Jesús Humberto Gómez writes:
I am an epidemiologist and currently I am studying my fourth year of statistics degree.
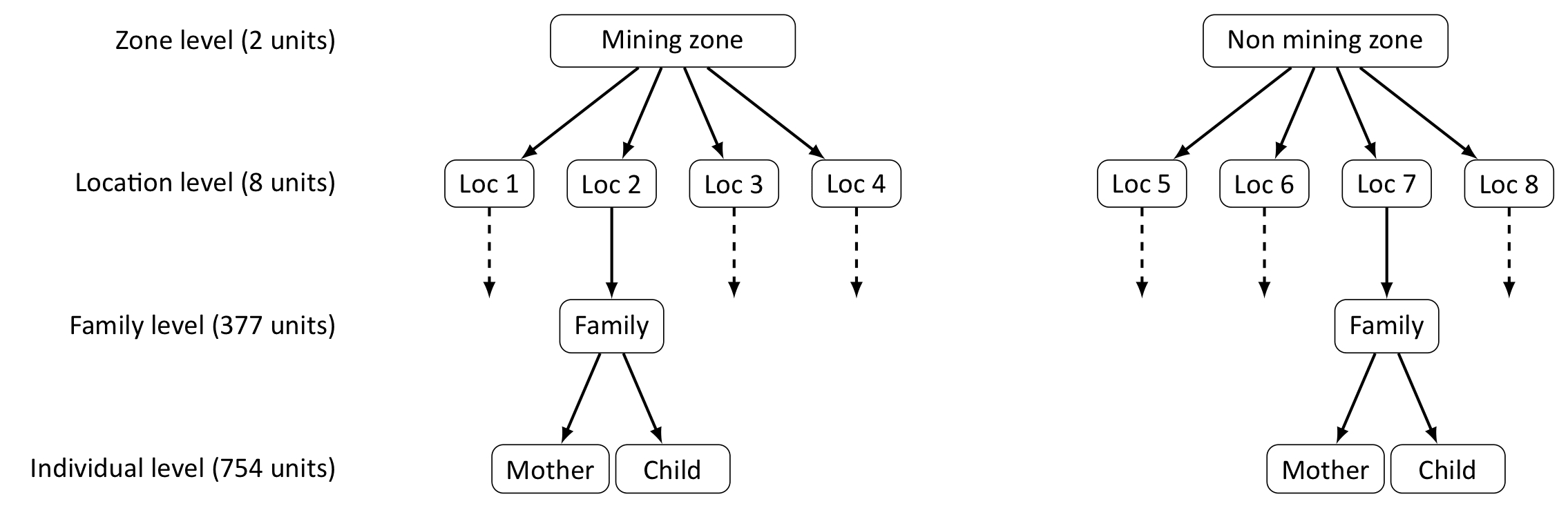
Currently we have a dataset with data structure shown here:
We want to investigate the effect of mining contamination on the blood lead levels. We have a total of 8 inhabited locations and the participants and politicians want to know the mean levels in each location.
To give an answer, we have constructed a hierarchical model: level one children (or mothers), level two defined by the locations and mining zone like a population effect (what is, a fixed effect). There are no explainatory variables at the second level. The sizes of the locations are 114, 37, 19, 11, 63, 56, 40, 12 (first four mining zone, second four non mining zone).
The model converges properly. Our data are left censored data and this has been taken account in the likelihood. The mining effect obtained is 23% higher that the obtained running the model without the hierarchical structure (0.59 vs 0.48) and this worries us.
In addition, we have doubts about what we are doing arise because locations are nested in the zones (mining vs non mining) and we are modeling it like a population effect.
Then, is this approach correct?
At the moment, we are going to study separately the mining effect in children and mothers, but in the future we will study both mothers and children together since the blood lead levels correlation is high.
Of course, we are using Stan.

{kind=link}
My reply:
First, good call on using Stan! This gives you the flexibility to expand the model as needed.
Now on to the question. Without looking at all the details, I have a few thoughts:
First, if you fit a different model you’ll get a different estimate, so in that sense there’s no reason to be bothered that your estimate is changing.
But it does make sense to want to understand why, or should I say how, the estimate changes when you add more information, or when you improve your model. For simple regressions there are methods such as partial correlations that are designed to facilitate these explanations. We need something similar for multilevel models—for statistical models in general—a “trail of breadcrumbs” tracking how inferences for qois change as we change our models.
For the particular example discussed above, I have one more suggestion which is to include, as a group-level predictor, the group-level average of your individual-level predictor. Bafumi and I discuss this in our unpublished paper from 2006.
When you change the model the meanings of the coefficients change, so you are comparing apples to oranges. Unless you have a reason to believe your model specification is correct (or at least approximately enough for your purposes) you shouldn’t be trying to interpret the coefficients at all.
Ie, you can interpret the parameters of models derived from assumptions you and your audience are willing to accept, but probably not some arbitrary statistical one like this. If you have any doubts at all, you shouldn’t be trying to interpret these coefficients.
