
This comes up sometimes in my applied work: I want a continuous “hinge function,” something like the red curve above, connecting two straight lines in a smooth way.
Why not include the sharp corner (in this case, the function y=-0.5*x if x<0 or y=0.2*x if x>0)? Two reasons. First, computation: Hamiltonian Monte Carlo can trip on discontinuities. Second, I want a smooth curve anyway, as I’d expect it to better describe reality. Indeed, the linear parts of the curve are themselves typically only approximations.
So, when I’m putting this together, I don’t want to take two lines and then stitch them together with some sort of quadratic or cubic, creating a piecewise function with three parts. I just want one simple formula that asymptotes to the lines, as in the above picture.
As I said, this problem comes up occasion, and each time I struggle to remember what’s a good curve that looks like this. Then after I do it, I forget what I did, the next time the problem comes up. And, amazingly enough, googling *hinge function* gives no convenient solution.
So this time I decided to derive a hinge function from first principles, so we’ll have it forever.
Let’s start with the simplest example, a function y=0 for negative x, and y=x for positive x:
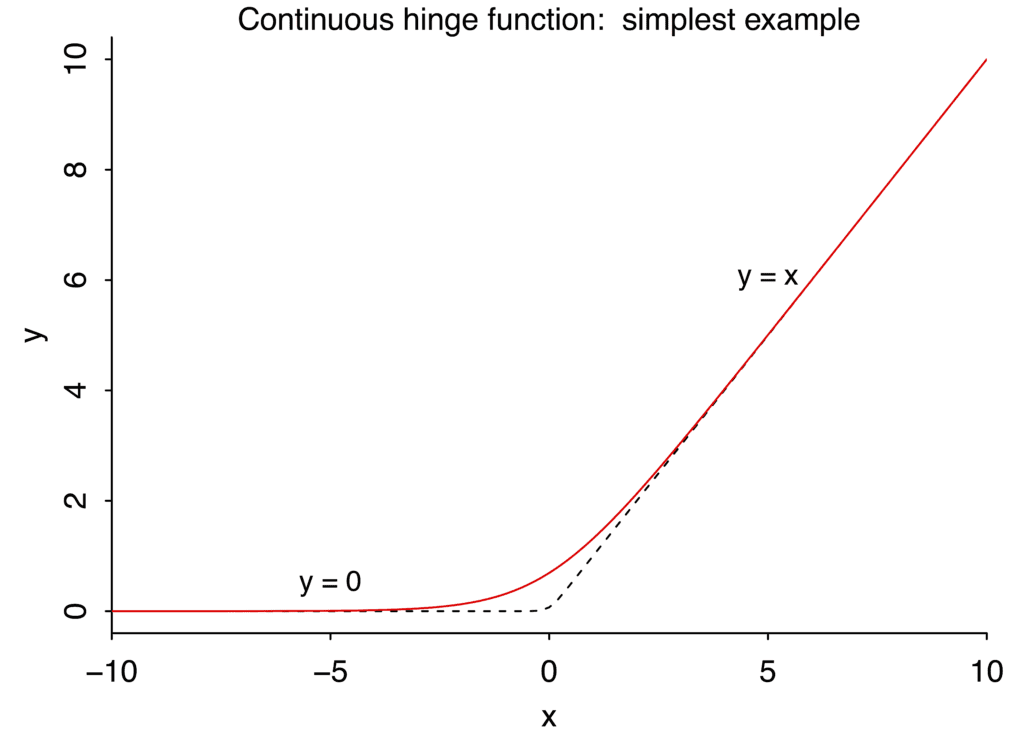
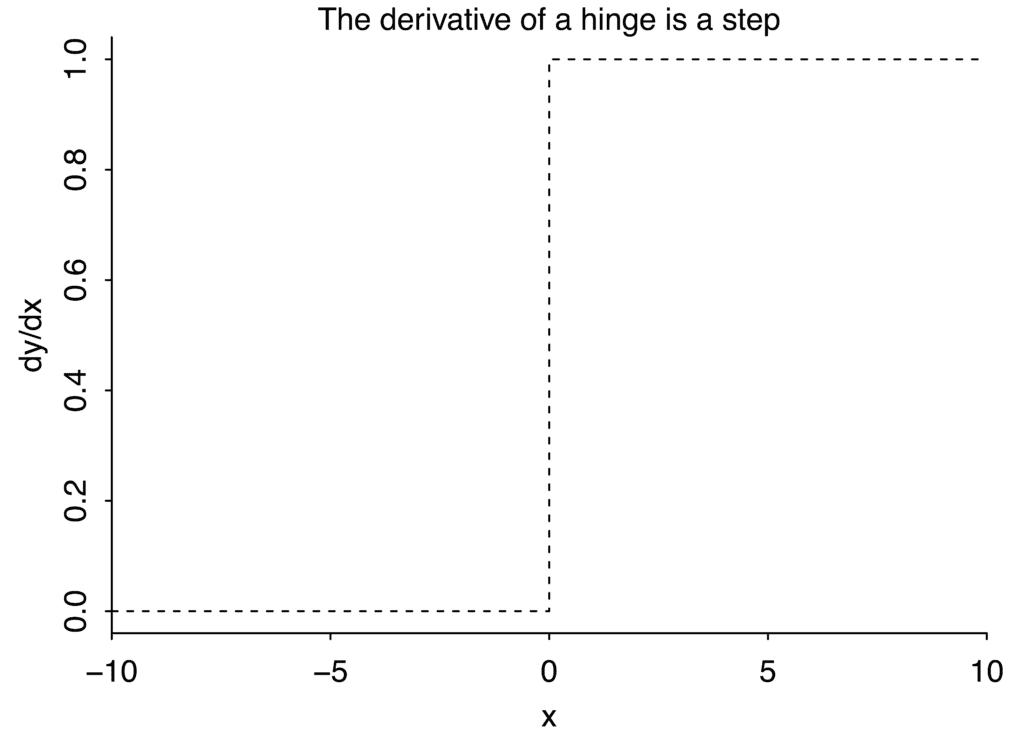
What’s a good curve for this? We can start with the sharp-cornered hinge. Its derivative is just a step function:
Ha! Now it’s clear what to do. We set the derivative to the inverse logistic function, dy/dx = exp(x)/(1 + exp(x)):
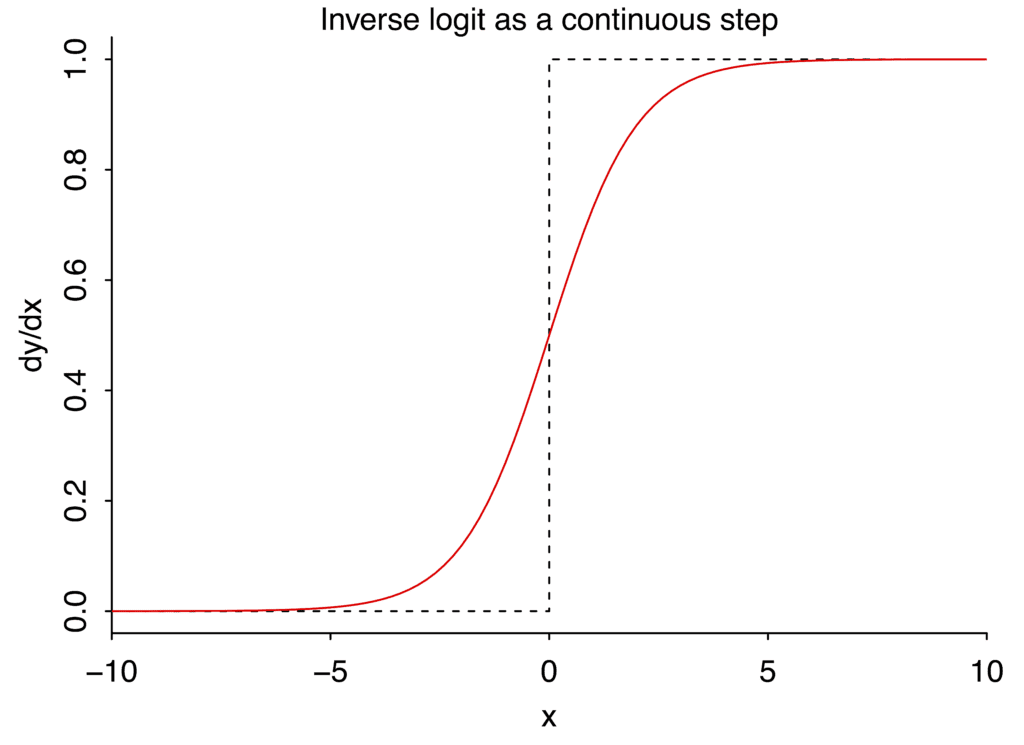
And now we just integrate this to get the original function, the continuous hinge. Integrating exp(x)/(1 + exp(x)) dx is trivial; you just define u = exp(x), then it’s the integral of 1/(1+u) du, which is log(1+u), hence y = log (1 + exp(x)).
