In a news article on Vox, entitled “Installing air filters in classrooms has surprisingly large educational benefits,” Matthew Yglesias writes:
An emergency situation that turned out to be mostly a false alarm led a lot of schools in Los Angeles to install air filters, and something strange happened: Test scores went up. By a lot. And the gains were sustained in the subsequent year rather than fading away.
That’s what NYU’s Michael Gilraine finds in a new working paper titled “Air Filters, Pollution, and Student Achievement” that looks at the surprising consequences of the Aliso Canyon gas leak in 2015. . . .
If Gilraine’s result holds up to further scrutiny, he will have identified what’s probably the single most cost-effective education policy intervention — one that should have particularly large benefits for low-income children. . . .
He finds that math scores went up by 0.20 standard deviations and English scores by 0.18 standard deviations, and the results hold up even when you control for “detailed student demographics, including residential ZIP Code fixed effects that help control for a student’s exposure to pollution at home.”
I clicked through the link, and I don’t believe it. Not the thing about air filters causing large improvements in test scores—I mean, sure, I’m skeptical of claims of large effects, but really I have no idea about what’s going on with air pollution and the brain—no, what I don’t believe is that the study in question provides the claimed evidence.
Here’s the key graph from the paper:
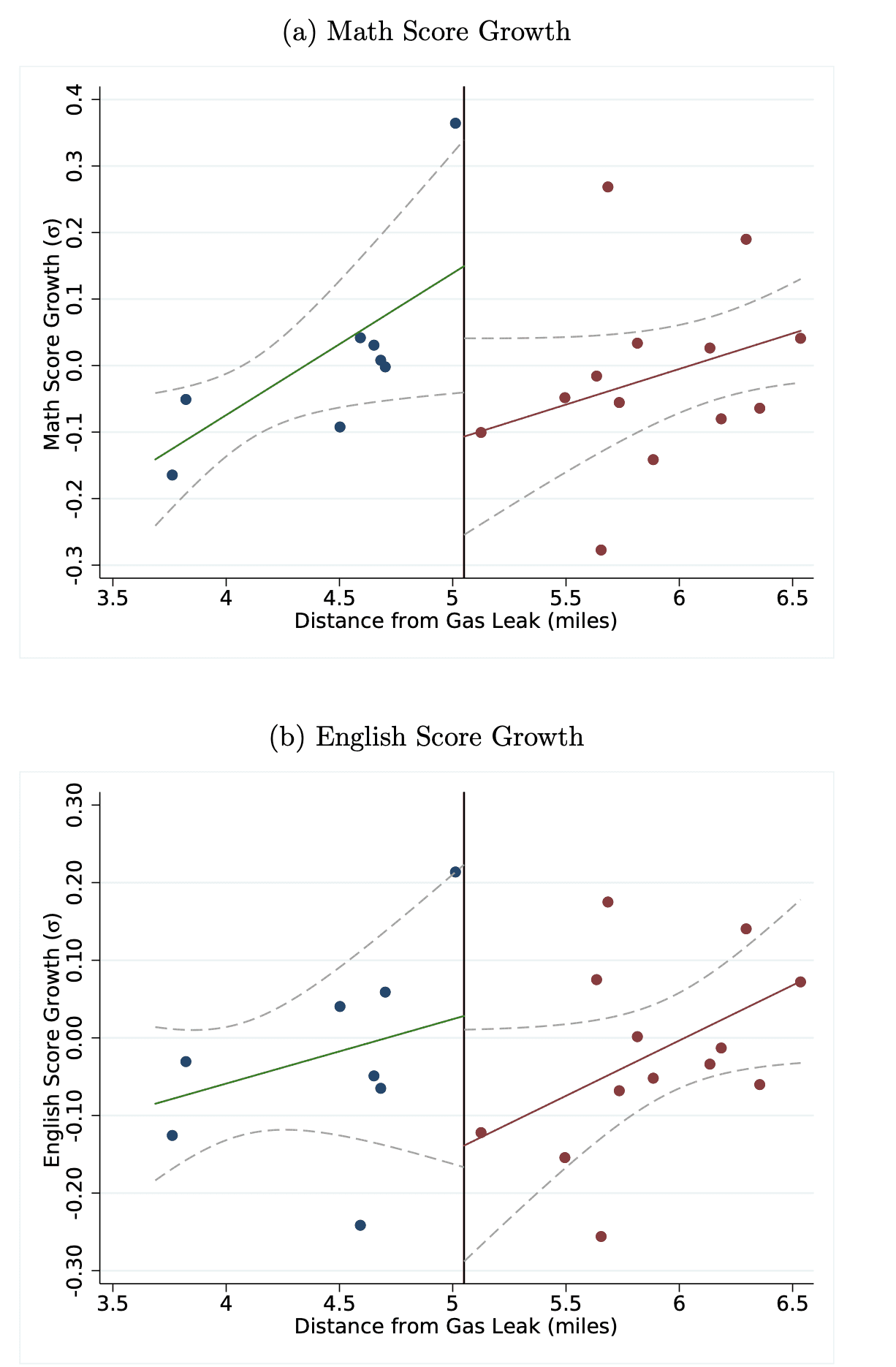
The whole thing is driven by one data point and a linear trend which makes no theoretical sense in the context of the paper (from the abstract: “Air testing conducted inside schools during the leak (but before air filters were installed) showed no presence of natural gas pollutants, implying that the effectiveness of air filters came from removing common air pollutants”) but does serve to create a background trend to allow a big discontinuity with some statistical significance.
