This came up in our discussion the other day:
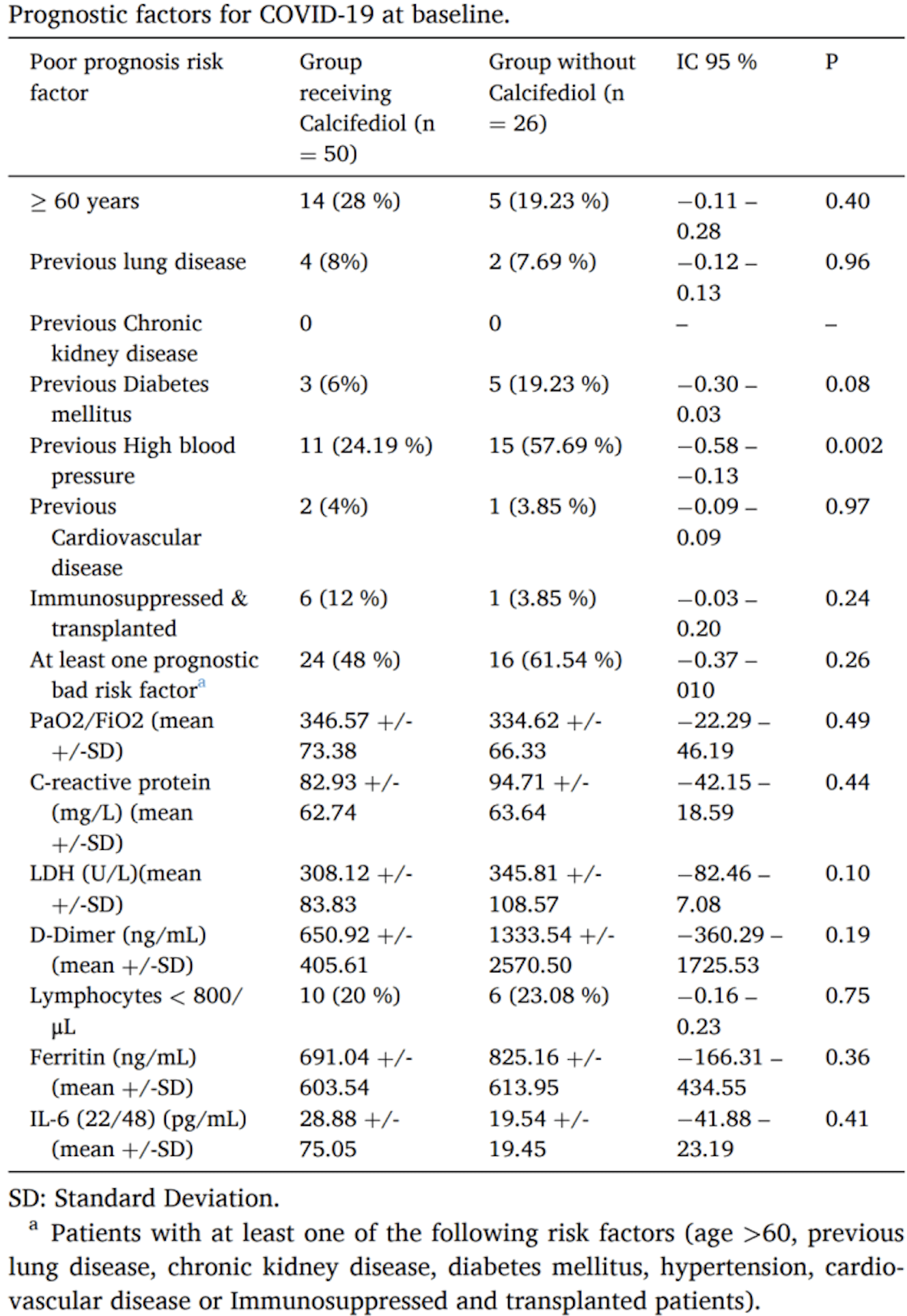
It’s a table comparing averages for treatment and control groups in an experiment. There’s one big problem here (summarizing differences by p-values) and some little problems, such as reporting values to ridiculous precision (who cares if something has an average of “346.57” when its standard deviation is 73?) and an error (24.19% where it should be 22%).
