Shinyoung Kim, Angie Hyunji Moon, Martin Modrák, and Teemu Säilynoja prepared this R package for simulation-based calibration (SBC)! They write:
SBC provides tools to validate your Bayesian model and/or a sampling algorithm via the self-recovering property of Bayesian models. This package lets you run SBC easily and perform postprocessing and visualisations of the results to assess computational faithfulness. . . .
To use SBC, you need a piece of code that generates simulated data that should match your model (a generator) and a statistical model + algorithm + algorithm parameters that can fit the model to data (a backend). SBC then lets you discover when the backend and generator don’t encode the same data generating process (up to certain limitations).
For a quick example, we’ll use a simple generator producing normally-distributed data (basically y <- rnorm(N, mu, sigma)) with a backend in Stan that mismatches the generator by wrongly assuming Stan parametrizes the normal distribution via variance (i.e. it has y ~ normal(mu, sigma ^ 2)).
I decided to try it out. The first step was to open R and install the devtools package. From there I copied the code from the above-linked webpage, just using cmdstanr instead of rstan:
devtools::install_github("hyunjimoon/SBC")
library(SBC)
gen <- SBC_example_generator("normal")
backend_var <- SBC_example_backend("normal_var", interface = "cmdstanr")
SBC_print_example_model("normal_var")
ds <- generate_datasets(gen, n_sims = 50)
results_var <- compute_SBC(ds, backend_var)
It gives some output:

I then continue with the code from the instructions page:
plot_rank_hist(results_var) plot_ecdf_diff(results_var)
Which gives these two pairs of plots:
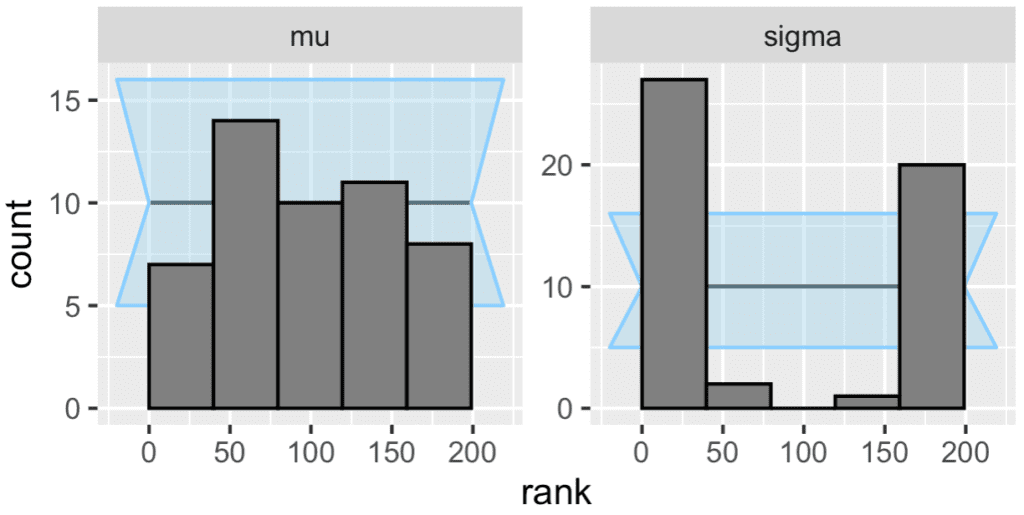
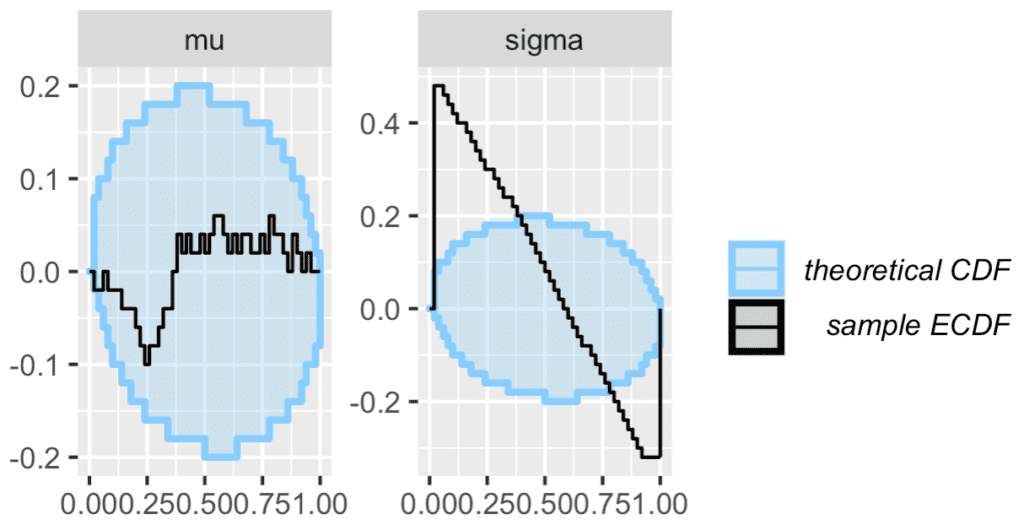
I then continued by running SBC with their backend that uses the correct parametrization (i.e. with y ~ normal(mu, sigma)):
backend_sd <- SBC_example_backend("normal_sd", interface = "cmdstanr")
results_sd <- compute_SBC(ds, backend_sd)
And this is what comes out. The result is not completely clear:

So let's do the graphs:
plot_rank_hist(results_sd) plot_ecdf_diff(results_sd)
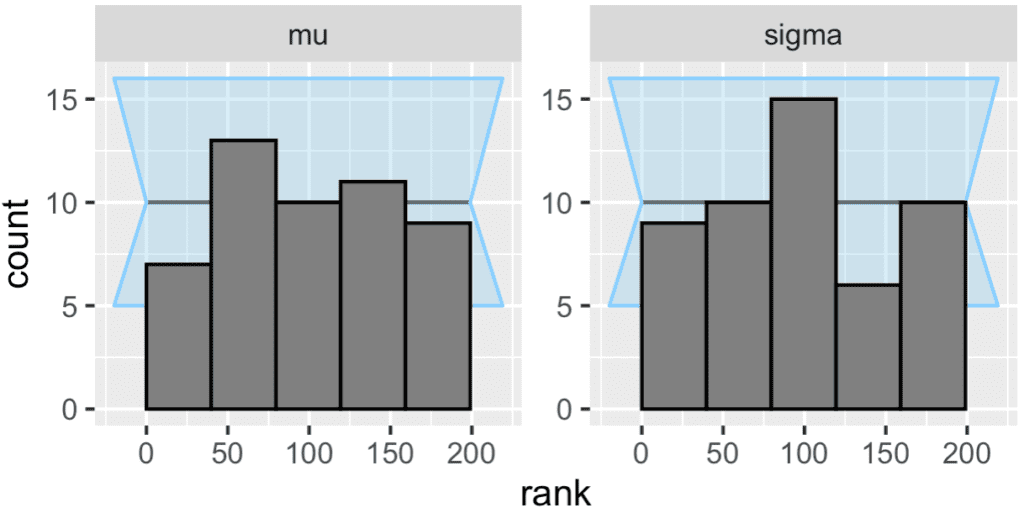
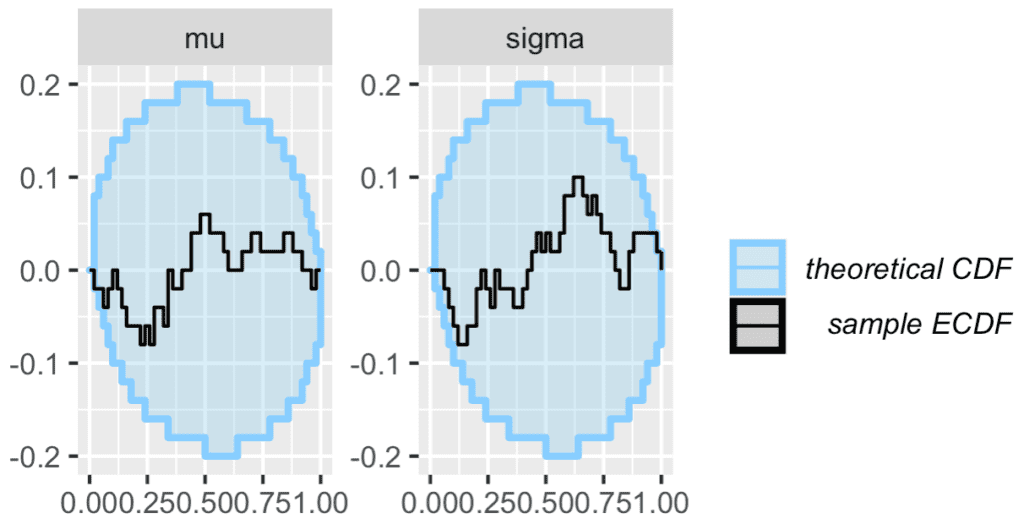
Kim et al. write:
The diagnostic plots show no problems in this case. As with any other software test, we can observe clear failures, but absence of failures does not imply correctness. We can however make the SBC check more thorough by using a lot of simulations and including suitable generated quantities to guard against known limitations of vanilla SBC.