We’ve been down this road before. When we discussed it earlier (see also here) it was in the context of high-degree polynomials, but really it’s a more general problem with analysis of observational data.
Given what we know about statistics, how should we think about this problem?
It goes like this: The installation of air filters can be considered as a natural experiment, so the first step is to compare outcomes in schools in the area with and without air filters: in statistics terms, a regression with one data point per school, with the outcome being average post-test score and the predictors being average pre-test score and an indicator for air filters. Make a scatterplot of post-test vs. pre-test with one point per school, displaying treated schools as open circles and control schools as dots. Make a separate estimate and graph for each grade level if you’d like, but I’m guessing that averages will give you all the information you need. Similarly, you can do a multilevel model using data from individual students—why not, it’s easy enough to do—but I don’t think it will really get you much of anything beyond the analysis of school-level averages. If you know the local geography, that’s great, and to gain insight you could make plots of pre-test scores, post-test scores, and regression residuals on a map, using color intensities. I don’t know that this will reveal much either, but who knows. I’d also include the schools in the neighborhood that were not part of the agreement (see caption of figure 1 in the linked paper).
I’m not saying that the proposed analysis plan is perfect or anything like it; it’s a starting point. If you take the above graphs and ignore the distracting lines on them, you won’t see much—it all pretty much looks like noise, which is no surprise given the variability of test scores and the variability among schools—but it’s fine to take a look. Observational data analysis is hard, especially when all you have is a small sample, in a small area, at just one time. That’s just the way it is.
What about that regression discontinuity analysis? As noted above, it doesn’t make a lot of sense given the context of the problem, and it’s a bit of a distraction from the challenges of data analysis from an observational study. Just for example, Table 3 reports that they adjust for “a cubic of lagged math and English scores interacted with grade dummies” as well as latitude and longitude?? Lots of researcher degrees of freedom here. Yes, there are robustness claims, but the result are still being driven by a data-based adjustment which creates that opportunity for the discontinuity.
Again, the point is not that the paper’s substantive conclusion—of the positive effects of air filters on cognitive performance—is wrong, but rather that the analysis presented doesn’t provide any real evidence for that claim. What we see is basically no difference, that becomes a large and possibly statistically significant difference after lots of different somewhat arbitrary knobs are twisted in the analysis. Also, and this is a related point, we should not by default believe this result just because it’s been written up and put on the internet, any more than we should by default believe something published in PNAS. The fact that the analysis includes an identification strategy (in this case, regression discontinuity) does not make it correct, and we have to watch out for the sort of behavior by which such claims are accepted by default.
What went wrong? What could the reporter have done better?
I don’t want to pick on the author of the above paper, who’s studying an important problem with a unique dataset using generally accepted methods. And it’s just a preprint. It’s good practice for people to release preliminary findings in order to get feedback. Indeed, that’s what’s happening here. That’s the way to go: be open about your design and analysis, share your results, and engage the hivemind. It was good luck to get the publicity right away so now there’s the opportunity to start over on the analysis and accept that the conclusions probably won’t be so clear, once all is said and done.
If there’s a problem, it’s with the general attitude in much of economics, in which it is assumed that identification strategy + statistical significance = discovery. That’s a mistake, and it’s something we have to keep talking about. But, again, it’s not about this particular researcher. Indeed, now the data are out there—I assume that at least the average test scores for each school and grade can be released publicly?—other people can do their own analyses. Somebody had to get the ball rolling.
There was a problem with the news article, in that the claims from the research paper were reported completely uncritically, with no other perspectives. Yes, there were qualifiers (“If Gilraine’s result holds up to further scrutiny . . . it’s too hasty to draw sweeping conclusions on the basis of one study”) but the entire article was written from the perspective that the claims from this study were well supported by the data analysis, which turns out not to have been the case.
