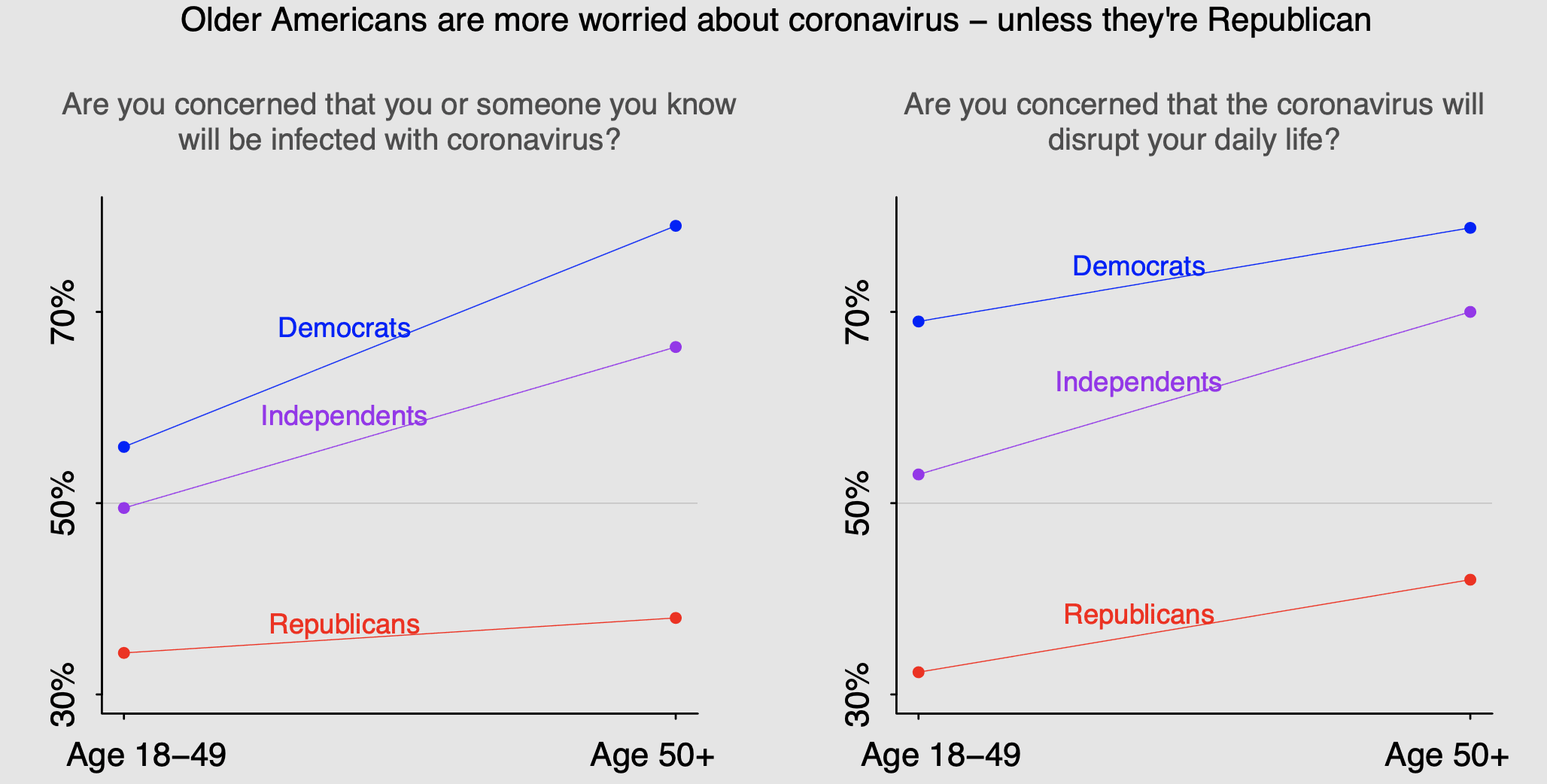
Philip Greengard points us to the above-titled news article by Philip Bump.