And that’s what I plotted in the second graph above, the one labeled, “Continuous hinge function: simplest example.”
More generally, we might want a continuous version of a hinge with corner at (x0, a), with slope b0 for x < x0 and slope b1 for x > x0. And there’s one more parameter which is the distance scale of the inverse-logit, in the dimensions of x. Label that distance scale as delta.
Our desired continuous hinge function then has the derivative,
dy/dx = b0 + (b1 – b0) * exp((x-x0)/delta)/(1 + exp((x-x0)/delta)).
Integrating this over x, and setting it so the corner point is at (x0, a), yields the smooth curve,
y = a + b0*(x – x0) + (b1 – b0) * delta * log (1 + exp((x-x0)/delta))
The top curve above shows the continuous curve with the values x0=2, a=1, b0=0.1, b1=0.5, delta=1.
Playing around with delta keeps the asymptotes the same but compresses or spreads the curving part. For example, here’s what you get by setting delta=3:

In this example, delta=1 (displayed in the very first graph in this post) looks like a better choice if we really want something that looks like a hinge; on the other hand, there are settings where something smoother is desired; and all depends on the scale of x. The above graphs would look much different if plotted from -100 to 100, for example. Anyway, the point here is that we can set delta, and now we understand how it works.
Here’s the function in Stan (from Bob):
real logistic_hinge(real x, real x0, real a, real b0, real b1, real delta) {
real xdiff = x - x0;
return a + b0 * xdiff + (b1 - b0) * delta * log1p_exp(xdiff / delta);
}
And here it is in R:
logistic_hinge <- function(x, x0, a, b0, b1, delta) {
return(a + b0 * (x - x0) + (b1 - b0) * delta * log(1 + exp((x - x0) / delta)))
}
This is not actually the best way to compute things, as the exponential can easily send you into overflow, especially if you set delta to a small number, as you might very well do in order to approximate the sharp corner. Indeed, in the graphs above, I drew the dotted lines using hinge() with delta=0.1, as this was less effort than writing a separate if/else function for the sharp hinge, and these graphs are at a resolution where setting delta=0.1 is close enough to setting it to 0.
What value of delta should be used in a real application? It depends on the context. You should resist the inclination to set delta to a tiny value such as 0.001 or even 0.1. Think of the curving connector piece not just as a computational compromise but as a part of your model, in that real-world functions typically do not have sharp corners.
Also, my R function could be cleaned up---rewritten in a more stable and computationally efficient manner. With the version that I wrote, make sure that the numbers being exponentiated aren't too extreme. If they are far from 0, do some rescaling in the computation to avoid instabilities. The hinge function Bob wrote in Stan is better, I think, in that it uses log1p_exp to avoid some of the worst instability problems.
P.S. Below is the R code for the graphs. Yeah, I know it's ugly. That's part of the point, to show what I do and, I hope, motivate you to do better. I'm not the world's cleanest coder, and I'm not proud of that.