What could the reporter have done? Here’s what I recommended a couple years ago:
When you see a report of an interesting study, he contact the authors and push them with hard questions: not just “Can you elaborate on the importance of this result?” but also “How might this result be criticized?”, “What’s the shakiest thing you’re claiming?”, “Who are the people who won’t be convinced by this paper?”, etc. Ask these questions in a polite way, not in any attempt to shoot the study down—your job, after all, is to promote this sort of work—but rather in the spirit of fuller understanding of the study.
I think the biggest problem with that news article was its misleading title, “Installing air filters in classrooms has surprisingly large educational benefits.”
Looking forward
To his credit Yglesias follows up with another caveat and comes up with a reasonable conclusion:
And while it’s too hasty to draw sweeping conclusions on the basis of one study, it would be incredibly cheap to have a few cities experiment with installing air filters in some of their schools to get more data and draw clearer conclusions about exactly how much of a difference this makes.
Perhaps school systems are already experimenting with pollution-control devices; I don’t know. They’re installing heating, ventilation, and air conditioning units all over the place, so I’m guessing this is part of it.
P.S. But let me be clear.
I don’t think the correct summary of the above study is: “A large effect was found. But this was a small study, it’s preliminary data, so let’s gather more information.” Rather, I think a better summary is: “The data showed no effect. A particular statistical analysis of these data seemed to show a large effect, but that was a mistake. Perhaps it’s still worth studying the problem because of other things we know about air pollution, in which case this particular study is irrelevant to the discussion.”
Or, even better:
New study finds no evidence of educational benefits from installing air filters in classrooms
A new study was performed of a set of Los Angeles schools and found no effects on test scores, comparing schools with and without newly-installed air filters.
However, this was a small study, and even though it found null effects, it could still be worth exploring the idea of installing air filters in classrooms, given all that we believe about the bad effects of air pollution.
We should not let this particular null study deter us from continuing to explore this possibility.
The point is that these data, analyzed appropriately, do not show any clear effect. So if it’s a good idea to keep on with this, it’s in spite of, not because of these results.
And that’s fine. Just cos a small study found a null result, that’s no reason to stop studying a problem. It’s just that, if you’re gonna use that small study as the basis of your news article, you should make it clear that the result was, in fact, null, which is no surprise given high variability etc.
How are you claiming that the data show no effect??
Demosthenes:
Not exactly zero, just no more than could be expected by chance variation. Just look at the above two graphs without the fitted lines. There’s no clear difference between the points on the two sides of the discontinuity. The jump at the discontinuity is facilitated by the positive slopes outside the discontinuity, but that has nothing to do with anything. The fact that there’s a school 3.7 miles from the gas leak with a low gain and another school that’s 5.0 miles from the gas leak with a high gain, that has nothing to do with the effect of air filters but that’s where the estimated effect of the gas leak is coming from. It’s good that the paper had those graphs so we could see this clearly. If the paper didn’t have the graphs, I’d have to say first that I’m concerned about forking paths in the rules for data including, data coding, and data analysis, and second that it would be hard for me to try to understand the results without seeing any graphs of the data. In general, I think it’s a mistake to trust a statistical analysis without seeing the path from data and theory to conclusions.
I data thieved the plots. Basically, the means and variances of the whole groups and the sub-groups are identical. (The means for the math scores are just about 1 standard deviation of the mean away from each other, the english score means are even closer.) Now, that’s not the most sophisticated thing one can do, but it does mean that at first blush the two sub-groups behave more or less like you’d expect any two randomly drawn sub-groups would look like, coming from the same parent population.
You basically have to first show that there’s some statistically significant trend with *something* (but how many somethings did you look at???), and then show that the chosen sub-groups clearly violate that, and at a statistical level that more than makes up for how many ways of parsing the data that you looked at.
There’s nothing in the quick look at the data that would make me think that these two groups are in any way different.
Filters have no effect because they are a binary intervention: Filters = 1 if inside 5 miles and Filters = 0 outside. To the extent there’s a real trend in scores related to distance, in either or both conditions, it cannot be caused by the filters. A continuous trend cannot be caused by a binary intervention.
You don’t really seem to get point of RDD, the “trend” is in the forcing variable, the intervention causes a discontinuity, hence “D”, not a trend.
Other issues aside, I believe in the Outlier section of the paper, the author removes this point, to see if the results are robust? (The results are smaller, but still significant.)