The article was just fine, a reminder of modern-day political polarization. The only thing that bothered me were the graphs. I redrew them above. Here were the original versions:


I see a few problems with these graphs. First, the information is duplicated because the percentages all add up to 99% or 100%. Second, the patterns are super hard to follow because your eye jumps up and down between the yes and no percentages. Third, the x-axis is multiplexed so it’s hard to compare age groups within parties. Fourth, nothing is really done with the color scheme. I think my redrawn version (it took me about a half hour in R; I guess Hadley could’ve done it better in 5 minutes) fixes these problems. I put age on the x-axis because it seems natural to go from young to old.
Once I did this, I thought it would be good to get some more discrimination on the age scale. An earlier graph in that news article showed age groups of 18-35, 35-49, 50-64, and 65+, so I clicked through to the survey report from Quinnipiac poll. But that left me even more baffled because I didn’t see the party x age breakdown in the report at all. Maybe I didn’t know where to look.
P.S. I’m kinda embarrassed to share my R code cos it’s so ugly, but in the interest of openness, here it is:
## https://www.washingtonpost.com/politics/2020/03/14/older-americans-are-more-worried-about-coronavirus-unless-theyre-republican/
y1 <- c(57, 45, 49, 50, 34, 65, 79, 21, 65, 33, 38, 62)
yes1 <- y1[seq(1,11,2)]
no1 <- y1[seq(2,12,2)]
p1 <- 100*yes1/(yes1 + no1)
y2 <- c(69, 31, 53, 47, 32, 67, 78, 21, 70, 30, 42, 58)
yes2 <- y2[seq(1,11,2)]
no2 <- y2[seq(2,12,2)]
p2 <- 100*yes2/(yes2 + no2)
pdf("coronapoll.pdf", height=4, width=8)
par(mfrow=c(1,2), oma=c(0,0,2,0), bg="gray90")
par(mar=c(2,3,3,2), mgp=c(1.5,.5,0), tck=-.01)
color <- c("blue", "purple", "red")
party <- c("Democrats", "Independents", "Republicans")
plot(c(0,1), c(30, 80), xlab="", ylab="", xaxt="n", yaxt="n", bty="l", type="n")
abline(50, 0, col="gray", lwd=.5)
mtext("Are you concerned that you or someone you know\nwill be infected with coronavirus?", line=1, side=3, cex=.9, col="gray30")
for (i in 1:3){
points(c(0,1), p1[c(i,i+3)], col=color[i], pch=20)
lines(c(0,1), p1[c(i,i+3)], col=color[i], lwd=.5)
text(.4, mean(p1[c(i,i+3)]) + 1, party[i], col=color[i], cex=.8)
}
axis(1, c(0, 1), c(" Age 18-49", "Age 50+ "))
axis(2, c(30, 50, 70), c("30%", "50%", "70%"))
plot(c(0,1), c(30, 80), xlab="", ylab="", xaxt="n", yaxt="n", bty="l", type="n")
abline(50, 0, col="gray", lwd=.5)
mtext("Are you concerned that the coronavirus will\ndisrupt your daily life?", line=1, side=3, cex=.9, col="gray30")
for (i in 1:3){
points(c(0,1), p2[c(i,i+3)], col=color[i], pch=20)
lines(c(0,1), p2[c(i,i+3)], col=color[i], lwd=.5)
text(.4, mean(p2[c(i,i+3)]) + 1, party[i], col=color[i], cex=.8)
}
axis(1, c(0, 1), c(" Age 18-49", "Age 50+ "))
axis(2, c(30, 50, 70), c("30%", "50%", "70%"))
mtext("Older Americans are more worried about coronavirus - unless they're Republican", line=1, side=3, cex=1, outer=TRUE)
dev.off()
And, yes, I know I'm violating some principles of good coding here. Also, the data are from my eyeballing of the graphs in that Washington Post article. They might be off by a percentage point here or there.
Though probably not available, it would be interesting to break this down by news source, especially Fox.
https://www.washingtonpost.com/lifestyle/media/rupert-murdoch-could-save-lives-by-forcing-fox-news-to-tell-the-truth-about-coronavirus–right-now/2020/03/11/72059f4c-63a7-11ea-acca-80c22bbee96f_story.html
Yes. Though it seems like party identification and media consumption are virtually collinear these days. This was already evident 10 years ago with attitudes towards the H1N1 flu vaccine: https://sites.hks.harvard.edu/fs/mbaum/documents/RedStateBlueStateFluState_JHPPL.pdf
Nice work! Just to answer your last question, I asked Quinnipiac for party/age data, which they provided.
