Class-participation activities are useful in many settings, but especially so at the beginning of the semester, where they can help build community and set up a norm of active student involvement. Here we describe an statistics-based activity that has the additional benefit of allowing students get to know each other on a social level.
This activity can be performed during the first week of class or later on during the semester if that seems to better fit with the sequence of topics in the course.
We start the activity by dividing students into groups of four—it’s fine if some groups have three or five students in them—to play “two truths and a lie.”

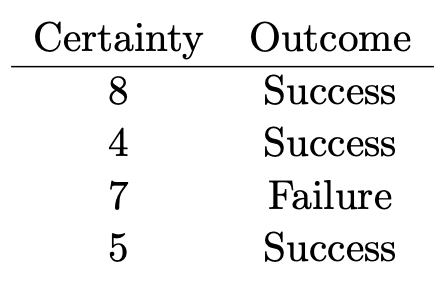
We display the above instructions onto the screen and explain the procedure. In this game, one person makes three statements about him or herself; two of these statements should be true and one should be false. The other students in the group should then briefly confer and together guess which statement is the lie. They should jointly construct a numerical statement of their certainty about their guess, on a 0-10 scale, where 0 represents pure guessing and 10 corresponds to complete certainty. The true statement is then revealed so that the students know if they guessed correctly. Each group of students then rotates through, with each student playing the role of storyteller, so that when the activity is over, each group of four students has produced four certainty numbers, each corresponding to a success or failure. Here is an example of data that could be produced by a group of 4 students:
We then give students the url of a Google form where they can enter their data using their phone or laptop. The form is set up to take one response at a time, so each group should enter four responses corresponding to their four guesses:
We download the data from the Google form as a csv file, read it into our statistical software, and announce that we will display the data (a scatterplot of the success/failure outcome vs. certainty score) along with a fitted curve showing probability of the guess being correct as a function of certainty score. If the class is sufficiently advanced, we explain that the fitted curve will be a logistic regression; otherwise we simply say we will fit a curve.
Before making the plot and displaying the data and fit, we we ask students in their groups to sketch what they think the scatterplot and fitted curve for the class will look like, and then we lead the class in discussion. Some possible prompts include: What do you think the range of certainty scores will look like: will there be any 0’s or 10’s? Will there be a positive relation between x and y: are guesses with higher certainty be more accurate, on average? How strong will the relation be between x and y: what will the curve look like? If students have seen logistic regression, we ask them to give approximate numerical values for the intercept and slope coefficients corresponding to their sketched curves.
After this discussion, we display the data and fitted curve:
logit <- qlogis
invlogit <- plogis
responses <- read.csv("Two truths and a lie.csv")
n <- nrow(responses)
x <- responses[,2]
y <- ifelse(responses[,3]=="Guessed right", 1, 0)
class <- data.frame(x, y)
library("rstanarm")
fit <- stan_glm(y ~ x, family=binomial(link="logit"), data=class, refresh=0)
print(fit)
a_hat <- coef(fit)[1]
b_hat <- coef(fit)[2]
x_jitt <- runif(n, -0.3, 0.3)
plot(class$x + x_jitt, class$y, xlab="Certainty score", ylab="Outcome")
curve(invlogit(a_hat + b_hat*x), col="red", add=TRUE)
We then conduct a follow-up discussion of what has been learned. Here is an example of a scatterplot and fitted logistic regression fit to real data collected from an applied regression class:

In this case, there is essentially no relation between the certainty score and the outcome (coded as 1 for a successful guess and 0 for an error). In fact, the estimated logistic regression coefficient is negative: higher certainty scores correspond to slightly lower rates of accuracy! It’s hard to see this in the plot of raw responses; in general, scatterplots are not so helpful for displaying discrete data. The standard error from the regression gives a sense of the uncertainty in the fit; in this case, the estimated slope of -0.08 with standard error 0.15 indicates that the sign of the underlying relationship is unclear from the data.
In the discussion that followed in our class, students conjectured why their guesses were so bad (23 our 49 correct, not much better than the 1/3 success rate that would come from random guessing) and why their certainty judgments were not predictive of their accuracy. In many ways, the class discussion before seeing the data was better than the post-data followup, which illustrates a general point that concepts can sometimes be clearer in theory, with real data providing a useful check on speculation.
For any particular class, the interpretation of the “two truths and a lie” experiment will depend on the data that come in, and you should be prepared for anything. In the class discussion before the scatterplot and fitted model are revealed, it is natural for students to expect the certainty score to be a strong predictor of empirical accuracy. If this occurs, great; if not, this is an excellent opportunity to discuss the challenges of measurement and the value of statistical evaluation of a measurement protocol.
The “Two truths and a lie” game should be fun for any group of students, but the relevant statistical lesson will depend on the level of the course being taught. This activity connects to several important topics, including measurement, uncertainty, prediction, calibration, and logistic regression. Whatever topic is covered, it is important to explicitly connect it to the material being covered that week, as well as to the course as whole.