There’s one other thing about the table that bothers me. It’s not a problem in the table itself; rather, it’s something that the table reveals about the data analysis.
Do you see it?
Answer is in the comments.
Here’s the answer. Or, at least my answer. I can’t be sure.
They categorize age as over or under 60. But it’s my impression that with coronavirus there are big differences in outcomes among the over-60-year-olds. So I think it would be better for them to simply use linear age. Or they could have three categories: under 60, 60-75, and 75+.
The way age is used when reporting covid, can be very misleading, albeit true. It’s really only 75+ and 85+ where most hospitalizations and deaths happen.
If you take a look at this CDC interactive graph for US hospitalization (select weekly, not cumulative),notice what happens to y-axis as you alternate b/w higher and lower age groups:
https://gis.cdc.gov/grasp/covidnet/COVID19_3.html
So, although a claim that most fatalities are in those 60 and over (I’ve heard 55 and 65 being reported too) is true, it is really misleading.
If you look at fraction of deaths vs fraction of population, over 60 is overrepresented, whereas under 60 is underrepresented. The LATimes graphs show this nicely (about halfway down this page): https://www.latimes.com/projects/california-coronavirus-cases-tracking-outbreak/
Agree. As long as the age is over 18 (really over 5) increasing age = increasing mortality in the population. Infection risk is higher in people in that under 60 category so using a continuous relationship or a finer break down would be important. That figure Navigator mentioned is quite striking. Their break down of mortality in 55-64, 65-74, 75-84, 85+, each group accounts for almost twice as much mortality as the younger group.
The thing that is left off here and is very important (especially in people under 60) is obesity. My husband (the oft referred to Infectious Disease doctor who saw his first covid patients in early March), noticed by April that the likelihood that you would die or spend a long time in the ICU was much higher if you were obese. Especially in people who weren’t particularly high risk otherwise. Which is not surprising considering adipose tissue produces lots of inflammatory products, increasing risk/severity of cytokine storm.
So not including obesity which is (depending on the source) Second only to hypertension as a baseline risk for severe disease and mortality is a little crazy. Especially since many statements regarding the benefits of calcifediol supplementation are offered in the context that obese patients are often deficient.
Oh, I would have thought the biggest issue is that this table indicates that the study is not randomised. Insofar as there’s issues with using p-values, applying a Bonferroni correction to the “previous high blood pressure” p-value suggests as much, and the 24% of patients vs 58% of patients difference is very large.
The large imbalance in the previous high blood pressure also implies their “at least one bad prognostic factor” measure is dodgy too. For one group the vast majority of patients with that variable = True are people with high blood pressure, for the other group it’s often something else.
The list of “Table 1 fallacy” issues discussed here may include the mistake you are thinking of: https://discourse.datamethods.org/t/should-we-ignore-covariate-imbalance-and-stop-presenting-a-stratified-table-one-for-randomized-trials/547/3
Comorbidity?
Not what you had in mind, but the “IC 95%” column is a mess. These are 95% confidence intervals, so “IC” is a typo (in English, anyway). The messed-up line wrapping possibly isn’t the authors’ fault (I checked the pdf, where it’s ok). But using dashes to separate the endpoints of an interval, esp when there are negative numbers all over the place, is unforgivable. You have to look really closely to see that they are reporting [-0.58,-0.13] and not [0.58,0.13]. Plus the table notes should say what these intervals refer to (odds ratios, I think).
A number of things I don’t like or find puzzling here:
– how are the p values even computed? Based on population marginal distributions? Using one group as the generating distribution and using the other to get the p value? How do they get the sigma of the normal to compute p without a prior distribution for each feature?
– if priors on each measure are population wide marginals, then they don’t account for comorbidities – I.e. each measure is being confounded by other measures in the dataset so reference CI intervals wouldn’t be accurate!
– The CI has negative boundaries on measures that can’t be negative. I guess that’s just the usual “don’t use p for this purpose”. If these are some kind of odds intervals, then what does it even mean for it to be negative?