Philip:
If they can send the data broken down by party and all 4 age categories, I can update the plot.
Just genuinely curious, what’s the difference (statistically?) between hard and super-hard? Is super-hard the same as or different from incredibly-hard? Or does super-hard mean very-hard? To my unprofessional ear this sounds like American young girl speak, but perhaps I’m obsessing over a trivial matter, in which case, feel free to ignore. BTW I love this blog.
Wonhoff:
Yes, “super hard” means “very hard.” I think of “super hard” as a bit harder than “very hard” but not as hard as “very hard.” I guess the use of these words varies by where you live and your social group; perhaps where I live, “super” is used as an adverb by people of all ages and sexes, but in your circles maybe it’s primarily used by girls and young women. I’m sure there’s lots of research on this; I remember many years ago reading this article, “Adverbs multiply adjectives,” by Norman Cliff. That particular article does not include “super” as one of its adverb choices, so maybe my use of that word is idiosyncratic; maybe it’s not standard English to use it in that way. BTW I love these unexpected comments.
Here’s some ggplot code to make the plot. I thought I’d whip it off in ten minutes or less but actually it took me about 35, the same as Andrew or a bit longer, and I had the advantage of being able to just copy Andrew’s numerical data: The ggplot defaults were OK but not great: too much space on each side of the points, colors reversed from blue = Dem, red = Rep, y-axis didn’t start at zero, questions needed line breaks specified, and I had to look up how to label the lines the way I wanted. The question order got switched around but I didn’t bother switching that, I think there’s an argument to be made for either order.
Even though I didn’t do it any faster than Andrew, I think this code is a lot clearer.
I used to be a research scientist and my code looked a lot more like Andrew’s. Now I’m a consultant and a lot more of my job consists of coding than it used to, plus I usually work on projects with one or two other people and we have to be able to read and modify each other’s code, so I’ve worked hard at improving my coding. I would still not hold it up as a model but I am waaaay better than I used to be. (I’d be interested in seeing what a really good coder will do here; please post your code if you have something clearer or better than this!).
The key to making good use of ggplot2 is: you want everything in one dataframe, with each point on its own line. It’s worth taking an extra minute or three, or ten, to figure out how to make that happen. In this case it was just an extra ten seconds to realize that I didn’t want to have one column that records percent for question 1, and another that records percent for question 2, but instead I want each question to have its own set of rows. But, as I mentioned above, it still took lots of tinkering to get it how I liked it. (Depending on the size of the graphics window you run this in, it might even need some more tinkering for you).
require(dplyr)
require(ggplot2)
y1 = c(57, 45, 49, 50, 34, 65, 79, 21, 65, 33, 38, 62)
y2 = c(69, 31, 53, 47, 32, 67, 78, 21, 70, 30, 42, 58)
age = c(rep("18-49",6), rep("50+", 6))
worried = rep(c(T,F),6)
party = rep(c("Democrat", "Republican", "Independent"),4)
q1 = "Percent somewhat or very concerned that\n they or someone they know will\ncontract the coronavirus"
q2 = "Percent somewhat or very concerned\nthat the coronavirus will disrupt their everyday life"
df_1 = data.frame(question = q1, Age = age, Party = party, worried = worried, Percent = y1)
df_2 = data.frame(question = q2, Age = age, Party = party, worried = worried, Percent = y2)
both = bind_rows(df_1, df_2, .id = "question_num" )
ggplot(both %>% filter(worried),
aes(x = Age, y = Percent, group = Party, color = Party)) +
geom_line() +
geom_text(data = both %>% filter(worried, Age == '18-49'),
aes(x = Age, y = Percent, label = Party),
nudge_y = -2) +
geom_point() +
scale_x_discrete(expand = c(0.3,0)) +
scale_y_continuous(expand = c(0, 0.6), limits = c(0,80)) +
scale_color_manual(values = c("blue", "purple", "red")) +
ylab("Percent concerned") +
xlab("Age group") +
theme(legend.position = "none") +
facet_wrap(~question)
Hmm, I thought wrapping that in ‘code’ tags would preserve the formatting and put it in a fixed-width font, but neither happened. Whaddyagonnado.