In our recently-published article, we discuss the following options:
- Introductory statistics: the focus can be on probability and uncertainty
- Bayesian statistics, the activity can be used to demonstrate the principle of calibration
- For a class on generalized linear models or machine learning, you can use this as an introduction to logistic regression
- For a class on psychometrics or multilevel modeling, you can turn this into a lesson on reliability and validity of measurement.
Finally, a key part of any class-participation activity is how things go after the data have been collected and analyzed.
We do not want to just dump the data and analysis onto the screen and stop there. It is fun when an activity has a twist, but it is not a magic trick; the point is not to amaze students but to bring them closer to the material being taught. We want the activity not to mystify but to de-mystify. So it is important to follow up the activity with explicit discussion, both of its connection to the material being taught in the class and its relevance to real-world applications of statistics in areas such as education, business, politics, or health, depending on the interests of the students.
We can also consider what lessons students might take away from this activity. “Statistics is fun”: that’s a good memory. “I got fooled by Jason’s lie: he’s not really adopted”: that’s fine too, as it serves the goal of students getting to know each other. “You can use logistic regression to convert a certainty score into a predicted probability”: that’s good because it’s a vivification of a general mathematical lesson. “The estimated slope was smaller than the standard error so we couldn’t distinguish it from zero”: that’s not a bad lesson either. Think about what memories you want to create, and keep the discussion focused.
In our experience we have seen three sorts of positive outcomes associated with this sort of activity, especially when performed near the beginning of the semester. The first is that students get used to the idea that attendance is active, not passive, and we hope the alertness required to perform these activities translates into better participation throughout the class period. The second is that people typically find data more interesting and relatable when they can see themselves in the scatterplot. The third valuable outcome is that the “Two truths and a lie” activity is a social icebreaker. That said, we do not have direct empirical evidence of the effectiveness of this activity on student learning. It is our hope that in laying out this activity---not just the general concepts but also the details of implementation, including instructions, Google form, sample data and analysis, and post-analysis discussion points---we have lowered the barrier of difficulty so that instructors in a wide range of statistics courses can try it out in their own classes, at minimal cost in classroom time and with the potential to get students more involved in their learning of statistics.
That said, we have not offered any formal evaluation of this activity. As is typically the case in education, it is easier to develop a new idea than it is to quantitatively evaluate its effects in the classroom. We can still learn from experience, but such learning tends to be qualitative, from observing student reactions and discussions. The biggest risk or opportunity cost we see in introducing a new class-participation activity is that time spent in the activity could be spent working on lecturing or problem solving. For this reason, it is important that the activity be closely tied to the course material (as discussed in Section 3 of our article) and that it be performed efficiently, with instructions and Google form prepared ahead of time and with code all set up to analyze the data when they come in. You can also use this as a template for designing and implementing your own class-participation activities.
Reminds me of specific problems with asking people to self-report confidence in general (eg the “hard easy effect” where people are apparently more overconfident on harder questions https://link.springer.com/content/pdf/10.3758/PBR.16.1.204).
Jessica:
D’oh! I should’ve cited some of this literature in my article.
I like this activity a lot! Great idea.
I could also see this used in an intro to AI course. At some point you usually talk about things like expert systems or approaches based on the idea that we can just ask a human to write down rules for how they solve a problem. Even if the students do well, an additional step of asking them to write down rules for generating a confidence score would demonstrate how difficult and fraught with error such a process is. There could also be another step of treating the rules as features and repeating the analysis or training an ML approach. It might be better than the textbook examples of medical diagnoses from symptoms.
This is a great activity. One extension that comes to mind is linking it, probably after, to a quick survey of literature on the general topic of how well (and how) people infer honesty/dishonesty. The idea that data analysis should be embedded in contextual knowledge is worth pushing.
Also, one other dimension that might be revealed in a discussion of results is the generic treatment of “statements”. There are different types of statements people might make about themselves, and it’s possible that students might be better at evaluating some than others. That could point to potential follow-up studies, and it also introduces the difficult problem of levels of specificity in study design. (I’ve had to wrestle with that one a lot.)
Awesome activity, thanks for sharing!
I tend to build toward factorial experiments rather than regression in my intro course, but it would be easy to change the predictor from metric to categorical. You can just have low vs. high confidence categories. Or groups could make separate lie vs. truth judgments for each statement, so you would have a contingency table of truth/lie vs. judgment. I guess that’s another plus to this activity, it can be easily adapted to emphasize different concepts.
A more intuitive graph would be to bin the certainty scores and then plot these against the proportion of outcomes that were correct for that certainty score bin.
I’m not so sure about it being “more intuitive” but it introduces potential discussion about binning. Sometimes bins make sense – but they should be data driven. The certainty scores people give may or may not lead to natural bins, and if they don’t, then binning is not appropriate. I tend to think of binning as usually doing more damage than good.
My recommendation is not to bin for the analysis, only to do so for the sake of the graph, to give a sense of how noisy the data are around the fitted line.
Johnny:
Good point. The certainty scores are actually already binned—they’re discrete responses from 0 to 10, so only 11 possible responses. If you do this for a large enough class, the graph of proportion correct for each certainty score should be informative.