– Some measures are flat out outside the CI range in both groups! E.g blood pressure. Again comorbidity at play here and it could have non-linear effects basic adjusting may not capture.
A bit of reverse engineering suggests the “IC 95%” and “P” columns are from t-tests (Welch’s version, I think) comparing the means of the binary prognostic risk factor between the calcefidiol/non-calcefidiol groups. Reporting the absolute risk difference could of course be done other ways, e.g. fit a GLM with the appropriate family & link function.
Either way, negative values with the CI and point estimates for the rates outside the CI for the difference in rates are nothing to be particularly alarmed about – better to focus on the many other issues present!
I agree with your age comment, but I was drawn to the differences between the 2 groups. It doesn’t look like an RCT to me, but even if it was, I would have questions about attributing any difference in outcomes to the treatment. All of the p values are large enough to lead someone to think that the two groups do not differ significantly, but there are enough differences that I would think it requires a model that incorporates all of those variables as factors. So, if they did that, then the results might tell us something – but if they did not (on the “evidence” that the 2 groups did not differ significantly), then I don’t see what value the results would have. Of course, if it wasn’t an RCT, then I’d have further questions about why the treatment was given to some people and not others.
Observational studies are referred to as “real world data” now.
Applying statistics designed for random samples to such data as if it were from an RCT is not valid, but everyone does it anyway.
Tiny N: 50 in group 1, 26 in group 2. Horrible covariate balancing. Dead on arrival.
Sfdljksdj:
Apparently it was a pilot study but then the results were so strong they published them. So you can’t blame them for the small sample size. See the earlier linked post for discussion of how the analysis could’ve adjusted for imbalance in the covariates.
I think it’s the lack of explanation of the terms. For example, “P”. I suppose we are supposed to know that that means a p-value to indicate whether the two groups are “the same”, but we shouldn’t have to infer that. I’ve seen tables where you can’t tell if something is a standard deviation or a standard error of the mean. And what are the confidence intervals expressed in?
And how were the CIs calculated, anyway? Take the hypertension numbers. The total number of participants was 76, and 36 of them had previous hypertension. So the probability of a participant having HT was .474. For the experimental group, the mean number would be expected to be 23.7, but there were only 11. If you assume a binomial distribution, that is about 2 1/2 SD below the expected number. The control group was less than one SD above the expected number. So it does seem likely that the experimental group differs from the control. But how does that relate to the CI numbers in the table, and how do you know that a negative CI value means that the experimental group is the one that is low?
Once again,critical information is not reported.
A bonus in this table is that the precision is all over the place. In the 2nd and 3rd columns, the percentage is sometimes reported with no decimal digits, sometimes with two. For that matter, using two decimal places makes little sense for this data.
I vote for ‘piranhas’: there are almost as many risk factors (15) as there are individuals in the “Group Without Calcidfediol” (26).
I wouldn’t say that including a p-value column in that table is “a big problem”. If those confidence intervals are ok, displaying the p-value saves people from calculating something similar in their heads.
I’m not sure if you would have found a z-score as problematic as a p-value, I suspect not. In any case, they are essentially equivalent and the readers may prefer the latter to the former.
The p-values in this table are uninformative, if not misleading. To reiterate critiques made in other posts (or comments on those posts): the standard errors of individual p-values are too large to distinguish them from one another or from zero; the population effect size is never zero so rejecting the nil hypothesis is trivial; p-values for nil hypotheses tell us nothing about whether there was a meaningful difference; useful research questions almost never have binary answers; multiple comparisons generally cut alpha down to an impossible level so people usually don’t adjust for them; p-values don’t tell us the probability that the effect is “real” despite frequently being misinterpreted that way; the alpha level is always arbitrary when specified; and not specifying an a priori alpha level makes the p-values even more problematic to interpret intelligently. Worst of all, if we keep reporting p-values as if they were useful, we are perpetuating the myth that p-values are useful.
