Retractions or corrections of published papers are rare. We routinely encounter articles with fatal flaws, but it is so rare that such articles are retracted that it’s news when it happens.
Retractions sometimes happen at the request of the author (as in the link above, or in my own two retracted/corrected articles) and other times are achieved only with great difficulty if at all, in the context of scandals involving alleged scientific misconduct (Hauser), plagiarism (Wegman), fabrication (Lacour, Stapel), and plain old sloppiness (Reinhart and Rogoff, maybe Tol falls into this category as well).
And one thing that’s frustrating is that, even when the evidence is overwhelming that a published claim is just plain wrong, authors will fight and fight and refuse to admit even an inadvertent mistake (see the story on pages 51-52 here).
These cases are easy calls from the ethical perspective, whatever political difficulties might arise in trying to actually elicit a reaction in the face of opposition.
Should this paper be retracted?
Now I want to talk about a different example. It’s a published paper not involving any scientific misconduct, not even any p-hacking that I notice, but the statistical analysis is flawed, to the extent that I do not think the data offer any strong support for the researchers’ hypothesis.
Should this paper be retracted/corrected? I see three arguments:
1. Yes. The paper was published as an empirical study that offers strong support for a certain hypothesis. The study offers no such strong support, hence the paper should be flagged so that future researchers do not take it as evidence for something it’s not.
2. No. Although the data are consistent with the researchers’ hypothesis being false, they are also consistent with the researchers’ hypothesis being true. We can’t demonstrate convincingly that the hypothesis is wrong, either, so the paper should stand.
3. No. In practice, retraction and even correction are very strong signals, and these researchers should not be punished for an innocent mistake. It’s hard enough to get actual villains to retract their papers, so why pick on these guys.
Argument 3 has some appeal but I’ll set it aside; for the purpose of this post I will suppose that retractions and corrections should be decided based on scientific merit rather than on a comparative principle.
I’ll also set aside the reasonable argument that, if a fatal statistical error is enough of a reason for retraction, then half the content of Psychological Science would be retracted each issue.
Instead I want to focus on the question: To defend against retraction, is it enough to point out that your data are consistent with your theory, even if the evidence is not nearly as strong as was claimed in the published paper?
A study of individual talent and team performance
OK, now for the story, which I learned about through this email from Jeremy Koster:
I [Koster] was reading this article in Scientific American, which led me to the original research article in Psychological Science (a paper that includes a couple of researchers from the management department at Columbia, incidentally).
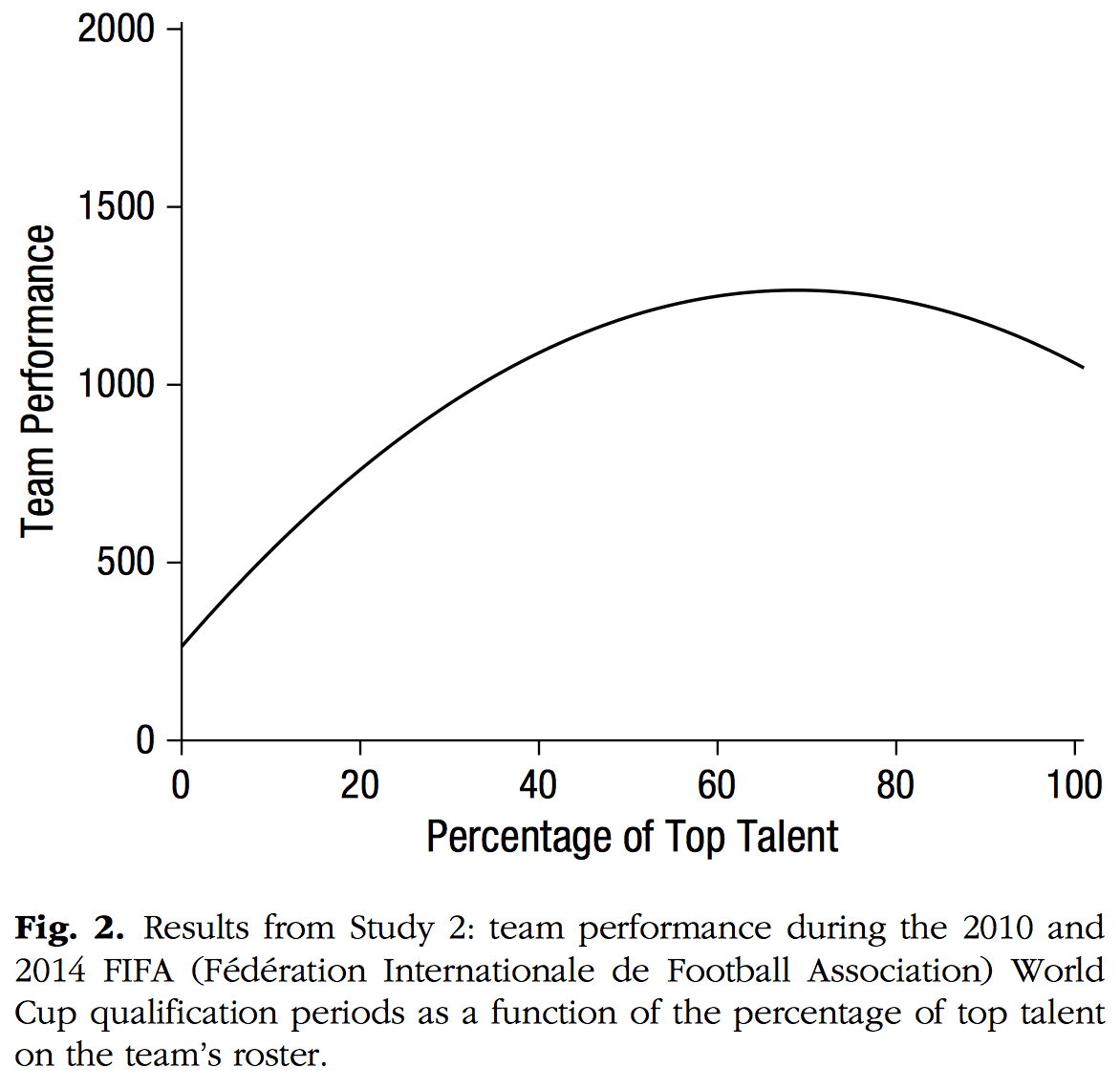
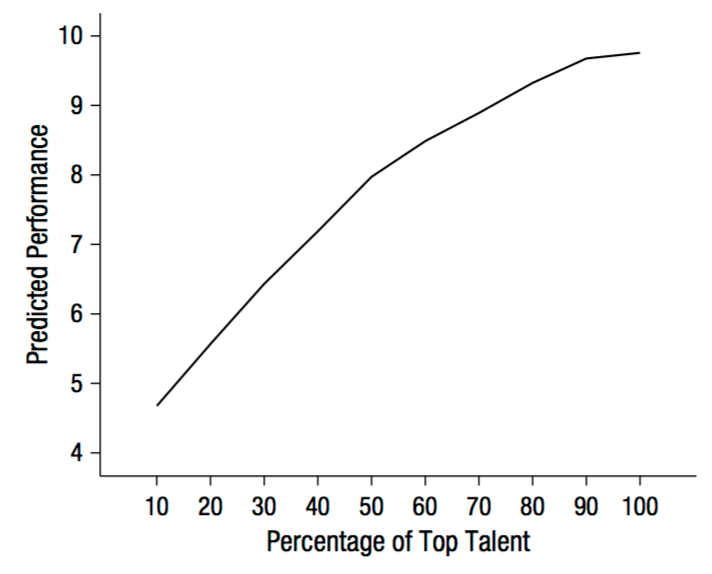
After looking at Figure 2 for a little while, I [Koster] thought, “Hmm, that’s weird, what soccer teams are comprised entirely of elite players?”
