Matt Folz points us to this recent JAMA article that features this amazing graph:
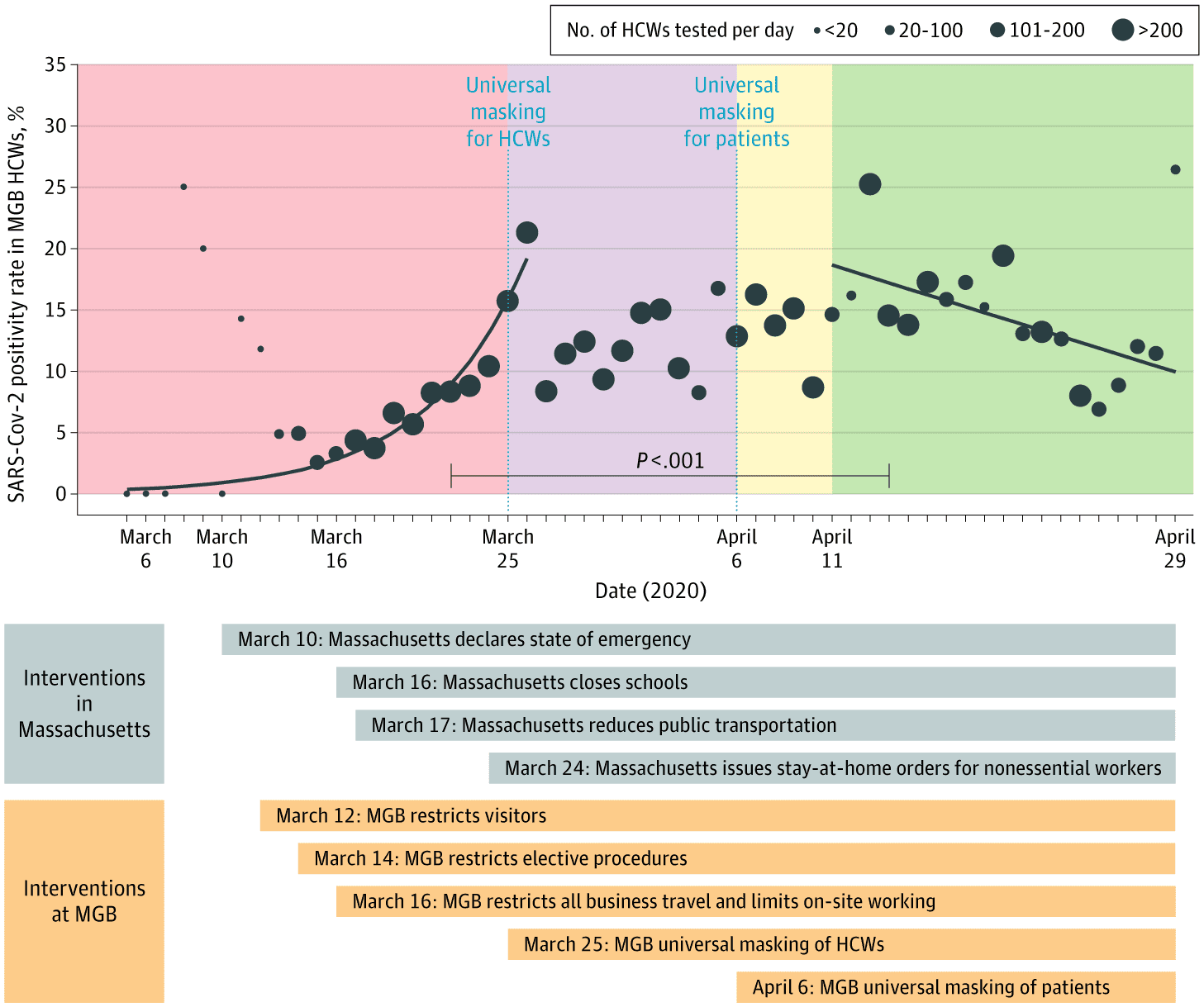
Beautiful. Just beautiful. I say this ironically.
