Ed Green writes:
I have fitted 5 models in Stan and computed WAIC and its standard error for each. The standard errors are all roughly the same (all between 209 and 213). If WAIC_1 is within one standard error (of WAIC_1) of WAIC_2, is it fair to say that WAIC is inconclusive?
My reply:
No, you want to compare directly; see section 5.2 of this paper by Aki, Jonah, and me.
For those of you who are too lazy to click over and read the paper, the idea is that Waic and loo are computed for each data point and then added up; thus when you are comparing two models, you want to compute the difference for each data point and only then compute the standard error. That is, the scenario is a paired comparison rather than a difference between two groups.
This can matter in computing the standard error because the pointwise components of predictive error can be highly correlated when comparing the two models, in which case the correct standard error will be much lower than the standard error that would be naively obtained by combining the standard error of the separate Waic or loo calculations for the two models.
In our paper we give the example of fitting two models to the arsenic well-switching data (which you might recall from chapter 5 of ARM):
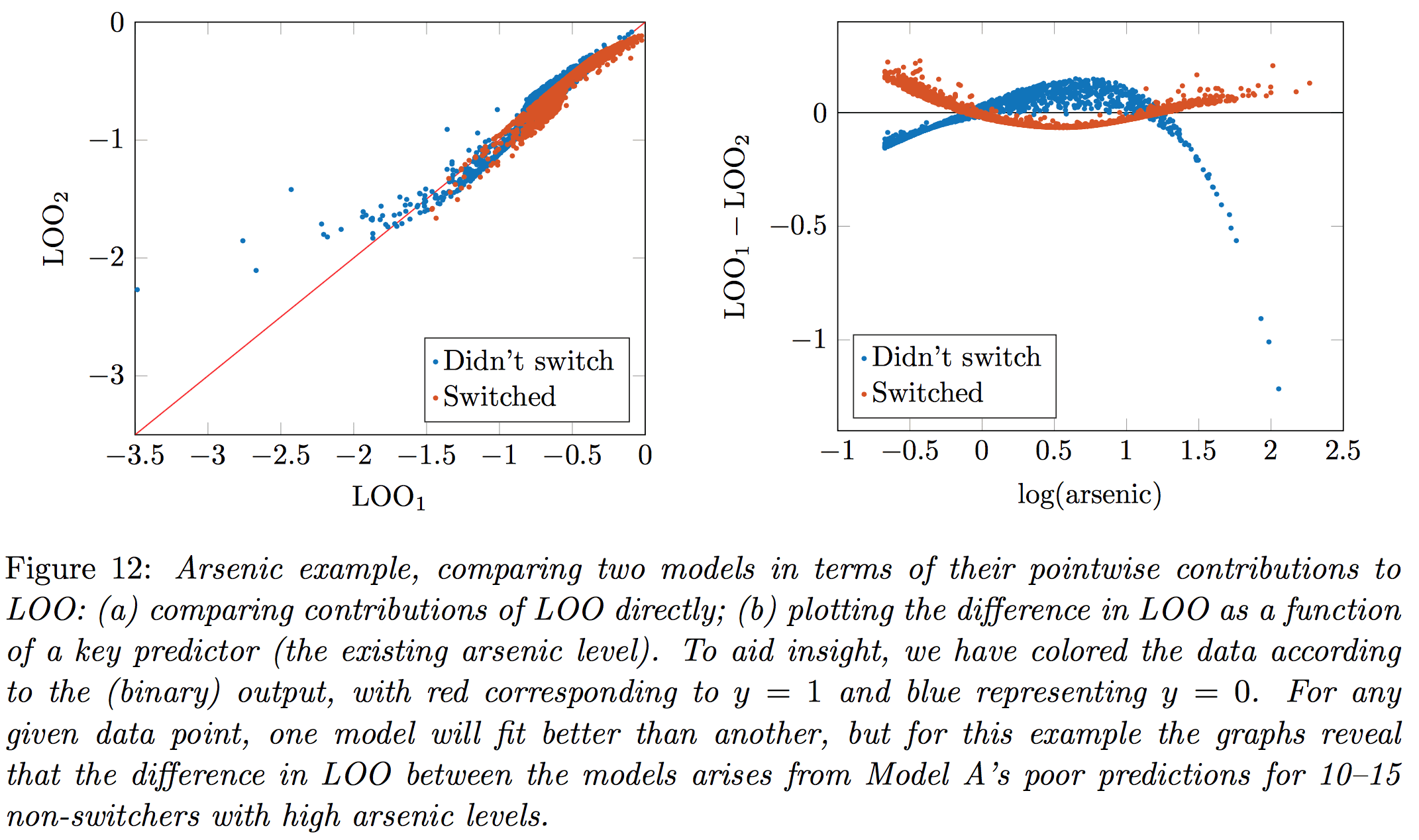
There are certain points which neither model fits well (for example, people living in households that are high in arsenic and close to neighbors with safe wells but who still say they would not switch wells), and when comparing the fit of two models it’s important to do it pointwise, otherwise you’ll overstate your uncertainty in the difference.
And all this is reminding me that we’d like to add an Anova-like feature for comparing multiple models; in that paper we present methods of computing Waic or loo for one model, or comparing two models, so we should really also present the general comparison of multiple model fits.
If you want to refer to the paper before it is published in a journal, you can refer to arXiv preprint
https://arxiv.org/abs/1507.04544
I think Jonah already extended the compare function in LOO to allow for multiple model fit comparisons. I haven’t tried it out yet, but apparently it returns a matrix if more than two objects are passed into it. Looking forward to seeing how it does… (https://github.com/jgabry/loo/blob/master/R/compare.R)
Is there any sense for how many standard errors we should be considering when using WAIC or LOO? I don’t know what the distribution of LOO and WAIC are, so I default to Chevychev’s Inequality. It would seem to require a choice of 3 or 4 SE, but this rule frequently seems much too conservative in practice. In fact, I find 2 SE often seems much too conservative, where similar models evaluated using other diagnostics like p-values or AICc are not.
Nels:
The standard error gives a sense of the uncertainty of the estimated predictive accuracy. I don’t see why there’s be a reason to choose a particular number of standard errors. The standard error is what it is.