Apparently there’s an idea out there that Bayesian inference with Gaussian processes automatically avoids overfitting. But no, you can still overfit.
To be precise, Bayesian inference by design avoids overfitting—if the evaluation is performed by averaging over the prior distribution. But to the extent this is not the case—to the extent that the frequency-evaluation distribution and the prior distribution are different things—we do need to worry about overfitting (or, I guess, underfitting).
But what do I know about Gaussian processes? Let’s hand the mike over to the experts.
I searched in the book and found exactly four mentions of “overfitting”:

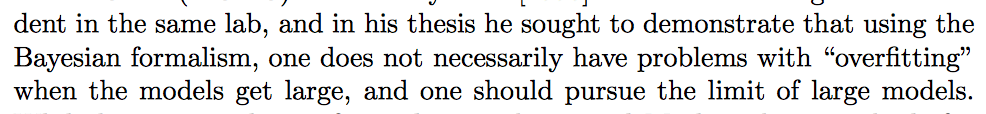


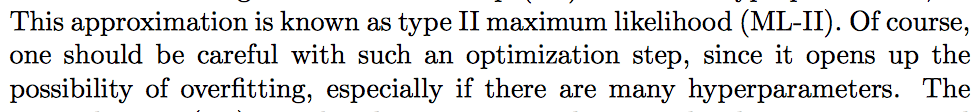
The Bayesian safeguards against overfitting seem to come in two flavors: there is the averaging of the predictive distribution over the posterior which works as long as the prior puts ample probability mass on all alternative explanations, and there is (weaker) the regularization effect from using complexity-penalizing priors. The latter is likely the only applicable safeguard for MAP estimates.
For Gaussian processes, the prior information is mostly encoded in the covariance function. Problematically, Gaussian process covariance function hyperparameters are often tuned with an empirical Bayes procedure (ML-II, mentioned in the text snippets), but commonly without any complexity-penalizing priors. A lot of modern developments come in the form of powerful and expressive covariance kernels, often loaded with dozens of tuneable hyperparameters, doubling the problem as the covariance is even more sensitive to the tuning process.
Rasmus:
Yes, we’ve found that when fitting Gaussian processes, it’s helpful to use strong prior distributions on the hyperparameters.