See here. Please share your reactions and suggestions in comments. I’ll be talking with Seth Flaxman tomorrow, and we’d appreciate all your criticisms and suggestions.
All this is important not just for Italy but for making sensible models to inform policy all over the world, including here.

Unfortunately, the link does not work, at least for me.
From looking at the updated results on the Imperial College London website, the modeled deaths look like a smoothed version of the reported deaths. But, are the reported deaths serious undercounts? I just heard a scientist from Belgium on The World saying that they are reporting confirmed deaths adjusted for estimated unconfirmed deaths, but that other countries were just reporting confirmed deaths. Since the model starts with deaths, this seems like an important issue.
More generally, I have been writing a letter to the authorities in my county in NW California, trying to explain to them why they should look to models like this for guidance, instead of simulations, so I am delighted to see this.
The link works now; thanks.
I suppose the question for this is whether they are using similarly collected death data to build the IFR part of the model. It’s okay for the reported deaths to be undercounts if the source data is also an undercount in the same way.
I really wouldn’t put any stock into a model that doesn’t incorporate at the very least the rate of testing.
Also, it ignores the effect of treatment on mortality.
https://www.businesswire.com/news/home/20200504005250/en/Sermo-Reports-50-Highly-Experienced-COVID-Treaters#.XrCcH92Y0O8.twitter
Seems like it would be better to use a correlated error assumption (both between regions, and in terms of a temporal autocorrelation) for the infection fatality rate. That will help soak up changes in reporting probability.
I’m not sure if it’s the best idea to throw out the confirmed case figure entirely and just use deaths. Can’t both be modelled together somehow?
I’ve been trying to work up the energy to build a dynamic model that incorporates ascertainment and differential death and hospitalization risk by age…
not that I’ve gotten anywhere, just basically thinking up the structure in my head but too many other things going on to write it down into code. I keep looking at Julia for its really excellent DifferentialEquations.jl
It is worth it. Do it. The world is on lockdown over this. There will never be a better time to prove your methods work.
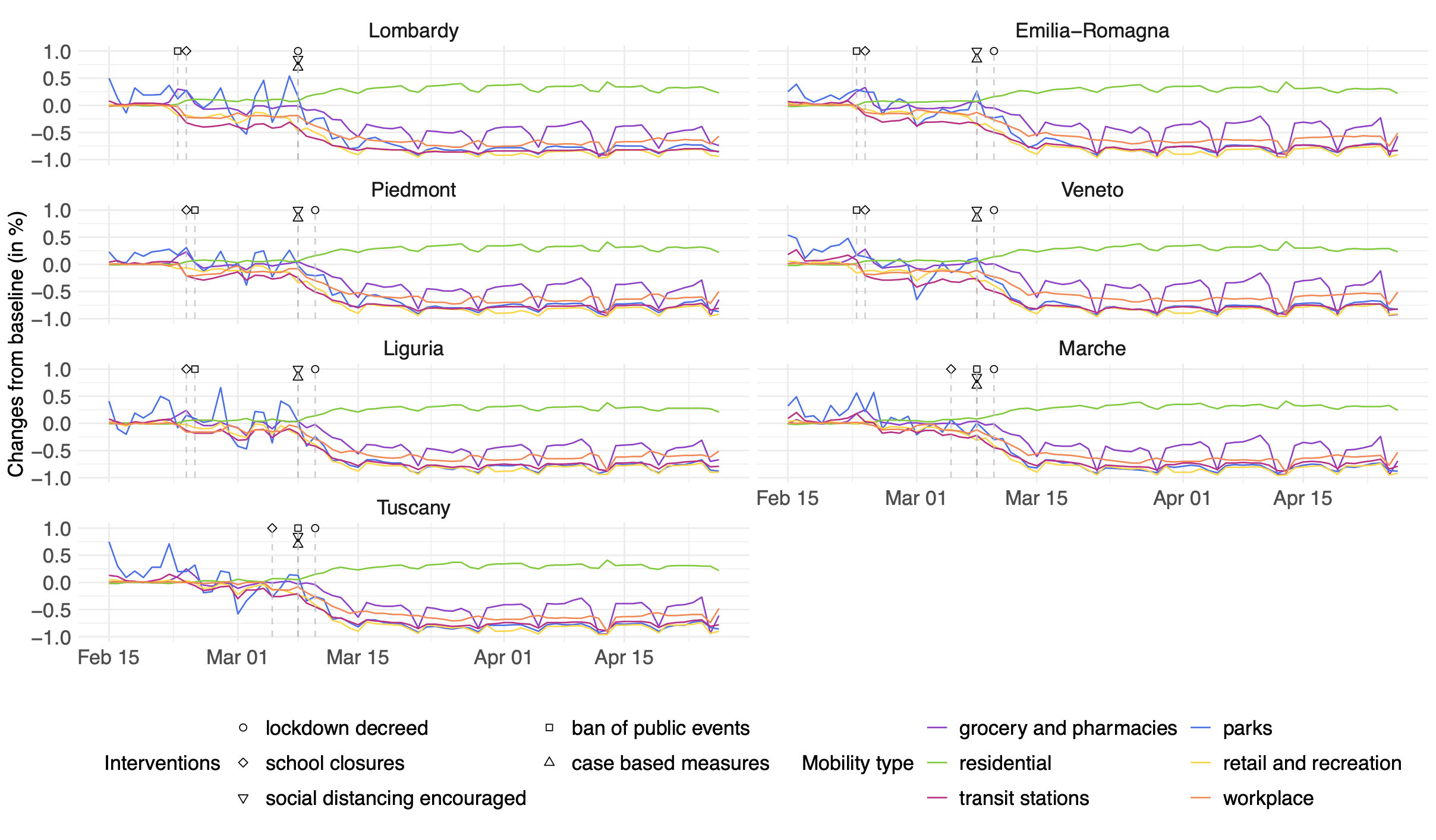
Caption on Figure 4 has a typo. Change “were mobility” to “where mobility”.