Peter:
I think that one point is part of the story but not the whole story. Regarding the particular claim, it refers to the statistical significance of column (3) in table 3, but this is only one of four analyses considered, so I’d think that the author could just as well have referred to the statistical significance as non-robust by choosing one of the other columns. But, yeah, it’s not just about one data point. That data point just makes it visually clear how the discontinuity estimate is driven by the slope of the fitted line.
Or maybe they went to better schools or maybe they weren’t even the same students. In looking for information about these “air filters” I came across a number of LAUSD docs describing multiple waves of reassignments of students to different schools before and after the gas leak; this for example https://home.lausd.net/apps/news/article/526601
I eventually found some info on the “air filters”. They appear to have been large versions of the activated carbon plug-in odor removers you can buy at HomeDepot for $90 but with a bigger fan to speed things up. The problem, according to the gas company, was that the escaping gas had enough mercaptans in it to stink up everything in a five mile radius around the leak. So their solution was to send a unit and replacement carbon filters to every school room.
Conclusion: Having done some mercaptan chemistry long ago I find it highly plausible that people living over a gas field would do better on cognitive tests if everything didn’t smell like rotten eggs. Other than that I doubt these findings are generalizable beyond the rather unusual circumstances that precipitated the use of these “air filters”.
I too find it highly plausible that people living over a gas field would do better on cognitive tests if everything didn’t smell like rotten eggs. But in this case, “Air testing conducted inside schools during the leak (but before air filters were installed) showed no presence of natural gas pollutants, implying that the effectiveness of air filters came from removing common air pollutants and so these results should extend to other settings.”
IOW, if the filters had an effect it was not on leaked natural gas, but on “common air pollutants,” which I think would probably not include noticeable levels of mercaptans.
Of course, but there are lots of different filters for lots of different environments and it would be rather surprising if for example a vapor cartridge filter turned out to be an effective particulate filter. Leery of lawsuits manufacturers send along detailed warnings to disabuse users of the notion that filters designed for one class of contaminants might also guard against another. So my question is: if the filter is wasn’t removing what it was designed to remove, what, if anything, did it remove? Until somebody analyses the filters we won’t know.
“Until somebody analyses the filters we won’t know.”
+1
it’s almost funny that no one even thought of it.
Good point.
If the filters are working by reducing common pollutants and not by reducing natural gas pollutants, then the effect would not increase with distance from the leak. There would be flat lines on both sides of the 5-mile point and a simple comparison of filter versus no-filter schools would show the effect.
This is the bit I find baffling. If there wasn’t any gas present, and the filters are meant to be catching some other pollutant, why on earth would the slope of a regression of change in score on distance from the leak be evidence of anything? I mean, why not regress the change in the scores on how many kids are Hannah Montana fans, or the phases of the moon?
Southern California engaged in a vast natural experiment between about 1965 and 2000 in the near virtual elimination of severe smog:
https://slideplayer.com/slide/5875876/19/images/7/Ozone+trends+in+Los+Angeles.jpg
Around 1966, there were 75 days per year with bad stage 2 smog alerts. After the late 1980s there were close to zero.
Lesser Stage 1 smog alerts declined from about 180 per year in the mid-1960s to single digits annually by the late 1990s.
Has anybody ever analyzed the effects of this huge environmental improvement on school test scores?
Umm…no academic in her right mind would publish a study that would hint at the benefits of using natural gas.
Um, during the same time period at that same location, lead was removed from gasoline and the air. Lead is much more harmful to student performance than is smog generally.
To put it another way:
From the evidence of the above graphs, there’s no difference between test score gains in area schools with and without air filters. But, when an analysis is done that has many moving parts, lots of researcher degrees of freedom in data inclusion, data coding, and data analysis, then some p=0.04 results came up. That’s fine—nothing wrong with doing an analysis.
But I think it’s a mistake of people to believe the results of such an analysis by default, just because it has the “regression discontinuity” label. Indeed, I’d have the same problem with a randomized experiment that gave the same outcome of no average difference, with something bigger showing up only after lots of data processing. Data processing has a role—I do it all the time—but if a result only appears after a series of adjustments, we have to think carefully about how these adjustments make sense, and how other adjustments would give different results—and the sorts of small changes that go under the name robustness checks don’t do it.
“But I think it’s a mistake of people to believe the results of such an analysis by default, just because it has the “regression discontinuity” label.”
This seems like a huge straw man, Andrew. Literally no one is saying that.
Demosthenes:
No one is saying to believe the study just because it has the “regression discontinuity” label. But I think they pretty much are acting that way. But I guess we could flip this around and ask why the Vox writer reported on the study so credulously. We can’t blame PNAS on this one, as the paper hasn’t even been published! I’m not quite sure what cues in the technical report made it seem reasonable for a reporter to accept the claims without question. Perhaps there was a certain professionalism in the presentation of the results. I do think that part of the appeal was that it was a natural experiment. Maybe not the discontinuity analysis per se, but something about the setup that made it look like trustworthy research, I dunno.
