Fritz Strack points us to this new paper, A multi-semester classroom demonstration yields evidence in support of the facial feedback effect, by Abigail Marsh, Shawn Rhoads, and Rebecca Ryan, which begins with some background:
The facial feedback effect refers to the influence of unobtrusive manipulations of facial behavior on emotional outcomes. That manipulations inducing or inhibiting smiling can shape positive affect and evaluations is a staple of undergraduate psychology curricula and supports theories of embodied emotion. Thus, the results of a Registered Replication Report indicating minimal evidence to support the facial feedback effect were widely viewed as cause for concern regarding the reliability of this effect.
But then:
However, it has been suggested that features of the design of the replication studies may have influenced the study results.
So they did their own study:
Relevant to these concerns are experimental facial feedback data collected from over 400 undergraduates over the course of 9 semesters. Circumstances of data collection met several criteria broadly recommended for testing the effect, including limited prior exposure to the facial feedback hypothesis, conditions minimally likely to induce self-focused attention, and the use of moderately funny contemporary cartoons as stimuli.
What did they find?
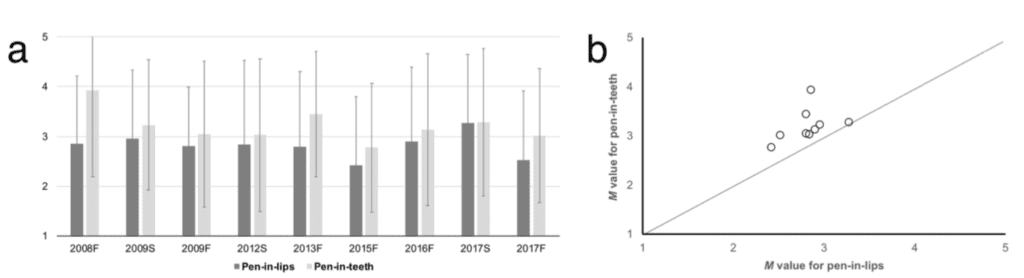
Results yielded robust evidence in favor of the facial feedback hypothesis. Cartoons that participants evaluated while holding a pen or pencil in their teeth (smiling induction) were rated as funnier than cartoons they evaluated while holding a pen or pencil in their lips (smiling inhibition). The magnitude of the effect overlapped with original reports.
Their conclusion:
Findings demonstrate that the facial feedback effect can be successfully replicated in a classroom setting and are in line with theories of emotional embodiment, according to which internal emotional states and relevant external emotional behaviors exert mutual influence on one another.
Here are the summaries, which, when averaged over all the studies, show a consistent effect:
I’ll leave it to others to look at this paper more carefully and fit it into the literature; I just wanted to share it with you, since we’ve discussed these replication issues of facial feedback experiments before.
Fritz is also on a new preprint that suggests the effect exists https://psyarxiv.com/cvpuw?fbclid=IwAR0KyIptn9wD2r_w8pBDxGzbRFpPfh1YUSqMsKqHA9Ma-97MqsqDUD3A5mw . It’s sort of neat since it was a (at least semi-) adversarial collaboration.
Quote from above: ” It’s sort of neat since it was a (at least semi-) adversarial collaboration.”
I never understood why this is “neat”. I think it doesn’t matter whether something is, or is not, an adversial collaboration. Next thing you know, folks will all be telling themselves (and others) that something is, or is not, “good science” because it involved, or not involved, people with “adversarial” ideas…
Regardless of this (or perhaps the following might actually be directly related to the above), i am puzzled by the following sentences of the preprint you provided the link for. On page 7 the following is written:
“We define foundational test as the identification and testing of researchers’ core beliefs regarding the conditions in which a hypothetical effect should most reliably emerge. Importantly, these beliefs are specified a priori. Therefore, whether this predicted effect emerges can provide insight into the degree that these core beliefs are correct. Failing to find the predicted effect, of course, does not necessarily mean that the hypothesis or theory is invalid. However, it can provide evidence that researchers’ core beliefs regarding this hypothesis or theory are invalid”
Uhm, i thought the goal of psychological science was to come up with theories, and test them via hypotheses, and reformulate theories based on the subsequent findings. If this makes (at least some) sense, can anybody explain to me what words like “researchers’ core beliefs” and “foundational test” are doing in a scientific paper?