Figure 4 is also hard on the eyes because the vertical axis is scaled differently for the different regions making for difficult comparisons.
If I understand correctly, the model assume that the IFR applies evenly to all ages and follows the PDF N(1,0.1)? (If I’m mistaken, please correct!)
But the most recent data from Italy (and elsewhere in the world) indicates IFR is a direct function of age and comorbitity. The most recent daily report lists a mean CFR of 0.28% for age 0-49; the mean CFR then jumps to 18.2% for age 50-90+. (For the sake of argument, assume IFR = CFR, even if this may not be true in reality.)
Furthermore, data from Italy indicates IFR is a direct function of comorbidities. What about stratifying by comorbitity, then? Those with high-grade obesity, high-grade obesity, poorly managed diabetes, and other poorly managed commodities seem to be much more likely to die from SARS-CoV-2 than a healthy person or one with well-managed comorbitities. (And the underlying pathophysiology/immunobiology seems to support this correlation.)
Without the above stratifying, the model could overestimate the total number of deaths in Italy.
IMO, the paper would be much stronger if the authors provided detailed rationale justifying why the model uses a single PDF for IFR instead of one stratified by age and/or comorbidity.
Their aggregate IFR approach in principle already incorporates these factors. To have a more detailed modelling approach to have value you would need regional information on age demographics and chronic conditions, and also compute the age-exposure relationship.
Zhou,
> Their aggregate IFR approach in principle already incorporates these factors.
From what I can find, they seem to calculate IFR (third paragraph Section 8.1 of Report 13) for specific ranges of age. They then calculate the mean IFR using age demographics.
But these values (following references, I’m assuming they are those in Table 1 of Report 9) shows that adjusted IFR has tremendous variance by age. Mean IFR for age 0-49 is 0.05% while mean IFR for age 50+ is 4.4%. The variance is so high in IFR that even if you incorporate age demographics when calculating the mean, it skews much higher when you incorporate older groups.
To check this, I used the IFR values from the aforementioned Table 1 and data from the Italian Census (https://www.istat.it/en/population-and-households?data-and-indicators). I calculated weighted mean IFR (IFR’) with weights = N_a / N, where N_a = population for age range and N = total population.
IFR’ for age 0-49 is 0.07%. When you include age 50-69 (so age 0-69), it jumps ~7 fold to 0.48%. When you include age 70-80+ (so age 0-80+), it jumps ~24 fold to 1.6%. (This does not match their values because I think they did additional/different weighting, but I could not find the specifics.)
So my question remains: Is it reasonable to apply a mean IFR to the population given its high variance?
If the variance of IFR was tighter, IMO this would not be an issue. But given the multiple order-of-magnitude variance in IFR — using the single IFR just doesn’t make sense to me. Maybe I’m missing a key point somewhere?
(thank you, Joshua, for linking me here from the “Coronavirus Quickies” comments)
The paper was posted online last week on MedRxiv in advance of peer review and submission to a journal. It uses IFR stratified by age group by region in Italy.
https://www.medrxiv.org/content/10.1101/2020.04.15.20067074v2
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Quoting from news release >>>>>>
Seljak says that getting COVID-19 doubles your chance of dying this year.
“If you want to know what are the chances of dying from COVID-19 if you get infected, we observed that a very simple answer seems to fit a lot of data: It is the same as the chance of you dying over the next 12 months from normal causes,” said Seljak.
Current uncertainties can push this number down to 10 months or up to 20 months, he added. His team discovered that this simple relation holds not only for the overall fatality rate, but also for the age-stratified fatality rate, and it agrees with the data both in Italy and in the U.S.
“Our observation suggests COVID-19 kills the weakest segments of the population,” Seljak said.
Please explain Mr. Seljak’s published comments, vis-a-vis
“getting COVID-19 doubles your chance of dying this year.” and “It is the same as the chance of you dying over the next 12 months from normal causes,” said Seljak. These comments appear to conflict. I must be missing something.
Seth and Andrew:
tl;dr: I think this report is exactly the kind of work that is currently needed, but it also has a key problem: many Rt projections are very near 1, which is a parameter space region where forecasts of infectious disease models are exceptionally sensitive to small assumption violations. This means that, although the report indicates several regions of Italy could safely reduce mobility lockdown restrictions by 20% (Tables 2-3; Figs 4, 7, 8), I think it is more of a coin toss for each region of whether consequences would be safe or produce terrible rises in Covid-19 deaths. A solution to the report’s problem might be to flip the goal of the analyses: Instead of forecasting Covid-19 deaths in each region, estimate for each region the maximum allowable increase in population mobility that keeps Rt at a safe distance below 1.
In (too much) more detail…
Thank you so much to the Imperial College teams that authored this report (Vollmer et al.) and the previous related work (Flaxman et al.). It’s absolutely fantastic quality work and I especially appreciate how it addresses topics that matter to public policy right now — how much do lockdowns and other non-pharmaceutical interventions help, and how much they need to be maintained.