Matt Folz points us to this recent JAMA article that features this amazing graph:
Beautiful. Just beautiful. I say this ironically.
I’ve seen worse
Anon:
Yes, I’ve seen worse too; for example here. But we can’t let ourselves be so jaded that we only reserve our criticism for the absolute worst work that is published.
Perhaps I am missing something on this one but I don’t see this as a particularly poor graphic. Certainly, there was some degree of freedom in selecting the cut-offs, but at the very least they do not appear to be arbitrary (it makes sense to make the cutoffs at points of policy intervention). Moreover, even if this graphic is unconvincing as far as positing a casual connection is concerned, it at least seems to provide enough information to allow one to question the posited connection. The same cannot be said for many other graphics that have been the subject of disdain on this blog.
On the other hand, it is 2am EST so perhaps it is likely that I am missing something…
Allan:
I agree that the graph has the virtue of revealing its the problems of the analysis. I don’t think it’s a poor graph at all. I think it’s an excellent graph. . . It’s the statistical analysis that seems poor to me.
You write, “there was some degree of freedom in selecting the cut-offs” . . . I agree with that part. And the cutoffs do appear to be arbitrary! Why do they allow a 4-day lag period at the time of the second intervention in their analysis but no lag period after the first intervention? (See the Methods section of the paper?) What are we supposed to think about that trail of dots at high values on the left part of the graph, which don’t fit into their exponential story at all? What about the huge issue of selection bias in who gets tested? Who cares about “P less than .001” given that this is a comparison to the entirely uninteresting null hypothesis of zero rate of change?
But, yes, my problem is with their statistical analysis. The graph has some excellent features.
I agree with those issues but I think some of those decisions are justifiable if adequately explained (better than in the paper…). For example, ignoring the trail of dots corresponding to <20 HCW tested per day could be a means of trying to address selection bias. Maybe there's also some theory that masks for HCW would have a more immediate impact than masks for patients.
I guess my issue is – why does this graph/data even NEED statistical analysis? The graph, even with the shading/cutoff point problem, is pretty clear. I don’t understand what the odd curve-fits add to the meaning.
I agree. I like the graph and I could imagine a few tweaks to make it actually a great graph (remove the p .001 note and change the second curve to an exponential fit). Then again, this would roughly equal the second graph in this post here:
https://statmodeling.stat.columbia.edu/2020/05/22/new-report-on-coronavirus-trends-the-epidemic-is-not-under-control-in-much-of-the-us-factors-modulating-transmission-such-as-rapid-testing-contact-tracing-and-behavioural-precautions-are-cr/
Now I mainly like both graphs because they point us to the sloppyness of the real-world behavior. We’ve seen quite large delays between interventions and adoption of a constant reproduction rate R in testing (e.g. in germany, this was roughly two weeks of delay between lockdown and adoption of a constant (lower) reduction rate). So I guess it really makes sense to put some delay between the last intervention and the evaluation of the resulting reproduction rate (as in the graph above).
So why am I writing about all this? Because I felt this paper here:
https://statmodeling.stat.columbia.edu/2020/06/18/estimating-the-effects-of-non-pharmaceutical-interventions-on-covid-19-in-europe/
ran into exactly this trap by trying to assign effects to single interventions while keeping everything else constant! It looks soooo sophisticated, and whoa, it does partial pooling and offers open stan code!1!!! But really, it’s no better, but there the wrongness is all hidden (I had to read several files in the github code to find them assigning values to the mortality rates for each country with no external justification, but 15 decimal places of accuracy?), while in this graph it’s at least there for us to see and discuss openly.
Then, I’m mostly thinking about the whole epidemic in rule-of-thumb values (basically what you can learn from the graph above by assigning a basic growth and decline rate to early and late stages and then thinking about how it might split into actual effects) while not caring at all about p-values and formal causal inference. And given the messiness of the data available as of today, this seems totally justified! There are just too much colinearities and non-identifiable parts…
This reminds me of the distinction between folk psychology (how normal persons infer each others motivations from their actions) and professional psychology (ranging from Freud to psychopharma) and how they relate to each other. So maybe what I’m doing here is just folk statistics, without ever doing any actual computation outside of my mental rule-of-thumb estimates?