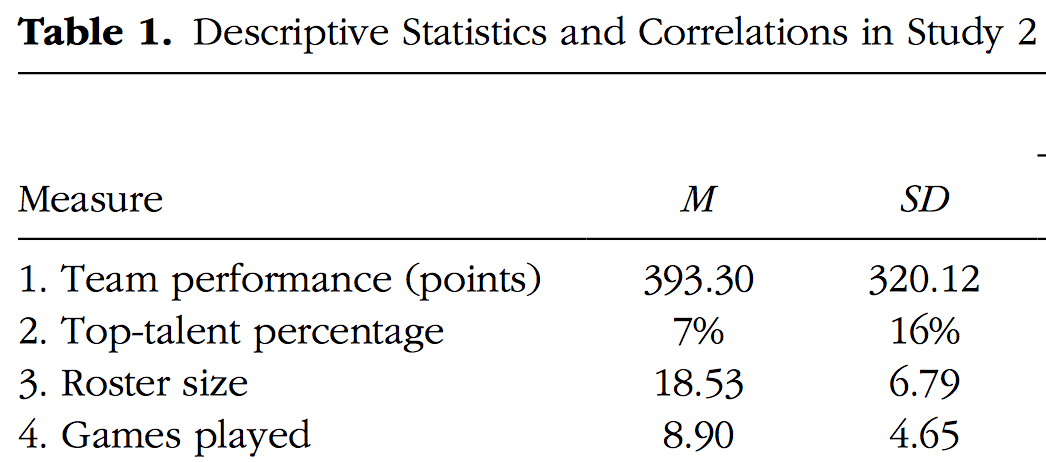
Which led me to their descriptive statistics. Their x-axis ranges to 100%, but the means and SD’s are only 7% and 16%, respectively:
They don’t plot the data or report the range, but given that distribution, I’d be surprised if they had many teams comprising 50% elite players.
And yet, their results hinge on the downward turn that their quadratic curve takes at these high values of the predictor. They write, “However, Study 2 also revealed a significant quadratic effect of top talent: Top talent benefited performance only up to a point, after which the marginal benefit of talent decreased and turned negative (Table 2, Model 2; Fig. 2).”
If you’re looking to write a post about the perils of out-of-sample predictions, this would seem to be a fun candidate . . .
For convenience, I’ve displayed the above curve in the range 0 to 50% so you can see that, based on the fitted model, there’s no evidence of any decline in performance:
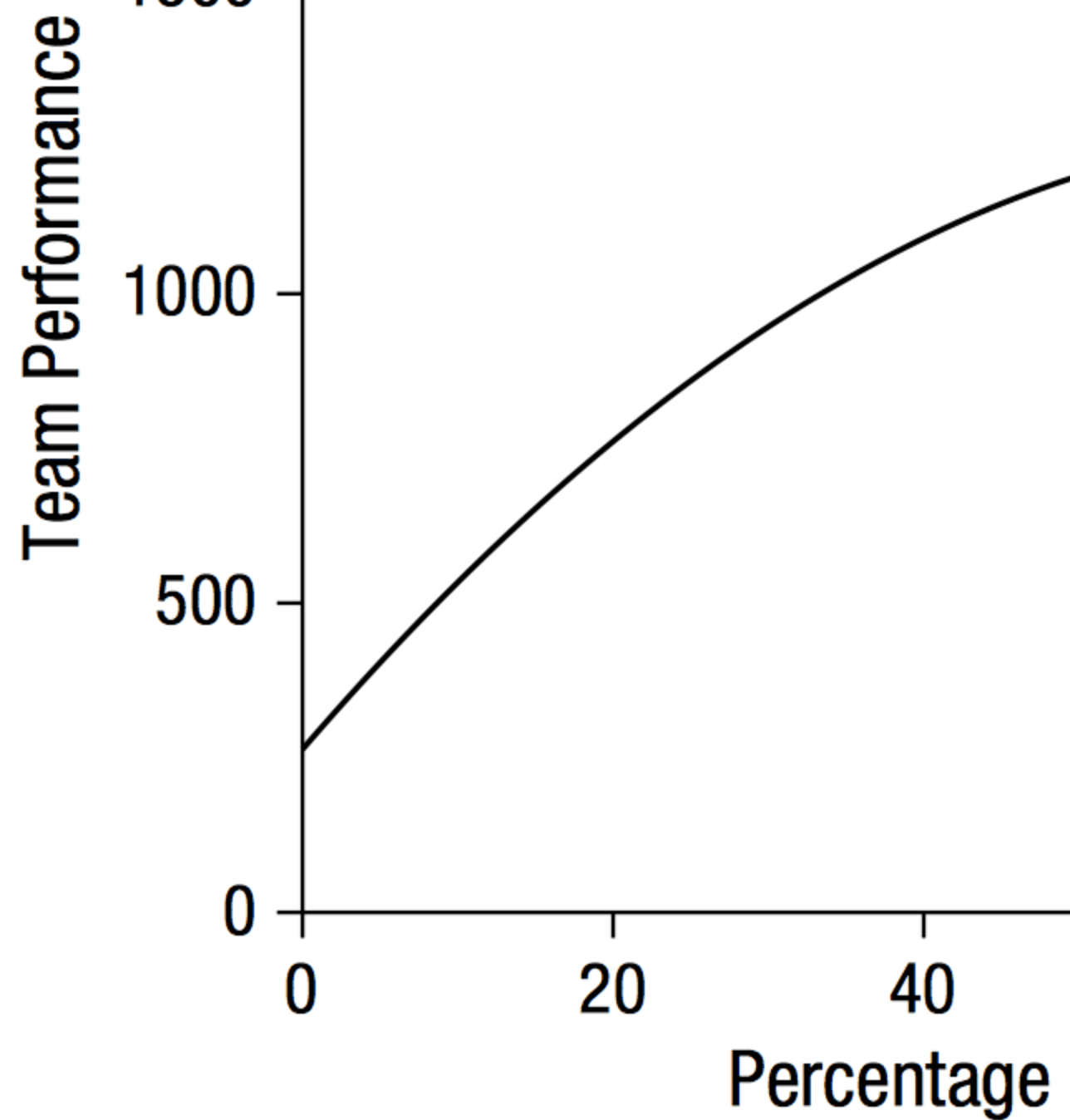
So, in case you were thinking of getting both Messi and Cristiano Ronaldo on your team: Don’t worry. It looks like your team’s performance will improve.