However, I think there is an important problem with the current (Vollmer et al.) report on Italy. The problem is a little subtle but has large consequences. Here’s the problem as I see it:
When the authors model the effect of a “20% return to pre-lockdown levels of mobility”, they obtain several projected Rt’s that are very close to the critical threshold of 1. For some regions of Italy, the projected Rt’s and associated 95% CIs are slightly below 1, and for these regions the authors forecast that Covid-19 cases and deaths will continue to reduce over time if the lockdown is 20% lifted. For other regions, the projected Rt’s and 95% CIs are slightly above 1, and for these regions the authors forecast that cases and deaths will grow horribly over time if the lockdown is 20% lifted. In summary, the forecasts about what happens to each region are exceptionally sensitive to whether the projected Rts and 95% CIs are slightly below or above 1.
The problem here is that small violations of the Covid-19 model’s assumptions and simplifications can easily make the “true” Rt slightly above 1 for regions the authors projected to have Rts and 95% CIs slightly below 1. Similarly, small assumption violations can easily make the “true” Rt slightly below 1 for regions the authors projected to have Rts and 95% CIs slightly above 1. As I think the authors would agree, small assumption violations are guaranteed to happen. The consequence is that, for regions they projected would be safe with a 20% reduction in the lockdown, I’d say that its actually more of a coin toss over whether they’d be safe or have to endure a bad increase in Covid-19 cases and deaths. Similarly, for regions they projected would have greatly increased cases and deaths with a 20% lockdown reduction, it’s more of a coin toss over whether that would happen or whether they’d be safe.
Note that this problem would not occur if the estimated Rts were far from 1. For example, for projected Rts of 2.5, if assumption violations meant “true” Rts were 2.4 or 2.6, this would not change the findings of the analyses to an extent that would be important to public health decision makers. However, since the projected Rts are near the critical threshold of 1, small assumption violations lead to massively, qualitatively different forecasts of cases and deaths, far larger than the report’s CIs suggest.
Maybe a good solution to this problem is to flip the entire analysis: Instead of analyzing the counts of cases and deaths that would occur with a 20% return to pre-lockdown mobility levels, analyze the percentage return to pre-lockdown mobility that could be allowed while keeping Rt safely below 1. At least in principle, it looks like the authors could use the models they already have for this. An added advantage here is that the Google mobility data could then be tracked by the Italian government in real-time, to check if lockdown reductions are allowing dangerous levels of mobility or, on the other hand, whether more restrictions can be safely lifted.
The authors could also build in some kind of safety buffer around Rt or the mobility percentage, in recognition that there will be assumption violations.
I’m sure the authors are overwhelmed with work, so may not be able to do this. But at the least, it might be kept in mind for future updates that track how Italy’s lockdown restrictions have turned out.
Thanks so much to the authors again for their work!
So if uncertainties about Rt and the effects of 20% lockdown were more realistically incorporated, the 95% CIs would span from near-zero to huge on most or all the graphs? Which suggests that the honest answer is “we have only the vaguest idea”?
Terry,
Yes, I think that more realistic 95% CIs for Covid-19 deaths would extend from near zero to high values in the scenario where mobility returns by 20% to pre-lockdown levels. As in, “we only have the vaguest idea” what happens in this scenario.
This may also be the case for the scenario where mobility returns by 40% to pre-lockdown papers, but it’s more difficult to tell from shown results.
Note that the problem I mention is not with the authors’ infectious disease model, but with all infectious disease models (at least all I know about) — they all become sensitive to small assumption violations when Rt is near 1. So using a more realistic model will probably not solve the problem.
Nonetheless, I still think the problem has a solution — change the analyses so they estimate the maximum allowable reduction in lockdown that keeps Rt bounded at a safe distance below 1, instead of forecasting Covid-19 deaths.
“Nonetheless, I still think the problem has a solution — change the analyses so they estimate the maximum allowable reduction in lockdown that keeps Rt bounded at a safe distance below 1, instead of forecasting Covid-19 deaths.”
Makes sense to me!
> change the analyses so they estimate the maximum allowable reduction in lockdown that keeps Rt bounded at a safe distance below 1, instead of forecasting Covid-19 deaths.
Makes sense to me as well.
Nonetheless, I predict it would be mostly be ignored in large swaths of the country. Presumably, the guidelines operated from a similar principle, and they are effectively being ignored in much of the country.
That would provide some useful information as it would give a relative idea of which areas could let up more and which areas should be more careful. It could help you decide which areas should go first.
To add to prior comments, there is uncertainty everywhere you look. For instance, the *actual* amount of the lockdown is uncertain because the choice variable is the intended lockdown reduction, but actual reduction is a noisy function of the intended reduction. You may intend to reduce 20% but actually get 5% (because people still won’t go to theaters even if they are open) or 64.2214% because one wedding invites 300 guests.
So the results may be reduced to “we really, really don’t know what is going to happen.”
Which raises serious doubts as to the value of these models.
These models might even be harmful by making us think we know more than we do.
People keep thinking about these models in terms of “predicting what really will happen”
that’s not what they are, they’re “predicting what would happen if the control variables could be set to the given values”
If you have an autopilot and it says “if you move the ailerons to angle theta the airplane will roll at such and such a speed” it is not a failure of the model when the pilot pushes the stick over hard so that theta goes to 2x as large, and the airplane rolls 4x as fast as predicted.
The lack of distinguishing between model “predictions” and model “projections” is a theme that gets repeated over a variety of contexts.
Happens a lot from “skeptics” who try to hold climate models to unachievable standards.
Well, it depends on what you are comparing it to, no? On March 25 the IMHE model estimated US covid death toll to be about 70,000. At that point, there were 1260 deaths.
A March 11 poll of the US public however showed that only 12% of the public believed the death toll would exceed 10,000.
Meanwhile today the government covid taskforce is using a cubic fit.
So the IMHE clearly did (and is doing) a better job than those guys.
