Two weeks ago we modeled vote choice with candidates C = {Left, Right, Other} as a multinomial logit:
P[voter i chooses candidate c from C] = exp(f(X_ic)) / sum_c’ exp(f(X_ic’))
We saw this model implies independence from irrelevant alternatives (IIA):
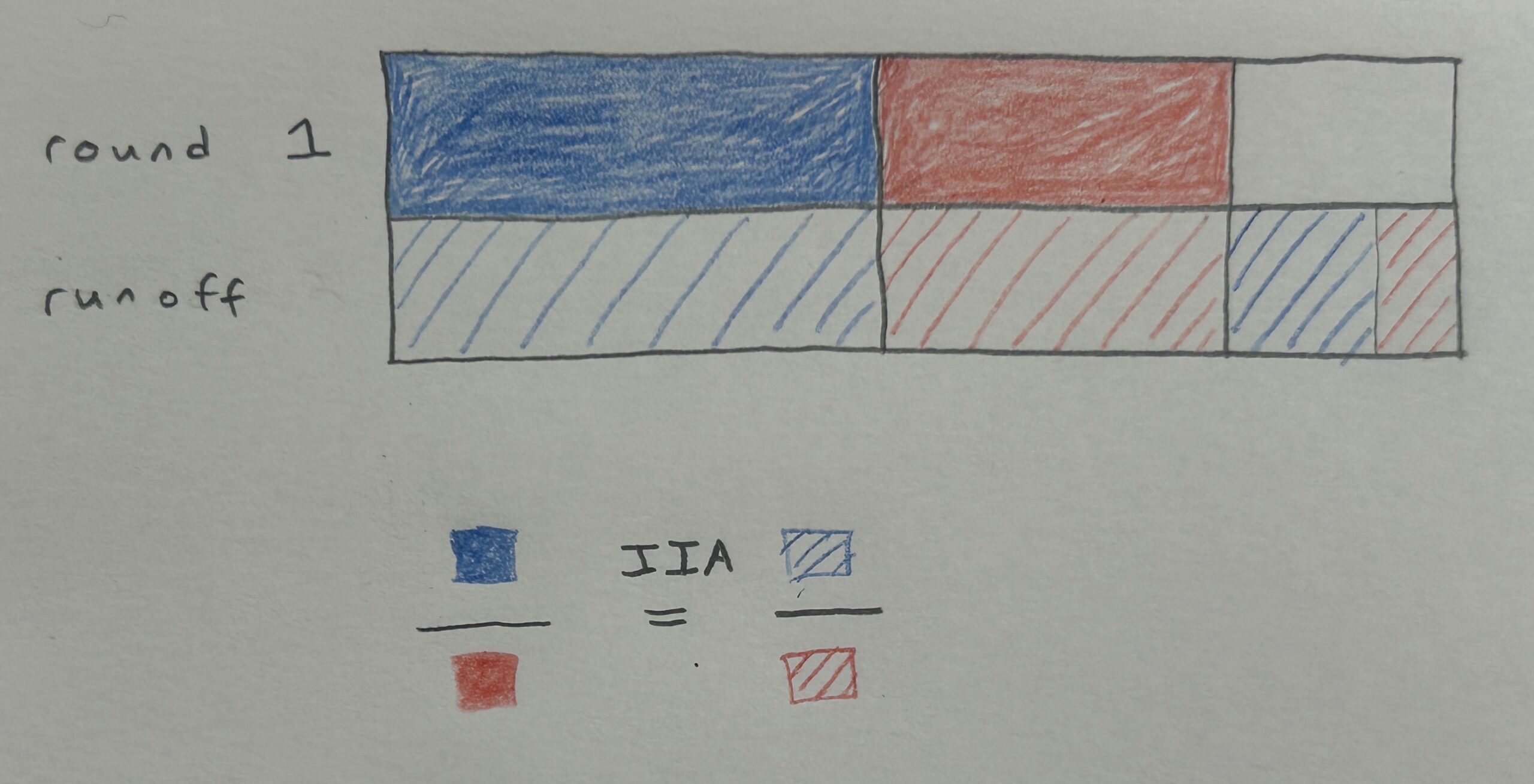
Another consequence of the multinomial logit model is a simple expression for ranked data:
P[i ranks Other then Left then Right] = exp(f(X_iOther)) / sum_c’ exp(f(X_ic’)) * exp(f(X_iLeft)) / (exp(f(X_iLeft)) + exp(f(X_iRight)))
Train (2009) Chapter 7 calls this an exploded logit.

To derive the exploded logit:
- Train (2009) Chapter 3 explains that the multinomial logit model is equivalent to latent utilities with a Gumbel distribution.
- Powell (2023)* notes “The exponentials of the negated Gumbel random variables are Exponential random variables” and uses the memoryless property of the Exponential to derive the exploded logit.
The exploded logit form implies that the ranking of 3 alternatives can be expressed as 2 pseudo-observations: 1) choosing Other from C, 2) choosing Left from {Left, Right}.

* I got Powell (2023) from White Rose Research, not to be confused with Blue Rose Research, where I work. The paper’s subtitle “why endurance is better than speed” caught my eye. They study competitions like Backyard Ultras, where the goal is to outlast your competition.

Who is Shira?
Here’s Shira.
Thanks, Andrew ! Hi Anonymous !
Michael Betancourt just released a massive discrete choice modeling chapter on his Patreon. I think it’ll be paywalled for a while but worth a read if you’re willing to subscribe! https://www.patreon.com/posts/new-discrete-154918610
Oh thank you for the reminder to take a look, Zach ! I’m already a long-time subscriber to Michael’s patreon materials.
Shira:
I’ve used and recommended these sorts of models for a long time. I’ve never heard it called an “exploded” model. It’s not a bad term. “Hierarchical” or “nested” or “tree” models would also make sense, but they could be confused with existing models with those names.
Cool ! Can you link to places you’ve recommended these ? Thank you, Andrew !
We discuss the idea in chapter 15 of Regression and Other Stories:
Page 277:
Page 278:
There’s a lot of good stuff in Regression or Other Stories!