Someone writes:
I’m a postdoc studying scientific reproducibility. I have a machine learning question that I desperately need your help with. . . .
I’m trying to predict whether a study can be successfully replicated (DV), from the texts in the original published article. Our hypothesis is that language contains useful signals in distinguishing reproducible findings from irreproducible ones. The nuances might be blind to human eyes, but can be detected by machine algorithms.
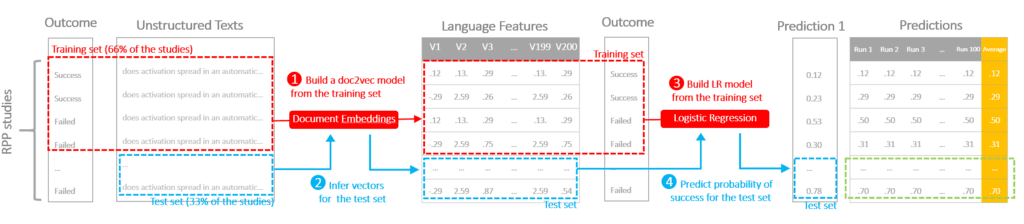
The protocol is illustrated in the following diagram to demonstrate the flow of cross-validation. We conducted a repeated three-fold cross-validation on the data.
STEP 1) Train a doc2vec model on the training data (2/3 of the data) to convert raw texts into vectors representing language features (this algorithm is non-deterministic, the models and the outputs can be different even with the same input and parameter)
STEP 2) Infer vectors using the doc2vec model for both training and test sets
STEP 3) Train a logistic regression using the training set
STEP 4) Apply the logistic regression to the test set, generate a predicted probability of success
Because doc2vec is not deterministic, and we have a small training sample, we came up with two choices of strategies:
(1) All studies were first divided into three subsamples A, B, and C. Step 1 through 4 was done once with sample A as the test set, and a combined sample of B and C as the training set, generating on predicted probability for each study in sample A. To generate probabilities for the entire sample, Step 1 through 4 was repeated two more times, setting sample B or C as the test set respectively. At this moment, we had one predicted probability for each study. Subsequently, the entire sample was shuffled to create a different random three-fold partition, followed by same three-fold cross-validation. A new probability was generated for each study this time. The whole procedure was iterated 100 times, so each study had 100 different probabilities. We averaged the probabilities and compared the average probabilities with the ground truth to generate a single AUC score.
(2) All studies were first divided into three subsamples A, B, and C. Step 1 through 4 was first repeated 100 times with sample A as the test set, and a combined sample of B and C as the training set, generating 100 predicted probabilities for each study in sample A. As I said, these 100 probabilities are different because doc2vec isn’t deterministic. We took the average of these probabilities and treated that as our final estimate for the studies. To generate average probabilities for the entire sample, each group of 100 runs was repeated two more times, setting sample B or C as the test set respectively. An AUC was calculated upon completion, between the ground truth and the average probabilities. Subsequently, the entire sample was shuffled to create a different random three-fold partition, followed by the same 3×100 runs of modeling, generating a new AUC. The whole procedure was iterated on 100 different shuffles, and an AUC score was calculated each time. We ended up having a distribution of 100 AUC scores.
I personally thought strategy two is better because it separates variation in accuracy due to sampling from the non-determinism of doc2vec. My colleague thought strategy one is better because it’s less computationally intensive and produce better results, and doesn’t have obvious flaws.
My first thought is to move away from the idea of declaring a study as being “successfully replicated.” Better to acknowledge the continuity of the results from any study.
Getting to the details of your question on cross-validation: Jeez, this really is complicated. I keep rereading your email over and over again and getting confused each time. So I’ll throw this one out to the commenters. I hope someone can give a useful suggestion . . .
OK, I do have one idea, and that’s to evaluate your two procedures (1) and (2) using fake-data simulation: Start with a known universe, simulate fake data from that universe, then apply procedures (1) and (2) and see if they give much different answers. Loop the entire procedure and see what happens, comparing your cross-validation results to the underlying truth which in this case is assumed known. Fake-data simulation is the brute-force approach to this problem, and perhaps it’s a useful baseline to help understand your problem.
Why not just use a larger number of folds instead of repeating the 3-fold cross-validation? Ten-fold CV will use 90% of the data for training instead of 2/3, reducing bias, and will take 15 times as long to train (assuming training time dominates and is linear in the number of training examples, 10*9/(3*2)=15. I believe 25-fold CV will take exactly 100 times as long as 3-fold according to the same crude computation.
I found the following study concerning the means of such “repeated CVs”, and while I haven’t read it in depth, it appears to be pretty pessimistic about the mean of CV statistics being useful at all
https://core.ac.uk/download/pdf/34528641.pdf
“I’m trying to predict whether a study can be successfully replicated (DV)”
Is DV a typo (i.e., was CV, for cross-validation, intended?), or does it mean “Deo Volente” (literally “God willing”, or figuratively “If all goes well”)?
Martha:
I kinda like the idea of researchers inserting the word “Inshallah” at appropriate points throughout their text. “Our results will replicate, inshallah. . . . Our code has no more bugs, inshallah,” etc.
Last year, I transcribed my grandfather’s journal from 1938 to send to relatives on his oldest grandchild’s 80th birthday. It had a lot of DV’s, so I assumed that that was indeed what Wu intended, but still looked for something else that it might have been in context.
I agree that either DV or Inshallah or something secular like “If all goes well” are often very appropriate in discussing research (especially research plans).
this could be one of the funniest comments I’ve read on this blog
I assume DV = dependent variable.
TL;DR: Maybe you can train doc2vec on an independent dataset (for which you don’t necessarily need to know anything about replication, just the text) and do your shuffles with those trained vectors. That would allow you to capture both the variation due to sampling and the variation due to the non-determinism of doc2vec, while cutting the number of times you need to train doc2vec by 100.