I think in the end everyone is using models, some models are worse than others, and I don’t think these ones are the worst.
Terry –
> the *actual* amount of the lockdown is uncertain because the choice variable is the intended lockdown reduction, but actual reduction is a noisy function of the intended reduction. You may intend to reduce 20% but actually get 5%
[..]
Which raises serious doubts as to the value of these models.
+++++
I don’t really think the one follows from the other. A lack of follow-through isn’t a function of the models value – its a function of people’s behavior.
I’d guess that a model that informs on how much mobility would impact infection rates would similarly be ignored by much of the country. It would get politicized into an “us” fighting for freedom vs. “them” trying to lock us down.
Terry (and maybe Daniel and Zhou),
Agreed, but Google mobility data are collected in near real time, so they might used to check in real time how much mobility rises as lockdowns are eased, and to prompt stricter restrictions if mobility rises too much or allow looser restrictions if mobility rises less than expected. An imperfect measuring tape, but a measuring tape nonetheless.
I agree that overconfident modeling can be worse than nothing, but as Zhou notes, what is the alternative perspective? If the alternative is people claiming Covid-19 is no worse than seasonal flu or people arguing that cases won’t rebound much, then showing decision makers how much (and how rapidly) deaths could increase is I think very helpful.
Also, I think two great contributions of model-based analyses are:
1. In a different world with a slightly different disease, maybe the widespread social restrictions would be overkill and all we’d have to do to stop Covid-19 is to stop holding large group events and maybe close schools. The Flaxman et al. results suggest strongly that stopping large group events and closing schools is insufficient because the R-effective of Covid-19 is too high and the proportional effects of these interventions too small. Valuable information.
2. Helping to explain how, even if deaths continue to drop for a while after restrictions are eased, this cannot be taken as good evidence that the lifting of restrictions is safe. Instead, the decline can turn around and become a large increase.
If lockdowns are reduced and deaths continue to drop, there will be a strong (!) impulse for politicians and others to claim, “We solved it! We won against Covid-19! Restrictions are not needed!” But this ignores that there is a long delay between the development of new cases and deaths, which means that deaths can initially decrease after a lockdown lifting, creating a false impression of success, but then rise precipitously. Models help demonstrate this.
I agree, in my opinion the value of the dynamics models is *specifically* as a *qualitative* illustration of the sorts of behaviors the system is expected to have. Showing how lifting restrictions can lead strangely to a temporary reduction in cases, followed by a precipitous rise (due to the delay in ascertainment etc) is an excellent use of these tools.
That’s why I like the tool Carlos linked to a few days ago https://analytics-tools.shinyapps.io/covid19simulator07/
Thanks!! Hadn’t seen that one.
More Anonymous,
> I agree that overconfident modeling can be worse than nothing, but as Zhou notes, what is the alternative perspective? If the alternative is people claiming Covid-19 is no worse than seasonal flu or people arguing that cases won’t rebound much, then showing decision makers how much (and how rapidly) deaths could increase is I think very helpful.
Something to consider: This model may be over-estimating deaths substantially because it is applying a uniform IFR (PDF of N[1,0.1]) for ALL the population. in practical terms, this means a healthy person age 20 is just as likely to die from COVID-19 as a morbid person age 80.
But clinical data does not seem to support this assumption — people age 0-49 have an IFR of ~0.05% or lower (for age 0-30 its ~0.005% and all IFR may be even lower given uncounted asymptomatic/paucisymptomatic infections). Yet the authors do not explain why their uniform IFR is reasonable despite the massive variance in IFR by age (per their own Report 9).
This over-estimating deaths, if excessive enough, could lead to an over-reaction in terms of shutdowns, etc.
The only information I could find for them stratifying by age are in Report 13: Section 8.1, Paragraph 3 and the statement ” ifr_m is population averaged over the age structure of a given country.” I did that weighted averaging myself (see above post) and it is clear that the elderly ages skew the mean IFR ~24 fold higher for than its value weighted for age 0-49 only. That would mean the model could over-predict deaths age 0-49 by an order-of-magnitude.
Given the above, their using (and not justifying thoroughly) a uniform IFR does not make sense to me given it being crucial to predicted deaths. Maybe I’m missing something obvious?
Twain –
Something else to consider:
> Black Americans represent just 13.4% of the American population, according to the US Census Bureau, but account for more than half of all Covid-19 cases and almost 60% of deaths, the study found.
https://www.google.com/amp/s/amp.cnn.com/cnn/2020/05/05/health/coronavirus-african-americans-study/index.html
Two big pieces that get lost in the clamor from openists: (1) the magnitude of impact on the heroes on the front lines and (2) the disparate impact in association with SES and ethnicity/race.
Wanting to “open” is certainly understandable, but the racial implications are disturbing.
The question should be asked whether those implications as implicitly racist. I would have to think that if the disparities ran the other way, the people currently formulating and implementing policies would have an altered perspective.
This is one of the problems when the legislature comprises a vastly different demographic profile than the American public.
Wow. Definitely something that needs to be considered.
Joshua,
Your statistic further highlights why using a uniform IFR could be misleading — if a specific demographic (minorities, HCWs, LTCFs residents, for example) has a disproportionately higher IFR, the uniform IFR could hide this fact (if their proportion relative to total population is small).
Not arguing yes/no for opening or not — just noting how assuming uniform IFR can unintentionally skew results.
Twain –
I agree. This is part of the reason why I said that extrapolating from Santa Clara data, even if those data were representative of the Santa Clara population (which I think is questionable) violate fundamental scientific principles.