I’ve never been able to get it to work. For some reason it works for Andrew, Bob, etc but not anyone else.
Use the “pre” tags.
Trying pre tags:
require(dplyr) require(ggplot2) y1 = c(57, 45, 49, 50, 34, 65, 79, 21, 65, 33, 38, 62) y2 = c(69, 31, 53, 47, 32, 67, 78, 21, 70, 30, 42, 58) age = c(rep("18-49",6), rep("50+", 6)) worried = rep(c(T,F),6) party = rep(c("Democrat", "Republican", "Independent"),4) q1 = "Percent somewhat or very concerned that\n they or someone they know will\ncontract the coronavirus" q2 = "Percent somewhat or very concerned\nthat the coronavirus will disrupt their everyday life" df_1 = data.frame(question = q1, Age = age, Party = party, worried = worried, Percent = y1) df_2 = data.frame(question = q2, Age = age, Party = party, worried = worried, Percent = y2) both = bind_rows(df_1, df_2, .id = "question_num" ) ggplot(both %>% filter(worried), aes(x = Age, y = Percent, group = Party, color = Party)) + geom_line() + geom_text(data = both %>% filter(worried, Age == '18-49'), aes(x = Age, y = Percent, label = Party), nudge_y = -2) + geom_point() + scale_x_discrete(expand = c(0.3,0)) + scale_y_continuous(expand = c(0, 0.6), limits = c(0,80)) + scale_color_manual(values = c("blue", "purple", "red")) + ylab("Percent concerned") + xlab("Age group") + theme(legend.position = "none") + facet_wrap(~question)It didn’t work at first (it showed up as normal text), but now it looks right. Did something get fixed?
Yes, I edited the comment and put the tags in directly.
Phil, when I did a facet grid to compare the “not worried” (I’m going to try out code tags):
facet_grid(worried ~ question)the results were pretty weird so I started checking the values. Filtering the code:
contract = "Percent somewhat or very concerned that\n they or someone they know will\ncontract the coronavirus"both %>% filter(question == contract & Age == '18-49' & Party == 'Democrat')
You’ll get values of 57 and 50, but it should be 57,45. Changing the party assignment variable fixes the problem:
party = rep(c("Democrat", "Independent", "Republican"), 4,12,2)It only affects the worried = FALSE values, so worried = TRUE is correct. This seems weird to me but I’m too slow to figure out why it doesn’t mess up the whole plot.
That is, as Wornhoff would (not) say, super weird.
Ah, hmm, the weird thing is that it works (or at least appears to work) the way I have it for _any_ case. Good catch, thanks.
This suggests that the “independent” voter is either:
(1) a partisan who doesn’t want to admit it.
(2) someone who uses a dumb weighted-average heuristic on every issue :D
Numbers I’ve seen from 538 suggest that it’s option 1. Something like 80-90% of ‘independent’ voters are actually reliable Dem/Rep voters. I guess that means the other 10-20% are option 2!
Why the hell would one want to admit it, either way?
Andrew sayz that for many, independent = “don’t care”… noise also pulls towards the center!
Maybe ist’s more about “rural versus urban”?
I wish these charts also broke it down by prevalence of coronavirus in where the people live.
It’s one thing if Republicans in Boston are less concerned than Democrats in Boston. Quite another if Republicans overall are less concerned only because the places they are don’t have as much of it (yet).
Thanks to Andrew and Phil for the code.
On the other hand both say that reality has no effect on belief.
I’m concerned about dichotomania and over confidence here. Are we to think 49 is so different from 50?
;^)
Justin
Justin:
1. Regarding discreteness: I agree that it would be better to have more age categories. As I wrote in the post, I’d love to have more detailed age data. I graphed what I could.
2. I don’t understand your question about overconfidence.
When is the data from? I am disturbed that so few young people still think the virus won’t disrupt their life. I don’t think the message is getting through, but maybe the change in messaging over the weekend will make a difference.