And yes, I realize that throws out 90%+ of epidemiology. And that someone else will come by and (incorrectly) interpret these coefficients for your boss if you don’t.
Btw, I tried to send Andrew an email about this topic, but it looks like it got labeled spam. Basically, it was about what to think when there is little correlation between a treatment and side effect, but then you “adjust” the effect (add more variables to the model) and see a correlation appear.
If making a medical decision I would rather use the unadjusted result. In this case, just show me a scatter plot of lead levels vs mining exposure. Using the hierarchical model to predict lead levels for a given individual would be great though.
Btw, this is just a simple descriptive statistic:
>Btw, this is just a simple descriptive statistic:
>> politicians want to know the mean levels in each location.
Sort of. With the small sample sizes, and without any high quality random selection process, using the mean of the sample to interpret what is going on in the entire population of people who live in the region is problematic.
Using a hierarchical model such as the one mentioned, and adjustments for known confounders (such as say whether they live in an old house with lead paint, etc), your estimate of the population wide average lead levels in each region should be more stable and accurate.
Yea, or different between but uniformly within water sources in the non-mining versus mining areas…
Sure, and income and education levels, for example more wealthy people may be more likely to be using water filter pitchers or filters attached to their sinks. (of course if you can just ask them, that’d be even better, but I’m assuming not).
There’s a lot of etc here, like if you can get a random sample of tap water lead levels in the regions, or lead levels in locally grown food, etc.
It’s these kinds of things that make what Anoneuoid says true: that the meaning of a coefficient in a purely predictive (as opposed to mechanistic) model changes as the model changes.
I’m not sure how effective water filters would be in this situation. That effectiveness would probably depend on the source of the drinking water.
I understand that dirt and dust are significant contributors to lead ingestion by children (probably adults also) living near lead smelters. See https://missoulian.com/news/state-and-regional/victims-of-north-idaho-lead-pollution-still-suffer-physical-emotional/article_49524244-b911-11df-accd-001cc4c002e0.html for a popular account of this route.
Bob
Indeed, it was just an example. Paint dust and flakes is a big source of lead even if you’re not near a lead smelter, as was car exhaust in the 60’s… but lots of things affect how much of all that you’re exposed to. For example being more wealthy means potentially living in a newer house, or having a better maintained house whose lead paint is underneath several layers of non-lead paint.
Didn’t they measure lead levels in some people and they want to estimate them in other people?
It sounds like what they want to do is different (estimate a coefficient of mining) from what the politicians are asking for (tell them the average lead levels in each area). Perhaps the latter has not been measured everywhere so it also needs to be estimated? I would guess sending a team to each county to get samples and send to a lab would be cheap enough to do.
> It sounds like what they want to do is different (estimate a coefficient of mining) from what the politicians are asking for (tell them the average lead levels in each area)
Good catch on the wording. I wonder if these samples are everyone in the area?
If not, then who got sampled? And do we have census data for everyone in the area that we didn’t count? Presumably that’ll all be important if we want to get this right.
I think this comment begs the question of how one establishes informative priors on regression coefficients, or how one uses previous research to induce priors on regression coefficients.
…which is why conditional means priors are the way to go!
https://www.tandfonline.com/doi/abs/10.1080/01621459.1996.10476713
I don’t think it matters for models like this. Generalizable predictive skill is all that counts. If the priors come to you in a dream that is fine with me. Just prove to me the model is not overfit to your training data. Coincidentally, I doubt they have holdout data for a project like this which would mean 100% it will be overfit.
From Anoneuoid:
Love that line. How about “pragmatic Bayes” as an alternative to “objective Bayes” and “subjective Bayes”, neither of which describe how we do Bayes around here?
I’m convinced that their pragmatism-first methodology is a large part of why machine learners are eating statisticians’ lunches. A large part of that is evaluating on the predictive task at hand, that is pragmatically rather than objectively or subjectively.
Anon:
As usual, let’s forget about focusing on “priors” and instead think about “models” in general. So now let’s get to your statement, “If the models come to you in a dream that is fine with me.” The real issue is not where the models come from, but how they perform. If a model “comes to you in a dream” and it performs well, that suggests that either (a) a wide variety of reasonable models will perform well, and the class of models you’re dreaming about has some models that are broadly useful, or (b) you’re dreaming really well, so that in your dream you’re incorporating useful knowledge. Perhaps you can do even better by figuring out what’s going into that dream!
To me, this is similar to the black-box approach to casual inference, whereby someone comes up with some idea for a treatment, which is then tested in a randomized experiment. This is all fine, but in practice there must be some reason why you think that the idea for the treatment might actually work. If you just try completely random things, it’s unlikely you’ll succeed. Mathematically this can be expressed as a population or prior distribution of effect sizes.
As to the “how” or “why”, though we haven’t been given much more info about how the data were collected other than the hierarchical structure, I might guess that the estimated effect(s) here decrease considerably in the hierarchical model due to some sort of sampling issue that goes unaccounted for in the non-hierarchical model. For e.g., the balance of samples across units. If individual, i, or location, j, has a disproportionate number of samples, and those samples tend to be higher for the response, all of those high samples get lumped with (or assumed exchangeable with) the fewer low samples in a non-hierarchical setting.
