. This is reminiscent of dynamic time warping, which works OK for bird calls but is questionable for historical data. What are the limits of this flexibility in actual practice? One series covering only January and another covering the whole year that are deemed to be similar? I don’t see them explicitly ruling out such extreme comparisons.
3) Rather broadly, this appears to be similar to “charting” methods for picking stocks, which have been discredited for many years. Similar patterns don’t necessarily predict similar outcomes because context matters. Different exogenous variables can produce similar patterns for very different reasons. Put another way, one can find similar patterns in different time series that are based on fundamentally different processes, particularly on a small scale (60 days in this case?).
4) Searching that many correlations based on “p=.05” is arbitrary. I know they need a magic number to help filter, but why give it this appearance of legitimacy?
5) They say, “Whether these patterns capture the actual psychohistorical equations governing all of human life or, perhaps far more likely, a more precise mathematical definition of how journalism shapes our understanding of global events, they demonstrate the unprecedented power of the new generation of “big data” tools like Google BigQuery …” I have no idea what they mean here. Perhaps there is some dynamical system underlying these types of historical events, but until someone identifies plausible variables, I find the observation both breathless and uninteresting.
6) I’m all for BIG DATA. After all, I now work at a machine learning company. But statistics is about using methods that minimize the chance of our being fooled by randomness or bias. The methods used here, it seems to me, offer none of these protections.
I still have positive feelings about this effort because, even though the big claims have gotta be bogus, setting aside the hype, ya gotta start somewhere. On the other hand, one can be legitimately annoyed by the hype, in that, without the hype, we never would’ve heard about this in the first place.
The problem is going from observing empirical relationship -> grand claim. Everyone seems to skip the intermediate step: Come up with a theory that makes a prediction you can test. That prediction is then your “null hypothesis”, although even in this case I doubt the use of NHST, since if the theory is “close” it may mean there is something to it. The theory should be based on as few assumptions as possible and make precise numerical predictions about the value of some observable, or the existence or not of some phenomenon.
I don’t remember where I heard it, but there is a nice analogy of science as a stool with three legs. The legs are theory, observation, and experiment. If any leg is missing the stool won’t stand on it own. In this case it seems like a one-legged (observation only) stool.
Also, this is an odd thing to write:
“To test the hypothesis of whether looking to the past could offer predictions about the future today…”
https://blog.gdeltproject.org/towards-psychohistory-uncovering-the-patterns-of-world-history-with-google-bigquery/
To try to be constructive, there has been a lot of interest lately in using dynamical systems theory to detect phase transitions in natural systems. Monitoring malaria eradication is the application I’m most familiar with, but there seems to be a diffuse set of applications. The term I hear most often is “critical slowing down.” e.g.: https://daphnia.ecology.uga.edu/drakelab/reprints/2013%20Oregan%20early%20warning.pdf
Trying to detect civil unrest could plausibly benefit from a similar approach. I suppose from the GDELT perspective, the problem with that approach is that it requires a model of the system dynamics. From my perspective, the strength of the approach is the it requires a model of the system dynamics.
I would be surprised if there weren’t already boffins in a bunker someplace applying phase transition theory to detecting social transitions.
Also, these big data snowballs remind me of whole-genome association studies. The category of interest is very rare in the data, so most of the hits will be false positives. Using theory to narrow the search seems essential. Maybe we should be teaching everyone basic signal detection theory in high school?
Or maybe I’m just a bitter theorist being left behind by the big data express?
Awhile back I collected all the publications on my research topic (script to d/l abstracts from pubmed) and charted the publications per author. This appeared to follow zipf’s law with two “dragons” (author’s with especially high number of publications, higher than predicted by the law). Investigating this I found some papers about the distribution of bubble sizes that displayed a similar phenomenon. I never got around to finishing that analysis and have since forgotten the refs, but it was interesting to find similarities between bubble behaviour and human behaviour.
“Or maybe I’m just a bitter theorist being left behind by the big data express?”
I actually think you are being pretty generous. Maybe its there, but from this link there does not seem to be much insight about the generating mechanism for their data. This could be consequential — for example, maybe more news stories are written about a particular event if it is followed by a historically important event (e.g. coup, civil war, larger protests etc). Wouldn’t this systematically bias upwards their estimates of p(major future event | minor current event)?
Having said that, they seem to have ample room for cross-validation (big data right?). So how well is recent history (say post 2000) predicted by everything prior? How well is the history of country A predicted by the histories of Countries[-A]? Is this kind of confirmation relevant for systems dynamics / phase transition problems?
That 95% CI to weed out the ones that aren’t “statistically significant correlations” is too funny.
I’m going to use that next time my bank account is overdraft. I’ll just show my bank a time series graph of my account balance and 95% CI showing the recent drop isn’t “statistically significant”. Stupid Frequentists.
6) I’m all for BIG DATA. After all, I now work at a machine learning company. But statistics is about using methods that minimize the chance of our being fooled by randomness or bias. The methods used here, it seems to me, offer none of these protections.
If it is noise, in the long-run, the probability of a correct prediction will be no better than random. If it isn’t noise, then there will be a benefit. Try predicting stock prices with these methods and see if you make money.
I had a statistics friend who was working on a project in grad school. He would record his elevation continuously as he moved about the five story statistics building on campus. Over a period of months, his data showed his elevation as we went to class each day, or spoke to professors, went to bathroom or whatever. The data looked fairly chaotic to me.
