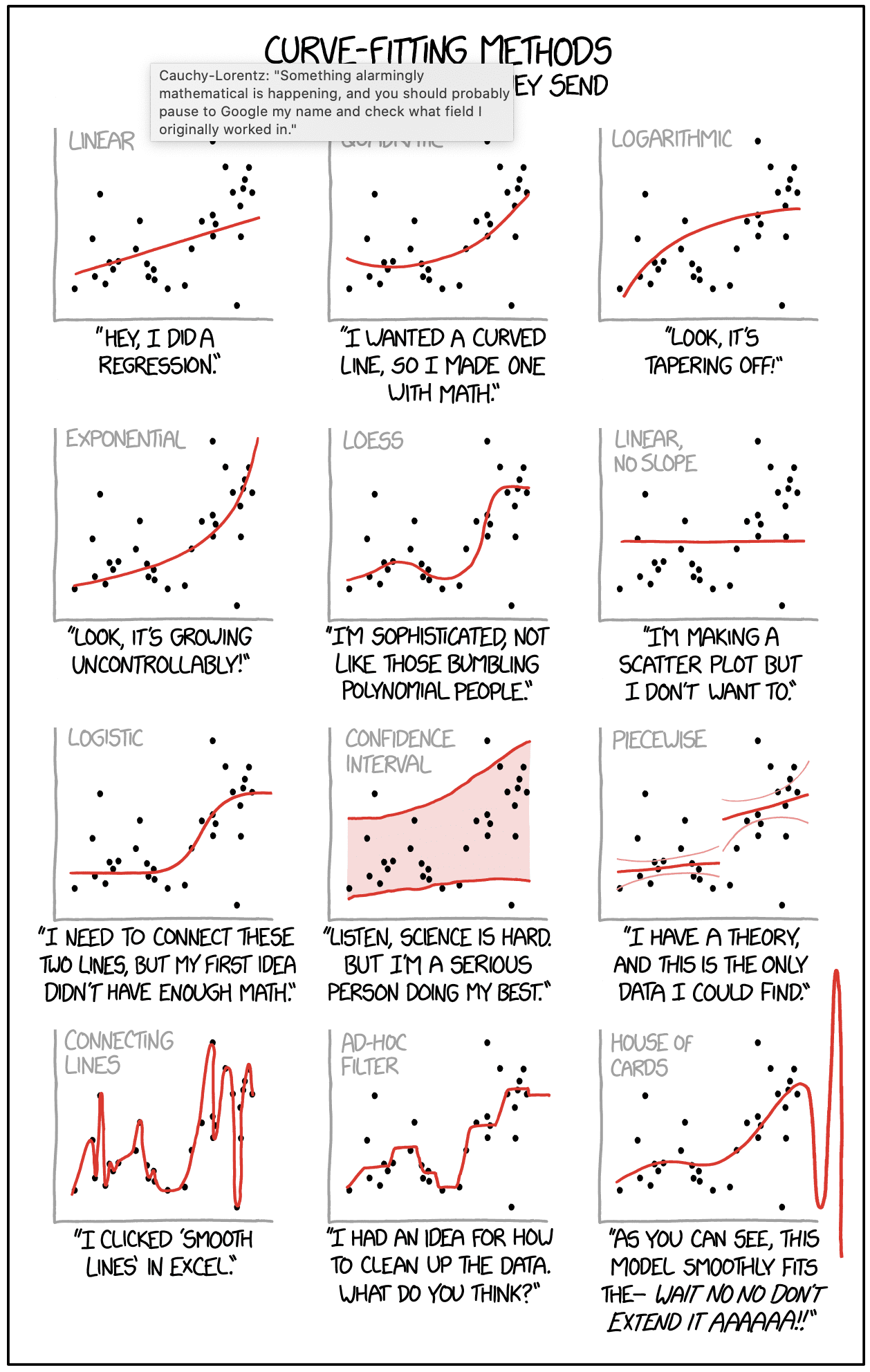
We can’t go around linking to xkcd all the time or it would just fill up the blog, but this one is absolutely brilliant. You could use it as the basis for a statistics Ph.D.
I came across it in this post from Palko, which is on the topic of that Dow 36,000 guy who keeps falling up and up. But that’s another story, related to the idea, which we’ve discussed many times, that Gresham‘s law applies to science.
But really what I like about Munroe’s cartoon above is not the topical relevance to some stupid thing that some powerful person happens to be doing, but rather the amazing range of curves that look like reasonable fits to the exact same data points! I’m remaining of the examples discussed here.
“remaining of” -> “reminded of” in the last sentence?
I loved this just about as much as its flip-side in the wonderful paper,
Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing
(dl.acm.org/doi/10.1145/3025453.3025912)
(For the avoidance of doubt, I enjoyed them both immensely!)
Last one looks a lot like these early COVID-19 predictions from IHME that have been discussed here.
Early IHME predictions (late March) were for as many as 160k deaths by late August. There were roughly 150k.
Persimonious:
I think Anon was talking about the curve-fitting exercise that was being pushed by the White House and discussed here with a followup here that specifically focused on curve fitting.
I think the ~60k number that was projected at one point for sometime in late summer is the really heavily-criticized IHME one.
There were several different models IHME changed between…
Lies, damned lies, and…
Lies, damned lies, and…
…curve fits.
I’d say that confidence interval is the most accurate one here.
I 90% agree with you.