I see this sort of thing a good bit in my own work when looking to estimate population means and such from environmental samples collected across spatial units (e.g, water chemistry measures from wells, within a county, state, etc) when structuring in the response is strong (e.g., due to physical processes) and sampling effort is also structured (e.g., unbalanced due to disproportionate targeting of impacted areas). Essentially these are selection issues, which you can try to tackle with a hierarchical model and/or conditioning on the factors that drove the sampling. Again, not saying this is certainly the issue here, but just offering a specific and potentially relevant example for thinking about the “how and why” when considering the results from different model parameterizations fitted to the same data, as Andrew suggested.
Gómez wrote that the estimate obtained using the hierarchical model was higher than that obtained using the non-hierarchical model. (Guessing the opposite would make sense if the model is hierarchical all the way up to the top so that the mining zone and non-mining zone raw effects are shrunk together, but Gómez wrote that mining/non-mining is treated as a fixed effect.) I think your guess as to why the estimates might be different is a good one though. It’s worth noting that it doesn’t depend on which model yields the higher estimate: failing to account for the correlation structure induced by the nesting of families within locations could potentially change the estimate of the difference between the two conditions in either direction.
Oh, you’re right, it does look like it went the other way. I should have been more careful in my reading! And, yes, more generally, it can certainly go either way. Thank you for clarifying why!
qois = ?
QOI = quantity of interest
Ha ha! I was interpreting the “oi” as a subscript!
This raises a good question: how much should we expect estimates to change? What should we look at to judge whether a parameter-estimate-change is “alarming”? My guess would be the standard errors of the parameter estimates (or whatever Bayesians call that sort of thing).
I personally was surprised that the change was only 23%. From the title, I expected something much larger.
I agree, though, with the OP’s desire to understand how the change happened.
This looks like a simulated data situation.
Or maybe a prior predictive situation.
We’re worried that model changes are affecting the model in a way we wouldn’t like, so we should just play with the two models by themselves for awhile and see if such an issue exists.
The model changed, but the only way that it changed was replacing the non-hierarchical prior with the hierarchical prior, right? If so maybe generate data from both priors and see if there’s a difference like the one you see in your estimates.
Also post it on https://discourse.mc-stan.org/
I think this answer applies to your problem as well: https://discourse.mc-stan.org/t/prior-specification-for-beta-distribution-in-brms/12860/2
Yup, but isn’t everything a simulated data situation for someone (at least if they lack the math)?
It’s easy to forget though!
> (at least if they lack the math)
Well that’s the point of computer experiments! You can go way beyond your mathematical background as long as you’re a good little keyboard scientist
What’s the point of a fancier model if the results aren’t supposed to change? Shouldn’t a “better” model produce “better”, results, which by definition are not the same as the original results?
Terry:
I agree, and this issue arises in robustness studies, where there seems to be a norm or expectation that some set of different analyses will all produce the same results.
Yup, a mug’s game from my assessment of Stephen Stigler’s assessment – https://home.uchicago.edu/~lhansen/changing_robustness_stigler.pdf (see page 1 and 13)
We can have it both ways. For instance, a multiverse analysis is valuable whether or not is shows that a given result is invariant to the possible data analysis choices we might make: if the result holds up under many different ways of analyzing the data then that gives us reason to give it credence*; if the result varies with data analysis choices then that tells us that the data underdetermine the result and, further, it gives us insight into which questions we need to answer to make progress.
* I have always viewed this through a Bayesian lens as showing that different ways of modelling the data give rise to the same result and thus if we are, in a hand-waving way, imagining distributing dollops of prior probability mass to these different modelling choices then the multiverse analysis is showing that these masses concentrate in the posterior.
I can see a distinction here.
Some robustness tests are done by varying what should be inconsequential choices: whether to include this additional data, whether to include another explanatory variable, whether to normalize by this denominator or another apparently comparable one. For those, we expect no change, and if there is a change, there is some explaining to do.
But, if we switch to a “better” model, then there should be some change and the new results are “better” results. If there isn’t any change, then that suggests that the “better” model is not really better, or the betterment is too small to care about.
I agree with you. In the present case, I think the analysis with non-hierarchical structure and a comparison with the main analysis could go in a supplement that addresses any questions that might arise regarding the use of the multilevel model. If (as RWM posits above) the fact that the non-hierarchical model neglects correlations that exist in the data explains the discrepancy then I think it’s worth spelling out this fact and the making the argument that the multilevel model is indeed better explicitly, especially in light of the the complicating factor of a tricky likelihood arising out of the censored data.
This would be an example of what I mean by “insight into which questions we need to answer to make progress”. The argument in the supplement goes something like this:
1. the flat model gives a different estimate — why?
2. one implication of the flat model is that the correlations that are nuisance parameters in the multilevel model are zero — is this in fact the case? (this is the question we need to answer to make progress)
3. the data show that the correlations cannot be taken to be zero
4. thus the multilevel model is indeed better