Following the links
The news article is by a psychology professor named Cindi May and is titled, “The Surprising Problem of Too Much Talent: A new finding from sports could have implications in business and elsewhere.” The research article is by Roderick Swaab, Michael Schaerer, Eric Anicich, Richard Ronay and Adam Galinsky and is titled, “The Too-Much-Talent Effect: Team Interdependence Determines When More Talent Is Too Much or Not Enough.”
May writes:
Swaab and colleagues compared the amount of individual talent on teams with the teams’ success, and they find striking examples of more talent hurting the team. The researchers looked at three sports: basketball, soccer, and baseball. In each sport, they calculated both the percentage of top talent on each team and the teams’ success over several years. . . .
For both basketball and soccer, they found that top talent did in fact predict team success, but only up to a point. Furthermore, there was not simply a point of diminishing returns with respect to top talent, there was in fact a cost. Basketball and soccer teams with the greatest proportion of elite athletes performed worse than those with more moderate proportions of top level players.
Now that the finding’s been established, it’s story time:
Why is too much talent a bad thing? Think teamwork. In many endeavors, success requires collaborative, cooperative work towards a goal that is beyond the capability of any one individual. . . . When a team roster is flooded with individual talent, pursuit of personal star status may prevent the attainment of team goals. The basketball player chasing a point record, for example, may cost the team by taking risky shots instead of passing to a teammate who is open and ready to score.
Two related findings by Swaab and colleagues indicate that there is in fact tradeoff between top talent and teamwork. First, Swaab and colleagues found that the percentage of top talent on a team affects intrateam coordination. . . . The second revealing finding is that extreme levels of top talent did not have the same negative effect in baseball, which experts have argued involves much less interdependent play. In the baseball study, increasing numbers of stars on a team never hindered overall performance. . . .
The lessons here extend beyond the ball field to any group or endeavor that must balance competitive and collaborative efforts, including corporate teams, financial research groups, and brainstorming exercises. Indeed, the impact of too much talent is even evident in other animals: When hen colonies have too many dominant, high-producing chickens, conflict and hen mortality rise while egg production drops.
This is all well and good (except the bit about the hen colonies; that seems pretty much irrelevant to me, but then again I’m not an egg farmer so what do I know?), but it all hinges on the general validity of the claims made in the research paper. Without the data, it’s just storytelling. And I can tell as good a story as anyone. OK, not really. Steven King’s got me beat. Hell, Jonathan Franzen’s got me beat. Salman Rushdie on a good day’s got me beat. John Updike or Donald Westlake could probably still out-story me, even though they’re both dead. But I can tell stories just as well as the ovulation-and-voting people, or the fat-arms-and-politial attitudes people, or whatsisname who looked at beauty and sex ratio, etc. Stories are cheap. Convincing statistical evidence, that’s what’s hard to find.
So . . . I was going to look into this. After all, I’m a busy guy, I have lots to do and thus a desperate need to procrastinate. So if some perfect stranger emails me asking me to look into a paper I’ve never heard of on a topic that only mildly interests me (yes, I’m a sports fan but, still, this isn’t the most exciting hypothesis in the world), then, sure, I’m up for it. After all, if the options are blogging or real work, I’ll choose blogging any day of the week.
I contacted one of the authors who’s at Columbia and he reminded me that this paper had been discussed online by Leif Nelson and Uri Simonsohn. And then I remembered that I’d read that post by Nelson and Simonsohn and commented on it myself a year ago.
Swaab et al. responded to Nelson and Simonsohn with a short note, and here are their key graphs:
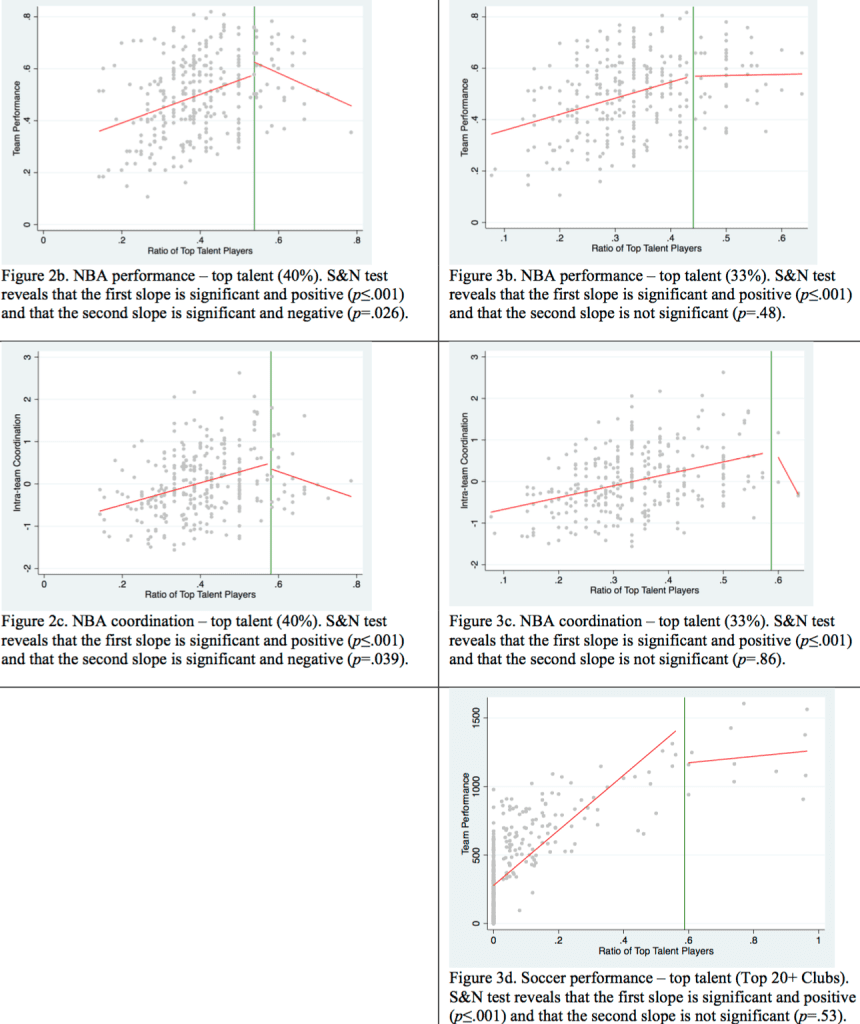
I think we can all agree on three things:
1. There’s not a lot of data in the “top talent” range as measured by the authors. Thus, to the extent there is a “top talent effect,” it is affecting very few teams.