When scientists have some manner of disagreement about the best way to operationally define something, or to design a study to test a hypothesis they disagree on, the disagreement needs to be worked out. My personal opinion is that doing it in advance so that both sides say “yes, this accurately tests what I think we should be testing” before there are any results to post-hoc about, is a positive. It doesn’t mean that non-adversarial studies are bad or lacking.
My opinion comes in part from my (previous) research field. My lab had a particular belief about what a certain kind of brain damage would do to performance on certain tasks, and another lab had an opposing belief. If you were deep in it and closely reading the studies you could usually see that there were (probably) theoretically important differences in the kinds of materials and study design between the two labs. Could everything have been worked out in the literature? Probably, but it really was just papers talking past each other. I think an adversarial collaboration would have been very helpful for clarifying who thought what features were important and why, and then developing a design that everyone agreed was a good one.
To the rest, if you keep up with the reproducibility stuff (either here on Gelman’s blog or in general) you know that researchers are surprisingly fluid in what they consider to be supporting or disproving evidence for their theories. It isn’t uncommon for someone to have a theory, to have someone else fail to find evidence for it, and for the first person to say “oh, well not under *those* conditions.” So yeah, I guess that would be related to what I said before: adversarial collaborations can be helpful by making people specifically state for the record, ahead of time, what’s really critical (core) to your theory. To use the Power Pose stuff as an example, is it the exact pose? Is it how long you hold the pose? Is it just how you feel? These things apparently never got spelled out until the shit hit the fan.
As a lawyer, this seems obviously right to me. “Sort of neat” seems like a fair characterization.
Quote from above: “So yeah, I guess that would be related to what I said before: adversarial collaborations can be helpful by making people specifically state for the record, ahead of time, what’s really critical (core) to your theory. To use the Power Pose stuff as an example, is it the exact pose? Is it how long you hold the pose? Is it just how you feel? These things apparently never got spelled out until the shit hit the fan.”
I think i understand the gist of what you are trying to say, and what people are trying to do. I just reason this makes little sense.
Why should i care about what a certain group of “adversarial collaborators” collectively have decided what their view of what is “crucial” to a certain theory is? It isn’t necessarily an accurate view for instance, nor does such an “adversarial collaboration” necessarily lead to a “good test”.
I fear this will only lead to certain topics and certain people keep being involved in these types of “collaborations” just because they are somehow viewed as being “important” or an “expert” member of side A or B of the “adversarial divide”.
Perhaps mr. Strack himself might be a nice example of this: he was asked as an “expert” to provide his opinion concerning the Registered Replicarion Report of his pen in mouth paper if i am not mistaken, and he is now part of this new replication project again.
Quoting from Anonymous above:
I think the point is that rarely does anyone come up with anything like a specific enough theory that it can actually be tested. If you say “some stuff should happen if you put something in your mouth” how do you test that? If you say “If I randomly assign a group of undergrads to either rate the funniness of comics, or rate the funniness of comics while holding a Staedtler number 2 pencil in their teeth, then the pencil group will consistently rate the commic as funnier” then you can test it, but who really gives a hoot? I mean, stupid conditions. It had better be a more generalized situation than “undergrads” that are “randomly” assigned to hold a *particular brand and size of pencil* in their teeth while “rating comics”…. otherwise it has no relevance to anything that actually happens in the world.
So now you need a theory like “being forced into having a certain kind of facial expression consistently alters your mood on average” which again… totally un-testable as stated…. So now you need something like a *wide variety of instances in which you can manipulate the facial expression and measure the mood*….