Cool idea for a study! Though I agree with Andrew’s comment about not wanting to think of study outcomes in a binary sense… Just to make sure I’ve got this straight, these are your two proposed methods? Please excuse the craptastic pseudocode:
(1)
for i in 1:100
split data randomly into groups A, B, C
for Te in [A, B, C]
Tr = the remaining data not in Te
train doc2vec on Tr
infer doc2vec vectors for Tr and Te separately
train LR on Tr vectors
Y[i,Te] = apply LR on Te vectors
compute single AUC score, from average Y (over shuffles)
(2)
for i in 1:100
split data randomly into groups A, B, C
for Te in [A, B, C]
for j in 1:100
Tr = the remaining data not in Te
train doc2vec on Tr
infer doc2vec vectors for Tr and Te separately
train LR on Tr vectors
Y[j,Te] = apply LR on Te vectors
aucs[i] = compute AUC from average Y (over shuffles)
So for method 2 you get a distribution of AUC scores. I assume the bottleneck here is training doc2vec (as opposed to the logistic regression)? Looks like with method 1 you only have to train a doc2vec model 300 times, but with method 2 you’ll have to train a doc2vec model 30,000 different times! I don’t do NLP so correct me if I’m wrong but seems like that’ll take… a while.
But, you’ve got a good point about wanting to separate the variation due to sampling (the random sampling that occurs during your cross-validation splits) from the variation due to the non-determinism of training a doc2vec model. Or at least I like the idea of getting a distribution of AUC scores instead of a single value.
Maybe as a compromise between methods 1 and 2, you could train doc2vec models on an independent dataset and then use those (already-trained) for inference during your shuffles. For example, you could train 100 doc2vec models on some independent dataset X (of papers in the same field as the ones in your current dataset or something, but for which you don’t need info about replications, just the text). Then, for each of those models, you could run 100 shuffles of the cross-validated logistic regressions. So, in the form of more crappy pseudocode,
for i in 1:100
re-train doc2vec on independent dataset X
for j in 1:100
split data randomly into groups A, B, C
for Te in [A, B, C]
Tr = the remaining data not in Te
infer doc2vec vectors for Tr and Te separately
train LR on Tr vectors
Y[Te] = apply LR on Te vectors
aucs[i,j] = compute AUC from Y
That way you only need to train a doc2vec model 100 times. But you can still see how the variance of the AUC is affected by sampling (by averaging aucs over the i dimension) separately from how the variance is affected by the non-determinism of doc2vec (by averaging aucs over the j dimension). Though it seems to me it would be most useful to just measure the total uncertainty (by looking at the variance of all the values in aucs, without averaging).
An interesting idea, but… the whole set-up seems weird from a point of view of a Natural Language Processing person. And I don’t mean (1) vs (2), but why do you (Y.W.) train document vectors on your small data set? You know, text is cheap (for unsupervised learning), just train your model on whatever masses of text you can get that is kinda similar to your training sample (the more, the better). Or you could just use pre-trained ELMo or BERT language models.
Or actually, I’d start with something simpler — count chi-squared stats for unigrams, bigrams and trigrams without any document vectors. Cause you’re more interested in insight than just having a marginally better classifier, right?
Anyway, don’t forget to run your paper through this, cause if it says “unreproducible” you’ve got a Gödelian nightmare!
Presumably training on the actual test data words (feature inputs, not classification outputs) is useful for all the usual reasons that language is very long tailed and each domain has different frequency properties. There is information in the test inputs (word sequences) that can be extracted as part of the joint “to-vec” process that would be lost if you did the to-vec stuff first on some external database.
Andrew wrote:
“Start with a known universe, simulate fake data from that universe, then apply procedures (1) and (2) and see if they give much different answers.”
Or maybe just run Daryl Bem papers through it?
How is “ground truth” ascertained in terms of replication?
If the concern is the finite-sample uncertainty of cross-validation, the Bayesian bootstrap will approximate the distribution of the cross-validated quantity (AUC score here) without the extra computation cost (re-training the model 100 times) in approach 2. We discuss this in section 3.4 in stacking paper (https://projecteuclid.org/download/pdfview_1/euclid.ba/1516093227).
Andrew—do you ever ping the relevant postdocs, etc. here, so they know when their topic comes up in the queue umpteen months after being submitted?
I’d try to work directly with quantities of interest, such as probabilistic predictions. For instance, looking at calibration of probabilistic predictions—if the algorithm says result A is 70% likely in 100 cases, how many of those cases were really category A? The standard hypothesis test would involve binomial(100, 0.7) being the expected distribution of errors for a well-calibrated model.
We also recommend a lot of posterior predictive checks, so I’m surprised Andrew didn’t do that. It’s a bit tricky with logistic regression because there’s no generative model of the features, so you can only replicate the predictions. But that can help you see at least if the marginals are right (number of instances of each category).
If you’re going to keep AUC, at least come to grips that the average AUC comes with some uncertainty and try to report that. When the weatherperson reports a 70% chance of rain, I want to know if their prediction is reliable (whether there really is a 70% chance of rain), not what it’s AUC is. And given two calibrated weather forecasters, I want the ones making sharper predictions (closer to 1 or 0 for categorical results, or smaller posterior intervals for continuous predictions).
You are using full Bayesian predictive posterior inference for those regressions, right?
Bob:
I sometimes but do not always ping people on these. In this case, motivated by your above question, I sent the person an email.
Interesting Design. I do prefer the second choice as I don’t know if the randomness of word-to-vec follows any specific pattern but maybe 100 times for word-to-vec randomness is a little bit overdo? I think after reading all of this my biggest question is how are you going to do with AUC distributions if you choose the second choice