Carol Nickerson pointed me to a series of papers in the journal Consumer Psychology, first one by Dawn Iacobucci et al. arguing in favor of the “median split” (replacing a continuous variable by a 0/1 variable split at the median) “to facilitate analytic ease and communication clarity,” then a response by Gary McClelland et al. arguing that “there are no real benefits to median splits, and there are real costs” in increases in error, another reply by Derek Rucker et al. also arguing against the median split on the grounds of statistical efficiency, and finally another defense of the median split from Iacobucci et al.
My reply:
I think it does not generally make sense to break a variable into 2 parts. Breaking into 3 parts is better; see this paper from 2008. We recommend splitting a predictor into three parts and then coding the trichotomized variable as -1, 0, 1. This allows the ease of interpretation of the median split (you can just compare the upper to lower parts) but at a great increase in efficiency.
Key figure:
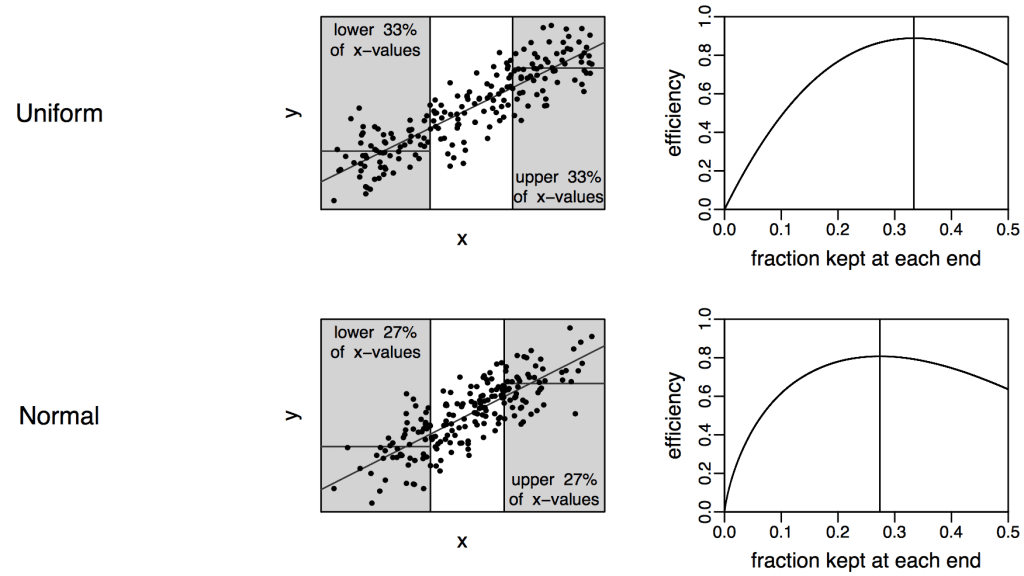
For pure efficiency it’s still best to keep the continuous information, of course, but if you have the a goal of clarity in exposition and you are willing to dichotomize, I say: trichotomize instead.
We used this trick in Red State Blue State to compare incomes of rich and poor voters, and rich and poor states, without having to run regressions (which I felt would add an unnecessary level of complexity in exposition). Indeed, David Park and I performed the analysis that led to this paper as a side project during the writing of Red State Blue State.
I had the impression this idea of trichotomizing was well known in psychometrics (when we got our paper back from the journal reviewers, they pointed us to a paper by Cureton from 1957 and papers from Kelley in 1928 and 1939!) so I was surprised to see the above papers which were all about dichotomizing. In many applications, though, I’ve seen people dichotomize in ways that seem wasteful and inappropriate. So I guess it’s necessary for experts to continue to write papers explaining why dichotomizing is generally a bad idea.
I suspect that part of the motivation for dichotomizing is that people like to think deterministically. For example, instead of giving people a continuous depression score and recognizing that different people have different symptoms at different times, just set a hard threshold: then you can characterize people deterministically and not have to think so hard about uncertainty and variation.
As Howard Wainer might have said at some point or another: people will work really hard to avoid having to think.
The median split indeed: what a joke! Truly a crime to throw away data like that, unless you really have way more than you need.
For some types of response scales, I explored something that is conceptually similar to categorizing by latent class but tried a few simple metrics to accomplish it. Consider the often used 5-point Likert type scale ranging from strongly agree to strongly disagree on multiple scale items (we will use 3 items for this example) depressed mood or some such psychological construct. Instead of simply averaging or cumulating responses and assuming this distribution reasonably represented an emergent meaning, I categorized respondents as being within one of the 5 categories based on the rationale that the categories were the conceptual constraints within which respondents were asked to think. I used a within person response mode across items. It turned out that a rounded or truncated mean produced similar results.
The logic of this is that if the items are intended to assess the same unidimensional psychological construct, then this was a more realistic representation of responses across items and that the variation lost from this was not meaningful given the methods used. I found a substantial reduction in false positives using this method. I did not get a chance to publish this before leaving that position and no longer had access to the data, so it is still simply a hypothesis, but from my exploration a rather promising one.
In addition to the reasons you cite, I suspect dichotomizing is done because dichotomizing is inherently linear. No possibility of the messy [informative] nonlinearity you can get with more pieces.
Zbicyclist:
Sure, but after trichotomizing I’m actually recommending that people just fit linear regressions. That is: conditional on having decided ahead of time to discretize and fit a linear model, I’m saying it’s better to split into 3 categories than 2.
Speaking of crimes against data – You really think -1, 0, 1 is the way to go instead of three dummy variables?