pdf("hinge_1.pdf", height=4, width=5.5)
par(mar=c(3,3,1,1), mgp=c(1.7,.5,0), tck=-.01)
curve(logistic_hinge(x, 2, 1, .1, .5, .1), from=-10, to=10, n=1e5, bty="l", xlab="x", ylab="y", xaxs="i", lty=2)
curve(logistic_hinge(x, 2, 1, .1, .5, 1), from=-10, to=10, n=1e5, col="red", add=TRUE)
mtext("A continuous hinge function")
text(-5, .7, "slope of 0.1", cex=.9)
text(7.2, 2.5, "slope of 0.5", cex=.9)
dev.off()
pdf("hinge_2.pdf", height=4, width=5.5)
par(mar=c(3,3,1,1), mgp=c(1.7,.5,0), tck=-.01)
curve(logistic_hinge(x, 0, 0, 0, 1, .1), from=-10, to=10, n=1e5, bty="l", xlab="x", ylab="y", xaxs="i", lty=2)
curve(logistic_hinge(x, 0, 0, 0, 1, 1), from=-10, to=10, n=1e5, col="red", add=TRUE)
mtext("Continuous hinge function: simplest example")
text(-5, .5, "y = 0", cex=.9)
text(5, 6, "y = x", cex=.9)
dev.off()
pdf("hinge_3.pdf", height=4, width=5.5)
par(mar=c(3,3,1,1), mgp=c(1.7,.5,0), tck=-.01)
curve(ifelse(x<0, 0, 1), from=-10, to=10, n=1e5, bty="l", xlab="x", ylab="dy/dx", xaxs="i", lty=2)
mtext("The derivative of a hinge is a step")
dev.off()
pdf("hinge_4.pdf", height=4, width=5.5)
par(mar=c(3,3,1,1), mgp=c(1.7,.5,0), tck=-.01)
curve(ifelse(x<0, 0, 1), from=-10, to=10, n=1e5, bty="l", xlab="x", ylab="dy/dx", xaxs="i", lty=2)
curve(exp(x)/(1+exp(x)), from=-10, to=10, n=1e5, col="red", add=TRUE)
mtext("Inverse logit as a continuous step")
dev.off()
pdf("hinge_5.pdf", height=4, width=5.5)
par(mar=c(3,3,1,1), mgp=c(1.7,.5,0), tck=-.01)
curve(logistic_hinge(x, 2, 1, .1, .5, .1), from=-10, to=10, n=1e5, bty="l", xlab="x", ylab="y", xaxs="i", lty=2)
curve(logistic_hinge(x, 2, 1, .1, .5, 3), from=-10, to=10, n=1e5, col="red", add=TRUE)
mtext(expression(paste("Continuous hinge function with ", delta, " = 3")), line=-.2)
text(-3.5, .1, "slope of 0.1", cex=.9)
text(7.2, 2.5, "slope of 0.5", cex=.9)
dev.off()
There's also this annoying thing where I make the graphs and view then in pdf---that's fine---but then I have to duplicate them and save them as png files, then upload them one at a time onto the blog, then edit the html. There's gotta be a better approach. I could use Markdown, I suppose, but then I'd have to learn Markdown. Also, I don't really like how Markdown documents look. I'm used to blogstyle.
P.P.S. I don't kid myself that this function is new; I'm sure it's been rediscovered a zillion times. I just find it useful to have the functional form and the derivation here in one place.
Wouldn’t a bezier curve or B-spline be computationally much easier?
Daniel:
I’d like a function that’s easy to write and with all continuous derivatives. I don’t particularly want a curving part that goes all the way to zero outside a finite interval.
The above post is all about modeling a single hinge. When there are a lot of knots, I could see a spline making more sense. As you know from a recent post, I’m a big fan of splines too.
Got it. I wasn’t trying to imply that you hadn’t considered splines—your blog is literally the only place I see the term now that I’m not a student! You answered exactly what I was asking: what the advantages/disadvantages are compared to the curve you proposed.
From a practical-usage standpoint, there can be cases where Andrew’s version (or similar versions using functions other than a line for the two pieces) is a good description of the data, with the location of the “hinge” (x0) being something scientifically meaningful that you would, e.g., like to derive from fitting data.
At least, that’s why I would find something like this potentially more useful than fitting with splines.
I like to build hinges out of ramps, and I like ramp(x) = 0.5*(x + sqrt(x^2 + k)). The parameter k controls the smoothness of the approximation.
Here’s a neat one I derived recently in the course of other work. Take the expectation of the absolute value of Z + x where Z is standard normal and x is the independent variable. This is a kind of smoothed absolute value; any such function can be used to generate a smooth ramp via ramp(x) = x + |x|.
(It turns out that E(|Z + x|) = x*(2*normal_cdf(x) + 1) + 2*normal_pdf(x).)