“I’m mostly thinking about the whole epidemic in rule-of-thumb values…reminds me of the distinction between folk psychology….maybe what I’m doing here is just folk statistics”
All you’re doing when you toss out the statistical analysis and use rules of thumb in the current epidemic is ignoring the quackery involved in producing the (thousands of) statistical analysis and shifting your focus back to the valid data and relationships. It’s not akin at all to the “folk psychology” you describe for a ton of reasons.
You don’t need R or p to see the arc of the trend in the graph above. It’s readily apparent despite the author’s trying to influence your view with lines and colors. There are lots of problems with it even without the lines and colors as Andrew described, so it’s not useful for making a precise forecasting model, and it doesn’t seem to provide anything useful with respect to the efficacy of the interventions. But it is useful to get a general idea of where things were headed at the time. We don’t need to be expert Bayesians to understand a basic chart.
The ‘i agree’ was intended as a response to AllanC.
I like this figure (minus the lines and p value)! I think it might have been interesting to see a similar plot of covid positivity rate over time for the entire state of Massachusetts alongside this figure, as I wonder if this curve is just the natural progression of the disease in the entire state and not just MGB. (I don’t know if there were any statewide mask rules, but none are listed in the plot).
In the article, the authors’ address your good point by stating, “…the case number continued to increase in Massachusetts throughout the study period, suggesting that the decrease in the SARS-CoV-2 positivity rate in MGB HCWs took place before the decrease in the general public.”
True, but this graph is the postivity rate – “the percentage of daily test results that were positive”. The case number and the positivity rate aren’t the same thing. So, I don’t think that saying that “the case number continued to increase in Massachusetts” necessarily addresses what I would like to see in a second plot of positivity rate over time for the entire state. It would be interesting to know if the positivity rate in the entire state also follows this curve.
Or I guess better than a plot of the state would be another healthcare system in the same state that didn’t implement these measures or did so at a different time….but I reckon that might be impossible to find as most healthcare systems probably did something similar around the same times.
I feel like some people here are missing the point. The appearance of an effect in the trend lines is driven by fitting to outliers at the boundaries. The super-linear (exponential?) growth trend in the first period is driven by the two high datapoints right at the first cutoff, and much of the decline in the last period is driven by the high datapoint right at the beginning. In addition, it appears they fit that first curve or at least extrapolated it to some datapoints past the cutoff, seemingly to make their point stronger. That’s pretty sketchy. To see this, pretend there are no colors and no lines, just look at the datapoints. If you think this graph makes it clear results are not to be trusted, the graph without all the colors and lines makes it even more clear, without the added defecit of seeming like convincing evidence to many people.
I think you are right about the bulk of the differences being driven by a few particularly high days. But I don’t think you need to do a terribly sophisticated analysis to argue that there’s a difference in trend between the start and end of the dataset. I’m not comfortable with just outright dismissing the “outliers” either.
I think the datapoints alone do show a trend changing over time, but I don’t appreciate the deception of these ridiculously dramatic graphs. In particular, extending the first trendline into the purple region feels very dishonest to me, though maybe they explain it in the full text.
@somebody : exactly right. The paper (which is just a few paragraphs long) doesn’t explain anything, and in fact clearly states the ridiculous claim that “During the preintervention period, the SARS-CoV-2 positivity rate increased exponentially … During the intervention period, the positivity rate decreased linearly…”
As you note, the datapoints themselves are fine, and show an interesting and probably important form. The fits are nonsense bordering on dishonesty.
somebody, Zhou Fang, and Raghuveer Parthasarathy,
Some quotes from the article relevant to your points
“The overall slope of each period was calculated using linear regression to estimate the mean trend, regardless of curve shape.” (and for the statistical comparison)
“The [post-masking] decrease in HCW infections could be confounded by other interventions… such as restrictions on elective procedures, social distancing measures, and increased masking in public spaces, which are limitations of this study.”