So now we know what is really required for any of this to make any difference at all: a wide variety of manipulations, to a wide variety of target audiences, in a wide variety of circumstances, and a consistent alteration to the measurement of mood in the comparison groups, of a size that matters practically (like say, similar in magnitude to other manipulations people obviously care about like giving mood altering medication or going on vacation or something).
Much of current psych science is obviously far from this ideal of widely applicable theories about practically important common topics
Quote from above: “So now we know what is really required for any of this to make any difference at all: a wide variety of manipulations, to a wide variety of target audiences, in a wide variety of circumstances, and a consistent alteration to the measurement of mood in the comparison groups, of a size that matters practically (like say, similar in magnitude to other manipulations people obviously care about like giving mood altering medication or going on vacation or something).”
I very much agree with you! Especially the part about practically important sizes of effect, and different manipulations.
I simply note that, with this specific preprint proposal “foundational test”-study (and a lot of recent large scale “collaborative” efforts) this is not done (optimally) in my reasoning. Perhaps they even emphasize statistically significant findings over practically significant findings. And perhaps they even emphasize a single manipulation over a wide variety.
(As a result of your comment, i was reminded of an idea i posted, and linked to many times, on this blog. The idea tries to take, how i interpret the gist of your comment, into account by emphasizing (practically important) effect sizes, multiple manipulations/variances of variables and/or hypotheses, and theory testing and-reformulation. It’s the best idea i had about how to possibly optimally perform psychological research: https://statmodeling.stat.columbia.edu/2017/12/17/stranger-than-fiction/#comment-628652)
Quote from above: “Uhm, i thought the goal of psychological science was to come up with theories, and test them via hypotheses, and reformulate theories based on the subsequent findings. If this makes (at least some) sense, can anybody explain to me what words like “researchers’ core beliefs” and “foundational test” are doing in a scientific paper?”
I have found the following 2 quotes which could shed some light of what exactly a “foundational test” could be:
1) “To provide a foundational test of the facial feedback hypothesis, a large and diverse group of researchers came together to (1) specify their beliefs regarding when facial feedback effects should most reliably emerge, (2) determine the best way(s) to test those beliefs, and (3) use this information to design and execute an international multi-lab experiment.”
2) “Notably, this specific combination of scenarios has never been tested in a single facial feedback experiment, further demonstrating the distinction between a foundational tests and direct replications”
I wonder if what they are calling “foundational test” is basically the same as what i would simply call “designing an experiment to test an hypothesis related to a certain theory”?
Quote from above: “I wonder if what they are calling “foundational test” is basically the same as what i would simply call “designing an experiment to test an hypothesis related to a certain theory”?”
I still reason a “foundational test” is basically the same as what i would simply call “designing an experiment to test an hypothesis related to a certain theory”. I just re-read the following sentences from the preprint concerning a “foundational test”:
“We define foundational test as the identification and testing of researchers’ core beliefs regarding the conditions in which a hypothetical effect should most reliably emerge. Importantly, these beliefs are specified a priori. Therefore, whether this predicted effect emerges can provide insight into the degree that these core beliefs are correct. Failing to find the predicted effect, of course, does not necessarily mean that the hypothesis or theory is invalid. However, it can provide evidence that researchers’ core beliefs regarding this hypothesis or theory are invalid”
If the “foundational test” does not provide the predicted effect, but this in turn does not “invalidate the hypothesis or theory”, does this mean you can keep doing “foundational tests” until one of them does “finds the predicted effect”?
And if so, how is this different from something like “selective reporting” of analyses, or putting away studies in the “file drawer”, where the results of tests, and studies are (also?) not consequential for the hypothesis or theory?
I wonder if a using a word like a “foundational test” is a great way to be able to not have to really do anything with results of your experiment if they are not in line with, and concerning, your current hypothesis or theory. If i understand the concept of a “foundational test” correctly, i reason theories, and hypotheses, will basically be immune to opposing evidence, because obviously only the “core beliefs” of the researchers concerning the hypothesis and theory might not be correct!