Personally, I like CI’s because it’s easier for me to picture the magnitude of variability given a range than it is from just the standard error, although it does carry the baggage of assuming a normal distribution. But everything you need is in the SE of the difference, or in the effect size. A z-score is an effect size, so it has none of the problems above, so long as it’s used as an effect size. If it’s used to make a binary answer to a trivial question based on an arbitrary alpha level, I feel certain Andrew would have found that problematic, too.
Really? One of the reasons I think they’re even worse than p-values in their potential to mislead is:
While all the p-value and CI misinterpretations “remain rampant” I think reporting of them should be accompanied by warnings such as that one or this. Just recently I tried (and failed) to correct an economist and a journalist who’d repeated, in a particularly ironic context, the “Fundamental Confidence Fallacy”. It’s an extraordinary situation – only the one in quantum mechanics is comparably awful.
I apologize in advance for not having the energy to read the articles you liked to in detail. It could be my terrible allergies, but it could also be the overly detailed analysis which, in my mind, did not help my understanding. From what I read, I remain unconvinced about your criticisms of CIs. Of course, you are technically correct – the fallacies (that there is an X% chance that the observed CI contains the true parameter; and that the width of the CI is an indicator of the degree of uncertainty) are indeed fallacious. I accept that. But I insist on continuing to exercise those fallacies, albeit with plenty of hesitation and caveats.
The two problems I have with the expositions are (1) the examples seem contrived and it isn’t clear to me how readily they can be generalized, and (2) the advice that the confidence interval should remain completely uninterpreted leaves me hanging. In terms of (1), the submarine example with 2 bubbles is a strange one – with 2 data points, I’m not sure I would rely on any procedure and trust it. So, how general these purported fallacies are remains elusive to me. In terms of (2), it seems to imply that nothing at all should be said based on a single study. Now, I’ve seen that opinion expressed on this blog and I respect it. But, in many applications, there will only be one study (one data set) and important decisions must be made. To reject CIs entirely because they can/are misinterpreted, seems to lead to the conclusion that such problems are not worth studying at all. And, the recommendation that Bayes credibility intervals should be used instead, seems somewhat off the point to me. It may be true that they are superior in many respects, but I don’t think they fundamentally change the underlying problem: if you have a data set from a single sample and try to infer anything about the population, you must be unsure about your “conclusions.” No procedure is going to protect you from that problem.
The Bayesian procedures have several advantages which the CI procedures do not in general have. It’s not just about having remaining uncertainty and saying that this will not be resolved.
a confidence procedure can include impossible values where a Bayesian procedure will not.
A confidence procedure can include ONLY impossible values where a Bayesian procedure will never include any.
A confidence procedure can create empty intervals or extremely short intervals even when uncertainty is large, whereas a Bayesian procedure will not.
When making decisions, Bayesian decision theory dominates other procedures including procedures such as “acting as if the value is in the confidence band”
Then, your position is that the problem with confidence intervals is that they are not Bayesian? I can buy that, but I don’t think that is the issue that Michael Nelson (and the links he provided) is raising. Admittedly, I was raised on frequentist statistics and have never been fully exposed to Bayesian analysis, but one of the things I like best about this blog is that Andrew often rises above the frequentist vs. Bayesian debate. While that debate is important and far from finished, I think it is not really the issue with whether or not confidence intervals provide useful information. I think that they do – with caveats and caution – and the extreme position taken in the cited papers appears to say they are absolutely worthless. Is that because they are the result of non-Bayesian analysis?
It’s more like the problem with confidence intervals is they don’t solve any problem anyone has.
As you say below “The “straightforward” answer you quote does nothing for me.” that’s because confidence intervals don’t do anything for you.
The Neyman Pearson hypothesis testing framework is a behavioral framework.