I like the Figure a lot. I don’t think the trend lines or the before-after comparison are good statistical practice, but… there’s a lot of good information squeezed into that one figure and short report (JAMA research letters are limited to 600 words iirc). Also, the discussion section sounds reasonable to me.*
The article is free and short, so I suggest reading it.
*I’d like to see more supporting argument for the last sentence of the article as well as the selection issues that Zhou Fang mentioned elsewhere, but there is no way that fits in 600 words.
Ugh, there’s a 600 word limit? I’m not so sure you can do a lot of good science in 600 words…
A number of things about this really bother me. It might tell an interesting story, but the opportunity for forking paths makes me leery of believing the analysis – it conveniently fits a story they want to tell. They did not ignore the points that did not fit the pattern – but by weighting the data by the number of tests, they essentially eliminated their impacts. It would have seemed sensible to me for them to have modeled the statewide (non-MGB) data as an explanatory variable in their model. One alternative pattern that looks like it might fit is for the positive results to have increased throughout – until the post intervention period. Quite possibly, the positive results were decreasing throughout the state at that time.
But we can’t tell – and this is my concern. The data, of course, is not available. But the article (such as it is) contains this statement: “Dr Bhatt had full access to all of the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis. Drs Wang and Ferro contributed equally to this article.” Sounds familiar? Ok, JAMA is not Lancet or NEJM, and Dr. Bhatt is not Dr. Mehra or Dr. Desai. But it is Brighan and Women’s Hospital. Reputations should matter and at this point, the burden of proof should lie with the authors and the journal. The easiest way to earn my trust is to provide the data. Without that, I remain unconvinced.
+1
The suggestion to compare against statewide non-MGB data is a good one: MGB was frequently reassuring its staff during the time covered by this chart by reporting that positivity for tested MGB HCWs was similar to positivity in the Boston area outside MGB, arguing that intra-MGB transmission was no different from community transmission where mask usage was independent of these interventions. That data needs to be analyzed and is available, and the authors should have included it, and the editors should have required it.
If the fits, p-values, and yellow color are removed, I think that revised chart would summarize the data nicely, but this published chart does include those features, and is associated with the article text, and the integrated effect is a very strong statement (that implementing universal mask-wearing changed intra-MGB positive case kinetics from exponential growth to linear decline). But that statement is no more strongly supported by the actual data than many other statements that would associate far lower effects with intra-MGB mask-wearing. It remains very likely in that universal mask-wearing does reduce positivity rates, but this data should not alter our confidence in that relationship, and the authors, aided by the journal editors, are trying very hard to convince us that it does.
This chart is great!
If we weren’t so uptight about having every paper being perfect, and about getting the right answer right this second, and about using everything instantly for policy, this chart – along with the others like it in this vein of COVID data mining – tells us something important: this kind of analysis is bunk!
There have been alot of these at this point and the theme is getting worn out. But someone had to do this stuff to show us that it doesn’t work. After all, it might have been otherwise. They might have plotted up the data and found clear breaks in trend at the supposed treatment boundaries.
Another way to think of this: someone is finally publishing negative results!!! The only issue is that they don’t seem to know it.
A more general issue with this is that interventions are often driven by the existing situation: if things are bad, you act; if things are good, you don’t.
So there may be a correlation/causation issue — IE, when the epidemic is rising sharply, measures are put into place; it then peaks and plateaus or declines; but you don’t really know if that was driven by the measures, or if it was going to peak anyway.
Ideally, you could compare to other locations, but there seems to be little pattern in many places. Comparing the death curves for GA and TX for example is rather strange; they don’t correlate to reopening in the same way (GA reopened earlier than TX, and TX has seen a rise in deaths but GA hasn’t.) South Dakota seems to be stable and/or very slowly declining, with less measures than anywhere else in the US; sure, its population density is super-low, but Montana is too, and it has a very different pattern, going down very low and then rising after reopening (though SD still has more total deaths than MT).