Andrew,
You mention the all the problems you saw with the original graphs, can you also speculate why do they still used them?
Your graph looks great, but if I saw it on a news article it would feel a bit “empty” compared to the text, there is much more white space (background) than data, and your better organization of it makes it clear that there is not too much information there to be shown.
Do you think those are a good guess of why they are still making a poorer graph that looks like it has more data?
Renato:
I’m guessing that using the graphs they produced are the defaults from their existing software. Your point about my graph looking empty is a good one; indeed, once you see my graph, it’s clear that we could learn more by breaking up into more age categories; this was not so clear in the original graphs.
Of course both the original and Andrew’s version have the same amount of information, so the amount of information per square inch is the same (if they are shown at the same size). The fact that the original looks less empty is due to the fact that most of the different colors of the pixels etc carries no information. I know everyone knows this, I’m just making it explicit.
Haven’t read the study, so I’ll make some assumptions.
There are two big issues with research methods, before any data are collected.
1. Prior to being asked about their level of ‘worry’, the participants must have been asked about the party preference. It is likely that their answer is going to be downplayed/over-exaggerated based on the party’s agenda (e.g. not a big deal for reps because the main man said so initially, and it’s all ‘fake news’; or too big of a deal because CDC and all smart folks are worried in case of dems)
2. The actual level of awareness varied across the country over time, irrespective to party preference. All of this was much bigger deal earlier in Seattle, than say, in Ohio.
If the study lacks a solid design, no amount of fancy stats can fix it.
On a lighter note, the conclusion seems to be that being a republican offers some protection from worrying, but no protection against the virus itself ;-)
I don’t buy this characterization because where were all the “smart” folks in mid January? Or even mid-February? Looking through my records, I see I started preparing for this Jan 10 and was very disturbed by Feb 14. What were they telling the public then?
Anoneuoid,
I agree. The ‘smart folks’ were nowhere to be found. My response was suggesting that on average, dem. respondents to the study would tend to respond more extremely in one direction (what their party pushes at the time), regardless of what they really think.
Same with rep. respondents. Even if they are worried, it’s not their party’s agenda (e.g. they tend to respond the same when it comes to climate change, and such).
In any case, the virus is absolutely indifferent to our level of ‘worry’.
Sorry, I missed your sarcasm. But, yea anyone who defines themselves as a democrat or republican at this point is basically handing a blank ballot to the party leaders and letting them fill it out.
Andrew’s charts are a big improvement over the original but after I thought about it I noticed some issues. On the one hand they express concepts not apparent in the original plots, but on the other hand they create some new probs. I figure Andrew’s objective was to simply communicate the newly exposed info to a knowledgeable audience, not to spruce it up for publication, but just the same I’ll throw some ideas out there.
The main problem is that the separation along the horizontal axis is subjective, but that’s not readily apparent to the reader. Normally a scatterplot compares two continuous variables, so people naturally think there is a continuous scale on both axes. The x scale is critical because it determines the slope of the lines which determines how people perceive the issue. So the lack of a horizontal scale is problematic.
The second problem is that the data isn’t very good for making a continuous axis, since there are only two values for that axis.
Another problem is the solid or continuous line between only two data points.
Adapting Phil’s code (below; thanks Phil!) I propose some changes:
First, to convert x to a continuous variable, the mean of the age range of each group was used, assuming the upper bound of the “50+” group is 100 years. People can make different choices, but whatever choice they make the x-axis label should reflect that choice.
Second, the prominence of the line is reduced with a dotted line and low alpha. The range of the line extends across the full plot. With only two points, it’s no more or less meaningful between the points than beyond them. Plus, to my way of thinking this *deemphasizes* the value of the line while being more consistent with the data.
Third, while the x-axis is now scaled, the x axis it’s still a pretty rough scale. To emphasize this, each point is labeled with its category description.
Forth, the questions were reduced to their essential elements, so readers can get a quick idea of what’s shown. You can read from y to x: “percent concerned” – “about contracting” …(the corona virus). Readers will recognize that these are abbreviations and can consult the full text if necessary.