How highly qualified researched could try to extrapolate a broadly applied fatality rate from data which are distinctly non-representative in terms of ethnicity and SES continues to boggle my mind.
> How highly qualified researched could try to extrapolate a broadly applied fatality rate from data which are distinctly non-representative in terms of ethnicity and SES continues to boggle my mind.
I’m not sure. But it certainly can be frustrating.
Twain and Joshua,
I’m running out of time for more discussion here, but you may be interested to know that some approaches to infectious disease modelling have the relevant property that the following two models return the same case and death counts
* Model A: Each person is assigned their own reproductive number, IFR, and generation time distribution, for example based on age and other characteristics.
* Model B: Each person is assigned the same reproductive number, IFR, and generation time distribution, and the parameters used are appropriately-formed averages of parameters from model A.
For this property to hold, iirc it is generally necessary for the population to mix homogenously, which is dubious but can be a reasonable approximation, and better perhaps than trying to guess IFRs, generation time distributions, and contacts rates for all individuals.
An especially clear explanation of this property for the reproductive number and generation time distribution can be found in the methods section of
Fraser. Estimating Individual and Household Reproduction Numbers in an Emerging Epidemic. PlosONE. 2007. doi: 10.1371/journal.pone.0000758
I think the Vollmer et al. and Flaxman et al. models have this property, though I didn’t check carefully.
The property would be what you are missing, though it is far from obvious!
Also, I’m not sure how you arrive at the conclusion that overestimating the IFR would lead to greatly overestimating forecasted deaths, rather than underestimating forecasted deaths or leaving them about the same. The relationship may be more complicated.
Oh, and I agree absolutely that differences in IFR with age and other characteristics are usually important to keep in mind, for example with the Santa Clara study or when considering disease impact within population subgroups at elevated risks.
More Anonymous,
Thank you for clarifying!
> For this property to hold, iirc it is generally necessary for the population to mix homogenously, which is dubious but can be a reasonable approximation
For this case, I think it falls into the more “dubious” (although I’d say “less accurate” personally) category.
For COVID-19, those with the high IFR are oftened sequestered from the rest of the population by their old age or morbidity. Consider the elderly as an example. They are far less mobile and active that the rest of the population — many live in LTCFs and/or not physically able to move much. As a result, they are unlikely to mix homogeneously with the population. We can bring infections and death to them, but the inverse not so much.
Second, I don’t think a uniform mean IFR is reasonable when there is very high variance (order-of-magnitude for this case) or skewing in its value across groups; perhaps using the median is better if a uniform value is necessary to make the problem tractable computationally (although IMO that isn’t the care here; but that’s just intuition).
But if the authors think using mean IFR is reasonable, that could be fine — so long as they make very clear why so that others can judge it themselves.
More anonymous –
Thanks for that informative comment.
> For this property to hold, iirc it is generally necessary for the population to mix homogenously, which is dubious but can be a reasonable approximation, and better perhaps than trying to guess IFRs, generation time distributions, and contacts rates for all individuals.
Interesting. I like to think that the reason why people use an aggregated IFR is because of what you say. But I’m somewhat reluctant to just take that at face value (I’m not suggesting you implied that I should) .
That is especially true when the authors of the Santa Clara paper say something line “COVID is basically like the seasons flu” when as far as I can tell they are effectively comparing a CFR for the flu with an IFR for COVID (I would be happy to be corrected on that).
> Also, I’m not sure how you arrive at the conclusion that overestimating the IFR would lead to greatly overestimating forecasted deaths, rather than underestimating forecasted deaths or leaving them about the same. The relationship may be more complicated.
Yah. I had the same question.
>>when as far as I can tell they are effectively comparing a CFR for the flu with an IFR for COVID
Well, I don’t think it’s quite that simple. The flu case numbers are estimated. And the flu *deaths* are *also* estimates.
It might be a symptomatic “case” fatality ratio rather than an all-infections ratio (I don’t know), but it’s not a “crude” CFR the same way as the early COVID numbers were calculated (just dividing observed deaths by confirmed cases).
I think the comparison of COVID to seasonal flu is incorrect, but not because of that – more because of the lack of prior exposure and vaccination, and (probably) a somewhat-higher IFR.
confused –
> It might be a symptomatic “case” fatality ratio rather than an all-infections ratio (I don’t know), but it’s not a “crude” CFR the same way as the early COVID numbers were calculated (just dividing observed deaths by confirmed cases).
I don’t know either. But my impression is that the “infections” as reflected in IFR for the flu may well be an underestimate – as it is my surmise that tons of people with the flu never get to the doctor. So if you’re comparing an IFR for the flu with people who have been identified as symptomatic (with or without tests confirming a “case”) to an IFR for COVID using numbers extrapolated from broad-based serolgical testing, then it approaches comparing a CFR to an IFR. That’s my impression, anyway, I’d be happy to be shown that I’m mistaken about that.
And more recently I’m not seeing much anymore, quantification of the IFR for COVID as being dividing deaths by confirmed cases.
It’s definitely true that many/most people with the flu never see a doctor for it, but the CDC tries to adjust for that in their flu burden estimates. (And also for the fact that many people who die with flu as a contributing cause of death don’t have it listed on their death certificates.)
https://www.cdc.gov/flu/about/burden/how-cdc-estimates.htm
It’s a CFR in the sense that it doesn’t include asymptomatic cases, but it does try to include “unnoticed” cases who never see a doctor. The CDC provides estimated illnesses (symptomatic cases), doctor visits, hospitalizations, and deaths. Dividing deaths by illnesses seems to be the source of the 0.1%, 0.12%, etc. numbers people throw around for seasonal flu.
https://www.cdc.gov/flu/about/burden/2017-2018.htm
61 million illnesses and 61,000 deaths estimated for 2017-2018 is 0.135%.