Am i understanding things correctly here that, for instance, when in this upcoming “facial feedback” experiment involving a “foundational test” the predicted effect will not be found, they can conclude something like “these unexpected findings make clear that our ‘core beliefs’ are probably wrong, but this does not subsequently influence our hypothesis (or theory) in any way whatsoever”?
Thank you for including the link of a previous discussion concerning this all https://statmodeling.stat.columbia.edu/2017/09/27/somewhat-agreement-fritz-strack-regarding-replications/
I would also like to include the more recent discussion concerning this all here https://statmodeling.stat.columbia.edu/2018/11/01/facial-feedback-findings-suggest-minute-differences-experimental-protocol-might-lead-theoretically-meaningful-changes-outcomes/
I hope it’s okay for me to point to the following comment back-and-forth between myself and mr. Strack on that blogpost:
https://statmodeling.stat.columbia.edu/2018/11/01/facial-feedback-findings-suggest-minute-differences-experimental-protocol-might-lead-theoretically-meaningful-changes-outcomes/#comment-911003
Here is “Bad Company” again with “Crazy Circles”: https://www.youtube.com/watch?v=g0tb9Tp1nVA
Never sure what to make of this kind of thing. ‘Cuing’ is part of how you organize a performance, whether it’s your lecture or a vaudeville show. Can you imagine reaching a difficult part of a talk about separating the threads of multi-level inferences and you suddenly pull out a seltzer bottle? If you go on after an act that dies or one that tears up the stage, you have a harder job – or you’re being sacrificed for the good of the show. The job of the MC is to connect the acts, so they don’t show you a short movie of a dog being shot just before the comedian. My guess is that people have been doing this since they started entertaining each other in small bands, and people would say ‘no one wants to follow Urgg because he’s so funny’. So sure if you form the face into a smile, then people are slightly more receptive, which is something street performers do, which pretty much any performer does in their entrance. Here’s Johnny! Wow, you’re a great audience. Not like last night’s.
One of my favorites is a thing some people do at weddings or events, which is to talk to some of the people at their table and form a conspiracy to laugh all at once to give the impression this is the fun table. It works incredibly well: people relax and have a much better time. It’s basic social cuing. Why is there such interest in finding out small examples of something that can be studied on much larger, more repeating scales? I fail to see the use in the idea that holding a pencil in the mouth causes ‘funny’ ratings but I can see the use in all sorts of social symbolisms. The size of the effect shows that there’s no magic way to induce funny. One of my favorite street performers – who did a lot of corporate work – used a technique from patent medicine shows: step closer. He’d get the crowd to press in by timing his step closer repetitions so they hit right when you were listening. Beautiful pacing. His biggest bit was beating some guy at poker using giant cards that everyone could see, just by confusing the heck out of him. One of the greats of street manipulation.
Many years ago, I met a terrific pick-pocket and confidence man. Utterly remarkable skills at reading people close up, seeing their vulnerabilities. One thing he explained to me was that the choice of target mattered much more than technique, that really the most important technique was the choice of target, because people who are oblivious or who can be distracted in specific ways don’t notice anything else. This is also how ‘pick-up’ artists work. They identify a type, see the defenses, see how they can be breached. Chess masters think the same way. (Disclosure: when I was a kid, I’d take watches off people’s wrists and give them back (because I’m not a thief), and it was very easy; you just did it while their minds were elsewhere. A couple of taps on the end of the strap. You can do it while walking.) All of this is cuing and reading visible cues. There is no magic in it, just close observation. A decent performer can notice the ability to smile in an audience.
I’ll repeat my objection from the last time we discussed this. When I hold a pen in my mouth, it is almost painful not to use my teeth. Wouldn’t this affect my ratings about humor? So, I can believe the ratings differ significantly (p<.05, .01, or whatever), but I fail to see that it is measuring perception of humor rather than the degree of discomfort of the participant. In any case, and perhaps more importantly, I fail to see how these results can be interpreted as meaning anything about attitudes towards humor, perceptions of individual traits, or much else. I am concerned about extrapolating the results of such studies to mean anything of practical significance.