I don’t know. I’ve seen reviewers accept a paper by virtue of the “novelty” of its statistical methods.
Yes, I’ve encountered talks where (for some reason I can’t really fathom), saying you use “novel methods” seems to get you brownie points.
One robustness check, now quite widespread, is to report results with double and half the selected bandwidth.
Figure A3 reports results for varied bandwidths (but not up to double the bandwidth, which might have good reasons, “I stop the figure at 2.5 miles as extending it further would start including the two school that were evacuated due to their proximity to the leak”) and the results are not significant at half the bandwidth and are not so strong with larger bandwidths either.
Of course, conditioning declaring a result on so many robustness checks passing can also distort inference, so not sure we should expect all checks to pass…
Dean:
I think there’s a larger problem here, which is considering this as a “regression discontinuity” problem rather than just starting from scratch and thinking it of as an observational study. There are lots of potential differences between the different schools, and distance from the gas leak is only one of these differences. It doesn’t matter what you do with this one variable, it still doesn’t adjust for anything else.
And of course in this particular example, there’s no difference between the outcomes in the treatment and control groups, and we always have to worry about a method that creates a statistical difference when there was no difference there in the first place. Yes, this can happen, but we should be concerned.
Noah Smith is leading an interesting discussion of this on Twitter. @Noahpinion
Kyle:
I found the thread. The best part was where Smith wrote, “His criticisms seem taken directly off of Twitter (or a summary someone sent him, or a very cursory perusal).” I don’t think that Smith realizes that when I write, I follow academic rules, which means that if I get an idea from something I read, I cite the source! If my criticisms had been “taken directly off of Twitter,” I would’ve linked to the relevant tweets!
I continue to think that a big problem here is that people take a published (or, in this case, unpublished) claim as a starting point. In this case, the starting point was “Putting air filters in classrooms increased test scores by 0.20 standard deviations,” and the idea is that the claim stands until someone shoots it down. I think the default should go the other way: we start with the observation that there was no apparent difference between the outcomes in the two groups of schools, and then if people want to make a positive claim from there, the burden should be on them. Relatedly, I think more graphs should be absolutely required in this sort of work. Not just that discontinuity graph (although it’s a start) but the pre/post graph I suggested in my above post. The final analysis might end up looking like a discontinuity regression, that could be fine, but we have to work our way there.
“I think the default should go the other way: we start with the observation that there was no apparent difference between the outcomes in the two groups of schools, and then if people want to make a positive claim from there, the burden should be on them.”
Is this Mayo or Gelman? Didn’t expect the logic of NHST to come out of your mouth.
Why not be Bayesian about it and give each hypothesis some probability by default (equal odds if we’re totally agnostic pre-data) and update in light of the data?
Adam:
Two things I’ve consistently said about the null hypothesis are: (a) it’s always false, and (b) if we can’t distinguish the data from simulations from the null hypothesis, that tells us something: it tells us that the data are not informative to learn very much.
If you have prior information that air filters can help test performance, that’s fine, go for it. But in this case the data provide approximately zero evidence. That was the point of my P.S. above. It’s fine to recommend air filters, but this recommendation shouldn’t be motivated by this particular study, where there were essentially no difference in outcomes between treated and control schools.
Nope, the meaning of this coefficient depends on what you included in the model. In this case that is “geographic location”, “lagged test scores”, “student demographics and fixed school characteristics”, etc.
Change the model, change the meaning of the coefficient. Why is this model specification any better than the millions of other ones they could have used? It seems to be an arbitrary one using coefficients of convenience.
See here for an example of someone actually checking the value of the coefficient for some other data: https://statmodeling.stat.columbia.edu/2019/08/01/the-garden-of-forking-paths/
Umm, the table in the paper does (a not completely exhaustive) set of robustness checks for the different control variables. You’re being lazy here.
And how do you think this addresses the problem? Eg, if there is another important variable that should be included that they lack data on, how is a robustness check going to discover it?
Demosthenes:
There’s one robustness check they didn’t do, which is the direct comparison between the two groups of schools, which would show essentially zero difference!
> Yes, there are robustness claims, but the result are still being driven by a data-based adjustment which creates that opportunity for the discontinuity.
In particular, yes, some different kernels were tried, but what about a constant fit? If neither the data nor prior reasoning strongly support a particular functional form, you should have to report fits with a wide range of functional forms, not just some cherry-picked ones that happen to give the desired significant results.