More information is in the vignettes for the package. Martin also posted this description in the Stan forums. He describes it as "the closest we have to unit tests for statistical models."
And, as usual, everything is free and transparent so this code should be easily adaptable to other probabilistic programming languages.
This is great, and we've really gone far since Samantha Cook first had this idea as part of her Ph.D. thesis, which back in 2006 became this article and this R package.
I'm just kinda bothered that it spits out a warning even for the model that works fine. I wonder if they could fix that?
The warnings are unfortunately a result of the difficulties in parsing cmdstanr’s console output at this moment (using rstan won’t have this problem). They correspond to messages like:
The current Metropolis proposal is about to be rejected because of the following issue: normal_lpdf: Scale parameter is 0, but must be positive!
If this warning occurs sporadically, such as for highly consatrained variable types like covariance matrices, then the sampler is fine, but if this warning occurs often then your model may be either severely ill-conditioned or misspecified.
Which happen occasionaly during warmup. As the message says, the number of rejections matters, so we display it. We erred on the side of reporting more stuff to the user as sometimes those messages should not be ignored (although they mostly can). Best solution would be to separately track rejections during warmup and rejections during sampling, but with cmdstanr, it is hard to distinguish those programatically (not completely impossible, just very tricky to implement, because progress of iterations is sent to a diffferent output stream than the rejection messages). More generally both rstan and cdmstanr don’t have their console output developed with eyes towards consumption by a program, so automatically parsing the output to produce meaningful summaries for the user is hard…
Impressive! I can’t wait to try this out. Although I’ve known about SBC for some time, so far I’ve only been doing calibration somewhat heuristically.
> the closest we have to unit tests for statistical models.
Isn’t SBC more like property-based testing? Basically, you generate random inputs, push them through some function and check that the output has some property, i.e. some desired mean or distribution in this case.
The little blue circles are quite pleasant to look at. It would be nice if they said diff in the legend to indicate that these are not CDFs but some sort of finite differences of them.