I’ve become increasingly convinced of the importance of treatment interactions—that is, models (or analyses) in which a treatment effect is measurably different for different units. Here’s a quick example (from my 1994 paper with Gary King):
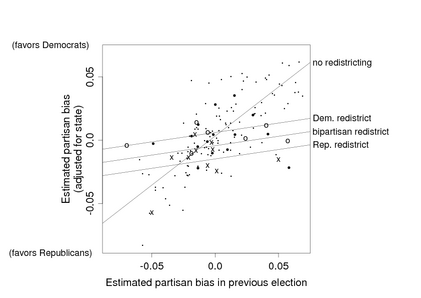
But there are lots more: see this talk.
Given all this, I was surprised to read Simon Jackman’s blog describing David Freedman’s talk at Stanford, where Freedman apparently said, “the default position should be to analyze experiments as experiments (i.e., simple comparison of means), rather than jamming in covariates and even worse, interactions between covariates and treatment status in regression type models.”
Well, I agree with the first part—comparison of means is the best way to start, and that simple comparison is a crucial part of any analysis—for observational or experimental data. (Even for observational studies that need lots of adjustment, it’s a good idea to compute the simple difference in averages, and then understand/explain how the adjustment changes things.) But why is is it “even worse” to look at treatment interactions??? On the contrary, treatment interactions are often the most important part of a study!
I’ve already given one example—the picture above, where the most important effect of redistricting is to pull the partisan bias toward zero. It’s not an additive effect at all. For another example that came up more recently, we found that the coefficient of income, in predicting vote, varies by state in interesting ways:
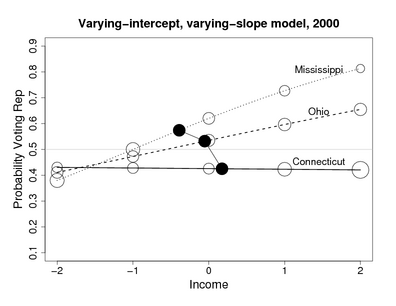
Now, I admit that these aren’t experiments: the redistricting example is an observational study, and the income-and-voting example is a descriptive regression. But given the power of interactions in understanding patterns in a nonexperimental context, I don’t see why anyone would want to abandon this tool when analyzing experiments. Simon refers to this as “fritzing around wtih covariate-asjustment via modeling” but in these examples, interactions are more important than the main effects.
Interactions are important
Dave Krantz has commented to me that it is standard in psychology research to be intersted in interactions, typically 3-way interactions actually. The point is that, in psychology, the main effects are obvious; it’s the interactions that tell you something.
To put it another way, the claim is that the simple difference in means is the best thing to do. This advice is appropriate for additive treatment effects. I’d rather not make the big fat assumption of additivity if I can avoid it; I’d rather look at interactions (to the extent possible given the data.)
Different perspectives yield different statistical recommendations
I followed the link at Simon’s blog and took a look at Freedman’s papers. They were thought-provoking and fun to read, and one thing I noticed (in comparison to my papers and books) was: no scatterplots, and no plots of interactions! I’m pretty sure that it would’ve been hard for me to have realized the importance of interactions without making lots of graphs (which I’ve always done, even way back before I knew about interactions). In both the examples shown above, I wasn’t looking for interactions—they were basically thrust upon me by the data. (Yes, I know that the Mississippi/Ohio/Connecticut plot doesn’t show raw data, but we looked at lots of raw data plots along the way to making this graph of the fitted model.) If I hadn’t actually looked at the data in these ways—if I had just looked at some regression coefficients or differences in means or algebraic expressions—I wouldn’t have thought of modeling the interactions, which turned out to be crucial in both examples.
I know that all my data analyses could use a bit of improvement (if only I had the time to do it!). A first step for me is to try to model data and underlying processes as well as I can, and to go beyond the idea that there’s a single “beta” or “treatment effect” that we’re trying to estimate.
I'm a fan of David Freedman's papers and books. In reading these, one gets the feeling that he's a purist, which I'm using as a neutral term.
I'm sure he would also have objections to your statement about discovering interactions by looking at the data. The main theorists for expt design always assert that we should never look for effects post-hoc; that the tests must be pre-ordained before the data is collected. Otherwise, there is the multiple comparisons problem. I wish there is some middle-of-the-road prescription between the extremes.
Speaking of which, can you recommend a book on observational studies that is application-oriented? I come from a classical stats background but would like to learn more about how social scientists think about these issues.
A wonderful example on how important is the attention do interaction (even when the effects are additive) is the Information Integration Theory of Norman Anderson. Allied to a strong theoretical reasoning, it explores all the advantages of factorial designs to understand some cognitive and/or percetual phenomena. By the way, a recent book by David Weiss ("Analysis of Variance and Functional Measuremente") highlights these points. On the status of statistical considerations for empirical data, I keep as a reference the perspective of Anderson, as exposed in "Empirical Direction in Design and Analysis" – the case being, statistical inference is regarded as some minor procedure once you can establish your research on a strong conceptual framework, phenomena, behaviour, measurement and design (on this same order).
I think Kaiser is right. Or, rather, I don't know what Freedman had in mind, but I agree with the view that Kaiser attributes to him. The key is to specify the effects that one is looking for ahead of time, and any experimental analysis should begin by examining these effects in the simplest possible way.