Seriously, these regression discontinuity things drive me batty. Has no one ever heard of the Runge phenomenon? It’s where the edges of an interval specifically interact with a fitting process to produce large deviation in the approximation function. It’s originally from the process of interpolation with accurate data, but in general the issue that boundaries provide information about the behavior of a function on *one side only* is the real issue
https://en.wikipedia.org/wiki/Runge%27s_phenomenon
In the middle of the interval, the function gets close to the right value, because it is a continuous function and it has data to constrain not only its value but also its slope, and maybe 2nd derivative, etc…
But at the end of the interval, particularly with noise involved, it has information from only one side of the interval. For example, here there is an upward outlier at about 4.95 and another downward outlier at 5.75 (math score graph). If the regression went through that region, those two would cancel out… the curve would stay somewhere in the middle… But because we drew an arbitrary boundary there, and then allowed the functions on each side of that boundary to do *completely different* things, the functions do exactly that, completely different things. This then becomes a “discovery” because we have an “identification strategy”. It’s like saying you discovered your feet are different sizes because when you allowed yourself to put on two different shoes you didn’t trip. People are pretty good at not tripping. Clowns can wear enormously oversized shoes… it’s normal for you to not trip (it’s normal for the curves to go off in oscillations at the edges of a boundary) nothing about finding that the usual thing happened should make you think anything unusual is going on.
I’m replying to a comment that hasn’t been approved yet, but whatever… hope it doesn’t break the blog…
Here is a very simple demonstration of why when you run a regression discontinuity on noise, you almost always get two very different results on either side of the discontinuity even when the data is pure noise (or maybe especially).
https://models.street-artists.org/2020/01/09/nothing-to-see-here-move-along-regression-discontinuity-edition/
Includes a simulation and 20 pdf graphs of the results… there’s always something going on in the graph.
Nice simulation. Very convincing.
If only we could get journalists to spend less time on twitter and more time reading these comment sections. I can’t expect this from most reporters, but I’d hope that an outlet such as Vox, which is specifically dedicated to explaining the news, coudl do this.
+1
Ha, that’s great Daniel! Looks just like the data in the paper.
Hi Daniel, those graphs are very convincing but the wikipedia article goes over my head a bit, would you mind expanding on the problem and what solutions we should turn to when using RD?
Thanks a lot
Nathan, take a look below at this comment:
https://statmodeling.stat.columbia.edu/2020/01/09/no-i-dont-think-that-this-study-offers-good-evidence-that-installing-air-filters-in-classrooms-has-surprisingly-large-educational-benefits/#comment-1222138
In general, you should think of regression discontinuity as just another kind of nonlinear model. if y(x) has a discontinuity in overall level, it can be approximated as a quickly rising function such as inverse_logit((x-d)/s) where d is the discontinuity point, and s is the scale for how fast the function rises/falls.
if it has a kink in the slope, you can use something like what andrew posted about a “continuous hinge” a couple years back:
https://statmodeling.stat.columbia.edu/2017/05/19/continuous-hinge-function-bayesian-modeling/
In general I recommend to use these continuous smooth functions rather than discontinuous ones. On the one hand, real things are rarely entirely discontinuous, so it’s the step functions and soforth that are the approximations usually, and on the other hand, smooth functions tend to work better for computational reasons.
Beyond that, you should realize that you *do* have scientific/background information, and use these interpretable basis functions such as the above to help you constrain the problem and regularize it…. For example if you’re looking at test data through time… and someone suddenly implements a new teaching method, no one expects suddenly that the rate of improvement of math scores will go from say 100 points per year to 1000… so you have background information, use it! put constraining priors on coefficients and things.
In general you will get a better fit if you:
1) treat the problem as a nonlinear function approximation problem
2) Use an interpretable set of functions to describe the behavior you could expect, with smooth functions.
3) Provide realistic prior information for the coefficients of the interpretable model
4) Use at least the very basic theoretical knowledge (in this case for example, with the absence of measurable gas levels before the filters, there is no theoretical reason why school performance should be related to distance from a gas leak)
The way RDD as an identification strategy was taught to me was to fit one regression with an indicator variable for the point of discontinuity. This way, you’re not letting the function do different things at both sides, and smooth trends in one side inform the function on the other side. It’s meant to be an identification strategy that controls for smooth trends in covariates, though is still susceptible to confounding for many interesting discontinuities (political boundaries would be one). I don’t know what this “compare two totally different regressions on either side of the discontinuity” thing is, or if it even has a name.