And 2017-2018 was unusually bad.
Flu vs. COVID is also not a great comparison since we have a vaccine for flu protecting some of the population, and we don’t know how much our various mitigation measures are affecting the COVID results. (Can’t really compare between states or nations doing more vs. less aggressive measures yet, since there are too many other factors, density, pre-existing social contact patterns, time the outbreak started – which we probably don’t know most places due to lack of testing early on, etc.)
>>And more recently I’m not seeing much anymore, quantification of the IFR for COVID as being dividing deaths by confirmed cases.
Yeah, I was talking about the estimates in February and early March, before there were any serology test results, and when some people were saying there were few-to-no asymptomatic cases.
I wrote a longer comment that got put in moderation since I linked to the CDC flu burden pages. It’s a CFR in the sense that they are estimating only symptomatic illnesses, not all infections; but what is being estimated is total illnesses, not just those seen by a doctor.
(And the deaths number for flu is estimated too. So it’s not really apples-to-apples anyway.)
confused –
Good info here on this question:
https://blogs.scientificamerican.com/observations/comparing-covid-19-deaths-to-flu-deaths-is-like-comparing-apples-to-oranges/
Joshua,
I agree it’s not apples to apples to compare seasonal flu with SARS-CoV-2, but it’s apple-ish enough for a decent comparison. And if we’re going to compare apples and oranges, which people are going to do, then we might as well try to do it right. This finance-industry guy took a good stab at it. I’d love to hear what everyone thinks of this approach — is it misleading? provocative? tacitly ideological?
https://finance.yahoo.com/news/covid-19-mainly-kills-old-183320903.html
That article seems pretty reasonable, from my non-expert perspective: the differential mortality of the old isn’t at all unexpected, and it points out how 1918-19 was quite different (and even 2009-10; though there were few deaths overall, the age curve was quite different).
The really interesting/odd bit about COVID is that it (thankfully) doesn’t have a mortality spike at the youngest ages.
The only thing I would complain about is the statement “That number [750,000] may seem improbably high, but it’s far from a worst-case scenario in which the disease spreads unchecked (in which case millions would likely die)”.
IMO, “likely” is far too strong here. Having “millions” of deaths (say greater than 1.5 million) seems very unlikely at this point even with unchecked spread; I doubt NYC’s implied IFR from its serology studies can be extrapolated to the rest of the country.
confused —
Thanks for reading it and your opinion on it.
Yeah, i guess you can always say that “millions would likely die” if you don’t put a timeframe on it.
Elon Musk was on Joe Rogan’s podcast yesterday discussing the mortality rate from coronavirus. It was not a very informative or insightful discussion and was pretty lame imo. I found it irresponsible that Elon, downplaying the mortality risk, by arguing that deaths are being counted as COVID when they aren’t really COVID (kind of a conspiratorial POV) and did not even bring up the fact that you can easily see the objective jump in all-cause deaths (where labeling “COVID” or not is irrelevant) in many places, especially NYC.
Elon did call for good data though so at least he is aware of the dearth. And he did bring up that it is killing the weakest segments of the population, which brings me back to the paper below which I find very compelling and well-done.
https://www.medrxiv.org/content/10.1101/2020.04.15.20067074v2
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> Quoting from news release >>>>>>
Seljak says that getting COVID-19 doubles your chance of dying this year.
“If you want to know what are the chances of dying from COVID-19 if you get infected, we observed that a very simple answer seems to fit a lot of data: It is the same as the chance of you dying over the next 12 months from normal causes,” said Seljak.
Current uncertainties can push this number down to 10 months or up to 20 months, he added. His team discovered that this simple relation holds not only for the overall fatality rate, but also for the age-stratified fatality rate, and it agrees with the data both in Italy and in the U.S.
“Our observation suggests COVID-19 kills the weakest segments of the population,” Seljak said.
Joshua and Twain,
Thanks for your comments and links!
The main point I’m trying to add about the Imperial College of London report (Vollmer et al.) is that many of its findings are probably incorrect because projected Rts and 95% CIs are near the critical threshold of 1, which is a region at which small violations of modeling assumptions can produce large changes in foretasted cases and deaths. If When Rt is near 1, forecasts become sensitive to small assumption violations for both simple and more realistic models of infectious diseases. So a solution to the problem would not be to use a more realistic model, but instead may be to change the goal of the analysis — rather than projecting cases and deaths in various scenarios, estimate the maximum allowable increase in mobility that keeps Rt bounded at a safe distance below 1.
Further from Rt equals 1, some simple infectious disease models have nice properties that make them good approximations to more realistic analyses, for example as discussed much better than I could in the Bergstrom twitter comments linked by Joshua above.
These nice properties do not extend to the Santa Clara antibody study. (Which also didn’t use an infectious disease model.) I have similar complaints as you (Joshua and I think Twain) about that study, including regarding large IFR differences in age.
Lastly, my knowledge of infectious disease models is rusty, so if you are interested in pursuing this I’d say don’t trust me, trust a book. The book I’m most familiar with is
Diekmann, Heesterbeek, and Britton. Mathematical tools for understanding infectious disease dynamics. Princeton University Press, 2012.
It has whole chapters on issues of age structure, heterogeneity, spacial spread, etc. I think it even mentions somewhere that the nice averaging properties of some models hold if there is large heterogeneity in infectiousness, but not if there is large heterogeneity in both infectiousness and susceptibility. I like the book a lot but it’s probably very bad as an introduction to the subject.