I don't object to then fishing around for indications of other treatment interactions. But this abandons the purity of the experiment, as there is no way to know what is the right critical value to use in tests without knowing how many tests are being performed. Despite this, hunting for unanticipated interactions can be extremely valuable. But it is valuable more because it gives you hypotheses to test in the next experiment than because it provides anything like the evidentiary weight that an experimental test of the intended hypothesis does.
Kaiser,
I agree with your implicit point that one's opinion about inferential strategies will depend on the problems being considered. I've never designed a clinical trial of a medical procedure, but I can imagine that such a study might be designed with a specific analysis in mind, with the goal of estimating an estimate of average treatment effect.
Contrariwise, in many applications in social sciences (such as I've been involved in), interactions are there, and interactions are important. It would be silly for me to ignore interactions, just because somebody I've never met is doing "data snooping" in a medical trial somewhere!
Since Simon Jackman does research in political science, I was surprise to see his apparent acceptance of the "don't look for interactions" advice.
Jesse,
I agree that it's a good idea to begin with the simplest possible analysis. But, as the two graphs above illustrate, I don't want to stop there. Often the assumption of constant treatment effects is naive, and often (as in these examples) the data are there to refute it. I prefer the spirit of Tukey's exploratory data analysis: I come to the data to learn new things, not just to confirm or refute or a single hypothesis. (But, once again, this depends on the problem-context; I could see that one might want to proceed differently when analyzing an experiment evaluating a new medical treatment.)
P.S. to Kaiser: My favorite book on applied observational studies is our forthcoming book on data analysis using regression and multilevel/hierarchical models. The book is not just about observational studies, but it does include three chapters on causal inference. Also, Don Rubin just came out with a collection of some of his articles on causal inference and observational studies. His work is very applied so it might be a useful read.
Interesting post.
I will say that interactions are essential for theory testing. Simple means testing is necessary but insufficient for a theory test. without interactions we can have NO theory testing.
It is through the interactions that we learn a cause and effect. A simple means test does not narrow the range of explanation. An interaction allows us to "manage" the effect.
Andrew,
Absolutely we want to use the data to "learn new things," and of course we should look for evidence of interactions. But I tend to exalt experimental evidence over non-experimental, thinking that the former is much more reliable. (I say this as someone who has written only non-experimental papers.) And I view Tukey-style exploratory data analysis as much more like non-experimental evidence than like experimental evidence, even if the data used originally came from an experiment. Otherwise, what does one do about the multiple comparisons problem? While you shouldn't "ignore interactions, just because somebody I've never met is doing 'data snooping' in a medical trial somewhere," neither can you ignore multiple comparison problems, just because you are confident that you yourself are not data mining.
Jesse,
Thanks for the comments. I agree with the idea of the randomized experiment as gold standard, and in my observational studies, I have worked hard to think clearly about implied treatments and potential outcomes. And "data snooping" issues are relevant whether in an experimental or an observational context.
But I don't see how either of these points should lead to the claim that it's bad to look for interactions, or that a difference in means is any kind of preferred analysis. What would that have done to me in my examples above? So . . . Yes on randomized experiments, No on assuming additivity.
P.S. Regarding multiple comparisons, many of the issues that arise there can be resolved using hierarchical modeling. The short version of this is that "multiple comparisons" = "many analyses in parallel" = a natural opprtunity for hierarchical modeling or meta-analysis. Basically, the shrinkage that is done by hierarchical Bayesian inference automatically reduces the "false positives" problem inherent in multiple classical inferences. See here for details.
Lest I be misunderstood: I have no problem with interactions per se in the analysis of experiments, just with "searches" for them that aren't particularly well motivated by theory. Just in the last month or two I published a study in the Journal of Politics with Paul Sniderman where we interacted our treatment with linear *and* quadratic terms in political sophistication (an important moderator of effects in political science, if ever there was one, plenty of theory/previous work to believe that responses to political stimuli are conditioned on a subject's level of political sophistication etc). So, (1) I'm not opposed to interactions as a general matter; but (2) I do have problems with ransacking data sets looking for a corner of the data set where the treated differ from control (i.e., the researcher *knows* the treatment "works", but couldn't specify where in the data it works a priori, or why; otherwise the experiment might have been designed that way from the get go…?).
And of course, since I am card-carrying Bayesian, I totally agree that when you've got good reasons to believe treatments effects vary over the treated, and how/why this happens, hierachical Bayesian modeling is a great way to go.
As I see it, there are two ways that variation within treatment is interesting: (1) reinforcing the difference in the average treatment effect and (2) exporing causal mechanisms.
Consider a hypothetical randomized experiment that shows higher voter turnout among those who were provided subtantive election guides. Treatment interactions may show that electoral competition and substantative differences between the candidates increases the treatment effect among the treated.
On the one hand, these interactions provide weak evidence that competition and candidate differences promote turnout. We cannot easily reject reverse causality or a spurious relationship. Too bad we can't manipulate these factors easily to find out the truth. On the other hand, these interactions provide reinforcing evidence that the provision of election information promotes turnout, because these interactions support plausible causal mechanisms. All of the treated subjects find out what's at stake, and then the ones with the most at stake then go vote!
So, treatment interactions are important nuance – let's not through away the baby with the bathwater! The problem with randomized experiments is construct validity, and treatment interactions can shed light on the generalizeability of treatment constructs.
if you want more examples, i found a strong age*treatment interaction in the national supported work experiment (asr 2000). assigning jobs to young criminals did not dent recidivism, while assigning jobs to older criminals significantly reduced recidivism. the interaction is clear in the survival plots of time to recidivism by treatment status — no effect for those 26 and under, big effect for those over 26 (p. 536).