“Cartoons that participants evaluated while holding a pen or pencil in their teeth (smiling induction) were rated as funnier than cartoons they evaluated while holding a pen or pencil in their lips (smiling inhibition)”
The manipulation is almost an Onion parody.
It’s believable that holding a pen or pencil in your teeth could make you feel absurd, so almost anything would seem funnier under that condition than if you were behaving normally.
The problem with a lot of these studies is that even if the statistical part of the analysis is correct, you still have to eliminate a lot of other potential interpretation to come to their favorite conclusion. Maybe it’s the physical discomfort you mentioned, maybe it’s because holding something in your lips just seems more stupid than holding it with teeth and puts one in a bad mood, maybe it’s the different rates of saliva secretion, etc.
And why is ranking moderately funny cartoons funnier a good proxy for positive emotion?
Two quick thoughts:
1) It is probably not ideal to inform your participants of the anticipated effect before you physically collect the data from them (see page 7).
2) Since this was a within-subjects design I would like to see some discussion of the proportion of participants whose ratings were consistent with the facial feedback hypothesis. Was a small effect spread across many/most participants or a large effect for a small proportion and a near null effect (with some negatives) for most others? Presumably the effect, if it exists at all, is not universal.
I really like the idea of summarizing the distribution of person-level effects with like a histogram or density plot or something. Or maybe graphing individual differences (smiley teeth – sad lips) across key characteristics of the subjects and adding a smoothed mean curve of the difference. The within-person disaggregation seems like it should be an obvious thing to do, but in general people seem to choose one level of aggregation and stick with it. I’m not sure where that comes from and why people are hesitant to do analyses at alternative levels. But I learn a lot more about a dataset when I see information coming from a number different levels of aggregation.
The title of this blogpost (“Facial feedback is back”) reminded me of the opening lyrics of the LL Cool J song “Mama said knock you out”:
“Don’t call it a comeback
I’ve been here for years
(I’m rocking my peers
Puttin’ suckers in fear)”
I was also reminded of what i found, and wrote, in an earlier discussion about this “facial feedback” hypothesis (linked to somewhere in this comment section as well):
“In 1980 (almost 40 years ago !!!!!), based on many papers, findings, and theories, Buck wrote the following in the paper’s conclusion section: “At present there is insufficient evidence to conclude that facial feedback is either necessary or sufficient for the occurrence of emotion, and the evidence for any contribution of facial feedback to emotional experience is less convincing than the evidence for visceral feedback.”
Here is a sweet cover of “Mama said knock you out” by Eagle-Eye Cherry:
https://www.youtube.com/watch?v=S609LUs1GEM
What a great birthday present: “Facial feedback is back!”
I would have never predicted that a study that was not really on my main track of research would attract that much attention.
But it was (and still is) great fun to participate in so many animated discussions and to experience “epistemology applied”.
All I can surmise is that Fritz must walk around with a smile on his face while I have a frown.
Quote from above: “I would have never predicted that a study that was not really on my main track of research would attract that much attention.”
Perhaps you could thank the “replicators” and their large-scale “collaborative” efforts for that!
I reason they, and these type of projects, have and will result in giving attention (and lots of resources) to this all for a 2nd time around!
Quote from above: “Perhaps you could thank the “replicators” and their large-scale “collaborative” efforts for that! I reason they, and these type of projects, have and will result in giving attention (and lots of resources) to this all for a 2nd time around!”
Who actually decides where the many resources concerning large-scale “collaborative” efforts like “Registered Replication Reports” (and perhaps even subsequent predictable follow-up efforts) are spend on?
If that’s only a small group of people, i would totally try and get them to replicate my research of 20 years ago if i were a “famous professor”!
I would probably get into the newspapers again, would probably amass lots of new citations, and would probably be asked to “help out” with all kinds of new projects related to my findings of decades ago!
It would almost be like reliving my glory days!
Here is Bruce Springsteen’s “Glory days”:
https://www.youtube.com/watch?v=6vQpW9XRiyM
Absolutely! I love replications….as long as we can learn something from them that goes beyond “not real”.