There are an infinity of models with a discontinuity at a given point. In this example, *everything* is discontinuous… the whole model of the world changes from one place to another…
In a more restricted/regularized design you might choose:
y = f(x) + k * step_function(x-d)
which specifies that y steps up it’s average value by an amount k at the point d…
you might also do:
y = f(x) + k * step_function(x-d) + j * integrate(step_function(x-d),x)
which now says in addition to stepping up its average value, it now has an additional trend.
As it stands, if f(x) is a+b*x then this is equivalent to what was done here. It can represent exactly the same functions as the specification a+b*x for x less than discontinuity and a2+b2*x for x greater than the discontinuity… (on the other hand, if the f(x) is a more complex nonlinear function then it represents the smooth nonlinear trend
So, now, we need to bring in background knowledge. First off… we need to acknowledge that if there weren’t any natural gas pollutants, then there is no real reason to believe that the slope is meaningful, so we should put a strong prior that b ~ 0 and j ~= 0 (where ~= is a little stronger than ~ ) with whatever difference from zero there is being due to some geography or whatever.
Next we should say that if there’s a difference in test scores, it shouldn’t be dramatically different from the approximate sizes of the differences in observed test scores in different parts of the county as pollution varies across the county… so k ~ normal(0,s) with s some small number probably like 0.05 to 0.1 or so on the scale they’re using here.
Now, refit the model, and you can get some kind of reasonable inference.
I wasn’t aware of the Runge thing. I’d seen the Gibbs thing before. Neat.
Two thoughts:
1. If you can look at the graph and draw a virtually horizontal line from a point on the left margin to a point on the right margin, staying between confidence limits around both of the regression lines, doesn’t that mean there’s a plausible regression line with slope ~= 0? It’s not a sophisticated evaluation of the data, but it raises a red flag for me.
2. If the air filters suddenly stopped being installed at 5 miles, why does distance greater than 5 miles still predict test score growth? Shouldn’t growth outside of that radius flatline as a function of distance? I didn’t read the paper, so maybe they establish somewhere that there’s a non-filter-related variable associated with scores and that also decreases with distance–like SES or general pollution levels. But then that would mean the authors chose not to adjust the graphed data points for that variable, requiring the reader to mentally rotate the two lines until the one on the right is flat in order to see the net difference due to filters. Right?
More to the point, why does distance from the leak predict growth at all, inside or outside 5 miles? The authors set this up as a binary issue–either you have the filters or you don’t, as determined by whether you were inside the radius or you weren’t. The only reason for looking at distance is if there really was contamination with gas, and readings taken in the schools show there wasn’t. The slope of the score growth as a function of distance is theoretically irrelevant–only the intercept (mean) matters if the filters are the cause of differences between groups. They have instead found evidence that, if there is a real difference, it cannot be caused by filters!
I realize now this is what Andrew meant when he wrote that it’s “a linear trend which makes no theoretical sense,” but I originally thought he was referring to the size/direction of the trend being nonsense, not the fact that there’s no sense in even looking at the trend.
Right, he snuck that in there about the trend and I knew what he meant, but he could have been more explicit about the fact that the trend is meaningless, distance doesn’t play any role… this is very close to monkey pushes button and sees if he gets a potato chip this time…
see below, where you’ll notice that when you fit noise like this you get a potato chip about 90% of the time: https://statmodeling.stat.columbia.edu/2020/01/09/no-i-dont-think-that-this-study-offers-good-evidence-that-installing-air-filters-in-classrooms-has-surprisingly-large-educational-benefits/#comment-1221843
Apparently one of my posts got held up in the spam filter because I linked to a wikipedia page about Runge’s phenomenon or something. But anyway, here’s a link to my blog in which I show that you should expect almost every graph you make of noise arbitrarily broken in half in the middle to have fairly dramatically different slopes and intercepts…. I have basically 20 graphs of pure random noise with outliers, and about 2 of them look like there’s nothing going on, the rest all show dramatic swings in overall level or in slope…
https://models.street-artists.org/2020/01/09/nothing-to-see-here-move-along-regression-discontinuity-edition/
the fact is the discontinuity is known to create this phenomenon. With a discontinuity you have information from only *one side* of the interval informing the fit… when you fit through the discontinuity you get a dramatically different result because under the null hypothesis, the information content is continuous through the discontinuity (slope, overall value, even second or third derivatives) whereas under the alternative hypothesis there is no connection at all between the two halves. Unfortunately for these people who keep doing this all the time… the world isn’t binary, it’s not “everything is the same across this boundary” or “everything is totally different across this boundary” the opposite of “everything is the same across this boundary” is “there exists something that is different across this boundary”
Put another way, regularization is needed here… you want to fit y=f(x) + g(x : x > boundary)
where f incorporates all the data, and g incorporates just the data on one side of the boundary, to show how the results there differ from the overall fit…
instead they fit:
y = f(x : x < boundary) + g(x : x > boundary)
so there is no information shared across the boundary at all… as if on one side of the boundary you have venusians being taught on teleprompters by 7 eyed tentacle beasts, and the other side is humans or something.
