Seth Flaxman et al. have an updated version of their model of coronavirus progression. Flaxman writes:
Countries with successful control strategies (for example, Greece) never got above small numbers thanks to early, drastic action. Or put another way: if we did China and showed % of population infected (or death rate), we’d erroneously conclude that this covid-19 thing really isn’t anything to worry about!
Here’s their technical report, where they write:
Following the emergence of a novel coronavirus (SARS-CoV-2) and its spread outside of China, Europe has experienced large epidemics. In response, many European countries have implemented unprecedented non-pharmaceutical interventions including case isolation, the closure of schools and universities, banning of mass gatherings and/or public events, and most recently, wide-scale social distancing including local and national lockdowns.
In this technical update, we extend a semi-mechanistic Bayesian hierarchical model that infers the impact of these interventions and estimates the number of infections over time. Our methods assume that changes in the reproductive number – a measure of transmission – are an immediate response to these interventions being implemented rather than broader gradual changes in behaviour. Our model estimates these changes by calculating backwards from temporal data on observed to estimate the number of infections and rate of transmission that occurred several weeks prior, allowing for a probabilistic time lag between infection and death.
In this update we extend our original model to include (a) population saturation effects, (b) prior uncertainty on the infection fatality ratio, (c) a more balanced prior on intervention effects and (d) partial pooling of the lockdown intervention covariate. We also (e) included another 3 countries (Greece, the Netherlands and Portugal).
We estimated parameters jointly for all M=14 countries in a single hierarchical model. Inference is performed in the probabilistic programming language Stan using an adaptive Hamiltonian Monte Carlo (HMC) sampler.
And here’s the website with their latest numbers.
Everything’s all out there so you can take a look at their assumptions, play with the model, etc.
Full disclosure: I know Flaxman, have worked with him on other problems, and have talked with him about this model. Some Stan colleagues have helped with the coding, but I have not looked at the details of the model myself. Of course I like the partial pooling and the flexibility of the modeling, but, when interpreting the results, much will depend on the specifics of the model and also data quality.
It’s hard to accept that school closures will have such a limited effect on transmissibility.
Howard –
A discussion here among modelers about COVID modeling, where they discuss the impact of schools closing at about 8 minutes in. (“The link for the pod says “Your intuitions about the virus are useless”)
https://meaningoflife.tv/videos/42714?in=47:31
They indicate that it is fairly well accepted among epidemiologists that closing schools beyond 8 days doesn’t limit spread – they acknowledge the counterintuitive aspect of that conclusion and that they have no explanation.
The only caveat they offer is that there’s no data on what happens with school closures along with the other interventions that are currently taking place.
Also hard to understand is their conclusion of the lack of effect from time of intervention. WTF?
Why do you expect an effect?
I suspect this is not sufficiently well thought out. In most cases, where they’re just closing schools alone, after a week or two you’d get adaptation by the families to start sending the kids to daycare etc so the parents can get back to work. that probably takes about 8 days.
But in the context of the parents are home and the kids are home and everyone is sheltering in place, and then you suddenly just reopen schools without reopening work… you can bet for sure there’s going to be a lot of transmission. So I think this is a case of taking a complex thing and treating it as a linear function instead of nonlinear interactions.
Yup — when the “KISS” principle can get you off in a fairy tale world.
Looks like these three are all philosophers. Do any of them actually do modeling?
One is a pretty well-known climate modeler.
Wrong: Nothing on their home pages says they have anything to do with climate. I also searched google scholar and found no climate papers for any of them. I think you have mistaken identity.
anotheranon –
> Wrong:
I suggest that you’re just a tad over-confident.
Listen to the podcast – just the first part when they introduce themselves.
https://philosophy.usf.edu/faculty/ewinsberg/
https://philsci-archive.pitt.edu/16065/
https://andthentheresphysics.wordpress.com/2019/06/11/extreme-weather-event-attribution/
anotheranon –
> Wrong:
Links in a comment that’s in moderation…should be out soon.
But perhaps I should have been more precise. One is fairly well known in climate science circles, and does some modeling in that context.
My bad. Sorry. I thought you were talking about Flaxman, Mishra, and Gandy. They are the lead authors on the updated study and seem to be primarily responsible for the modeling.
Yah. That occurred to me later. No problem.
All three are modelers. Experts in statistics and machine learning methods. And the fourth author (Unwin) is an epidemiologist/modeler who shares the last name of a highly-regarded quantitative geographer (daughter or granddaughter?).
So don’t be confused by PhD or DPhil behind the name. It just indicates the ultimate level of academic expertise in their discipline.
In Sweden, schools and child care for children up to grade 9 have been open throughout. There hasn’t been any formal study on schools AFAIK, but the flattening of the curve would not have happened if schools were a major vector of transmission.
