
Mike Betancourt pointed me to this news article by Alan Travis that is refreshingly positive regarding the use of sophisticated statistical methods in analyzing opinion polls.
Here’s Travis:
Leading pollsters have described YouGov’s “shock poll” predicting a hung parliament on 8 June as “brave” and the decision by the Times to splash it on its front page as “even braver”.
It is certainly rare for a polling company to produce a seats prediction. They usually leave that to psephologists and political scientists.
Good catch: YouGov’s chief scientist is Doug Rivers, who’s a political scientist. And the new method they’re using is multilevel regression and poststratification (MRP or Mister P), which was developed by . . . me! And I’m a political scientist too.
Travis continues:
But it is even more unusual for a company to suddenly employ a new polling model 10 days before a British general election.
Good point! That really would be an unusual practice. Fortunately, So, sure, MRP is not so new—our first paper on the method (“Poststratification into many categories using hierarchical logistic regression,” with Tom Little) was published 20 years ago.
Travis then supplies some details of YouGov’s forecast:
The Tories are in line to lose 20 seats, giving them 310, and Labour is set to gain 30, giving it 257 . . . But as Stephan Shakespeare, YouGov’s chief executive, notes in an accompanying analysis, that is only a central projection that “allows for a wide range of error” and he concedes: “However, these are just the midpoints and, as with any model, there is leeway either side. The Tories could end up with as many as 345 and Labour as few as 223, leading to an increased Conservative majority.” . . . The Times says the projection means the Tories “could get as many as 345 seats on a good night . . . and as few as 274 on a bad night”. That is a pretty wide range.
It’s good to see Travis explaining that realistic forecasts have wide ranges of uncertainty.
He continues with some details:
The methodology involved is described as “multi-level regression and post-stratification” analysis and is based on a substitute for traditional constituency polling, which it regards as “prohibitively expensive”. Shakespeare claimed YouGov tested it during last year’s EU referendum campaign and it produced leave leads every time. What a shame YouGov did not feel like sharing it with voters while their own published referendum polls showed a remain lead right up to polling day.
Travis missed a beat on this one! YouGov did share their MRP estimates during the EU referendum campaign. Ummm . . . let me google that . . . here it is: “YouGov uses Mister P for Brexit poll”: it’s an article by Ben Lauderdale and Doug Rivers which includes this graph showing Leave in the lead:
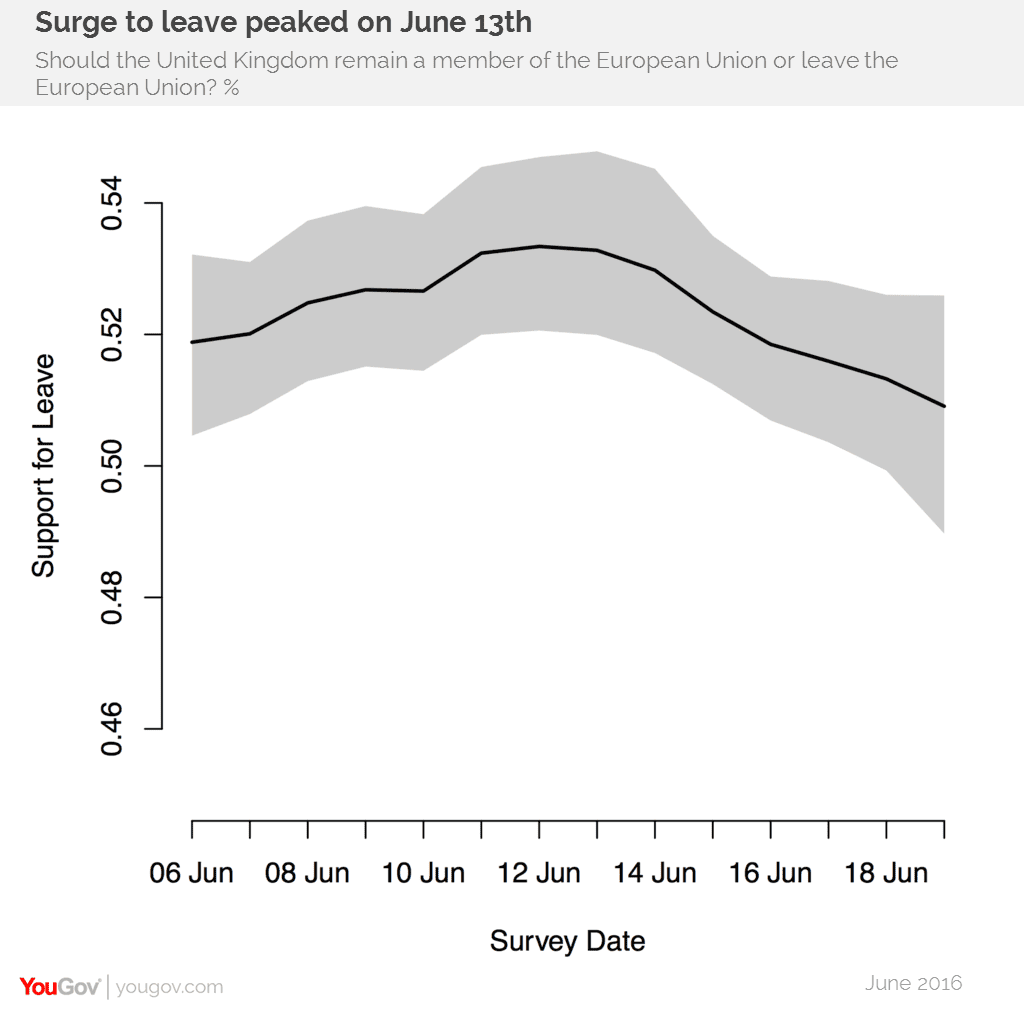
OK, it’s good we got that settled.
Travis concludes:
In an industry already suffering from an existential crisis of public confidence it is indeed a “brave” decision to come up with this one 10 days before a general election and promise to publish its results several times more before polling day.
“Brave” is perhaps overstating things, but, yes, I agree with Travis that presenting MRP estimates is the honorable way to go. Using the best available methods based on the best available knowledge, and giving appropriately wide uncertainty intervals: that’s how to do it.
It’s indeed a shame that Travis was not aware that YouGov had released a report with MRP in the lead-up to the Brexit vote. Also Travis, coming from the U.K., might not have realized that MRP was used in U.S. polls too. For example there was this Florida poll from September, 2016, which was analyzed by four different groups:
Charles Franklin, who estimated Clinton +3
Patrick Ruffini, who estimated Clinton +1
New York Times, who estimated Clinton +1
Sam Corbett-Davies, David Rothschild, and me, who estimated Trump +1. We used MRP.
That said, I don’t have any crystal ball. Shortly before the election I was promoting a forecast that gave Clinton a 92% chance of winning the election. That forecast didn’t use MRP; it aggregated information from state polls without appropriately accounting for expected levels of systematic error. I should’ve used MRP myself—I would’ve, but I wasn’t working with the raw data. In this upcoming U.K. election, YouGov does have the raw polling data so of course they are using MRP; it would at this point be a strange choice not to.
Anyway, it’s cool that Alan Travis conveyed some subtleties of polling to the British newspaper audience, even if he did miss one or two things.
Full disclosure: YouGov gives some financial support to the Stan project.
P.S. Thanks to Steven Johnson for the photo at the top of this post.
P.P.S. More on yougov’s use of MRP here.
While you’re patting yourself on the back for the accuracy of newly-developed polling methods (the evidence which appears to be anecdotal), perhaps you would care to comment on the large swings in polling support for Clinton in the last week and a half of the campaign. Is it due to voter non-response? Or is it actually legitimate changes in support? Of course, if it is legitimate changes in support, that would indicate that the Florida results you are promoting as proof of accuracy almost certainly was the least accurate of all the estimates, as Clinton was up by a sizable amount in September and one would expect, since she lost the state by 1% after a nearly 10-point drop in national support in the last few days, that she was actually winning the state in September.
Numeric:
1. I would not describe MRP as newly-developed, given that our paper on the topic came out 20 years ago.
2. As I’ve discussed a few times on blog, I think that the large swings in the last week and a half of the campaign were mostly changes in differential nonresponse.