2. The data are consistent with there being declining performance for the most talented teams.
3. The data are also consistent with there being no decline in performance for the most talented teams. Or, to put it another way, if these were the quantitative results that had been published (when using the measure that they used in the main text of their paper, they found no statistically significant decline at all; they were only able to find such a decline by changing to a different measure that had only been in the supplementary version of their original paper), I can’t imagine the paper would’ve been published.
The authors also present results for baseball, which they argue should not show a “too-much-talent effect”:
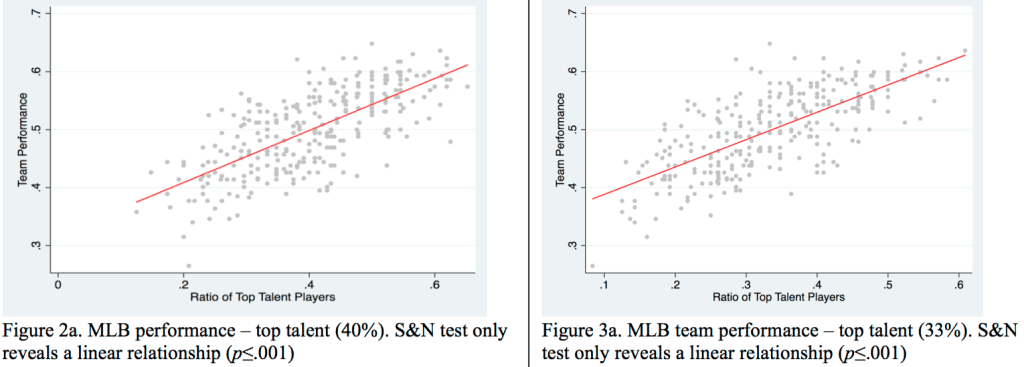
This looks pretty convincing, but I think the argument falls apart when you look at it too closely. Sure, these linear patterns look pretty good. But, again, these graphs are also consistent with a flat pattern at the high end—just draw a threshold far enough near the right edge of either graph and you’ll find no statistically significant pattern beyond the threshold.
In discussing these results, Swaab et al. write, “The finding that the effect of top talent becomes flat (null) at some point is an important finding: Even under the assumption of diminishing marginal returns, the cost-benefit ratio of adding more talent can decline as hiring top talent is often more expensive than hiring average talent.”
Sure, that’s fine, but recall that a key part of their paper was that their empirical findings contradicted naive intuition. In fact, the guesses they reported from naive subjects did show declining marginal return on talent. Look at this, from their Study 1 on “Lay Beliefs About the Relationship Between Top Talent and Performance”:
These lay beliefs seem completely consistent with the empirical data, especially considering that Swaab et al. defined “top talent” in a way so that there are very few if any teams in the 90%-100% range of talent.
What to do?
OK, so should the paper be retracted? What do you think?
The authors summarize the reanalysis with the remark:
The results of the new test . . . suggest that the strongest version of our arguments—that more talent can even lead to worse performance—may not be as robust as we initially thought. . . .
Sure, that’s one way of putting it. But “not as robust as we initially thought” could also be rephrased as “The statistical evidence is not as strong as we claimed” or “The data are consistent with no decline in performance” or, even more bluntly, “The effect we claimed to find may not actually exist.”
Or, perhaps this:
We surveyed ordinary people who thought that there would be diminishing returns of top talent on team performance. We, however, boldly proclaimed that, at some point, increasing the level of top talent would decrease team performance. Then we and others looked carefully at the data, and we found that the data are more consistent with with ordinary people’s common-sense intuition than with our bold, counterintuitive hypothesis. We made a risky hypothesis and it turned out not to be supported by the data.
That’s how things go when you make a risky hypothesis—you often get it wrong. That’s why they call it a risk!
of course this paper needs to be retracted.
we need to stop coddling bad research practices.
One solution to this whole mess: just reclassify the entire body of research in the social sciences (and probably other disciplines, too) as exploratory studies. Exploratory studies are perfectly legit. Once everyone makes that mental shift, work on confirmatory studies can begin. For the next 20 years or so, folks can sift the existing exploratory literature for promising hypotheses to subject to confirmatory studies (e.g., pre-registered, adequately powered, nearly exact replications).
I don’t see why the next 20 years of researchers should be slop-pen cleaners.
I agree that much of the research in the social sciences is exploratory–and it would be beneficial to label and treat it as such–but to call the *entire* body of social sciences research exploratory seems a bit heavy handed. After all, even though good research is hard to do, I have to believe that *some* existing social research is high quality and confirmatory. Downgrading all past social research to exploratory status, irrespective of the characteristics of individual studies, seems to be an association fallacy.
Perhaps the problem has less to do with whether any given study is exploratory and more with a pervasive and misguided attitude about the development of scientific knowledge. The pervading sentiment seems to be “I/the authors followed the procedure and came to a conclusion, therefore, we must know the truth.” But, even for adequately powered and confirmatory research, the conclusions from a single study are not “the truth, full stop.” Rather, they’re (perhaps highly suggestive) evidence about one facet of an incredibly complex social reality, subject to countless and less-than-fully known limitations and constraints. The focus of our general attention should probably shift from individual studies to research reviews and meta-analysis (although, I doubt that news media will likely have the patience to wait for this gradual accretion of knowledge). Is research on the association between gender and the attractiveness of parents, fertility-related clothing choices, power poses and the like important enough (particularly in the face of current social challenges) to merit the effort of conducting and then reviewing dozens of studies? Maybe, maybe not. Perhaps researchers would make different choices about which studies to pursue if they first asked themselves “would this be worth including in a research review?”
Research doesn’t happen in a vacuum, and researchers are people, not robots. People are enmeshed with other people and naturally seek out approval from their peers according to a system of norms and rewards. In academia, (the appearance, at least, of) competence, ingenuity, and discovery are rewarded. Academic environments can many times be more caustic than affirming, and researchers with fragile egos (myself included, I’m sure) could be sucked into believing that their worth as a human being is contingent on their academic performance. As much as I might prefer to see a softer, more collaborative approach, I can empathize with researchers who take a hard defense when potential defects (much more, fatal flaws) are pointed out in their work: After all, someone (most likely someone they don’t know or trust to affirm their personal worth irrespective of their work performance) has just said (publicly, no less) that *they* (not just their work) don’t measure up. That the intent of the post-publication reviewer may be only on the work and not on the personal worth of the researcher is irrelevant if the researcher has identified the two and has no personal relationship with the reviewer–even if the the criticism is offered in a constructive spirit focused on the “greater good” of scientific knowledge development, it’s more likely to be received as a (personal) attack in a system of rewards that’s focused on the personal success and prowess of individual researchers.