I’m not sure what to recommend as a first introduction, but there are several lectures on youtube. I’d guess the MSRI one by Nicholas Jewell is probably excellent.
More Anonymous,
Thank you for sharing the textbook! I downloaded it and it seems like a really great resource.
After reading their Chapter 2, “Heterogeneity: The art of averaging,” it seems like the key assumption for using an “average” person to represent a heterogeneous population applies when ONLY infectivity varies — (e.g., susceptibility, mortality, etc., remain constant).
Quoting from the Section 2.1: “We conclude that differences in infectivity, while they do complicate the characterization of the probability of a minor outbreak, do not complicate the characterization of the expected final size.”
Quoting from Section 2.3: “In Section 2.1 we argued that, when individuals differ only in infectivity, one can in a sense, simply work with the `average’ individual.”
So it seems like using an “average” person when IFR skews with age (e.g., like with SARS-CoV-2) is not a valid assumption. But I’ll keep reading the textbook to make sure I’m not missing something else!
Twain — Those quotes you provide are out of context. Please note that the book does not say what you think.
The book doesnt really provide a list of facts that are applicable to all infectious disease models. Instead, it trains the reader in methods that the reader can apply to check which facts are true about a specific infectious disease model that the reader is studying.
So let’s do that here. Let’s start with the methods section of the Fraser paper (from PlosONE, cited above) which is closest to the model used by the Imperial College of London reports that are under discussion.
The Fraser paper shows how a model with an appropriately formed average reproductive number and generation time distribution returns the same incidence estimates as a model where reproductive numbers and generation time distributions differ across population groups, subject to various assumptions including homogenous mixture of the population.
So the question at hand is, “does this nice averaging property extend to infection fatality ratios (IFRs) too?”
To see that it does, consider the following proof sketch: First, set up the infectious disease model without considering IFR at all, but including all the groups with different reproductive numbers and generation time distributions that you want. Then for each group, split it into two subgroups based on potential outcomes: the first being people who if they get covid survive and the second being people who if they get covid die. Reproductive numbers and generation time distributions will differ between these subgroups because one can no longer infect others once one has died. Nonetheless, the homogenous mixture property continues to hold because, at least conditional on our original groups, membership in the potential outcome subgroups is independent of whether one gets covid or not. So, in answer to our question, the nice averaging model property does extend to IFR.
If you think there’s an error in this proof sketch let me know. It happens …maybe especially to me. But please think through the logic or math of the situation, rather than searching for quotes.
More Anonymous,
Apologies if it seemed like I was taking the quotes out of context — I should have prefaced that they conveyed my understanding of the chapter (which I read; not going to cherry-pick!).
It seems like we are discussing two separate topics.
I agree that you can average R across ages even if it varies. In terms of a compartmental SEIR Model, whether you use a population-weighted or population-stratified reproduction number, R, results in the same total infected population, I; the math is straightforward there.
But my question is this: Is it reasonable to apply a uniform, population-averaged IFR (usually mu in SEIR Models) to that infection population, I? The population of I depends on R, but mu does not; it’s a independent value measured empiralically to add a “Dead” compartment (and one-way sink from I) to the SEIR model. So if mu varies with age, it does so independent of R, and the averaging assumptions that work for R do not apply to mu.
More anonymous and Twain –
This Twitter thread goes a long way towards clarifying these questions – and is largely consistent with what more anonymous was saying:
https://mobile.twitter.com/CT_Bergstrom/status/1256828515057467393
And this article questions what Bergstrom says in that thread:
https://necpluribusimpar.net/lets-have-a-honest-debate-about-herd-immunity/
Joshua,
Thank you for sharing!
After reading the Op-Ed and reviewing the code for their SEIR+ Model, a few thoughts:
Bergstrom claims “Given that current estimates suggest roughly 0.5 percent to 1 percent of all infections are fatal, that means a lot of deaths.” As we’ve already discussed, it is not accurate to claim a uniform IFR for the whole population.
I do agree with his stance on herd-immunity in principle, though. But for SARS-CoV-2, it requires nuance — what if the 60-70% of the population we exposed are age 0-49 (which is plausible) where IFR is 0.05-0.001% (based on current data)? His argument would make much more sense if IFR was less varied and less skewed toward older age.
And SEIR+ Model, in terms of documentation and presentation, is excellent and transparent.
However, they still apply a uniform IFR (mu_I in their model) to all actors; I could not find the “age-specific interactions” that Bergstrom claims the model has. Perhaps I missed them or they are still developing them.
“As we’ve already discussed, it is not accurate to claim a uniform IFR for the whole population.”
Nor would it be reasonable to claim that a nonuniform IFR would be at the 0.5% end of the range.
“I could not find the “age-specific interactions” that Bergstrom claims the model has. Perhaps I missed them or they are still developing them.”
Occam’s razor would suggest that Bergstrom has no motivation to lie about something that could so easily be refuted by their own documentation or source code. Perhaps you need to dig deeper.
dhogaza,
I read their entire README and only found “Heterogeneous populations: Nodes can be assigned different values for a given parameter by passing a list of values (with length = number of nodes) for that parameter in the constructor.” No explicit examples or explaining of age-stratified values, etc.
Presumably the quoted statement means one can introduce age-stratified mu_I (IFR) into the model. I could not find examples doing this, though; so I’ll have to test it myself at some point.
I think this is a very sensible model: complex (includes some epidemiological mechanistic modelling & various heirarchical levels) but pragmatic: fits practically in Stan (allowing for full Bayesian inference and model checking: I’m going to assume!). My question is: how confident can we be regarding the effect sizes attributed to movement, given that presumably various other changes to personal habits and social norms presumably also came into play at the same time: changes that presumably hold even when movement begins to pick up again?