Quote from above: “Absolutely! I love replications…”
Enjoy them while you can! I predict replications will not even be performed anymore in the future!
Here is a new project by the “Center for Open Science” in collaboration with DARPA (“Defence Advanced Research Projects Agency”). I find it weird that these parties are working together, but perhaps that’s all perfectly normal. Anyway, here is some information about the project:
https://cos.io/about/news/can-machines-determine-credibility-research-claims-center-open-science-joins-new-darpa-program-find-out/
“DARPA identifies the purpose of SCORE is “to develop and deploy automated tools to assign ‘confidence scores’ to different SBS research results and claims. Confidence scores are quantitative measures that should enable a DoD consumer of SBS research to understand the degree to which a particular claim or result is likely to be reproducible or replicable.”
Interesting. Are the results going to be secret?
Quote from above: “Interesting. Are the results going to be secret?”
Of course not, it’s partly by the “Center for Open Science” which name surely implies that they are all about being “open” and “transparent”! I mean, why else would they have chosen their name!!
(Side note: the “Center for Open Science” are perhaps all about being “open” and “transparent” except when they promoted the h#ck out of “Registered Reports”. A format that, if i am not mistaken, did not in their introductory papers, and to journals, and authors, make clear that they should really provide a link to any pre-registration or else it wouldn’t really be “open” and “transparent” at all. E.g. see https://www.nature.com/articles/s41562-018-0444-y
As another side note to another one of their promoted efforts, please also see the “Registered Replication Report” of your pen-in-mouth study and try and see if they “registered” the exact labs who participated. If they are all about “transparency”, i reason they should value pre-registration of analyses (because otherwise researchers could leave some out of the final report), as much as value pre-registering the labs who will participate (because otherwise researchers could leave some out of the final report).
Come to think of it, i have very recently started to ponder whether the “Center for Open Science” (COS) should actually (also?) be called “Controllers of Science” (COS) because a lot of their efforts to me seem to all involve giving power and responsibilities to an increasingle smaller group of people (all in the name of “collaboration” and “improvements” of course!). Also see the comment section here: https://blogs.plos.org/absolutely-maybe/2017/08/29/bias-in-open-science-advocacy-the-case-of-article-badges-for-data-sharing/
To me, it’s almost starting to become hilarious, because it’s like they took a critical paper about the current state of affairs in academia by Binswanger (2014), and mistook it for a playbook: https://link.springer.com/chapter/10.1007/978-3-319-00026-8_3)
Quote from above: “Enjoy them while you can! I predict replications will not even be performed anymore in the future!”
I just read this https://pursuit.unimelb.edu.au/articles/the-credibility-of-research-needs-you?utm_source=twitter&utm_medium=social&utm_content=story and i now also predict that next to replications, original research, will not even be performed anymore in the future!
In the future, teams of “experts” will all be “collaborating” to use “the wisdom of the crowd” to decide which research hypothesis would probably result in “significant” results if they would actually perform the research. However, and in line with a quote from the article linked to above: The problem is, we simply can’t afford to be performing every piece of research before it’s published – it will be too costly and time consuming. “Prediction markets” and algorithms are super useful to save money by not even performing any actual science anymore!
On a (slightly) more serious note, i never understood this “prediction market” stuff. I always thought it sends out a wrong message concerning science that will likely only lead to unscientific things like not actually performing replications, and not really tackling the reasons why research might be unreplicable. I additionally thought it could also lead to bigger projects, like this new massive one. My worries, and fears, have already become true in that regard…
(Some side notes: The article itself is lacking, and possibly misrepresenting things, to me as well:
1) It mentions that “The problem is, we simply can’t afford to be testing and replicating every piece of research before it’s published – it will be too costly and time consuming. For example, an effort to replicate 15 cancer biology studies took an average of seven months for each study at a cost of US$27,000 each.” but the project seems to be about social science research which i think cost way less to replicate than 27 000 dollars for the biology studies. It seems a gross misrepresentation.