Re: On your graph, the certainty scores do not look binned. Perhaps I should say it would be worthwhile to bin the “average certainty score”?
Johnny:
OK, the certainty scores in the data are not literally “binned”; they’re simply integers. There are no average certainty scores, only certainty scores. They take on at most 11 discrete values. In this case there were no 0’s, 9’s, or 10’s, so they only took on 8 discrete values. I couldn’t do a straight scatter plot or the points would fall on top of each other, so I jittered them (see R code in the post). I agree that, rather than plotting the points, it would be better to just plot proportion correct for each certainty score. I didn’t do that, just because in class we’re always doing scatterplots so it seemed simpler to do that than to design a custom plot for this case. But, given the trouble I’m having explaining this, maybe I should have just started with the plot of proportion correct vs. certainty score and never done the scatterplot at all!
Extremely valuable followup lesson: ask students to come up with the “best” way of displaying the results of the exercise.
yeah, my first thought would have been to do a stacked barplot showing the proportion of “hits” and “misses” in data like this, e.g. something like the left panel here: https://i.imgur.com/RB0jVl9.png
or you can tease apart the two blocks and go back to the count scale to get something like the right panel
(data generated by sampling 15^2 numbers from a discrete uniform in {0,1,…,9,10}, and then treating them like probabilities for a Bernoulli draw. Come to think — we don’t see an ‘0’s or ’10’s in OP’s scatterplot, so I wonder if the students just treated them as probabilities? i.e. number / 10 is the probability of a statement being a lie? I guess one check could be, since they know a priori that there are two truths and a lie: do their numbers for all three statements sum to 10, in accordance w/ the law of total probability?)
(would also second other suggestions to try & incorporate multilevel effects on that slope in later lessons… would be neat to tease out who in the group is a good liar and who in the group is a good lie detector. Maybe the former are screwing up the overall trend!)
Andrew, I’m sure you considered having the team assign a probability rather than a 0-1 scale. At the high end these are the same — certainty = 10 presumably maps to probability = 1, or at least probability > 0.95. But at the low end, certainty = 0 maps to probability = 1/3. If I think there’s about a 50% chance that I’ve identified the lie, what certainty would I assign? I’d have to do the calculation, assuming, I suppose, that the scale is linear. (I could imagine preferring a nonlinear scale but that’s a different issue).
Hmm, this reminds me that I’ve read that Back In The Day before heart rate monitors were cheap and convenient, some pro cyclists used to keep records in which they rated their perceived effort on a scale from 6 to 20; supposedly you could multiply by 10 and get a good estimate of their heart rate. You could have the students put their certainty on a scale from 3 to 10, maybe that would map to probability.
But perhaps there are good reasons for NOT asking for probability.
And anyway I realize that if the students aren’t actually more likely to be right when they’re more certain, that’s really the point, and not the exact numbers. I like the exercise. Just wondering about the choice of scale.
Phil:
I used for a 0-10 “certainty score” in part because I didn’t want to increase complexity to the task by asking the participants to assess their probabilities. It also has to do with how to spin the results: instead of, Hey, fools, your probability judgments are miscalibrated!, it’s Hey, look, we can use statistics to turn your certainty scores into probabilities.
This is such a neat idea! It would be more time-consuming, by N/4, but it could be neat to try (entire class – student) to predict for student, for all students. I guess you’d get the same average effect of certainty vs outcome across all students, but I’d imagine things could look different on a per-student basis. This is because some students are probably bad liars or gave a “lie” scenario that was an obvious lie. It could be neat to tease out which students gave better or worse lies in the game.
I think you could also do the Monty Hall problem.
Ed:
There are a million things you can do in class. Deb Nolan and I wrote a whole book, “Teaching Statistics: A Bag of Tricks.”
Maybe I should’ve added more detail about what I meant: with two truths/one lie, students do an initial guess, then the storyteller eliminates one of the two truths, then the students have to decide whether to switch from their initial guess about what was a lie. Maybe the problem makes more sense in this context, as compared to goats on a game show.
One of the disappointments with the Monte Hall problem is that if the choice between which of two doors to open when both have goats is informative, but not in a way that effects the winning strategy. To me the real lesson should be to discern if a choice could be informative one needs to check check if it changes the probabilities. Often that is not explicitly stated but just implicitly assumed.
Is “I always lie” a true or false statement?
I think what needs to be taught is reasoning in a world where ~80% of claims are false. Whether it is a lie/fraud, mistake, only true for some very limited circumstances, or whatever does not really matter.
Student engagement is indeed key to statistics education pedagogy. Another “trick” is to involve students in designing, running and analyzing experiments. Some if ideas for it are listed in https://www.tandfonline.com/doi/abs/10.1080/02664768700000027
The disappointing is realizing that two unrelated experiments ended up with identical outcomes. This means that two groups had the exact same estimates of model parameters, even though they did two totally different experiments. Another option of course is to raise the option that someone copied the analysis… We describe this experience in the paper listed above.