Daniel,
Your conditioning argument below seems very sound to me, and clear. Thank you!
As someone who has never fitted any type of discontinuity analysis, do you have a reference/method for performing your suggested regularized model: eg. y(x) = f(x) + g(x : x > boundary).
I don’t have a reference, but the way to think about this is that you’re representing a nonlinear function, so the place to read about it is in function approximation theory. you’re doing a basis expansion basically.
It isn’t just that the g(x) should be windowed at the boundary, but also for regularization it should be from a more limited family of functions than the f(x). In this case they use linear functions for both f and g and then g can “undo” all of f, they become independent functions on either side… if f(x) is from a larger function space, then g(x) is more of a perturbation to it.
This is another form of a prior really.
I agree with most of the criticism of this study. While the main assumption for the validity of a regression discontinuity design seems to be met here (there is nothing special about the 5 mile line that should suddenly change apart from this policy, I think) the sample of schools very close to this line on either side is very small. Therefore, the results depend heavily on modeling assumptions and chance in addition to the identification assumptions.
I disagree with the notion that the analysis Andrew favors deserve a privileged status. Andrew goes so far as to summarize the hypothetical results from his analysis as “*the data showed* no effect”. No, the data alone do not show anything about whether there is a causal effect. Only a combination of assumptions, models, and data can show that. Andrew thinks the assumptions and models of the regression discontinuity are too cumbersome, but I also find the strong assumptions underlying his simpler approach unlikely.
However, I do share Andrew’s implicit intuition that if there’s not a big difference in a simple comparison between treated and untreated, there’s probably not a sizable causal effect. Basically, what are the odds that confounding would almost exactly cancel out the effect? When an involved analysis turns up an effect that wasn’t apparent from a simple comparison, it does seem more likely that there’s really no effect and the analysis screwed something up than that there was an effect that was perfectly cancelled out by confounding that the analysis removed.
Z:
I agree. When I say these data “do not show any clear effect” and that the study “found a null result,” I don’t mean that the true effect is zero. What I mean is that the data are consistent with a zero true effect.
The point of my proposed simpler study is not that it gives the right answer but rather that I think it is a reasonable starting point, in the same way that, if you have survey data, a reasonable starting point is to do some demographic adjustments to line up the sample to the population. That’s not the end point, just a start.
Sure, maybe I’m picking up on unintended implications. To me it came across as “The tortured RD analysis says X but the data show (if you just let them speak for themselves through my simpler analysis) Y”. But I wouldn’t report results from your proposed study as “the data show…” any more than I would report results from the bad RD study as “the data show…”. Even though your analysis is simpler in some sense, it’s not like the simpler analysis is just letting the data speak. Both are “data + assumptions imply…”
Z:
Yes, the data show what the data show, but the real question is about generalizations to other settings, and to do that we need to make lots of assumptions in any case. The simpler analysis does allow the data to speak, but without assumptions the data do not speak to the larger questions of interest.
A relevant (and otherwise) interesting paper by Guido Imbens and Stefan Wager: https://www.mitpressjournals.org/doi/abs/10.1162/rest_a_00793?journalCode=rest
These kinds of spatial RDs typically collapse the spatial discontinuity to a single dimension and then use local linear regression, but better estimators are available.
Another weird thing was, someone linked to this paper on twitter and wrote: imagine how much improvement Delhi schoolchildren would experience in their school performance if air filters were installed there (Delhi is more polluted than the US). wild extrapolation.
Since the article is a pre-print and I would expect (hope) the author would benefit from constructive criticism to make the best use of a unique dataset to study an important problem, is there anything else he could do before reframing the write-up as “I find no evidence that air filters affect students’ performance”? For example, could he try to use the eight years of pre-period data to predict untreated 2016-17 outcomes?
Put differently, is there some way to learn something useful about air pollution from this data? It is an important question. Lots of work in this area finds comparable results with comparable (or worse) methodological faults. Is most we can learn about the question (not the methodology) really nothing?
Greg:
I agree with your general point. In this case, I suspect the sample size is too small to learn anything useful. The estimate of the effect of air filters will be near zero and not statistically significant, but I think the uncertainty interval will be so wide that it would not be appropriate from these data to claim that the effect size is near zero.
It’s a cool natural experiment, but it might be just too small to give any useful information. But, sure, the researcher could do some time-series plots and see if anything turns up.