2) It mentions that “People need to have confidence in published research findings if the important research work being done in the social sciences is going to be picked up and make a difference.” I don’t know what this means precicely, but i am always annoyed with researchers who are talking about policy, etc. Your first job as a scientists is to try and understand/predict/whatever behaviour or phenomena, not talk about stuff like the quoted sentence.
3) It mentions that “But peer review based on the opinions of just a couple of individuals clearly isn’t a good enough guide as to how replicable research is.” and then goes on to talk about how they are going to need thousands of experts. However a few sentences later it states that “We are going to ask groups of five or six experts each to assess together the replicability of each research claim using the benefit of each other’s expertise.” So, how is this not the same as “the opinions of just a couple of people”?
4) It mentions that “We expect our crowd will do better at identifying potential failures to replicate, compared to traditional peer review, because of the structured deliberation protocol and elicitation methods we are employing,” says Associate Professor Fidler.” How can this be examined when, as far as i understand, the goal of peer-review is not primarily about deciding whether the research is replicable or not?
5) It mentions that “Usually it is the experts who need public volunteers to participate in surveys and experiments. But this time it is the other way around. Public confidence is demanding the experts step up. Science needs you.” First of all, “i have had it with all these m@therf#cking experts on all these m@therf#cking panels, and papers, and boards, and committees.” (possibly spot the Samuel L. Jackson “Snakes on a plane” reference). Second of all, they talk about recruiting undergraduate students which i don’t get if they are talking about “experts”. Perhaps by “Experts” they really mean “scientists”.)
Quote from above; “i have had it with all these m@therf#cking experts on all these m@therf#cking panels, and papers, and boards, and committees.” (possibly spot the Samuel L. Jackson “Snakes on a plane” reference)”
I have been reading a translation, and interpretation, of the “Tao Te Ching” in the past weeks/months(?). Today i reached, what i believe to be, the final chapter: chapter 81 https://www.taoistic.com/taoteching-laotzu/taoteching-81.htm.
In the interpretation of the chapter i read the following, which i thought fitted well concerning some of the things i wrote above, and perhaps even concerning some unexpressed and/or unaware thoughts and feelings behind what i wrote. I hope it’s okay for me to quote it here:
“So, the more human knowledge is gathered, the less we know and the farther we get from understanding. There is less and less that we dare to believe we comprehend, without being experts on it.
That way, our society is quickly moving towards a world ruled by experts, as if there are always facts demanding this or that solution, and neither priorities nor ideals have anything to do with it. As if society is merely a machine and we are its fuel.
But facts are often inconclusive and experts are rarely infallible. Any social situation is so complex that several options are present. When we make our choices, we need to consider what future we want to reach.
We cannot surrender our responsibilities to facts that are yet uncertain or ambiguous. Nor can we allow those who claim to be the most learned to make all our choices for us. That ends in a world nobody wanted.
Knowledge without true understanding is blind. If we follow the blind we are sure to leave the Way.”
“I’ll leave it to others to look at this paper more carefully”
It seems strange that you have nothing to say about a study that conforms to two of your most consistent recommendations (within-subjects, hierarchical model) and provides evidence for a finding that perhaps you have determined is unlikely to exist. Why so mum?
Quote from above:”(…) and provides evidence for a finding that perhaps you have determined is unlikely to exist”
I have been thinking about this, also as a result of this discussion:
What does it mean for the validity/truth value (or whatever the appropriate term is here) of a “finding” when manipulation X (e.g. that of the original Strack et al. paper) does not seem to work (anymore), and manipulation Y (e.g. this new proposal) does?
The more i think about it, the less i think that there even such a thing as “a finding” in psychological science. There is only “a finding” that is very probabably closely related to, and dependend on, the manipulation, and measurement.
If this makes any sense, i reason discarding manipulation X while accepting manipulation Y could possibly not be scientificly sound as i reason it is (the same or) similar to selective reporting/file-drawer problem…