At the moment, academia is largely a finite game in which there are winners (researcher-heroes who achieve widespread fame and admiration) and losers (ninnies relegated to obscurity and grunt work–I do exaggerate for rhetorical effect). Winners get to “play” again by receiving desirable posts at prestigious universities and lots of grant funding to further their research, while losers are shut out of the game, encumbered by non-research responsibilities and without resources to move their research forward. The rules of the game (peer review, publish-or-perish promotion and tenure systems, norms about shared authorship, etc.) tend to focus attention on the players (the researchers), not the goal (scientific knowledge). In some sort of “infinite game” version of academia, rewards would be structured so that researchers would care more about collaborating for the development of knowledge than worrying about their personal success.
I guess the point that I’m rambling to is that the problems of the reproducibility crisis and p-hacking and headline chasing and retraction fighting and all have roots much deeper than ignorance of forking paths or broken editorial policies or hard-nosed researchers: These are all outgrowths of a system that is fundamentally wired for winners and losers, a system focused on players instead of the goal, a system that has lost sight of its supposed purpose, namely the growth of our collective knowledge about the world. I’m skeptical that any amount of educating about proper statistical technique, of labeling studies as exploratory or confirmatory, of peer/post review vigilance or retraction policies will be sufficient to correct a system that has so fundamentally lost its focus. Unfortunately, I also don’t have any particularly good ideas for how to construct an infinite academic game in world with real resource limitations, but perhaps with enough bright minds focused on the problem, we can move in that direction.
(I credit Niki Harré’s keynote at the 2013 SCRA biennial conference, drawing on James Carse, for the concept of finite and infinite games.)
“Downgrading all past social research to exploratory status, irrespective of the characteristics of individual studies, seems to be an association fallacy.”
Downgrading? Smarter people than me think pretty highly of exploratory research:
https://www.amazon.com/Exploratory-Data-Analysis-John-Tukey/dp/0201076160
Andrew blogged on this a few months ago:
https://statmodeling.stat.columbia.edu/2016/02/11/in-general-hypothesis-testing-is-overrated-and-hypothesis-generation-is-underrated-so-its-fine-for-these-data-to-be-collected-with-exploration-in-mind/
You can’t learn *unexpected* things about the world from confirmatory studies. And when it comes to a complex system like human psychology and behavior, there are going to be many unexpected things. Do you need to control for age or sex? Uh, I don’t know, maybe. You won’t be able to design a confirmatory study if you don’t know if you should control for age or sex, but you won’t know that if you haven’t run a high quality exploratory study. And contrary to this paper that Andrew linked to:
https://johnsakaluk.com/wp-content/uploads/2014/06/Sakaluk_2015_JESP.pdf
exploratory studies probably need to be big, not small, so that you have reasonably precise estimates to work from. Andrew scoffed that the ovulation and clothing folks controlled for the weather. But if you’re studying clothing choice in British Columbia, the weather is probably a huge factor. To know how the weather might influence your results, though, you need an exploratory study because your theory is probably not good enough to have a priori predictions about the effects of the weather.
Exploratory studies are essential to science, yet you’re right that most people view them, at best, as the poor stepchild of confirmatory studies, and social scientists don’t get any credit for doing them. That’s why we try to disguise our exploratory studies as confirmatory studies. I could see a norm developing, however, that *requires* one or more large exploratory studies prior to any confirmatory study. In other words, exploratory studies need to become a big part of what we social scientists do, and we need to get academic credit for them.
Ed:
I scoffed at their weather analysis because (a) they didn’t mention the weather at all in their first paper, and (b) they only considered the weather in their second paper as a way to avoid the natural conclusion that their data were consistent with null effect.
Sure, weather is relevant to clothing choice. Here are a bunch of other things relevant to clothing choice:
– age
– marital status
– relationship status
– height
– weight
– number of older siblings
– sex of older siblings
– employment status
– parents’ employment
– parents’ age
– . . .
I think you get the idea. I love exploratory studies, but gathering crappy one-shot data on a hundred people and looking for the first thing that can explain your results . . . that’s low-quality exploratory research.
One problem, I think, is that people don’t always realize that exploratory research can be of different levels of quality. We all know that a confirmatory study can be bulletproof, or completely sloppy, or somewhere in between, but we’re not used to evaluating exploratory work in this way. To describe a study as “exploratory” does not get it off the hook for problems of measurement, conceptualization, etc.
(I’m not saying you’re making the error of treating all exploratory studies as being equal; I’m just pointing out more generally that, to the extent that we want exploratory studies, we want good exploratory studies.)
“(I’m not saying you’re making the error of treating all exploratory studies as being equal; I’m just pointing out more generally that, to the extent that we want exploratory studies, we want good exploratory studies.)”
This is exactly my point. Exploratory studies need to become a “thing”. Right now, they play almost no formal role in social science, yet they are essential to good social science. That means we need to put as much effort in developing standards, procedures, and techniques for exploratory studies as we have for confirmatory studies. And we need academic norms that reward good exploratory studies so there is less incentive to disguise them as confirmatory.
My two cents.
Ed:
Thanks. I have a post elaborating on these points (scheduled for mid-Nov).
Couldn’t agree more, especially when published online it can easily be read/taken out of context.
Although exploratory studies are HUGELY important they need their publishers to be very honest about how they tag/grade them.
Yes, you’re right. “Downgrading” was a poor choice of words on my part, though as you point out, there are a number of entrenched social science traditions that denigrate exploratory research in favor of confirmatory. So, there’s another message (exploratory research is valuable, even vital, to the progress of social science) to add to the party platform (or maybe it’s already a part and I’m just catching up). It makes me wonder whether social science research reform efforts would achieve more success by focusing on one or two key messages first, and then moving on to other messages after the norms have started to shift. Exploratory research, researcher degrees of freedom, careful measurement, peer review, theory testing (and p < .05 doesn't count), Type S and M errors–where's the best place to start? There seems to be a lot of talk lately about p-values. I wonder whether riding the growing energy there would be most beneficial or if there is some other, more fundamental message that could do more good for research reform if pressed.
Entire body of research in other disciplines? Why should we label Quantum Mechanics or the Hubble Shift as “exploratory” just because a few notorious sub-disciplines have sloppy research standards?
“Entire body of research in other disciplines?”
Cancer biology?
https://www.slate.com/articles/health_and_science/future_tense/2016/04/biomedicine_facing_a_worse_replication_crisis_than_the_one_plaguing_psychology.html
Thanks for the link. A worthwhile read.