I don’t know how to do the tags, so I didn’t bother:
require(dplyr)
require(ggplot2)
require(scales)
y1 = c(57, 45, 49, 50, 34, 65, 79, 21, 65, 33, 38, 62)
y2 = c(69, 31, 53, 47, 32, 67, 78, 21, 70, 30, 42, 58)
agemean = c(rep(33.5,6), rep(75, 6))
agelab = c(rep(’18-49′,6), rep(’50+’, 6))
worried = rep(c(T,F),6)
party = rep(c(“Democrat”, “Republican”, “Independent”),4)
q1 = “About Contracting”
q2 = “About Disruption”
df_1 = data.frame(question = q1, Age = agemean, AgeGroup = agelab, Party = party, worried = worried, Percent = y1)
df_2 = data.frame(question = q2, Age = agemean, AgeGroup = agelab, Party = party, worried = worried, Percent = y2)
both = bind_rows(df_1, df_2, .id = “question_num” )
ggplot(both %>% filter(worried),
aes(x = Age, y = Percent*0.01, group = Party, color = Party)) +
geom_point(size = 2) +
geom_line(stat=’smooth’, method = ‘lm’, se=FALSE, fullrange=TRUE, linetype=”dotted”, size = 3, alpha = 0.1) +
geom_text(data = both %>% filter(worried, AgeGroup == ’18-49′),
aes(x = Age, y = Percent*0.01, label = Party),
nudge_y = -0.02) +
geom_text(data = both %>% filter(worried, AgeGroup == ’18-49′),
aes(x = Age, y = Percent*0.01, label = AgeGroup),
nudge_y = 0.02)+
geom_text(data = both %>% filter(worried, AgeGroup == ’50+’),
aes(x = Age, y = Percent*0.01, label = AgeGroup),
nudge_y = 0.02)+
geom_point() +
scale_x_continuous(limits = c(0,100)) +
scale_y_continuous(limits = c(0,1), labels = percent) +
scale_color_manual(values = c(“black”, “purple”, “dark orange”)) +
ylab(“Percent Concerned”) +
xlab(“Mean of Age Range”) +
theme(legend.position = “none”) +
facet_wrap(~question)
jim: I like what you’ve done. Here’s my version of it.
library(tidyverse)y1 <- c(57, 45, 49, 50, 34, 65, 79, 21, 65, 33, 38, 62)
y2 <- c(69, 31, 53, 47, 32, 67, 78, 21, 70, 30, 42, 58)
agemean <- c(rep(33.5,6), rep(75, 6))
agelab <- c(rep('18-49',6), rep('50+', 6))
worried <- rep(c(T,F),6)
party <- rep(c("Democrat", "Republican", "Independent"),4)
q1 <- "About Contracting"
q2 <- "About Disruption"
df_1 <- tibble(question = q1, Age = agemean, AgeGroup = agelab,
Party = party, worried = worried, Percent = y1)
df_2 <- tibble(question = q2, Age = agemean, AgeGroup = agelab,
Party = party, worried = worried, Percent = y2)
both <- bind_rows(df_1, df_2, .id = "question_num" )
both_worried % filter(worried)
both_worried %>%
{
ggplot(.,
aes(x = Age, y = Percent*0.01, group = Party, color = Party)) +
geom_point(size = 7, alpha = 0.3) +
geom_point(size = 4) +
geom_line(
stat = "smooth", method = 'lm', formula = y ~ x, se = FALSE,
fullrange = TRUE, linetype = "dotted", size = 2, alpha = 0.2
) +
geom_text(
data = group_by(.,Party,question) %>%
summarize_at(vars(Age,Percent),mean),
aes(label = Party), nudge_y = 0.03, fontface = "bold"
) +
geom_text(aes(label = AgeGroup), nudge_y = 0.02) +
scale_x_continuous(limits = c(0,100)) +
scale_y_continuous(limits = c(0,1), labels = percent) +
scale_color_manual(values = c("blue", "purple", "red")) +
labs(x = "Mean of Age Range", y = "Percent Concerned" ) +
theme_bw(base_size = 20) +
theme(legend.position = "none") +
facet_wrap( ~question )
} %>%
print()
Nice! I like the double plot of the points. Emphasizes fuzz factor!