Quoting from the article linked above (which quotes Neyman 1941): https://link.springer.com/article/10.3758/s13423-015-0947-8
“it is not suggested that we can ‘conclude’ that [the interval contains θ], nor that we should ‘believe’ that [the interval contains θ]…[we] decide to behave as if we actually knew that the true value [is in the interval]. This is done as a result of our decision and has nothing to do with ‘reasoning’ or ‘conclusion’. The reasoning ended when the [confidence procedure was derived]. The above process [of using CIs] is also devoid of any ‘belief’ concerning the value […] of [θ].” (Neyman 1941, pp. 133–134)
So it’s a “decision theory”. That is “decide to act as if the interval contains the value”. So long as the different values within the interval don’t produce wildly different conclusions, this could maybe occasionally be ok. Basically the only time the confidence interval situation would make sense is when it corresponds to a narrow Bayesian interval so that using say the middle of the interval as the “true” value produces only “epsilon” errors in prediction/decisions.
Frequentist theory tells us that Bayesian Decision Theory dominates any other decision methodology in terms of better frequency properties. Basically for any non-Bayesian decision rule, there is a Bayesian decision rule which does **uniformly** better. (This is Wald’s theorem… there are some technicalities, but basically that’s what it says)
So, even if you’re a strict frequentist what you want is a Bayesian decision rule.
So, yes, the answer is that CIs don’t answer any question we have, and Bayesian decision rules do.
A probabilistic interpretation, whether “B-ian” or “F-ist”, posits a “universe”, a bowl from which the experiment (and the experimenter) is “drawn”. And hence the interval as well. The interval is an epiphenomenon, of the model, and the model is supposed to represent the universe from which a probabilistic interpretation emerges. The “B” says, the universe includes the experimenter’s prior experiences (encoded by his “rational” beliefs — let us leave out the “irrational” ones). The “F” says, the universe is supposed to describe similar experimental setups, irrespective of what the experimenter expects. Both posit however such a universe of replicates; the “Bs” universe is perhaps broader, more complex; but it is a proxy for past experience just as much as is the Fs universe.
In *either* event, the interval is *intended* to tell us something about the “signal to noise ratio” of the result. *If* that number were really a signal; *would* the experimental setup be trustworthy as a discriminator; as a signal-detector? Or not? But under no circumstances does the judgement end with the result of a *single* experiment — or I should say “ought to end”.
I fact see Michael Lews comment below, many of these CIs have these problems, including a wide range of negative values in the interval for concentration values which are necessarily nonnegative. That would never happen with a Bayesian analysis which would have zero support in the prior for negative values
The 95% confidence intervals in that table are for the differences in means. It’s not a problem if they are partially or totally on the negative side.
It’s true that for the measurements reported as mean +/- SD (not as CIs) there are a couple where the standard deviation is higher than the mean. For the D-Dimer and IL-6 (22/48) factors it seems that there may be an outlier in one of the groups raising the mean strongly and even more strongly the standard deviation.
[My emphases.]
Similarly, the other paper asks only that if you “insist on continuing to exercise those fallacies” you do so in ways which “minimize the harms of current practice”. This is not an “extreme position”. It’s not extremist Bayesians* demanding the abolition of frequentist methods; it’s statisticians asking others to do their job properly; to respect the theory they’re using and stop doing things which would “horrify its founders”.
* IIRC Stephen Senn is no Bayesian.
The “straightforward” answer you quote does nothing for me. I have a data set and have constructed a confidence interval for something. I can use the correct words – that it represents properties of a procedure, not of any particular interval. Now, how is anyone to use the results of my study? Suppose I was examining whether a particular criminal justice reform leads to a reduction in crime. The confidence interval I obtain is for the percentage change in a particular type of crime under the new practice. The straightforward answer basically says to ignore my results. I fully appreciate the dangers of misinterpreting what I have found, but I fail to see how the quoted section provides any foundation for using the results of my study for anything other than saying that more studies need to be done.
Is it just one?
My vote: green jelly bean effect – https://xkcd.com/882/
But also support @Mike’s piranha problem / all-else-equal (these two problems appear quite similar to me)
The summary values for concentrations of various blood constituents (C-reactive protein and below) are nonsense because concentrations of mediators cannot ever be negative and typically have very skewed distributions. The wide (WIDE) intervals listed are a consequence of a small number of individuals having far higher values than most. This is a very common issue.
Geometric means or simple log transform of such values usually give a more informative picture, along with far higher power for the p-value test.