One day he went to the fourth floor of the building and jumped out a window. Fortunately he survived the fall, but broke dozens of bones including his back. I visited him in hospital and asked why he did it. He showed me a graph of his elevation data with a calculation and said:
“a five story change in elevation was statistically significant, but a four story change is just random noise and wasn’t significant at the alpha=.05 level”.
Luca Pozzi at Skytree pointed out the following in an email to the machine learning group here. He said…
It’s actually even worse:
here https://nbviewer.ipython.org/github/fhoffa/notebooks/blob/master/GDELT%20correlations.ipynb
they claim a “remarkable similarity” between peaks on completely different scales
Hi Lee,
I’m the one that wrote that how-to do correlations with GDELT and BigQuery IPython notebook.
Thanks for the comment. I added a link to Andrew’s article (this one) and to one by Anthony A. Boyles.
I also added a comment to the specific statement you highlight: “(but not necessarily significant, more analysis is needed before reaching any conclusions)”.
Since you note that that this is being debated on a machine learning group, I’ll take this opportunity to plug another IPython Notebook that I co-wrote. In this one we use play-by-play soccer data to predict the world cup results: https://nbviewer.ipython.org/github/GoogleCloudPlatform/ipython-soccer-predictions/blob/master/predict/wc-final.ipynb
On that one we used correlation to weed out interesting features during the pre-analysis, then obtained results using logistic regression. At the end of the day we got 12 out 14 match predictions right.
On the GDELT side, note that the main article was published by Kalev H. Leetaru, a researcher at Georgetown, and not by Google Researchers. I wouldn’t qualify myself as researcher either, but someone happy to contribute tools and techniques to the larger community.
Hi Felipe!
Thank for your reply!
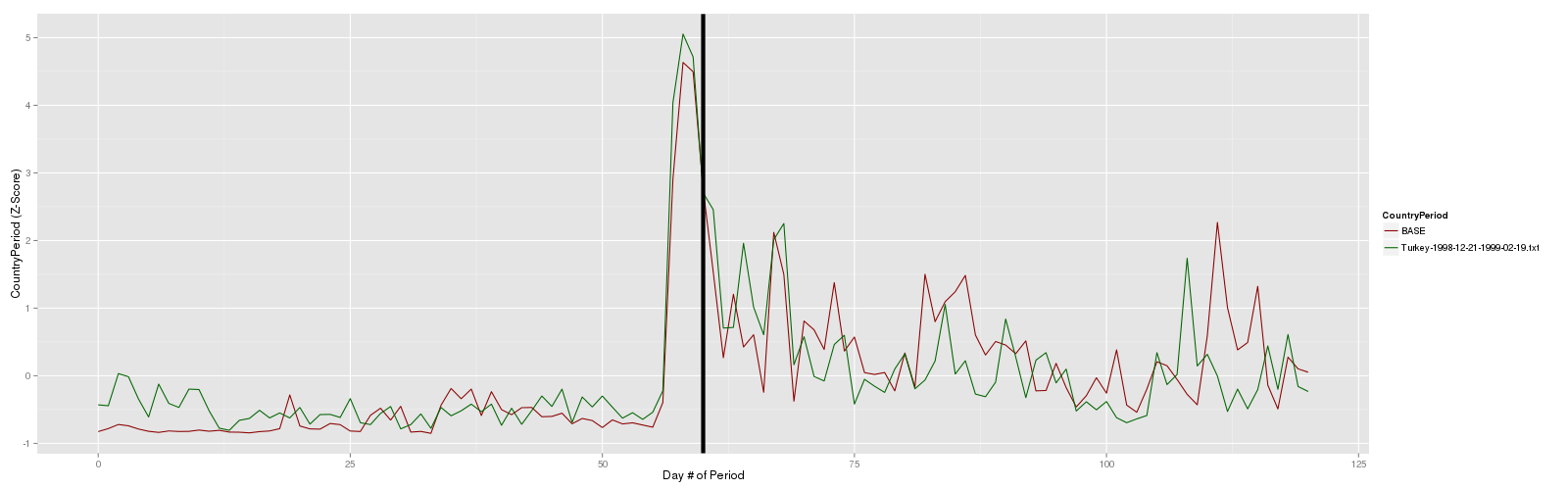
My concern about those peaks is not about their statistical significance but about their magnitude.
Showing graphs on a completely different scale might be very misleading.
For example you should notice that the peak on Jan. 11th 2011 in the Egypt data is higher (~5K) than the highest of the peaks in the Chad data. This is of course due to Pearson’s correlation being oblivious to scale.
Are we comparing noise with noise?
Regarding the soccer notebook, if I didn’t misinterpret it, what you are trying to do here is to predict single matches by using a logistic regression based classifier which completely ignores the time component. Oblivious to the correlation structure of the observations which are simply treated as iid. One of the effects of this assumptions is that it also ignores the correlation between the training set and the test set which are of course very strongly linked (hence the 12 out of 14).
I agree with the notebook though: we need a lot more power!
I am very excited about the potential for tools like GDELT and BigQuery, they are very promising and sharp, but like with all sorts of sharp tools extreme
caution is required.
The theoretical existence of predictable patterns has been most closely argued over in financial economics regarding stock prices. The Efficient Markets theory suggests that if you could tell that stocks were going up tomorrow, you’d buy today. But eventually, others would likely notice you getting rich and reverse engineer your insight, so stocks wouldn’t go up tomorrow, they’d go up today, so they’d eventually reflect all available information.