Because: https://statmodeling.stat.columbia.edu/2014/06/24/linear-true-curious-case-jens-forster/#comment-175016
To update (myself and others) on that: https://retractionwatch.com/2015/11/12/psychologist-jens-forster-settles-case-by-agreeing-to-2-retractions/
“This settlement does not represent either an admission of fault by Prof. Förster nor an accusation of fault by the Court of Honor.”
To be fair, that is about 3 different “treatments” being coded in this manner, not 3 levels of an explanatory covariate. But I still sometimes think that this was a case of “regress Y level” instead of “regress Y level1 level2 level3, noconstant” Either way, the -1, 0, 1 makes that kind of mistake possible, where three dummy variables makes it impossible, while also avoiding the problem of mentally linking low/med/high with some linear relationship.
So why code it like that? Why not just indicator variables for group?
Jrc:
I find this easiest to understand from a Bayesian perspective. Suppose we have three predictors: a constant term, a linear predictor taking on the values -1, 0, 1, and an indicator for the central bin (thus, taking on the values 0, 1, 0). Put these predictors into a linear model with coefs b0, b1, b2.
My suggested default model is equivalent to a flat prior on b0 and b1, and a point mass prior at 0 for b2.
Your suggested default model is equivalent to a flat prior on b0, b1, b2.
Which model is better? Your model can be seen as more general, but it’s unregularized. Ideally we’d want informative priors on all 3 coefficients.
I was choosing the linear model as a default because I was assuming that researchers were already planning to use a linear model on the original continuous variable. But if they were planning to include a quadratic term, then I think your model would be the natural discrete analog.
This is such a good answer – it is partly why I keep coming back here.
Thanks!
I would do something slightly different. a constant term, a linear predictor -1/2, 0, 1/2, and the orthogonal quadratic predictor -1/2, 1, -1/2. The coefficient for the quadratic equals the difference between the mean of the middle group and the mean of the two extreme groups. In a linear relationship, the mean of the two extreme groups predicts the location of the middle group. If the mean of the middle group isn’t where it is supposed to be, then the coefficient for the quadratic term is non-zero. We call it ‘quadratic’ but it really is testing non-linearity–whether the middle group is where it is supposed to be for a linear relationship.
In class I used to say, “dummy codes are named after the people who use them.” The term “dummy code” comes from the same meaning as in a “ventriloquist dummy” who doesn’t say anything on its own. We have to do a lot of work to figure out what they are saying. They also are necessarily correlated. In balanced day, the codes either I or Andrew suggest are uncorrelated and in unbalanced data they are less correlated than dummy codes.
Hence, using the linear and quadratic (really non-linear) codes is as general as dummy codes but is more readily interpretable because the codes can speak for themselves.
Maybe it is just me, but to “facilitate analytic ease and communication clarity” seems a weak argument.
For the analytic ease — maybe the solution is to pass the data to a more enthusiastic and committed researcher? (okay, half joking)
For the communication clarity — if one believes in a linear relationship, wouldn’t the proposed method be dominated by just fitting the linear relationship and then making predictions for the top and bottom halves of the dataset (for the continuous predictor), and then you can report it in the same dichotomous way, but without the loss of information that happens when you discretize the variable? (this is a real question — seems better to me, but maybe I am missing something).
I did not go past the abstracts, but the language of the final rebuttal is one of the most interesting aspects:
“…and although both teams clearly put a lot of work into their papers, the bottom line is this: our research sets the record straight.”
Well I am glad they sorted that out.
I agree with Nick. I can’t imagine a physicist or chemist saying “to facilitate analytic ease and communication clarity, I used a method that is well-known to be suboptimal.” We social scientists should be embarrassed to make such arguments.
And Nick’s suggestion for how to communicate is exactly the one that I lay out in my longer response that Andrew kindly published as the next blog https://statmodeling.stat.columbia.edu/2015/11/25/gary-mcclelland-agrees-with-me-that-dichotomizing-continuous-variable-is-a-bad-idea-he-also-thinks-my-suggestion-of-dividing-a-variable-into-3-parts-is-also-a-mistake/
I don’t see how any of these avoids the equivalent to age adjustment problem. Failing to account for the details of the distribution within groups leads to the same potential problem. The median one is especially bad in this respect but really why throw away information.
I think the idea that it’s easier to illustrate for people is also questionable, I’d like to see some research on that. If you want to explain why not just show yhat for two or three or more values if you think showing the fitted line, or even better the fitted line with data is more confusing. But I think it isn’t more confusing, my experience with really math-averse undergraduates is one thing that is not that difficult for them is under standing a scatter plot and the statement “as x increases, y increases” and usually they have some understanding of slope from algebra. GapMinder also shows really nicely that people “get” scatter plots.
PS I admit I haven’t read the articles.
I am an author on one of the rebuttals (in case it is difficult to keep it all straight). I agree with Elin; it is not clear to me what the issue is with explication. Even my most math-averse students understand scatter plots and fitted lines or curves. They can all make them in excel using trendlines. I think splitting the data is much more difficult to explain, whether into 2 or 3 groups (with or without dropping out the middle).
The only reason I can see for making categories out of continuous data is if the researcher only knows ANOVA, in which case Nick is right that they should either learn regression or coauthor with someone who knows it. The statistical problems with categorizing continuous data are not worth it.
How to split the data into three groups? I know how to split the data into two groups by using the median value. How to calculate the cutting point for three groups? Thanks.
I have found the solution here: www-psych.stanford.edu/~pam/Stats/SPSSguide.doc