A Bayesian prior characterizes our beliefs about different hypotheses (parameter values) before seeing the data. While some (subjectivists) attempt to elicit informative priors systematically – anticipating certain hypotheses and excluding others – others (objectivists) prefer noninformative priors with desirable properties, letting the data “decide”. Yet, one can actually use the data to come up with an informative prior in an objective way.
Let us assume the problem of modeling the distribution of natural numbers. We do not know the range of natural numbers a priori. What would be a good prior? A uniform prior would be both improper (non-normalized), but also inappropriate: not all natural numbers are equally prevalent. A reasonable prior would be an aggregate of natural number distributions across a large number of datasets.
Dorogovtsev, Mendes and Oliveira have used Google for assessing the Frequency of occurrence of numbers in the World Wide Web. While they were not concerned about priors, their resulting distribution is actually a good general prior for natural numbers. Of course, it would help knowing if the natural numbers are years or something else, but other than that, the general (power law) distribution of p(n) ~ 1/sqrt(n) is both supported by data and mathematically elegant:
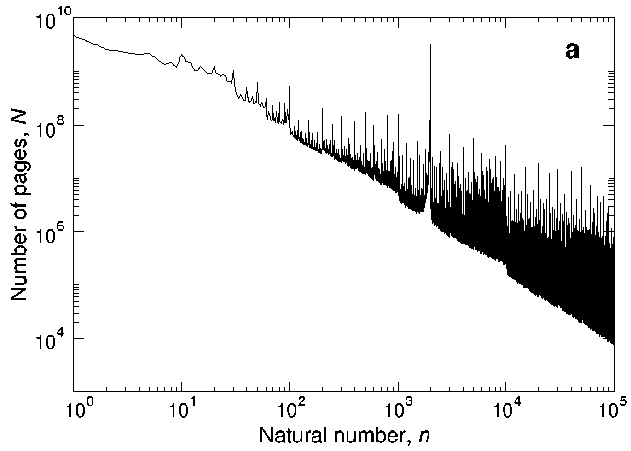
In this context it is worth mentioning also Benford’s law, which elaborates on an observation that the leading digits are not equally likely. Instead, 1 is considerably more likely than 9.