Here is the local authorities’ more classical model of Rt. (The testing regime changed significantly around 15 March, moving from track&trace to testing hospitalized patients and health care personnel.)
https://www.folkhalsomyndigheten.se/contentassets/4b4dd8c7e15d48d2be744248794d1438/sweden-estimate-of-the-effective-reproduction-number.pdf
In the Netherlands it was reported from contact tracing that kids who got covid tended to get it much more from older age groups. Rather than the other way around.
Also much lower seroprevalence in kids (1% / 4%). Finally no change in age distribution of disease after school closures started.
Do you mean from older kids, or from adults?
Presumably if there really is something protecting the majority of children not only from serious illness, but even from being significant carriers, it might be valuable to know at what age that stops applying… and why it happens.
I don’t know at what point this study was done, but if they closed schools before we had much school transmission, then obviously kids wouldn’t have had much exposure to other kids, so if they got it, it’d be probably from the adults that take care of them.
Only if you had an extended period where kids were both exposed to other kids, and to other adults, could you compare the two mechanisms.
What I’d like to see is an inter-country analysis of the effect of a strong contact tracing and quarantine regime, would be nice if that correlated with where on these error bars a country ends up.
Related:
> We describe the epidemiology of a coronavirus disease (COVID-19) outbreak in a call center in South Korea. We obtained information on demographic characteristics by using standardized epidemiologic investigation forms. We performed descriptive analyses and reported the results as frequencies and proportions for categoric variables. Of 1,143 persons who were tested for COVID-19, a total of 97 (8.5%, 95% CI 7.0%–10.3%) had confirmed cases. Of these, 94 were working in an 11th-floor call center with 216 employees, translating to an attack rate of 43.5% (95% CI 36.9%–50.4%). The household secondary attack rate among symptomatic case-patients was 16.2% (95% CI 11.6%– 22.0%). Of the 97 persons with confirmed COVID-19, only 4 (1.9%) remained asymptomatic within 14 days of quarantine, and none of their household contacts acquired secondary infections. Extensive contact tracing, testing all contacts, and early quarantine blocked further transmission and might be effective for containing rapid outbreaks in crowded work settings.
https://wwwnc.cdc.gov/eid/article/26/8/20-1274_article
“Extensive contact tracing, testing all contacts, and early quarantine blocked further transmission and might be effective for containing rapid outbreaks in crowded work settings.”
Makes a lot of sense to me!
The revised Santa Clara study has been released.
https://www.medrxiv.org/content/10.1101/2020.04.14.20062463v2.full.pdf+html
Joseph:
I took a quick look and here’s what I noticed:
1. The summary conclusion, “The estimated population prevalence of SARS-CoV-2 antibodies in Santa Clara County implies that the infection may be much more widespread than indicated by the number of confirmed cases,” is much more moderate. Indeed, given that there had been no widespread testing program, it would’ve been surprising if the infection rate was not much more widespread than indicated by the number of confirmed cases. Still, it’s good to get data.
2. They added more tests of known samples. Before, their reported specificity was 399/401; now it’s 3308/3324. If you’re willing to treat these as independent samples with a common probability, then this is good evidence that the specificity is more than 99.2%. I can do the full Bayesian analysis to be sure, but, roughly, under the assumption of independent sampling, we can now say with confidence that the true infection rate was more than 0.5%. (They report a lower bound for the 95% confidence interval of 0.7%, which seems too high, but I haven’t accounted for the sensitivity yet in this quick calculation. Anyway, 0.5% or 0.7% is not so different.)
3. The section on recruitment says, “We posted our advertisements targeting two populations: ads aimed at a representative population of the county by zip code, and specially targeted ads to balance our sample for under-represented zip codes.” This description seems incomplete, as it does not mention the email sent by the last author’s wife to a listserv for parents at a Los Altos middle school. This email is mentioned in the appendix of the report, though.
4. They provide more details on the antibody tests. I don’t know anything about antibody tests; I’ll leave this to the experts.
5. On page 20 of their report, they given an incorrect response to the criticism that the data in their earlier report were consistent with zero true positives. They write, “suggestions that the prevalence estimates may plausibly include 0% are hard to reconcile with documented data from Santa Clara…” This misses the point. Nobody was claiming that the infection rate was truly zero! The claim was that the data were not sufficient to detect a nonzero infection rate. They’re making the usual confusion between evidence and truth. It does not help that they refer to concerns expressed by “several people” but do not cite any of these concerns. In academic work, or even online, you cite or link to people who disagree with you.