For a situation like this, I wonder if there should be an option to “replace” or “mega-correct”. Maybe they add Nelson and Simonsohn as co-authors and just replace the paper in place. The original authors had the idea and collected the data, so they should get some credit, but the work it would take to make the paper accurate is more than a correction. So they could just rework the paper in place and give credit to the people who contributed to the changes that had to be made. Some kind of note should be attached though, so that readers/hiring committees can keep track of what happened.
Or just work this short note https://datacolada.org/wp-content/uploads/2014/09/AuthorsResponse3.pdf into a methods paper of how not to do less than ideal analysis that we (unfortunately) did here. Ideally the old paper would have a link to the new methods paper.
why not just retract the paper?
Must:
I don’t think the authors would be inclined to retract the paper, as then they’d presumably have to stop claiming that their results are correct.
The problem is that “retraction” is so pejorative. The label matters. Maybe talking about “corrections” (as you do) would help with swallowing the pill. When they hear “retraction” people think unethical behavior (as in Lacour etc.). “Correction” is not so big a deal. Anyone can make a mistake, admit it and move on. In this specific case, a correction would be in order. There’s nothing unethical here, but the data are not well analyzed. A better, and more plausible, analysis changes the conclusion. That’s important.
I generally concur. I would love for a future publishing platform to allow for versioning and to allow for citations to versions. As well as notifications when past papers that you have cited have been updated. As much as I love this idea, I have yet to figure out how to make it work without an explosion of complexity.
Perhaps we need “unbiased retraction” and “biased retraction” much like how there is “with prejudice” and “without prejudice” in a court case (https://www.illinoislegalaid.org/index.cfm?fuseaction=home.dsp_content&contentID=6092).
Tweaks to the existing system are doomed to failure. It’s an attractive equilibrium that benefits the people who set it up. You’ll need to perturb the system sufficiently to get it out of the basin of attraction. The current system looks a lot like the medieval Christian church, with tax money at the NSF and NIH tithes to support professors bishops arguing about power poses, ego depletion, and the effectiveness of Tamiflu angels on heads of pins…
Tweaks to the existing system are doomed to failure. It’s an attractive equilibrium that benefits the people who set it up. You’ll need to perturb the system sufficiently to get it out of the basin of attraction. The current system looks a lot like the medieval Christian church, with t̶a̶x̶ ̶m̶o̶n̶e̶y̶ ̶a̶t̶ ̶t̶h̶e̶ ̶N̶S̶F̶ ̶a̶n̶d̶ ̶N̶I̶H̶ tithes to support p̶r̶o̶f̶e̶s̶s̶o̶r̶s̶ bishops arguing about p̶o̶w̶e̶r̶ ̶p̶o̶s̶e̶s̶,̶ ̶e̶g̶o̶ ̶d̶e̶p̶l̶e̶t̶i̶o̶n̶,̶ ̶a̶n̶d̶ ̶t̶h̶e̶ ̶e̶f̶f̶e̶c̶t̶i̶v̶e̶n̶e̶s̶s̶ ̶o̶f̶ ̶T̶a̶m̶i̶f̶l̶u̶ angels on heads of pins…
Hopefully that works with the strikethrough, damn you wordpress and your lack of preview.
start rant
I get that the authors won’t be inclined to retract the paper because then they have to stop claiming that their story is true (hello power pose!). That’s the central problem we face over and over again. There is too much emphasis on story telling (garden of forking paths, etc) and being clever and far too little on getting to base truths.
Without a retraction, this paper stays in the literature. Someone will come across it in a few years and find that this story adds to their story and construct a larger narrative. Rinse. Repeat.
The implications of this paper could have been tested as well. If the idea is that talent saturates and then actually does harm to a team, then test the dang hypothesis! Given that the authors believe that this is a general cross domain finding, they could have done experiments to test it. A few super off the top of my head experiments:
1) find some sort of team game, bring a bunch of undergrads in, figure out who are best, divide them into teams based upon performance, figure out how the teams do over multiple plays of the game.
2) use online team video games. advertise a new tournament for call of duty teams or something (i have no idea about online team games) with the caveat that you will be assigned teams randomly (but do so based upon past player performance), then run many tournaments.
3) others?
This is the thing that just gets be every dang time, researchers never go and TEST their hypotheses! Okay, you found what might be an interesting pattern, that’s the easy part, now the hard part, the part that makes this all better (best?) science, is to go figure out an experiment to test your hypothesis. The vast majority of these sorts of articles that I read, I always have the same rebuttable, why didn’t you test your hypothesis?
end rant
I think this is what people think they’re doing when they do Null Hypothesis Tests. We tested our hypothesis… the null is rejected so our hypothesis must be true! The reason they don’t test their hypothesis experimentally is that they just don’t understand the need (also, what’s the incentive? also, it’s expensive)
:(
sadly i think that you are correct.
“The reason they don’t test their hypothesis experimentally is that they just don’t understand the need”
is perhaps the most gut wrenching sentence i’ve read on science in forever. If researchers do not understand (and I think you are likely correct here) the need for experimentation, then isn’t all the work on better stats, reproducibility, etc for naught?
Indeed. But, I’d point out that not all sciences can/do rely on experimentation. Take astronomy, for example. It’s pretty difficult to set up an astronomy experiment, but astronomers still manage to generate scientific knowledge with observation and abduction and prediction of future events. Certainly, let’s experiment where we can (“must do better” lists some great ideas), but I think the (lack of) multiplicity of studies on the same theory is perhaps more fundamental than whether an experimental manipulation is involved in the design.
Right, whether it’s an experimental test, or just a prediction of what we’ll find in future observations and then following up with future observations… they don’t test these models because they think that’s what “Null Hypothesis Test” means… they’ve already tested! [sic]
“I think this is what people think they’re doing when they do Null Hypothesis Tests. We tested our hypothesis… the null is rejected so our hypothesis must be true! ”
Yes — in particular, Keith’s suggestion to incorporate the note in a “methods paper” is not adequate. What is really needed is something more like “post-publication open review” — whereby comments are accepted and linked to the original paper. (Of course, one needs to figure out how to deal with trolls — and with people who attach the label “troll” to someone who makes a legitimate criticism.
My intent would be clearer if I wrote “linked FROM the original paper” instead of “linked to the original paper”
Martha:
I had put “Ideally the old paper would have a link to the new methods paper” in my comment ;-)
Keith:
“I had put “Ideally the old paper would have a link to the new methods paper” in my comment”
Yes, but my point was that there should be a platform for multiple comments from multiple people rather than just a single “methods” paper by the original authors; however, I botched my attempt to state the part that I thought should be kept.
It’s not to the level of a retraction, IMO.
A retraction basically would say to me “don’t even bother to look at this paper”. Others may feel that there’s a different signal given.
In part, I feelthis way because we have an operationalization here (top talent) which could be reasonably expected to get a lot better over the next decades as sabermetrics improves. (Think about how much better baseball metrics are post James, and in other sports the metrics aren’t as developed yet.) I can imagine someone taking their basic data set in 2035, providing a new operational definition of top talent, and finding … whatever they find.