They use these sort of functions a lot in neural networks: https://en.wikipedia.org/wiki/Rectifier_(neural_networks), they call a slightly simpler version a softplus function
John:
I followed the link and, yes, they use log(1 + exp(x)), which is exactly the same model as what I proposed. Just to be clear, I should emphasize that in my above post I was not claiming any originality on this one; I just found it convenient to have the derivation, code, and graphs all in one place.
To solve your pdf to png problem, why not use the grDevices::png function to create a png in code?
E.g.,
gg <- ggplot2::ggplot(data = mydata, mapping = aes(x = x, y = y)) + ggplot2::geom_line()
png(gg, ""gg.png", width = mywidth, height = myheight, units = 'in', res = 300)
yargh, I didn’t do an explicit package call for png, which I prefer to do in code. Altered code below:
gg <- ggplot2::ggplot(data = mydata, mapping = aes(x = x, y = y)) + ggplot2::geom_line()
grDevices::png(gg, ""gg.png", width = mywidth, height = myheight, units = 'in', res = 300)
YARGH. It’s early and I didn’t get much sleep, so I wrote that code all wrong. Here is how you would ACTUALLY write it.
gg <- ggplot2::ggplot(data = mydata, mapping = aes(x = x, y = y)) + ggplot2::geom_line()
grDevices::png("gg.png", width = mywidth, height = myheight, units = 'in', res = 300)
gg
dev.off()
gg = ggplot(…)
ggsave(“foo.png”) should do it too
+1.
ggsaveis awesome, especially compared to the mess of base graphics output to file and rescaling issues.Perhaps I am just lazy, but I typically use the “zoom” feature in Rstudio, resize the image as I see fit, and then drag and drop it to my directory of choice. I like being able to change the dimensions on the fly.
I just fit this model to some data that I’m working with. Up to this point, I’ve used a non-linear model y = exp(a-bX). The fit is virtually identical between the two models. The non-linear model has fewer parameters, but is not as easy to interpret as the hinge model.
Here’s the Stan function:
real logistic_hinge(real x, real x0, real a, real b0, real b1, real delta) { real xdiff = x - x0; return a + b0 * xdiff + (b1 - b0) * delta * log1p_exp(xdiff / delta); }The value of
x - x0is computed once and reused (helps improve autodiff speed, but not a big deal). This form is so common that we have a specialized form of the log sum of exponentials for it (follow link for explanation of why log-sum-exp is arithmetically stable).P.S. It’s markdown all the way down—WordPress uses its own kind of ad hoc styling and you can also throw in HTML and use their terrible image formatting GUI. The knitr HTML and LaTeX output can be customized. But I don’t know of any decently laid out knitr formats.
P.P.S. WordPress is a disaster for editing user comments, as you can see above—there’s no way for users to preview them and make sure they’re right, so users post, see the mess, try to correct, and repeat (see above). This comment would’ve been a series of comments if I’d had to create it as a user.
P.P.P.S. This would be more efficient if we built in a C++ function with analytic derivatives, but it won’t be bad as written above.
https://bookdown.org/yihui/blogdown/
You might consider Jupyter notebooks for this sort of thing. Although originally designed for Python, the R kernel (https://github.com/IRkernel/IRkernel) seems to work quite well. Google provides several pages describing how to integrate a notebook with WordPress (such as https://www.mianchen.com/wordpress-blogging-with-jupyter-notebook-in-five-simple-steps/).
To deal with the extreme values stuff here’s what you need:
log(1+exp(x)) ~ x for large x, so let’s just call x = 30 large since exp(30) is about 10^13 and double floats have about 15 digits of accuracy. so we’ll define log1pexp that does log(1+exp(x))
log1pexp 30){return(x)} else {return log(1+exp(x))}}
then use log1pexp to do your calculation.
argh, blog ate things after the less than sign…
log1pexp 30){return(x)}else{return(log(1+x))}}
stupid blog
log1pexp = function(x){if(x > 30) return(x) else return(log(1+exp(x)))}
You want to use log sum of exponentials to implement this, noting that 1 = exp(0). This will prevent not only overflow but also rounding down to 0 in log(1 + epsilon) cases when epsilon is near zero.