Note that the Dow is at 31,152 when I look at it right now. The problem with the forecast wasn’t the level, it was the time in which it will hit that level. The Dow will hit 36,000 eventually.
John:
Yes, if it’s the timing. If they’d said that the Dow would reach 36,000 sometime, or even if they’d said it would happen sometime before 2050 or whatever, I don’t think people would’ve thought it was so objectionable. You can see the wikipedia article on the book for more details. Apparently they said, “Stocks are now in the midst of a one-time-only rise to much higher ground,” which did not happen, and in fact is somewhat contradicting any vague advice that stocks will eventually rise in the long term.
To put it another way: they used an attention-grabbing title and they were wrong. Nobody was forcing them to use a dramatic title. In doing so, they took a risk. If the stock market really had boomed during the 5 years after the book came out, then they would’ve received lots of credit for their prediction (even if they’d just been lucky); conversely, given that what happened was nothing like the prediction, it’s only fair that they get negative credit.
Statistics means you _should_ argue with success – it’s often illusory (unless sufficiently repeatable).
As the t-shirt says, “statistics means never having to say you’re certain.”
+1
Statistics is a perfect job for people with no self-confidence
I don’t know, is the t-shirt really the appropriate shirt here?
Well, t-shirts are fairly robust to violations of the usual assumptions about normal distribution of body mass.
;~)
There’s a large family of predictions that are almost always right when you leave out the “imminent.” Anything involving mortality for instance.
For example, around 1980 broadcast television lost its monopoly with the emergence of cable and home video. Industry watchers started predicting that at least one of the big three would be gone in the decade.
Every year since competition has grown and viewership has declined but the industry is still around, still big and still profitable.
That means that after becoming a national medium sometime in the late 40s, broadcast tv has spent more than half its life with experts predicting its imminent demise.
Given that the forecast was for the Dow to hit 36,000 in ~2003, it was utterly inaccurate. I would venture to say that predicting a 26,000 point (or 250%) increase in the Dow over 3-4 years has a much different meaning than predicting it will increase by that amount in ~25 years. Those two predictions imply very different understandings of the value of companies on the list.
The daily high temperature in Death Valley will eventually be mild at some point in the year, but if I predict a high temperature of 60 degrees F for July 4, it’s not that my timing is off by a few months… my model of the world is completely wrong.
“The problem with the forecast…was the time…”
That’s the problem with every forecast that’s wrong.
> That’s the problem with every forecast that’s wrong.
Especially the ones about the future.
Maybe we need to do fewer forecasts and more hindcasts?
One can draw an infinite number of lines through a finite number of points. I think Gödel said that. This means that in a real sense every study can only lead to provisional answers. Statistics is a tool to show us the likelihood of any prediction of the next point on the curve. If you want people to think you’re smart, you should only give Delphic answers. Any hard answer can be disproved by events. I think the SuperBowl will be won by the team with a great balance of the running attack and passing game, and I think that this response proves that I’m smart.
Balance, schmalance. I’m betting on the one with the most points. (Or, alternatively, the one that beats the spread.)
This also reminds me of this paper: https://www.nature.com/articles/431525a which when you look in the supplementary material you see that they fit multiple different models, but finally used the linear model because the others were not significantly different (essentially accepting the Null). A better modeling process would have used more scientific knowledge to put priors on the different models, and/or use posterior predictive checks on their extrapolations to see which models were even realistic for their conclusions.
Some commentaries on the paper, such as this one: https://www.callingbullshit.org/case_studies/case_study_gender_gap_running.html point out the fun, but ridiculous extension of their model. This commentary at least suggests that the authors could have known that their conclusions were silly, but wanted a case study to point out options for better modeling.
Writing at a time when the delta of the Mississippi River — not to be confused with the Mississippi Delta, which refers to the delta of the Yazoo River –, was growing each year into the Gulf of Mexico, Mark Twain made fun of the fact that if the growth continued at the current rate, in 150 years it would create a land bridge to Cuba. ;)
I’ve had this hanging in my office for a couple years. I like to show it to PI’s I do stat work for. I think there is a lot of wisdom in this cartoon.
https://xkcd.com/892/
I can’t believe schools are still teaching kids about the null hypothesis. I remember reading a big study that conclusively disproved it years ago.
Njo,
Also, what’s this “solve for x” business? I had to solve for x back when I learned algebra in junior high. I solved for x, x was 2, end of story.
No, x=42. Everybody knows that.
Well, if x was 2 forty years ago, them maybe x is 42 now.
…. which makes Andrew 56.
https://www.google.com/url?sa=i&url=https%3A%2F%2Fpercentagecalculator.mes.fm%2Fmemes%2Ffind-x-here-it-is&psig=AOvVaw1tyPSDYz8c-mqWEGlyvmbE&ust=1610139123586000&source=images&cd=vfe&ved=0CAIQjRxqFwoTCIDB_eXZiu4CFQAAAAAdAAAAABAD
I love this.
Andrew, you are misinterpreting the graphs. You shouldn’t – they clearly labeled the X- and Y-axes.
The relationship between the linearity of the world and the use regression is linear (in an optimal science). You have to be sufficiently Sophisticated to employ Lowess, you can’t use it before you learn it (S greater than S*). The relationship between how much you “clean” your data and whether the AD(verstising) or Head of College (HOC) pay attention to you is idiosyncratic.
These are real structural models. This is the way social science should work.