{Disclosure: I also know Seth & many of the other co-authors}
Aren’t the credible intervals a bit narrow (within the range of observed data)?
The data covers ~2 months (60 days), and present 95% credible intervals – so we’d expect on the order of 3 outliers, and yet I eye-balled ~20 points outside of the interval in the first panel (Emilia-Romagna).
I’ll admit this is based on only a cursory look at the plots attached above, rather than a thorough reading of the paper – so apologies if I’m missing something obvious.
A few thoughts:
– A fourth scenario with 100% of pre-lockdown mobility (while implausible) would provide useful context for the impacts of individual behaviors, as well as a better sense of the true downside risk, which might help drive better-considered behavior by indivudals.
– I’m surprised that the summary calls out watching mobility and virus transmission rates, without specifically mentioning watching hospital loads. The key innovation I took from the March 16 ICL paper was using weekly new ICU admission count as on/off trigger for non-pharmaceutical interventions. I’ve had no success gathering that data in any region, but NY state has been publishing something that’s close enough — the 3-day average of daily new hospital admissions for COVID. This measure has almost perfectly predicted deaths, with 5 days’ lead time. I would’ve expected a similar measure to be part of the recommended monitoring.
NY State hospitalization/deaths plotted here:
https://i.redd.it/btg29alkqww41.png
The IHME released an update to their model yesterday: http://www.healthdata.org/covid/updates
Using now a better model and taking into account the relaxation of mitigation measures their forecast for US deaths has almost doubled to 134k (95% uncertainty range 95k-243k).
My charts of the evolution of forecasts across time can be found at ungil.com/ihme.html
Why do the red bands explode in some graphs and not in others? Herd immunity?
A very good question, answered by ‘More Anonymous’ above.
Some news from Italy.
There is another important model using Italian data. Before moving to a gradual lifting of lockdown measurements, Italian Government assessed the results of a model managed by ISS (Istituto Superiore di Sanita’) and in particular by the Bruno Kessler foundation (Stefano Merler is the main author).
A 22-page long report has been widely circulated (unfortunately it is in Italian). It models the number of critical cases (deaths plus patients in ICU) assuming an IFR=0.657%. The model is applied separately for each of the 20 Italian regions and eventually aggregate results were provided. The most shocking datum was an expected number of approx. 150000 critical cases by the first week of June in case of a complete removal of the lockdown (note that the overall number of beds in Italian ICUs is approx. 10000). This finding was harshly criticized by the ‘it is just a bad flu and now we need to re-start’ party. Their main objection was … we have reached a max. of 4500 COVID patients in ICUs (they forgot the deaths) after 3/4 months from the start of the outbreak (nobody knows the exact date of the first real Italian case) how can we get 150000 cases in just 1 month? To me the point is that currently there are 100000 confirmed active cases (removing deaths and recovered) in Italy pus probably others, let’s say 500000, unregistered cases not subjected to any quarantine. Now the impact of an infectious disease is completely different when it starts from scratch vs when it starts from a basis of 500000 infected. In my opinion that’s the reason why the results of the model are plausible.
As far as I know this work has not been published yet in any peer reviewed journal but I would expect it will be released soon.
Very interesting, thank you. I was not aware of that report. I found it here: https://drive.google.com/file/d/1vCdvsnB84P-K50kTnXbgzZfj4IqoJ-78/view
Carlos,
yes that’s the document I’m referring too. Unfortunately it is in Italian
L’italiano é molto facile e divertente! (That was the slogan for an Italian language course on tape back in the day…)
I am kind of surprised people in Italy with political relevance are taking the “just a bad flu” position.
A lot of people in the US think that way, but mostly in states that haven’t had bad outbreaks. (I don’t personally know anyone who has had COVID*, and the friends-of-friends I’ve heard about are all in other states.) And I think the attitude is also driven by just how different life is in the “plains and mountains” states versus NYC or Detroit; the bad experiences of those cities don’t really seem “relevant” to many people. There’s a huge urban-rural divide. Does Italy have the same thing?
*more accurately, anyone who knows they have had it; given the apparent number of undetected mild-to-asymptomatic cases, I probably do know someone who had it and didn’t know.
when I used the expression ‘it is just a bad flu and now we need to re-start party’ I have simplified a little bit the complexity of the debate in Italy. In addition ‘party’ does not mean necessary a specific political party. In any case until mid March some politicians / influencers belonging to different political sides backed the ‘it is just a bad flu’ position suggesting that people are dying ‘with’ COVID but not necessary due to COVID. Now they tend to support the idea that the worst is over and we need to re-open almost all the activities.
A couple plot things,
Figure 9 says three plots and there are only two.
I think get rid of region colors for Figure 6, do it in one plot, use colors to indicate R0 vs. Rt at May 1st (doesn’t look like there will be confusing overlap). If the regions are important, then arrange the names by region.
It’s difficult to find differences in these two things cause the y-axes are sorted differently. Also I guess it’s possible the differences are different than the differences of the marginals (if that was the case then a different plot would be in order alltogether).
With all the other plots, does using the same scale just look bad? I’m tempted to compare them, but maybe that’s a bad idea and I should just think of them as individual plots anyway.
I just saw this article: https://www.bbc.com/news/uk-politics-52553229; “Coronavirus: Prof Neil Ferguson quits government role after ‘undermining’ lockdown”
A crazy development amidst everything else.
This may be of interest – a critique of the model (possibly not entirely objective)
https://lockdownsceptics.org/code-review-of-fergusons-model/