They also say, “for 0 true positives to be a possibility, one needs not only the sample prevalence to be less than (1 – specificity) . . . but also to have no false negatives (100% sensitivity).” I have no idea why they are saying this, as it makes no sense to me.
The most important part of their response, though, is the additional specificity data. I’m in no particular position to judge these data, but this is the real point. They also do a bootstrap computation, but that is neither here nor there. What’s important here is the data, not the specific method used to capture uncertainty (as long as the method is reasonable).
6. I remain suspicious of the weighting they used to match sample to population: the zip code thing bothers me because it is so noisy, and they didn’t adjust for age. But they now present all their unweighted numbers too, so the weighting is less of a concern.
7. They now share some information on symptoms. The previous version of the article said that they’d collected data on symptoms, but no information on symptoms were presented in that earlier report. Here’s what they found: among respondents who reported cough and fever in the past two months, 2% tested positive. Among respondents who did not report cough and fever in the past two months, only 1.3% tested positive. That’s 2% of 692 compared to 1.3% of 2638. That’s a difference of 0.007 with standard error sqrt(0.02*0.98/692 + 0.013*0.987/2638) = 0.006. OK, it’s a noisy estimate, but at least it goes in the right direction; it’s supportive of the hypothesis that the positive tests results represent a real signal.
Table 3 of their appendix gives more detail, showing that people reporting loss of smell and lost of taste were much more likely to test positive. Of the 60 people reporting loss of smell in the two weeks prior to the study, 13 tested positive. Of the 188 reporting loss of smell in the two months prior to the study, 21 tested positive. Subtracting, we find that of the 188 reporting loss of smell in the two months prior but not the two weeks prior, 8 tested positive. That’s interesting: 22% of the people with that symptom in the past two weeks tested positive, but only 4% tested positive among people who had the symptom in the previous two months but not the previous two weeks. That makes sense: I guess you have less antibodies if the infection has already passed through you. Or maybe those people with the symptoms one or two months ago didn’t have COVID-19, they just had the regular flu?
8. Still no data and no code.
Overall, the new report is stronger than the old, because it includes more data summaries and more evidence regarding the all-important specificity number.
I really don’t get why they don’t weight for age. In my experience with weighting population samples, age tends to be one of the more important factors. And although it doesn’t directly play into this here, we know prognosis with infection is greatly affected by age — if infections are rather rare among the elderly but they make up the large majority of the deaths, that’s worth knowing.
Jacob:
They say they didn’t weight for age because it would make their weights too noisy. But their weights are already too noisy! They could fix their problems using MRP. They know about MRP at Stanford, but that knowledge exists in the engineering school and the political science department, not in the medical school or the statistics department. So it makes sense that this research group wouldn’t know what to do about this. Survey research is difficult, but people who don’t do survey research don’t always recognize this difficulty, and they end up using bad methods because (a) they don’t know better, and (b) they don’t know who to ask.