3. I’m not presenting that Florida poll as proof of accuracy; I’m sharing it to indicate that MRP has been used in recent, high-profile elections. Regarding Florida itself, I’d guess that she was not actually winning the state in late September. In any case, we and the others had standard errors on our polling estimates, and so, sure, the fact that we happened to get Trump up by exactly 1 is a bit of (retrospective) luck on the part of our estimate. The poll only had 867 respondents.
In summary, I’m not saying that MRP will necessarily give the right answer: there are lots of concerns, including changes in public opinion, differential nonresponse within poststratification cells, and plain old sampling error. What I am saying is that MRP is a serious approach, it’s been tried before (including by Yougov), hence (a) I think it’s just fine for Travis to laud Yougov’s decision to use MRP in their forecasts, and (b) I wanted to clarify that MRP has done just fine in past elections. I also appreciated that Travis discussed the wide uncertainty in forecasts of the distribution of seats: journalistic accounts are often flawed by presenting forecasts as essentially deterministic.
+1.
I’d guess that Andrew Gelman is right about Hillary not actually winning the state of Florida in late September. It might have had something to do with her basket of deplorables comment on September 11. That nonplussed large portions of the electorate nationwide, including Florida. There’s also the powerful and impossible to capture effect of the Shy Trump Voter….
I think it is great that The Guardian praises yougov’s use of Andrew’s MRP polling methodology!
P.S. The reason that I am replying to Andrew rather than numeric is because I like this so much:
A really minor marginalia: YouGov appears as an entity in the post-cyber-punk novel Infomocracy, by Malka Older (currently completing a PhD thesis at Science Po’ Paris, where Andrew taught a few years ago).
It is absolutely fantastic to see Doug Rivers in his capacity at YouGov to be using MrP and there being a wider mass audience to consume the subtleties of public opinion polling. We are out I have five days until the election when the model will be put to the test. This may be nothing but academic navel gazing; curiosity has gotten the best of me.
I am the first to say that no model is perfect and no model should be expected to be perfect. I am also the first to say that hindsight is 20/20: in hindsight things are obvious that were not obvious from the outset. We know there are improvements to accuracy when MrP is employed but a lot is riding on the context-level information. There is an inherent problem is how to include the context-level information in an optimal fashion. A paper presented at the Political Studies Association Annual Conference in April held at Glasgow by Philipp Broniecki (University College London), Lucas Leemann (University College London), Reto Wüest (Geneva) made the point quite robustly (https://www.psa.ac.uk/conference/2017-conference/advances-political-methodology).
My substantive academic navel gazing is there is little indication from the YouGov description (https://yougov.co.uk/news/2017/05/31/how-yougov-model-2017-general-election-works/) of 1) the groups the constituencies are organised into and 2) what group-level predictors are employed in the model. Britain can be cut up in a lot of ways and there is an incredible variety of covariates available to someone performing MrP. This makes me wonder, what is in River’s secret sauce. What group-level covariates and hierarchical typologies for British electoral geography are the most optimal for predicting vote choice?
Incidentally the YouGov MrP estimates effectively mirror my implementation of Jackman (2005; https://www.tandfonline.com/doi/abs/10.1080/10361140500302472): https://twitter.com/mansillo/status/871321460941271040. I certainly hope their model is quality, otherwise I’m in the lurch.
If the exit polls are accurate, then Mr P. did a pretty good job, much better that the traditional model that YouGov used for their final call https://yougov.co.uk/news/2017/06/07/two-methods-one-commitment-yougovs-polling-and-mod/ .
Still early but early results looking good for Mr P:
https://twitter.com/ForecasterEnten/status/872966686017806337
Deinst, Jeremy:
I think Mister P is just great and I welcome all positive publicity, even if in this case it’s a bit of luck, given that Yougov did report pretty wide predictive intervals.
If the election goes as the polls forecasted, perhaps I can argue “from a position of strength” to emphasize the importance of margins of error and predictive uncertainty. If my model’s predictions performed well, then I’m the ideal person to make the case that forecasters don’t deserve too much credit for any particular lucky shot.
The YouGov central prediction continues to hold up (and yes, no doubt there’s some luck involved in doing *this* well):
https://twitter.com/jblumenau/status/873001552386166785