The (correct) claim that peer review isn’t a stamp of correctness often leads to the related argument, that I’m pretty sure Andrew has made many times, that we’d be better off scrapping the present system and going to something like post-publication peer commenting. Such a system relies, of course, on people actually commenting on the merits and flaws of published papers. In practice, this commenting almost never happens. This paper is indexed on PubMed, and that would be a great place to write comments that others might actually see: https://www.ncbi.nlm.nih.gov/pubmed/24973135 . There are zero comments so far. (I don’t know if there’s something more “standard” than PubMed for Psychology articles.)
Two issues at work here:
1) There’s no one good place to comment on everything. Fragment the discussion and it’s no longer a discussion.
2) No one really cares about this stuff, and those that do probably do the same kinds of work and don’t know any better.
re (2): Unless I’m misunderstanding what you mean by “No one really cares about this stuff,” (2) is clearly not the case — this got covered in Scientific American, and the topic of how to compose teams is certainly of widespread interest. I’m sure far more people care about this than about most research!
re (1): Even if there’s “no one good place,” there have been real attempts to make more centralized venues for comments. I don’t know how many people use PubMed, but it’s standard in many fields, and I’m sure the readership for a comment made on the PubMed listing for the article would get many orders of magnitude more readers than a comment written here.
I meant “this stuff” in the general context of the overall kind of stuff we’re hearing about at this blog, red shirts and ovulation, political attitudes and arm circumference, blablabla… Occasionally you will find a topic people outside academia care about (like this one) but even when that occurs, the researchers don’t care about doing *good science* they care about getting *fancy publications* which generally goes along with doing *bad science* as Science/Nature/PNAS/Cell/PsychSci etc want a steady stream of hype.
See also my comments a little up-thread about needing to have a mechanism for comments that can be linked from the original article.
One obvious component of the problem of retractions is career impact. Someone with hundreds of papers should be able to suffer it without problem, but I suppose it’s fairly typical to have at least one junior author on a paper. In this case the senior author may fight a correction in order to protect the junior one suffering a fatal blow to her career (or less naively, in order to avoid having to admit to the junior author that the promise that working with Dr Senior will launch her career was empty). And this component is not solvable as long as personal advancement is strongly tied to the publication record (I like to recall an earlier comment from this blog: https://statmodeling.stat.columbia.edu/2016/04/05/best-disclaimer-ever/#comment-268527).
Just out of curiosity, Andrew, how old were you in terms of papers when your corrections happened?
There is something important that is missing from the detailed graphs, as well as from the paper itself. That is any kind of analysis of the variance and significance of the fitted results. Anyone who has looked at a lot of data is not going to put much stock in the details or slopes of those curves – still less for the short lines after those break points.
When I amalgamate all the data sets by eye, it does look like there might be a tendency for the overall curve to flatten somewhat. But I wouldn’t like to go beyond that, and even saying that much could be a stretch. It’s hard to see how an actual analysis of the variance would give a very different result.
So the reviewers can be faulted for not insisting on this part of the data analysis (I assume they didn’t, since it doesn’t show up in the results). There was also no (printed) attempt to see if the differences between different types of sports (e.g., baseball vs basketball) had any statistical significance.
So the original paper is missing basic statistical analysis that is critical for evaluating its claimed results. I’m not sure if that merits a retraction, but it should at least lead to a correction. It should also lead to some action on the part of the journal not to publish further papers that lack enough analysis and data to evaluate the claimed results.
5th order polynomials, broken-stick with 2 breaks, splines, gaussian processes, radial-basis expansions, fourier series, no matter what you choose if it is sufficiently flexible to represent all the possibilities at the upper end, you’re going to find that the slope in the upper portion of the graph is not well determined (posterior probability of positive slope similar order of magnitude to negative slope)
Only by choosing an insufficiently flexible model (2nd order polynomial) did they get this result. If the mass of the data has a diminishing returns concave down type shape, and you have a 2nd order polynomial to fit, the polynomial will be concave down, which means it’s required *by mathematics* to eventually reach a peak and decline. Whether that occurs before or after 100% on the x axis is not necessarily determined by actual performance in the 50-100% region.
+1
As Von Neumann purportedly said, it’s fitting an elephant, and maybe even making him wag his trunk.
Yes, except I think my point is opposite to the intention of the von Neumann quote. Without enough parameters, you can’t waggle the trunk enough to figure out that you don’t know where it really belongs. With a quadratic, the trunk HAS to turn over and go the same way as the back legs, so to speak.
Any curve sufficiently capable of wiggling around at the top end of this graph will wiggle around a lot (in posterior probability), because the top end of the data doesn’t constrain the behavior to turn over and fall down. A posterior over the curve shapes, displayed by spaghetti graphs, will show a lot of different behaviors are plausible at the top end.
I really wish I had the data sets because I’d have put up graphs illustrating what I mean. It’d be quick to fit the curve through Stan and plot the posterior samples of the curve shapes, and realize that you really don’t know what’s up here.
Over-emphasis on point estimates combines with misunderstanding in function approximation to produce a way-overly-specific “finding”.
We seem to be interpreting the von Neumann quote differently. I interpret it as “you can (often) choose a model to support almost anything you want” — in this case, choosing a model that forced a maximum.
I sort of thought he was referring to the fact that with enough flexibility a model can be made to do anything you want it to, whereas in this case, it’s *insufficient* flexibility that forces the model to do something that it wouldn’t have if it had enough flexibility.
My guess my interpretation is a little liberal, but I think still in the spirit of what von Neumann was saying: He was focusing specifically on the problem of over-fitting by using too flexible a model, but this example gives a misleading fit by working with too specific a model. So the general problem is one of using an “appropriate” type of model — one that neither allows over-fitting nor presupposes something (e.g., a maximum) that might not fit the real situation. Both are primrose paths that can give “what you want” rather than what really is the case.
I totally agree with you that by failing to model things correctly, either by being too flexible, or too inflexible, or too oblivious to important parts or considering a lot of stuff that is unimportant… you can almost always *force* your model to give what you want. In particular when you focus on a point-estimate that can be really misleading. That’s what they did here I think, and it’s in-spirit the same basic idea as von Neumann’s quote, making the model fit the expectation instead of the reality.
It’s unfortunate that retraction has become reserved for the big problems, like villainy or huge mistakes. Otherwise, this might be a good candidate. I think the fundamental problem is that retraction is seen as an indictment of the authors because they did something bad to merit their paper being banished from the literature. Here, the mistake was on the part of the journal. They should never have accepted this paper without asking for more support. Maybe with more revision the authors would have found a better approach, or more data, or just owned up to the lack of unambiguous support. But I think we really need two categories of retraction: one where the authors are at fault and one where the journal is at fault. Seems like here it’s Psych Science’s fault for accepting an incomplete paper. Maybe the retraction can be conditional on further revision, so the authors have a chance to fix up the paper with the possibility of acceptance if they do so sufficiently?