Fantastic work.
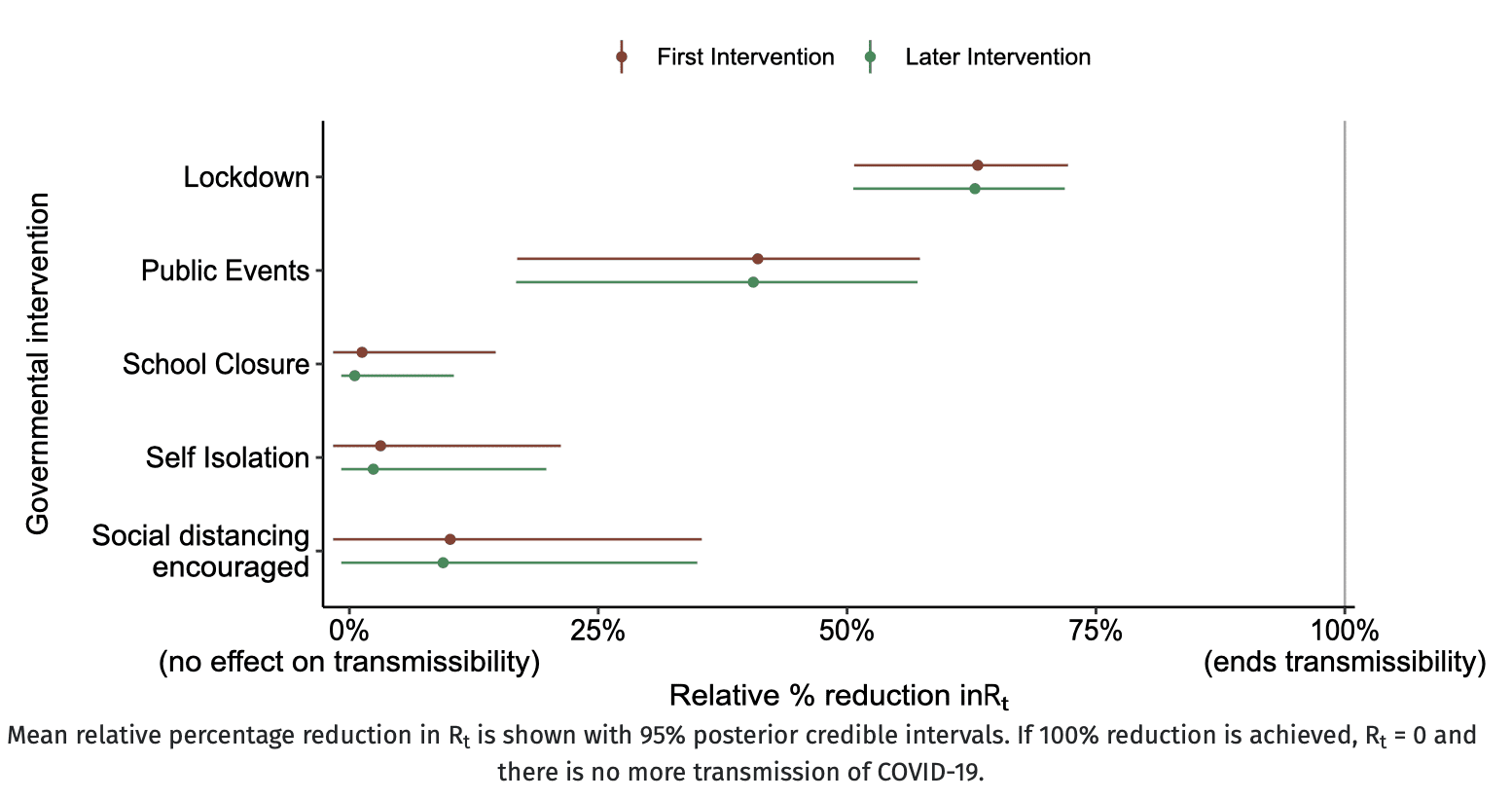
Unfortunately, with initial R-effective / R_t values generally >3.5, the results suggest lockdowns are the only societal measures capable of reducing R-effective to below 1. Actually, it looks like lockdowns are the only measures capable of reducing R-effective to 3.5 most places but near 2 in Greece and Sweden?
Also, because the benefits of several of the interventions overlap considerably (lockdowns and stopping public events, for example), the fact that similar estimates are obtained for “first intervention” and “later intervention” suggests some problem with the model or maybe insufficient variability in the dataset (lockdown will rarely if ever be a later intervention).
But overall, this work is excellent because it is so on point for the kind of information that matters right now.
“Far better an approximate answer to the right question, which is often vague, than the exact answer to the wrong question, which can always be made precise.” – Tukey
Hmm, some text got cut from my above comment. Trying again:
Fantastic work.
Unfortunately, with initial R-effective (Rt) values generally greater than 3.5, the results suggest lockdowns are the only societal measures capable of reducing R-effective to below 1. Actually, it looks like lockdowns are the only measures capable of reducing R-effective to less than 2 in most countries, even. I’d be happy to be corrected if I’m misinterpreting, especially since this is bad news.
The wide range of initial R-effectives is strange, however. Why greater than 3.5 most places but near 2 in Greece and Sweden?
Also, because the benefits of several of the interventions overlap considerably (lockdowns and stopping public events, for example), the fact that similar estimates are obtained for “first intervention” and “later intervention” suggests some problem with the model or maybe insufficient variability in the dataset (lockdown will rarely if ever be a later intervention).
But overall, this work is excellent because it is so on point for the kind of information that matters right now.
“Far better an approximate answer to the right question, which is often vague, than the exact answer to the wrong question, which can always be made precise.” – Tukey
Does it account for the number of tests done when fitting to the data? After a quick look, it seems no.
Does it account for giving people HBOT instead of putting them on ventilators?
I think that it is a great piece a work. The only problem I see is the assumption regarding the infection fatality rate. The 1% IFR in China is reasonable, the added uncertainty of 0.1% is a bit small but reasonable too, but just adjusting the IFR for the age structure before applying it to every country of Europe seems quite strong. The between country heterogeneity in total infected (https://mrc-ide.github.io/covid19estimates/#/total-infected) could at least partially be explained by differences in mortality.
Nevertheless the results are quite convincing.
What happens to Covid if there is no more transmission (see graph note)
Straw poll. What NPIs would readers include in their models. Are their any they think would be impactful and relatively low cost, even if they would need,a little organizing and detail. I am thinking about things for verticals or specific activities and those for general application. Tx!