P.S. This comments section is an excellent illustration of why WordPress comments are broken.
If you don’t like the exponentials, you can integrate an arctan function in the same way. You get a function like this:
a0+a1(x-x0)+a2*(2/Pi)*(ArcTan(x-x0)-(1/2)log(1+(x-x0)^2)).
The two slopes are a1-a2 and a1+a2. If you’re not too picky about having exactly straight asymptotes, you can drop the log and make the function look a little prettier. I don’t know whether such a function has any advantages. I’ve never used it.
This post is also a great example of why it helps to know a little math and a little computation if you want to build bespoke stats models. Knowing how to set the problem up is even more important, and that requires a different kind of math thinking. In some ways you have to know more math to set the problem up, but you don’t actually need to know how to solve the equation because you can just plug the integral of the CDF into Wolfram alpha and let it solve it for you. I used to hate being a calc two teaching assistant—it was just a barrage of integrals to solve long before you could plug them into a web site and get an answer.
I’ve seen this called a fuzzy max or soft max function in system dynamics. In your first example, you’re taking the “soft maximum” of a line with slope 0.1 and another with slope 0.5.
I remember first seeing this issue addressed as “bent-cable regression” in a 2002 Ph.D thesis by Grace Chiu. Not sure if she ever published it.
I like exponential function myself, but it is possible to get away with f^{-1}(1+f(x)) with many a function f(x).
Do:
Ultimately the answer should depend on the application, but I like to use logit as a default because I’m used to logit so I think I kind of understand it.
Neat!
A version of this kind of thing, but describing a broken/bent power-law, was defined by Lauer et al. (1995) for the purposes of fitting galaxy radial surface-brightness profiles (it’s known in the community as the “Nuker law”, for somewhat obscure reasons):
https://adsabs.harvard.edu/abs/1995AJ….110.2622L
And I came up with an equivalent for broken exponentials (for a similar purpose):
https://adsabs.harvard.edu/abs/2008AJ….135…20E
But it’s nice to have the “broken-linear” version available, especially with such a clear explanation of how it was constructed; I can already see a use for it in a paper I’m working on….
OK, URLs got slightly mangled by the blog software. These should hopefully link correctly:
Lauer et al. (1995)
Erwin et al. (2008)
I’ve often wondered why more models in stats aren’t just described/derived by differential equations.
It’s a very convenient way to generate interpretable nonlinear models (even linear odes give simple nonlinear functions).
Is this what some people call ‘functional data analysis’?
No, “functional data analysis” just indicates that functions are being treated as the basic unit of observation (as opposed to scalars or vectors), e.g., N observations means N trajectories or times series or spatial fields or what have you. See https://cran.r-project.org/web/views/FunctionalData.html for how that plays out in practice.
But they emphasise the use of derivative information to characterise said functions right?
From https://www.psych.mcgill.ca/misc/fda/
“But what is unique about functional data is the possibility of also using information on the rates of change or derivatives of the curves. We use slopes, curvatures, and other characteristics made available because these curves are intrinsically smooth, and we can use this information in many useful ways.”
So yes, obviously what you say is correct in the literal sense, but I suppose I’m wondering about the broader perspective of eg using derivative information directly in data analysis and/or (statistical) model definitions.
Funnily enough I just found this:
‘Dynamic Data Analysis: Modeling Data with Differential Equations’
by Ramsay and Hooker, building on functional data analysis ideas.
(See https://www.springer.com/gp/book/9781493971886)
So maybe ‘dynamical data analysis’ is a better term than ‘functional data analysis’ for what I was getting at.
I consider Gaussian process regression to be an FDA method, and there’s no intrinsic restriction to smooth functions there. But it’s true that smoothness conditions are appropriate for a great many applied settings.
Yup, fair enough. Technically, even dynamical systems need not be smooth – there is such thing as a ‘non-smooth dynamical system’.
Thank you for this nice explanation. This helps a lot in avoiding discontinuities in my probabilistic models.
max(x-x0;0) = delta*log(1+exp((x-x0)/delta))
Very nice and (relatively) simple derivation. Thanks!
Does anybody know about a reference? I understand the math is quite simple, but I don’t want pass the idea as mine. Thanks.