I don’t understand how the authors are deciding where to put those vertical green lines. How are they doing this?
They choose the point at which the quadratic originally fit has its maximum. The whole procedure is highly problematic. Here’s an alternative, unfortunately I guess the data isn’t publicly available or I’d have fit it and put up some graphs:
https://models.street-artists.org/2016/06/28/on-u-shapes-and-nhst/
What would be a good visualization for showing the distribution of the beta estimates over the range of data?
Its hardly newsworthy that a published paper overclaims beyond what its data actually shows. If that was grounds for retraction, you’d have to retract most of the published papers in the field.
Lewis:
I addressed your point in my above post:
Sure. But why even single out this paper? You could have picked a paper from many psych or poli sci journals at random and had a highly likelihood of finding similar over-claiming past what the data shows.
Lewis:
I didn’t single out this paper. In this blog I’ve written about dozens of papers with statistical problems. I find it useful when considering a general problem to consider a specific example. Rather than saying, “Psychological Science published papers with bad statistical analyses,” I find it helpful to consider particular examples in detail.
This comment is not on whether the paper should be retracted, but on the statistical analysis itself. The “effect” seems to simply be a matter of restriction of range. Segment off any sufficiently small portion of the x-axis and the effect will attenuate. For example, look at what the effect would be if you just examine the data between .2 and .4 on any of the graphs–small or no effect. That the authors found that performance flattened out at high levels of the independent variable is no surprise. This will happen will almost all datasets with less than perfect correlations between the independent and dependent variables.
As Lauren notes above, the inflection point (placement of the green lines) is important. I can’t see a theoretical reason why the inflection points are where they are, or why they are at different places in different analyses.
I believe that there ought to be a way to get authors such as these to publish results that are in a form that makes it clear that they are only a “maybe”.
As a broader conversation, I think that how data can be publicly disclosed, and how corrections in existing literature can be made deserves much greater discussion and then guidance and mechanisms.
In a news headline today, Vice President Biden, at the “Cancer Moonshot Summit” is pressuring cancer researchers for results: https://www.heraldonline.com/news/article86582522.html
“Vice President Joe Biden threatened Wednesday to pull federal funding for cancer studies that fail to publicly disclose their results, putting pressure on researchers, clinicians and drug companies to speed up progress toward cancer cures…..He cited concerns that prominent medical institutions that receive millions in taxpayer dollars are flouting a federal rule that says they must submit their results to a publicly accessible database within a year.”
There are several possibilities here.
A. There really are dishonorable scientific researchers who try their best to hold their work “close to the vest” so as to get to the endpoint, and to the glory themselves, and deny that opportunity to competing researchers in other laboratories. Maybe there is a Nobel prize at stake, maybe only a shot at bigger grants next year.
B. There really are researchers hard at work in their labs, with their noses down, who don’t want to stop now to get the data organized into some presentable form.
C. There really are Research agencies, who have those nose to the grindstone scientists working in their labs, and don’t want the results of those researchers to be scooped up by entrepreneurial whippersnapper patent artists before the research institution can scope out the prospects themselves.
D. There really are a lot of blind alleys to traipse down before finding the right path.
E. There really are Internet savvy, and desperate patients, who will beat down the doors of the laboratories demanding an experimental cancer treatment just before the scientists figure out it is not the right answer.
F. The amount of paperwork and other bureaucracy appeasing effort involved here would be a scientific fail.
Ultimately, we ought to find plenty of ways to say stuff like “We made a risky hypothesis and it turned out not to be supported by the data.” and move on. And, apparently, if Joe Biden is to be obeyed, we must have literature venues for reporting all of those times this occurs.
I say this as someone who’s own progress towards a PhD in Chemistry was aborted shortly after my refusal to present a paper at a conference because the credibility of the data therein was a matter I disputed with my then research advisor. It is entirely possible, from a career point of view, that I should have just read the damn paper. Other than the fact that I ended up with a masters degree and employed by the source of our research funding (Lawrence Livermore National Laboratory), and he ended up minus a position as a chemistry professor, the whole matter dissipated into a sort of gray fog.
I love new organizations like Retraction Watch which are bringing things to public view.
But now we will need mechanisms for repositories of such information as the stuff I was working on which I thought didn’t work. A lot of which is boring and uninteresting, and in some cases not even deserving of being thought about ever again.
And if we don’t want researchers to sugar coat their blind alleys we need to figure out mechanisms wherein venturing down some blind alleys does not turn into a career impacting mistake. We need to somehow provide impetus for real forward progress and also credible reporting of false starts.
Possibilities C, D, and E are likely very real concerns. I’d like to believe that there is some reasonable regulatory/legislative solution to C. I’m not sure what to do about E, but D seems like all the more reason to disseminate which are the blind dead-end alleys so that other researchers don’t duplicate effort (or so they can see the hidden trap door at the end that eluded the original research team).
Perhaps some kind of pre-print repository like ArXiv could be established for studies with disappointing results. Researchers could write up what they did quickly and not have to worry about flooding the peer-review and publication pipeline. The work in the repository could come with a big caveat that the work is preliminary and has not undergone extensive vetting.
In some disciplines, I can imagine that having your name out there with a lot of “dud” studies might be a serious disincentive, but perhaps most people in a field like cancer research understand that you try a lot of things that don’t work before you hit on the one that does.
+1
The researchers find that lay people believe ‘the relationship between top talent and team performance is linear and monotonic”, but Studies 1a and 1b (https://osf.io/zyrmj/)that they constructed to demonstrate this result only consider the variables talent and team performance. Adding other relevant variables may have yielded different results. For example, if certain players in Study 1b were described as less athletic, but more accurate passers or less agile, but with greater endurance, that would have been a clear cue to participants they may want to build a team with varied skills. If a player was described as a poor shooter, but great playmaker and passer, some participants might want to add that player to the roster, especially anyone who watched the Boston Celtics with Rajon Rondo a few years back.
Many real life examples show that just throwing a lot of superstars together does not ensure success . The researchers share a few of those examples in basketball and football, but leave out the times it has been successful (2007-2008 Boston Celtics).
They set up the straw man of linear monotonicity for lay people belief about adding talent at the superstar level and proceed to debunk that with questionable methods to fit the data while ignoring potentially relevant variables. Whether or not the paper needs to be retracted is not my realm, but to attempt a rough translation to my experience at consulting firms, if there was the possibility that the findings could be taken seriously and affect real life decisions, then there would have to be an alert to the users/clients of concern about the information . If there is no likelihood of anyone basing their real world activity on the results other than, say, to perform further studies, it might be allowed to just sit there as is on the assumption that everyone is moving on.